模拟指定人声进行人机对话的照片框的制作方法
本发明涉及人机对话的照片框技术领域,尤其涉及模拟指定人声进行人机对话的照片框。
背景技术:
普通的相框:类似一个正方形,内部扣空,空白处刚好放常用的相片。它主要是用于相片的四边定位及加强它的美观性。也利于保护相片的质量,像带有玻璃的相框,可以防止相片变色发黄等。是装饰物品。
现有的照片框结构简单,并不能实现人机对话,现有照片框只能放置一张照片,功能少,实用价值低,为此,本发明提出模拟指定人声进行人机对话的照片框。
技术实现要素:
本发明的目的是为了解决现有技术中存在的缺点,而提出的模拟指定人声进行人机对话的照片框。
为了实现上述目的,本发明采用了如下技术方案:
模拟指定人声进行人机对话的照片框,包括圆形底座,所述圆形底座的顶部活动安装有圆柱状相框主体,所述圆柱状相框主体的外表面圆周方向等距离设有照片放置槽,所述照片放置槽的侧面铰接有透明槽盖,所述透明槽盖的另一侧通过卡扣卡接在圆柱状相框主体的表面,所述圆形底座的顶部设有安装槽,所述安装槽的内壁上部设有轴承槽,所述轴承槽的内壁安装有轴承,所述圆柱状相框主体的外壁下部固定在轴承的内壁上,所述圆柱状相框主体的内底壁中心处固定有转轴,转轴的下端活动安装在安装槽的内底壁,所述转轴的外壁下部固定有第一齿轮,所述第一齿轮啮合连接有第二齿轮,所述第二齿轮固定在驱动电机的输出轴上,所述驱动电机固定在安装槽的内底壁上,所述圆柱状相框主体的外壁上部周向等距离安装有多个红外线传感器,所述圆形底座的外壁上安装有语音交互终端,语音交互终端上设置有电源单元、声音输出单元、显示单元、储存单元、声音传感器、音色转换单元和处理器单元,所述处理器单元分别与电源单元、声音输出单元、显示单元、储存单元、声音传感器和音色转换单元连接。
优选的,所述处理器单元的输出端连接有红外线传感器,红外线传感器连接有驱动电机,红外线传感器检测是否有物体靠近,并将信息发送至处理器单元,处理器单元控制驱动电机的运行。
优选的,所述声音传感器与音色转换单元双向连接,声音传感器采集外界的语音数据,音色转换单元将采集的语音数据中的音色替换成数据库中的指定人声。
优选的,所述储存单元与声音传感器和音色转换单元双向连接,储存单元中储存有人声数据库,声音传感器采集的音色储存在人声数据库中。
优选的,所述音色转换单元的输出端与声音输出单元连接。
优选的,包括以下语音交互方法,
s1,接收语音数据;对语音数据进行语音识别,得到语音识别结果;
s2,根据预先构建的基于语义层面的判断模型对语音识别结果进行判断,得到模型输出结果;
s3,根据模型输出结果确定所述语音数据是否为人机交互语音数据;如果是,则对语音识别结果进行语义理解,根据语义理解结果生成交互结果,交互结果包括响应文本,并将响应文本转换为预设音色;
s4,根据预设音色将响应文本朗读出来,预设音色为指定人声的音色。
优选的,所述圆柱状相框主体的顶部圆形凹槽,所述圆形凹槽的顶部设置有槽盖,且槽盖与圆形凹槽的内壁螺纹连接。
与现有技术相比,本发明的有益效果是:通过照片放置槽的侧面铰接有透明槽盖,透明槽盖的另一侧通过卡扣卡接在圆柱状相框主体的表面,本照片框可以存放多个照片,通过处理器单元的输出端连接有红外线传感器,红外线传感器连接有驱动电机,红外线传感器检测是否有物体靠近,并将信息发送至处理器单元,处理器单元控制驱动电机的运行,声音传感器与音色转换单元双向连接,声音传感器采集外界的语音数据,音色转换单元将采集的语音数据中的音色替换成数据库中的指定人声,根据预设音色将响应文本朗读出来,预设音色为指定人声的音色,可以实现人机对话,而且朗读的音色可以指定设置,智能程度高,通过驱动电机可以控制照片的转动,本发明设计巧妙,结构合理,具有人机对话功能,实用性强,适合推广使用。
附图说明
