本技术涉及人工智能、网络游戏,本技术涉及一种智能体训练方法、游戏对战方法、装置及电子设备。
背景技术:
1、随着互联网技术的发展,网络游戏的类型越来越多,例如,moba(multiplayeronline battle arena,多人在线战术竞技游戏)中,玩家通常被分为两个或多个阵营,在分散的游戏地图中互相竞争,每个玩家控制所选的游戏角色与对方进行对战。本领域中,游戏中的游戏角色不仅可以由玩家控制,还可以由人工智能(artificial intelligence,ai)模型(如智能体)控制游戏角色进行游戏。
2、相关技术中,采用强化学习算法,采用自对弈方式让智能体在训练过程中不断探索和优化,从而学习到智能体认为的最优策略。
3、然而,智能体通常以端到端方式设计的,该方式使得使用者无法介入对智能体的调控,即使智能体在游戏对战中做出不合理行为,使用者也难以控制其行为,因而导致缺乏对智能体的可控性。
技术实现思路
1、本技术提供了一种智能体训练方法、游戏对战方法、装置及电子设备。所述技术方案如下:
2、一方面,本技术实施例提供了一种智能体训练方法,所述方法包括:
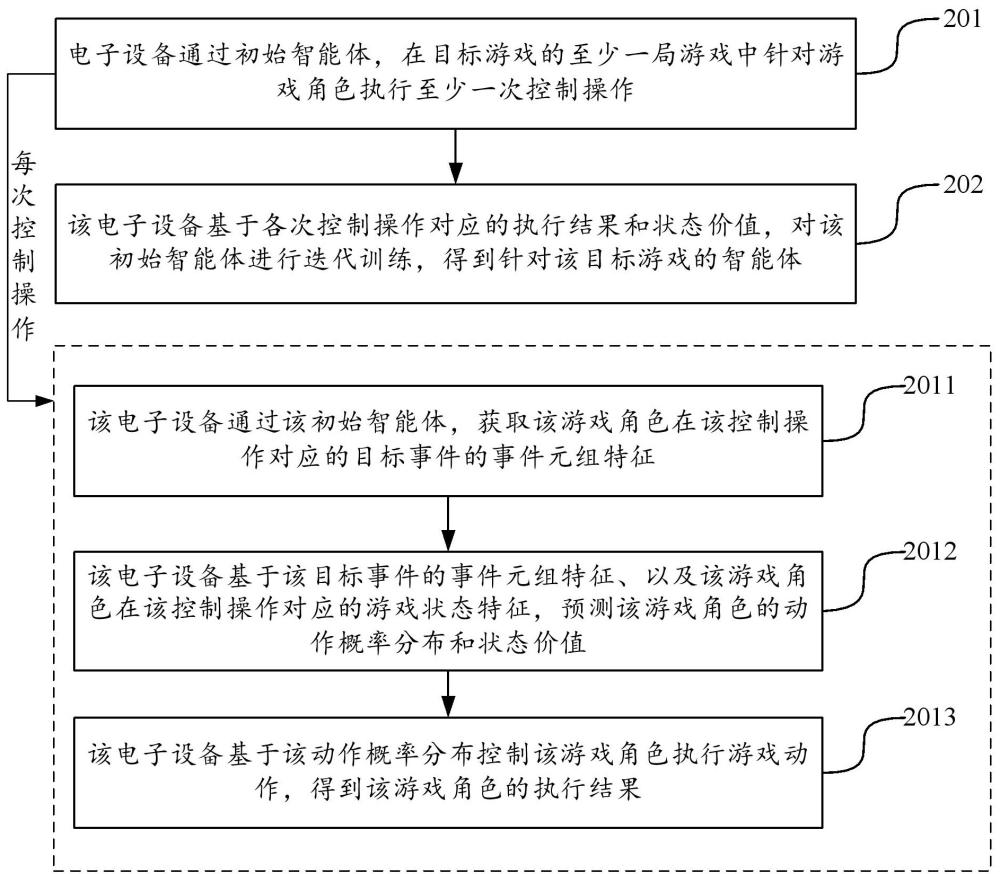
3、通过初始智能体,在目标游戏的至少一局游戏中针对游戏角色执行至少一次控制操作,每次控制操作用于调控初始智能体基于样本游戏事件控制游戏角色进行游戏对战;
4、基于各次控制操作对应的执行结果和状态价值,对所述初始智能体进行迭代训练,得到针对所述目标游戏的智能体;
5、其中,所述每次控制操作的执行过程,包括:
6、通过所述初始智能体,获取所述游戏角色在所述控制操作对应的目标事件的事件元组特征,所述目标事件是用于调控初始智能体的样本游戏事件;
7、基于所述目标事件的事件元组特征、以及所述游戏角色在所述控制操作对应的游戏状态特征,预测所述游戏角色的动作概率分布和状态价值,所述状态价值表征游戏角色的当前游戏状态对应的奖励期望;
8、基于所述动作概率分布控制所述游戏角色执行游戏动作,得到所述游戏角色的执行结果,所述执行结果包括对所述目标事件的完成程度和对应获得的游戏奖励。
9、另一方面,本技术实施例提供了一种游戏对战方法,所述方法包括:
10、在采用智能体控制目标游戏角色进行游戏对战过程中,当接收到针对所述目标游戏角色的游戏控制事件,获取所述游戏控制事件的事件元组特征;
11、基于所述游戏控制事件的事件元组特征和目标游戏角色的状态特征,通过所述智能体预测得到所述目标游戏角色的动作概率分布,所述智能体是采用上述的智能体训练方法进行训练得到的;
12、基于所述目标游戏角色的动作概率分布获取待执行动作,并控制所述目标游戏角色执行所述待执行动作。
13、另一方面,本技术实施例提供了一种智能体训练装置,所述装置包括:
14、第一训练模块,用于通过初始智能体,在目标游戏的至少一局游戏中针对游戏角色执行至少一次控制操作,每次控制操作用于调控初始智能体基于样本游戏事件控制游戏角色进行游戏对战;
15、第二训练模块,用于基于各次控制操作对应的执行结果和状态价值,对所述初始智能体进行迭代训练,得到针对所述目标游戏的智能体;
16、其中,所述第一训练模块,在用于执行每次控制操作时,包括:
17、获取单元,用于通过所述初始智能体,获取所述游戏角色在所述控制操作对应的目标事件的事件元组特征,所述目标事件是用于调控初始智能体的样本游戏事件;
18、预测单元,用于基于所述目标事件的事件元组特征、以及所述游戏角色在所述控制操作对应的游戏状态特征,预测所述游戏角色的动作概率分布和状态价值,所述状态价值表征游戏角色的当前游戏状态对应的奖励期望;
