一种基于进化算法的在线娱乐游戏难度自适应调整方法与流程
本发明涉及自适应调整,尤其涉及一种基于进化算法的在线娱乐游戏难度自适应调整方法。
背景技术:
1、随着信息技术和在线娱乐行业的飞速发展,游戏难度自适应调整成为提高用户体验和游戏粘性的重要技术。特别是在在线娱乐游戏中,游戏难度的合理调整对玩家的持续兴趣和参与度起着至关重要的作用。然而,现有技术在游戏难度自适应调整方面仍存在诸多不足,难以满足实时性和个性化的要求。
2、在现有技术中,传统的游戏难度调整方法多依赖于预设的规则和固定的难度级别。这些方法在面对多样化的玩家行为和不断变化的游戏环境时,显得力不从心。具体来说,传统方法在以下几个方面存在明显的不足:
3、1、缺乏动态适应能力:传统难度调整机制通常基于固定规则或简单的动态调整策略,无法根据玩家实时表现进行灵活调整,导致游戏难度要么过于简单要么过于复杂。
4、2、数据处理效率低:面对海量的玩家数据,传统方法往往缺乏高效的数据处理和分析能力,无法及时从数据中提取有用信息,导致难度调整滞后。
5、3、响应时间延迟:由于依赖于预设规则和静态模型,传统难度调整系统在检测和响应玩家行为变化时存在显著延迟,无法实现实时调整和快速响应。
6、4、缺乏全面性视角:传统方法多专注于单一指标(如玩家得分或游戏时间),忽略了玩家操作速度、误操作次数等多维度数据的综合分析,难以全面反映玩家的真实能力和游戏体验。
7、因此,如何提供一种基于进化算法的在线娱乐游戏难度自适应调整方法是本领域技术人员亟需解决的问题。
技术实现思路
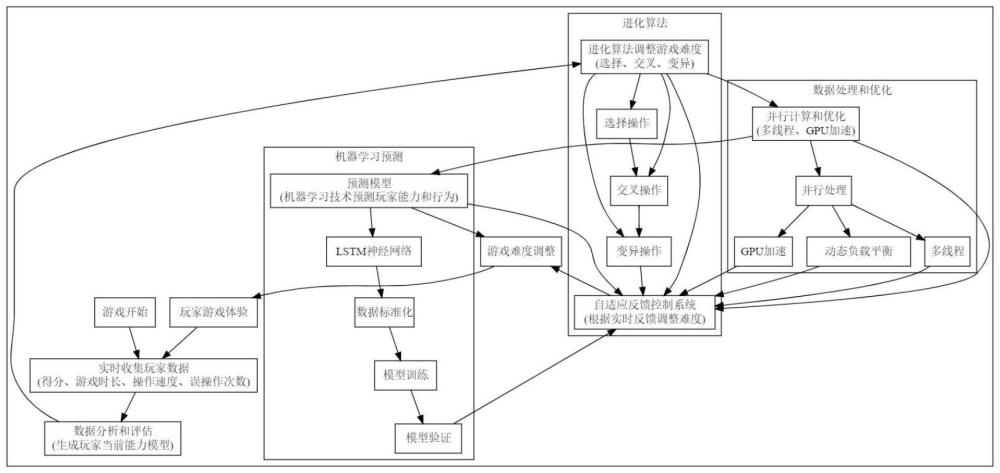
1、本发明的一个目的是提出一种基于进化算法的在线娱乐游戏难度自适应调整方法,本发明充分利用了进化算法、数据分析与挖掘、实时计算与响应、反馈控制系统和并行计算等技术,详细描述了通过实时收集和分析玩家数据,动态调整游戏难度的算法,具备动态实时调整能力强、数据处理效率高、响应时间快和多维度数据综合分析的优点。
2、根据本发明实施例的一种基于进化算法的在线娱乐游戏难度自适应调整方法,其特征在于,包括如下步骤:
3、s1、在游戏开始时初始化游戏难度,并实时收集玩家的得分、游戏时长、操作速度和误操作次数;
4、s2、基于收集的玩家数据,使用数据分析方法对玩家的表现进行评估,并生成玩家当前游戏能力的初步模型;
5、s3、应用进化算法对游戏难度进行调整,选择当前游戏难度和若干候选游戏难度作为初始种群,对选中的候选游戏难度进行交叉操作,生成新的候选难度,对交叉生成的候选难度进行变异操作,产生多样化的难度调整方案;
6、s4、通过自适应反馈控制系统,根据玩家的实时反馈对候选游戏难度进行评估和筛选,选择适合玩家当前能力的游戏难度;
7、s5、利用实时数据分析和机器学习技术,预测玩家的能力和行为模式,提前调整游戏难度;
8、s6、通过并行计算、多线程技术、gpi加速和分布式计算架构,优化进化算法的计算过程,提高游戏难度调整的响应速度和计算效率。
9、可选的,所述s1具体包括:
10、s11、在游戏开始时,根据预设的游戏难度模型初始化敌人数量、敌人攻击力、障碍物数量和游戏进程速度;
11、s12、实时收集玩家的得分数据,得分数据s为玩家在特定时间内所获得的游戏分数:
12、
13、其中,t为时间,si为第i个时间段内的得分;
14、s13、实时收集玩家的游戏时长数据,游戏时长数据t为玩家在特定游戏阶段内的持续时间:
15、
16、其中,ti为第i个时间段的时长;
17、s14、实时收集玩家的操作速度数据,操作速度v为玩家单位时间内的操作次数:
18、
19、其中,o为总操作次数,t为总游戏时长;
20、s15、实时收集玩家的误操作次数数据,误操作次数e为玩家在游戏过程中发生的错误操作次数:
