一种非完美信息机器博弈中的虚拟遗憾最小化方法
本发明涉及非完美信息博弈,尤其涉及一种非完美信息机器博弈中的虚拟遗憾最小化方法。
背景技术:
1、机器博弈是人工智能领域的重要研究方向,它将博弈论知识应用于计算机,使计算机具有像人类一样的理性决策能力。非完美信息博弈模拟了只包含部分信息的情况下,多智能体之间的策略交互,其中最成功的算法簇是虚拟遗憾最小化算法及其变种。虚拟遗憾最小化是目前最先进的能够在大型不完全信息博弈中生成高效策略的技术之一,是一种在两人零和博弈中收敛到纳什均衡的迭代算法,并且在两人零和博弈中计算出近似纳什均衡策略的存在性和收敛性都具有理论保障。此外,深度虚拟遗憾最小化算法将深度学习与采样的虚拟遗憾最小化算法结合,用神经网络拟合状态与动作估值之间的关系,能在大型博弈空间概括状态空间从而快速收敛寻求纳什均衡策略。
2、然而,纳什均衡策略只保证了理性行为下最保守的利润,但缺乏建模对手和利用对手的能力,实现低可利用性的同时却降低了对非理性对手弱点的利用。因此,将对手建模和近似均衡结合起来是非常有必要的。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种非完美信息机器博弈中的虚拟遗憾最小化方法,克服纳什均衡收益的保守性,兼顾对手利用和安全性。
2、为解决上述技术问题,本发明所采取的技术方案是:
3、一种非完美信息机器博弈中的虚拟遗憾最小化方法,包括以下步骤:
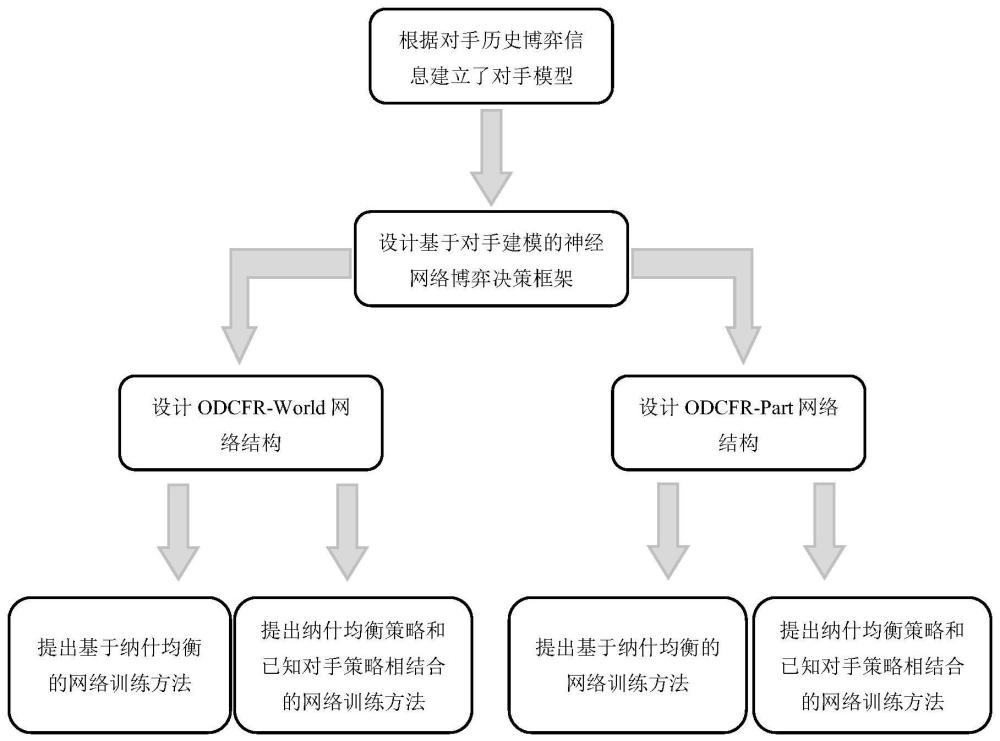
4、步骤1:建立对手模型;
5、步骤2:设计基于在线隐式对手建模的神经网络博弈决策框架;
6、将步骤1中得到的对手模型μoppo和玩家状态st作为神经网络的输入,把玩家的策略作为网络输出,构建一个通用的神经网络博弈决策框架,该决策框架无需根据专业知识建立对手模型来分析对手策略和隐藏信息,而是直接将概率化的对手模型隐性编码至对策略的影响过程中;
7、步骤3:提出基于深度对手建模的虚拟遗憾最小化-整体式和基于深度对手建模的虚拟遗憾最小化-分布式两种算法,分别简称为odcfr-world和odcfr-part,为每种算法建立估值神经网络和策略神经网络;其中,估值神经网络和策略神经网络具有相同的网络结构,分别预测当前输入下玩家的动作估值和动作策略;对于odcfr-world和odcfr-part两种算法,估值神经网络和策略神经网络的输入是不同的;
8、步骤4:面对未知对手,针对步骤3中提出的估值网络和策略网络,设计基于纳什均衡的网络训练方法;
9、步骤5:面对已知对手,针对步骤3中提出的估值网络和策略网络,提出纳什均衡策略和已知对手策略相结合的网络训练方法;
10、步骤6:训练完成后得到4组网络,分别用于与未知对手和已知对手进行非完美信息博弈。
11、进一步地,所述步骤1的具体方法为:
12、步骤1.1:基于非完美信息扑克博弈环境leduc,采用外部采样的蒙特卡洛虚拟遗憾最小化算法进行博弈游戏,并收集相关的游戏数据,包括玩家在不同状态st下的估值和策略数据;
13、步骤1.2:在每局结束时,根据步骤1.1中收集的数据,复盘统计对手在不同手牌下的博弈行为,计算对手不同手牌时的行为概率,进一步得到相应的概率分布;博弈行为包括加注、跟注、弃牌;
14、步骤1.3:根据步骤1.2中获得的对手行为概率建立对手模型。
15、进一步地,步骤1.2中所述对手不同手牌时的行为概率和概率分布的计算如下:
16、
17、
18、
19、
20、其中,roppo、coppo、foppo分别代表第t局对手手牌下加注、跟注和弃牌的次数,分别表示第t局对手加注、跟注或弃牌的概率,为当前手牌下行为的概率分布。
21、进一步地,所述步骤1.3中建立对手模型的方法如下:
22、将各个行为的概率分别按照时间进行加权处理得到对手加注、跟注和弃牌的概率μoppo,r、μoppo,c、μoppo,f,然后转换成概率分布,得到对手模型μoppo,如下式所示:
23、
24、赋予最近新的行为更高的权重,有益于在博弈过程中及时动态识别对手,从而改变自身策略。
25、进一步地,所述步骤3中,odcfr-world网络结构的设计具体如下:
26、无论对于估值神经网络还是策略神经网络,先将当前的玩家状态st和对手模型μoppo整合为一体,作为整体环境信息输入网络,然后对该整体环境信息作特征提取;当对手行为发生改变时,意味着此时的整体环境也发生了变化,网络会拟合对手模型对动作估值和策略的影响;
27、按照对手的策略对对手行为节点进行采样,重新定义odcfr算法的更新过程:在博弈状态下,将当前的状态st和对手模型μoppo作为网络的输入,输出有效动作的估值q;并将遗憾匹配算法得到的策略strategy作为依据,执行动作a,改动作a为加注、跟注或弃牌,状态转移到st+1;
28、在本局游戏结束后,针对对手的表现进行遗憾值计算,得到更新的采样历史信息集上的遗憾值rt+1;然后回顾本轮的对手隐藏信息和行为,更新对手模型μoppo,然后将{st,t,μoppo,rt+1}作为训练数据保存入估值记忆库中。
29、进一步地,所述步骤3中,odcfr-part网络结构的设计具体如下:
30、对于估值和策略两个神经网络,对状态信息和对手模型分别单独编码,然后对得到的特征向量进行合并,实现环境和对手模型共同作用来预测动作估值和策略;具体地,对环境状态提取特征,处理为隐藏信息ws,同时将对手模型μoppo提取特征,处理为隐藏信息wo,然后合并隐藏信息ws和wo。
31、进一步地,所述步骤4的具体方法为:
32、步骤4.1:收集训练数据;
33、针对未知的博弈对手,博弈双方都采用蒙特卡洛虚拟遗憾最小化算法的外部采样算法交替更新策略,收集状态-估值数据对和状态-策略数据对,并分别存入估值记忆库和策略记忆库;
34、步骤4.2:采样训练网络;
35、每收集200局的数据,从步骤4.1的记忆库中采样训练一次网络,共训练100次;采样过的数据不再放回记忆库中;
36、在这种方式下训得的网络,在博弈初期不明确对手策略的情况下,采用最谨慎的策略,以保证自身收益,并持续观察对手,在博弈中后期收集和分析对手信息,利用对手弱点调整自身策略以获得更高收益。
37、进一步地,所述步骤5的具体方法为:
38、步骤5.1:收集训练数据;
39、针对已知的博弈对手,我方玩家依然采用蒙特卡洛虚拟遗憾最小化算法的外部采样算法更新策略,但重新设计对手更新策略的方式,以200局游戏为周期,对手交替采用纳什均衡策略和已知的对手模型策略,依次收集我方的状态-估值数据对和状态-策略数据对,并分别存入估值记忆库和策略记忆库;当前记忆库中有两种类型的博弈数据,即对手分别采用纳什均衡策略和已知的对手模型策略时,我方玩家与之对应的两种博弈数据;
40、步骤5.2:采样训练网络;
41、每收集200局的数据,从记忆库中采样训练一次网络,共训练100次;此时被采数据有可能是对抗纳什均衡策略的也可能是对抗已知对手策略的混合训练网络;采样过的数据不再放回记忆库中。
42、采用上述技术方案所产生的有益效果在于:本发明提供的非完美信息机器博弈中的虚拟遗憾最小化方法,首次将对手建模与深度虚拟遗憾最小化算法结合起来,提出了一种基于深度对手建模的虚拟遗憾最小化算法,通过有效利用次优对手的弱点来获取更高的收益,同时避免被对手利用以保证策略安全。针对不同规模的非完美信息博弈问题提出了两种不同的网络结构,同时针对已知和未知的博弈对手提供了两种不同的网络训练方法。该算法充分利用非理性对手的缺点,在不损失安全性的情况下,为玩家在大型不完全信息博弈中获得了比纳什均衡更高的收益。
- 还没有人留言评论。精彩留言会获得点赞!