19、动作执行单元,用于基于所述动作概率分布控制所述游戏角色执行游戏动作,得到所述游戏角色的执行结果,所述执行结果包括对所述目标事件的完成程度和对应获得的游戏奖励。
20、在一个可能实现方式中,所述获取单元,在获取所述游戏角色在所述控制操作对应的目标事件的事件元组特征时,包括:
21、获取子单元,获取所述游戏角色在所述控制操作对应的目标事件;
22、拆解子单元,用于对所述目标事件进行拆解,得到所述目标事件的事件风格和事件资源;
23、生成子单元,用于基于所述目标事件的事件风格和事件资源,生成所述目标事件的事件元组特征。
24、在一个可能实现方式中,所述生成子单元,在基于所述目标事件的事件风格和事件资源,生成所述目标事件的事件元组特征时,用于:
25、将所述事件风格转换为所述目标事件的风格特征;
26、对所述事件资源进行拆解,并基于拆解得到的所述目标事件的事件位置、事件目标和事件任务,生成所述目标事件的资源特征;
27、对所述风格特征和资源特征进行拼接,得到所述事件元组特征。
28、在一个可能实现方式中,所述游戏奖励至少包括与所述目标事件的完成程度对应的事件奖励;
29、所述动作执行单元,在基于所述动作概率分布控制所述游戏角色执行游戏动作,得到所述游戏角色的执行结果时,用于:
30、基于所述动作概率分布采样得到所述游戏动作,并控制所述游戏角色执行所述游戏动作;
31、当对所述游戏动作执行结束时,基于所述游戏角色对所述目标事件的完成程度,向所述游戏角色发放事件奖励。
32、在一个可能实现方式中,所述执行结果还包括执行所述游戏动作前后的状态差异,所述游戏奖励还包括与所述状态差异对应的状态奖励;
33、所述动作执行单元,在基于所述动作概率分布控制所述游戏角色执行游戏动作,得到所述游戏角色的执行结果时,还用于:
34、当对所述游戏动作执行结束时,获取所述游戏角色执行所述游戏动作前后的游戏状态的状态差异,并基于所述状态差异向所述游戏角色发放状态奖励。
35、在一个可能实现方式中,所述每次控制操作的执行过程,还包括:
36、轨迹获取单元,用于获取针对所述游戏角色的游戏轨迹,所述游戏轨迹包括按照执行顺序排列的多个样本游戏事件;
37、所述获取单元,在获取所述游戏角色在所述控制操作对应的目标事件的事件元组特征时,用于:
38、按照所述游戏轨迹中各个样本游戏事件的执行顺序,从所述游戏轨迹中获取在所述控制操作对应的目标事件,并获取所述目标事件的事件元组特征。
39、在一个可能实现方式中,所述轨迹获取单元,在获取针对所述游戏角色的游戏轨迹时,用于以下至少一项:
40、在执行每次控制操作时,基于所述游戏角色在每次控制操作对应的游戏状态,通过事件预测模型,预测所述游戏角色对应的事件置信度矩阵,并基于所述事件置信度矩阵采样得到游戏事件,将采样得到的游戏事件按照执行顺序添加至所述游戏轨迹中;
41、若所述游戏角色的阵容属于目标阵容集合,从所述目标阵容集合对应的配置轨迹集合中,获取针对所述游戏角色的阵容的已配置游戏轨迹;
42、从预先构建的事件库中采样得到多个样本游戏事件,基于所采样的多个样本游戏事件生成针对所述游戏角色的游戏轨迹。
43、在一个可能实现方式中,所述第二训练模块,在基于各次控制操作对应的执行结果和状态价值,对所述初始智能体进行迭代训练,得到针对所述目标游戏的智能体时,包括:
44、确定单元,用于基于各次控制操作对应的游戏奖励和状态价值,确定各次控制操作对应的游戏动作的优势值;
45、差异获取单元,用于获取初始智能体与参考智能体在各次控制操作对应的动作预测差异;
46、损失计算单元,基于各次控制操作对应的游戏动作的优势值、以及动作预测差异,计算各次控制操作对应的损失值;