21、
22、其中,ei为第i个时间段内的误操作次数;
23、s16、将收集到的玩家数据进行标准化处理,生成标准化玩家数据集d:
24、
25、其中,μ为数据集的均值,σ为数据集的标准差,xi为原始数据中的第i项,x′i为标准化后的数据;
26、s17、根据标准化玩家数据集d,构建玩家的实时表现矩阵m:
27、
28、其中,矩阵元素mij表示第i个时间段内第j项数据的标准化值。
29、可选的,所述s2具体包括:
30、s21、基于收集的玩家数据,使用数据分析方法对玩家的表现进行多维度评估,构建动态玩家表现评估模型,模型输入为标准化后的玩家数据集d,并结合时间衰减因子和权重调整机制进行实时更新;
31、s22、计算玩家的时间加权平均得分引入时间衰减因子λ:
32、
33、其中,si为第i个时间段内的得分,n为时间段总数,λ为时间衰减因子;
34、s23、计算玩家的时间加权平均游戏时长
35、
36、其中,ti为第i个时间段的时长,λ为时间衰减因子;
37、s24、计算玩家的时间加权平均操作速度
38、
39、其中,vi为第i个时间段内的操作速度,λ为时间衰减因子;
40、s25、计算玩家的时间加权平均误操作次数
41、
42、其中,ei为第i个时间段内的误操作次数,λ为时间衰减因子;
43、s26、利用上述计算得到的时间加权平均值,生成玩家当前游戏能力的动态初步模型,所述初步模型包括玩家的综合表现指数it,综合表现指数通过动态加权平均计算得到,设权重系数分别为α,β,γ,δ,则综合表现指数it为:
44、
45、其中,α+β+γ+δ=1,且α,β,γ,δ可根据玩家表现动态调整。
46、可选的,所述s3具体包括:
47、s31、选择当前游戏难度和若干候选游戏难度作为初始种群,设当前游戏难度为dc,候选游戏难度为{d1,d2,...,dk},初始种群的种群大小设为n,包含当前游戏难度和候选游戏难度,初始种群表示为:
48、p0={dc,d1,d2,...,dk};
49、其中,初始种群大小n=k+1;
50、s32、对初始种群进行适应度评估,评估标准包括玩家的综合表现指数it、游戏流畅度g和玩家的满意度s,适应度函数f定义为:
51、f(di)=w1·it(di)+w2·g(di)+w3·s(di);
52、其中,w1,w2,w3为权重系数,满足w1+w2+w3=1,it(di)为第i个游戏难度对应的玩家综合表现指数,g(di)为第i个游戏难度对应的游戏流畅度评分,s(di)为第i个游戏难度对应的玩家满意度评分;
53、s33、基于适应度评估结果,选择适应度较高的若干游戏难度进入交叉操作,设选择概率为ps,选择操作采用轮盘赌选择机制,选择概率ps定义为:
54、
55、其中,f(di)为第i个游戏难度的适应度值,n为初始种群的大小;
56、s34、对选中的候选游戏难度进行交叉操作,采用单点交叉方式,生成新的候选游戏难度,设交叉点为c,选中的两个游戏难度为di和dj,交叉后的新游戏难度d′表示为:
57、d′=crossover(di,dj,c);
58、
59、其中,k为游戏难度参数的索引,di(k)和dj(k)分别为第i和第j个游戏难度在索引k处的参数值,c为交叉点位置;
60、s35、对交叉生成的候选游戏难度进行变异操作,设变异概率为pm:
61、d″=mutate(d′,pm);
62、
63、其中,d″为变异后的游戏难度,d′为交叉后的游戏难度,k为游戏难度参数的索引,δ为一个小的随机变动值,rand(0,1)为生成在0到1之间的随机数函数,pm为预设的变异概率;