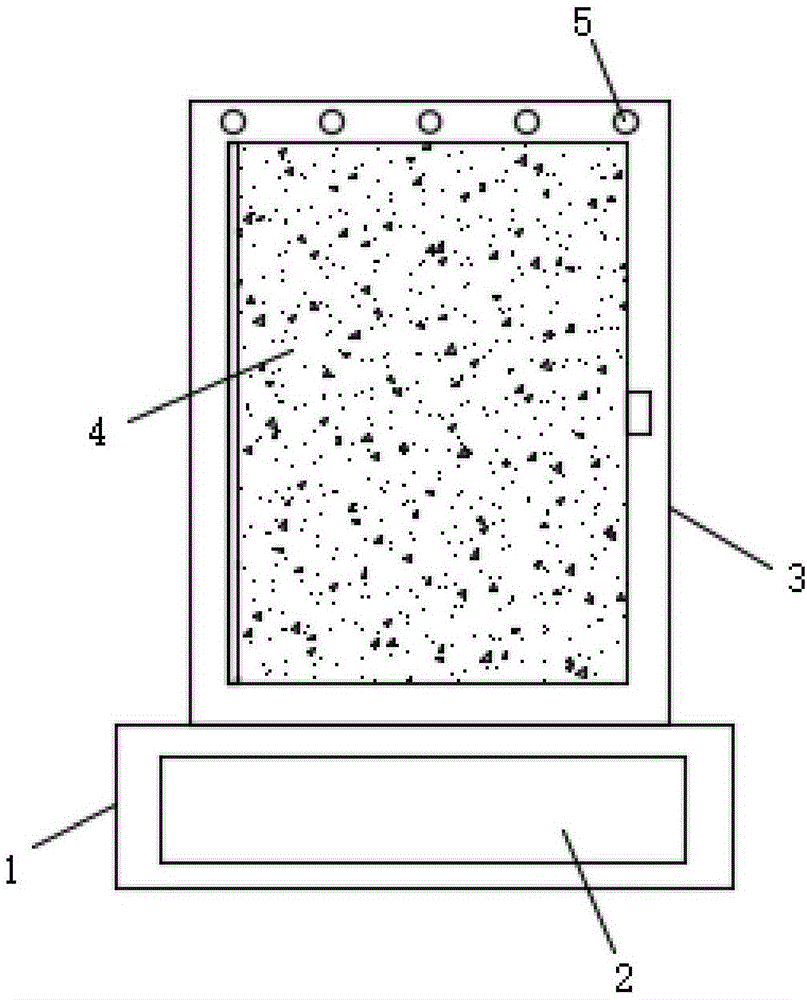
图1为本发明提出的模拟指定人声进行人机对话的照片框的结构示意图;
图2为本发明提出的模拟指定人声进行人机对话的照片框的剖视图;
图3为图2中a-a处的剖面图;
图4为本发明提出的模拟指定人声进行人机对话的照片框中语音交互终端的原理框图;
图5为本发明提出的模拟指定人声进行人机对话的照片框的人机对话原理框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
参照图1-5,模拟指定人声进行人机对话的照片框,包括圆形底座1,圆形底座1的顶部活动安装有圆柱状相框主体3,圆柱状相框主体3的外表面圆周方向等距离设有照片放置槽,照片放置槽的侧面铰接有透明槽盖4,透明槽盖4的另一侧通过卡扣卡接在圆柱状相框主体3的表面,圆形底座1的顶部设有安装槽11,安装槽11的内壁上部设有轴承槽,轴承槽的内壁安装有轴承6,圆柱状相框主体3的外壁下部固定在轴承6的内壁上,圆柱状相框主体3的内底壁中心处固定有转轴7,转轴7的下端活动安装在安装槽11的内底壁,转轴7的外壁下部固定有第一齿轮8,第一齿轮8啮合连接有第二齿轮10,第二齿轮10固定在驱动电机9的输出轴上,驱动电机9固定在安装槽11的内底壁上,圆柱状相框主体3的外壁上部周向等距离安装有多个红外线传感器5,圆形底座1的外壁上安装有语音交互终端2,语音交互终端2上设置有电源单元、声音输出单元、显示单元、储存单元、声音传感器、音色转换单元和处理器单元,处理器单元分别与电源单元、声音输出单元、显示单元、储存单元、声音传感器和音色转换单元连接。
本实施方式中,处理器单元的输出端连接有红外线传感器,红外线传感器连接有驱动电机9,红外线传感器检测是否有物体靠近,并将信息发送至处理器单元,处理器单元控制驱动电机9的运行。
本实施方式中,声音传感器与音色转换单元双向连接,声音传感器采集外界的语音数据,音色转换单元将采集的语音数据中的音色替换成数据库中的指定人声。
本实施方式中,储存单元与声音传感器和音色转换单元双向连接,储存单元中储存有人声数据库,声音传感器采集的音色储存在人声数据库中。
本实施方式中,音色转换单元的输出端与声音输出单元连接。
本实施方式中,包括以下语音交互方法,
s1,接收语音数据;对语音数据进行语音识别,得到语音识别结果;
s2,根据预先构建的基于语义层面的判断模型对语音识别结果进行判断,得到模型输出结果;
s3,根据模型输出结果确定语音数据是否为人机交互语音数据;如果是,则对语音识别结果进行语义理解,根据语义理解结果生成交互结果,交互结果包括响应文本,并将响应文本转换为预设音色;
s4,根据预设音色将响应文本朗读出来,预设音色为指定人声的音色。
本实施方式中,圆柱状相框主体3的顶部圆形凹槽12,圆形凹槽12的顶部设置有槽盖13,且槽盖13与圆形凹槽12的内壁螺纹连接。
本发明在使用时,通过照片放置槽的侧面铰接有透明槽盖4,透明槽盖4的另一侧通过卡扣卡接在圆柱状相框主体3的表面,本照片框可以存放多个照片,通过处理器单元的输出端连接有红外线传感器,红外线传感器连接有驱动电机9,红外线传感器检测是否有物体靠近,并将信息发送至处理器单元,处理器单元控制驱动电机9的运行,声音传感器与音色转换单元双向连接,声音传感器采集外界的语音数据,音色转换单元将采集的语音数据中的音色替换成数据库中的指定人声,根据预设音色将响应文本朗读出来,预设音色为指定人声的音色,可以实现人机对话,而且朗读的音色可以指定设置,智能程度高,通过驱动电机9可以控制照片的转动,本发明设计巧妙,结构合理,具有人机对话功能,实用性强,适合推广使用。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!