47、训练单元,用于基于各次控制操作对应的损失值对所述初始智能体进行迭代训练,得到所述智能体。
48、在一个可能实现方式中,所述初始智能体中包括原子层网络,每次控制操作对应的动作概率分布和状态价值是采用所述原子层网络基于事件元组特征和游戏状态特征进行预测得到的;
49、所述第二训练模块,在基于各次控制操作对应的执行结果和状态价值,对所述初始智能体进行迭代训练,得到针对所述目标游戏的智能体时,用于:
50、基于各次控制操作对应的执行结果和状态价值,对所述原子层网络的网络参数进行迭代优化,直至符合目标条件时停止迭代,得到所述智能体;
51、其中,所述目标条件包括以下至少之一:
52、所述初始智能体在各次控制操作对应的样本游戏事件的事件达成率符合第一收敛条件;
53、所述初始智能体控制游戏角色进行各局游戏对战的胜负率符合第二收敛条件。
54、另一方面,本技术实施例提供了一种游戏对战装置,所述装置包括:
55、获取模块,用于在采用智能体控制目标游戏角色进行游戏对战过程中,当接收到针对所述目标游戏角色的游戏控制事件,获取所述游戏控制事件的事件元组特征;
56、预测模块,用于基于所述游戏控制事件的事件元组特征和目标游戏角色的状态特征,通过所述智能体预测得到所述目标游戏角色的动作概率分布,所述智能体是采用上述任一项所述的智能体训练方法进行训练得到的;
57、执行模块,用于基于所述目标游戏角色的动作概率分布获取待执行动作,并控制所述目标游戏角色执行所述待执行动作。
58、另一方面,提供了一种电子设备,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序以实现上述的智能体训练方法或游戏对战方法。
59、另一方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的智能体训练方法或游戏对战方法。
60、另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现上述的智能体训练方法或游戏对战方法。
61、本技术实施例提供的技术方案带来的有益效果是:
62、本技术实施例提供的智能体训练方法,通过初始智能体,在目标游戏的至少一局游戏中针对游戏角色执行至少一次控制操作,每次控制操用于调控初始智能体基于样本游戏事件控制游戏角色;具体在每次控制操作时,可通过初始智能体,获取游戏角色在该次控制操作对应的目标事件的事件元组特征,并基于该目标事件的事件元组特征以及游戏角色的游戏状态特征,预测动作概率分布和状态价值,基于该动作概率分布控制该游戏角色执行游戏动作;并且,基于各次控制操作对应的执行结果和状态价值,对该初始智能体进行迭代训练,得到智能体。基于此,可在训练阶段,使得智能体能在样本游戏事件的调控下,不断优化学习到游戏竞技能力和完成目标事件的能力,使得训练后的智能体能基于使用者输入事件,控制游戏角色进行高水平的游戏对战,有效提高了智能体的可控性。
63、本技术实施例提供的游戏对战方法,在接收到针对该目标游戏角色的游戏控制事件时,通过智能体获取该游戏控制事件的事件元组特征;并基于该事件元组特征和目标游戏角色的状态特征,通过该智能体预测得到动作概率分布;以便基于该动作概率分布控制该目标游戏角色执行对应的待执行动作。由于该智能体是通过执行多次控制操作、并基于多次控制操作对应的执行结果和状态价值进行训练得到的,每次控制操作时可被调控基于样本游戏事件控制游戏角色执行游戏动作;使得该智能体能在多次样本游戏事件的调控下学习到游戏竞技能力和完成目标事件的能力。在使用该智能体进行游戏对战过程中,方便使用者随时输入事件对智能体进行调控,进而提高了使用该智能体进行游戏对战的灵活性和可控性。