64、s36、对变异后的候选游戏难度进行适应度重新评估,并与初始种群进行比较,选择适应度较高的若干个游戏难度进入下一代种群,设变异后的候选游戏难度为d″,适应度函数为f:
65、f(d″)=w1·it(d″)+w2·g(d″)+w3·s(d″);
66、其中,w1,w2,w3为权重系数,满足w1+w2+w3=1,it(d″)为变异后游戏难度对应的玩家综合表现指数,g(d″)为变异后游戏难度对应的游戏流畅度评分,s(d″)为变异后游戏难度对应的玩家满意度评分;
67、选择适应度较高的游戏难度进入下一代种群,设新一代种群为pnext:
68、pnext={di∈p∪d″∣topnbyf(di)};
69、其中,p为初始种群,d″为变异后的候选游戏难度,n为新一代种群的大小;
70、s37、设当前代数为t,最大进化代数为tmax,适应度值收敛判定条件为δf<∈,其中δf为适应度变化量,∈为收敛阈值:
71、δf=|favg(pt+1)-favg(pt)|;
72、其中,favg(pt)为第t代种群的平均适应度值:
73、
74、其中,若满足δf<∈或t≥tmax,则停止进化,输出优化后的游戏难度d*,d*为最终种群中适应度最高的个体;
75、s38、将优化后的游戏难度d*应用到实际游戏中,实时调整游戏难度以适应玩家的当前能力和表现,设实时调整后的游戏难度为dreal:
76、dreal(t+1)=α·dreal(t)+(1-α)·d*;
77、其中,α为调整平滑系数,取值范围为0到1,用于控制实时调整的平滑程度。
78、可选的,所述s4具体包括:
79、s41、通过自适应反馈控制系统,实时监测玩家的游戏表现,所述游戏表现包括玩家的得分s、游戏时长t、操作速度v和误操作次数e;
80、s42、将监测到的玩家表现数据与当前游戏难度关联,构建实时反馈矩阵f,矩阵元素fij表示第i个时间段内第j项数据的实时反馈值:
81、
82、s43、计算实时反馈矩阵f的综合表现指数if:
83、
84、其中,和分别为玩家得分、游戏时长、操作速度和误操作次数的平均值,α,β,γ,δ为权重系数,满足α+β+γ+δ=1;
85、s44、对综合表现指数if进行动态调整,设调整系数为k,根据玩家的实时反馈调整游戏难度d:
86、dnew=dcrrent+k·(itarget-if);
87、其中,dcurrent为当前游戏难度,dnew为调整后的游戏难度,itarget为目标综合表现指数;
88、s45、在实时反馈控制系统中引入积分控制机制,设积分时间为ti:
89、
90、其中,δd为积分控制调整量,t为时间;
91、s46、结合比例控制和积分控制,生成最终调整后的游戏难度dfinal,并将最终调整后的游戏难度dfainal应用到游戏中:
92、dfunal=dnew+δd。
93、可选的,所述s5具体包括:
94、s51、利用实时数据分析和机器学习技术,预测玩家的能力和行为模式,所述玩家数据包括得分s、游戏时长t、操作速度v和误操作次数e;
95、s52、将玩家数据输入到预测模型中,预测模型采用长短期记忆lstm神经网络,构建预测模型的输入序列x和输出序列y:
96、
97、y=[sn+1 tn+1 vn+1 en+1];
98、s53、训练lstm模型,使用时间序列交叉验证方法评估模型性能,定义损失函数为均方误差mse:
99、
100、其中,yi为真实值,为预测值;
101、s54、利用训练好的lstm模型对玩家的未来表现进行预测,生成预测值其中包括未来的得分游戏时长操作速度和误操作次数
102、
103、s55、根据预测结果,提前调整游戏难度,设调整系数为k′:
104、dpred=dcurrent+k′·(itarget-ipred);
105、其中,dcurrent为当前游戏难度,dpred为预测调整后的游戏难度,itarget为目标综合表现指数,ipred为根据预测值计算的综合表现指数;
106、s56、在实际游戏过程中,结合实时反馈调整和预测调整,生成最终游戏难度dfinal:
107、dfinal=β·dreal+(1-β)·dpred;
108、其中,dreal为根据实时反馈调整的游戏难度,β为权重系数,取值范围为0到1,用于平衡实时调整和预测调整。
109、可选的,所述s6具体包括:
110、s61、在进化算法的选择、交叉和变异过程中,利用多线程技术并行处理多个候选游戏难度,设并行处理的线程数为m,每个线程处理的候选游戏难度集合为{di1,di2,...,dik}:
111、
112、其中,pt为第t代种群;
113、s62、在适应度评估过程中,利用gpu加速技术并行计算适应度函数,适应度函数f(di)为:
114、f(di)=w1·it(di)+w2·g(di)+w3·s(di);
115、其中,di为第i个候选游戏难度,w1,w2,w3为权重系数,满足w1+w2+w3=1,it(di)为玩家综合表现指数,g(di)为游戏流畅度评分,s(di)为玩家满意度评分;
116、s63、在交叉操作和变异操作中,利用分布式计算架构进行并行处理,设分布式计算节点数为n,每个节点处理的交叉和变异操作集合为{ci1,ci2,...,cik}和{mi1,mi2,...,mik}:
117、
118、其中,pt+1为第t+1代种群,crossover(di1,di2,cij)为第i个节点中第j个交叉操作,multate(dij,mij)为第i个节点中第j个变异操作;
119、s64、引入动态负载平衡机制,根据各计算节点的实时负载情况动态调整任务分配,设节点负载为li,总负载为ltotal:
120、li,new=li+δli;
121、其中,通过动态调整各节点负载,实现计算资源的均衡分配;
122、s65、在进化过程的各个阶段,通过监控计算性能指标,优化计算资源的分配策略:
123、
124、其中,tcompute为总计算时间,为第i个gpu的利用率,为第i个cpu线程的利用率,通过优化peff提高整体计算效率。
125、本发明的有益效果是:
126、(1)本发明通过结合进化算法、数据分析与挖掘、实时计算与响应、反馈控制系统和并行计算技术,提供了对玩家行为的深度理解和动态适应,使得系统能够根据玩家的实时表现不断调整游戏难度,从而有效提升游戏的挑战性和用户体验。通过进化算法的选择、交叉和变异操作,游戏难度能够在多种候选方案中逐步优化,确保每个玩家都能获得最适合其能力的游戏体验。
127、(2)本发明通过自适应反馈控制系统,实时监测和分析玩家的游戏表现,结合积分控制机制和比例控制机制,快速响应玩家的反馈,及时调整游戏难度,避免游戏难度调整过于剧烈或不及时。利用多维度数据综合分析,全面反映玩家的真实能力,确保游戏难度调整的准确性和稳定性。
128、(3)本发明利用并行计算、多线程技术和gpu加速技术,显著提高了数据处理和计算的效率。通过在进化算法的选择、交叉和变异过程中并行处理多个候选游戏难度,以及在适应度评估过程中利用gpu加速技术并行计算适应度函数,确保游戏难度调整的快速响应和高效执行。同时,引入动态负载平衡机制,根据各计算节点的实时负载情况动态调整任务分配,优化计算资源的利用,进一步提高整体计算效率。
129、(4)本发明通过机器学习技术,预测玩家的能力和行为模式,提前调整游戏难度,提供个性化的游戏体验。利用长短期记忆(lstm)神经网络模型,实时预测玩家的未来表现,根据预测结果动态调整游戏难度,确保游戏难度与玩家的预期表现相匹配,提高游戏的趣味性和持续吸引力。
- 还没有人留言评论。精彩留言会获得点赞!