一种基于强化学习的时序逻辑任务规划方法与流程
本发明属于人工智能领域,具体涉及一种基于强化学习的时序逻辑任务规划方法。
背景技术:
在实际任务中,很多任务不仅要求简单的并行协作,而且需要去执行更为复杂的串行协作任务,即机器人根据任务进行的阶段不同需要执行不同的任务。这种在环境、时间和执行顺序都有要求的任务称为时序逻辑任务。任务规划(taskplanning)问题是在给定任务下,找到一系列将系统从初始状态更改为目标状态的操作。解决过程类似于人类审议,通过预测其结果来选择和组织行动。任务规划可以应用在多个领域:人工智能,机器人系统,军事指挥等。所以,任务规划这一领域的研究吸引着越来越多的研究人员投入其中。
针对实际中具有时序逻辑特性的任务,任务规划的解决方案有:
方案1:文献(mengg,zavlanosmm.probabilisticmotionplanningundertemporaltasksandsoftconstraints[j].ieeetransactionsonautomaticcontrol,2017.)针对时序逻辑任务规划问题,首先对任务使用确定性rabin自动机进行建模,并将运动过程转换成马尔科夫决策过程,最后使用dijkstra算法得出任务规划结果。
方案2:文献(a.krizhevsky,i.sutskever,andg.e.hinton.imagenetclassificationwithdeepconvolutionalneuralnetworks[j].advancesinneuralinformationprocessingsystems.2012:1097–1105.)利用深度卷积神经网络进行任务规划,机器人可以从以前的例子中收集数据或观察人类演示,通过反复试验找出解决方案。
上述方案1在使用过程中需要进行计算,实时性不好;方案2不能处理训练数据中没有的新任务,有效性不足,而且规划结果不具有安全性,可能违背给定的任务时序逻辑。
技术实现要素:
有鉴于此,本发明提供了一种基于强化学习的时序逻辑任务规划方法,能够提高时序逻辑任务规划的实时性、有效性和安全性。
为了解决上述技术问题,本发明是这样实现的:
基于强化学习的时序逻辑任务规划方法,包括:
步骤1、采用线性时序逻辑语言给定任务,并转换成büchi自动机
所述生成式büchi自动机ap由六元组组成:ap=(q',δ',q0',f',wp,d')
其中,q'是生成式büchi自动机中的组合状态的集合,组合状态是生成式büchi自动机状态图中的顶点,它是büchi自动机状态与fts中栅格区域的组合;
δ'是生成式büchi自动机中的状态转换关系,是生成式büchi自动机状态图中的边;当且仅当顶点之间的转换关系满足fts所表达的地理约束和nba所表达的任务约束,才将这两个顶点之间的边连通;
q0'表示智能体初始状态;
f'是由所有可接受状态组成的可接受状态集;
wp表示代价函数,直接采用fts中栅格之间的路径长度;
d'表示死区状态的集合;死区状态定义为:当执行到这个状态时,违背了给定任务,无法继续执行;
步骤2、利用q-learning方法对生成式büchi自动机ap进行任务规划训练;在迭代训练训练过程中,当组合状态进入可接受状态f'或者死区状态d'时,结束本轮迭代,跳转进入下一次迭代过程;同时,更新状态-动作值所使用的奖励函数包含当组合状态进入可接受状态f'或者死区状态d'时给予奖励值或者惩罚值的设定。
具体来说,所述步骤2包括:
步骤201、定义组合状态s所对应栅格区域π的动作空间为a(s),动作空间中的执行动作记为a,a∈a(s);定义在组合状态s下执行动作a的状态-动作值为w(s,a);在组合状态s应该执行的动作记为x(s),定义为组合状态s对应的动作空间a(s)中令状态-动作值最大的动作;初始化w(s,a)=0;
步骤202、初始化当前组合状态变量s=<π0,q0>,π0表示智能体初始位置,q0表示任务初始状态;
步骤203、以概率ε在当前组合状态s对应的动作空间a(s)随机选取动作,以概率1-ε在动作空间a(s)选取状态-动作值w(s,a)最大的动作;根据状态转换关系δ',确定执行所选取动作后即将跳转到的下一个组合状态为s';确定跳转到组合状态s'所带来的奖惩值r(s');
步骤204、将组合状态s'应该执行的动作x(s'),赋值给动作变量a';
步骤205、更新当前组合状态s的状态-动作值w(s,a):更新为w(s,a)+α[r(s')+γw(s',a')-w(s,a)];其中,α,γ∈(0,1)为设定的超变量;r(s')为利用奖励函数确定的、从当前组合状态s跳转到状态s所带来的奖惩值;w(s',a')为组合状态s’执行组合动作a'的状态-动作值;
步骤206、更新x(s):在当前组合状态s对应的动作空间a(s)中找到令状态-动作值最大的动作,更新当前组合状态s应该执行的动作x(s);
步骤207、跳转到步骤203所确定的下一个组合状态s',令当前组合状态s=s';
步骤208、如果跳转后的当前组合状态s属于f'或d',则进入步骤209,否则,返回203;
步骤209、令迭代次数t自加1,如果迭代次数未达到设定次数,则返回步骤202,否则,结束训练,得到最终的动作规划策略x(s)。
优选地,所述奖励函数为:
当组合状态s'属于可接受状态集f'时,表明该任务完成,给予设定的正奖励值+k;
当组合状态s'属于死区状态的集合d'时,表明该行为违背任务,给予设定的负的惩罚值-k';
当组合状态s'处于其余状态时,表明正在执行任务,给予与移动距离成正比的负的惩罚值,正比比例β的取值范围为0<β<1。
有益效果:
(1)本发明基于büchi自动机和有限状态转移系统,设计了一种结合环境和任务时序逻辑的自动机——生成式büchi自动机,该自动机的状态转换关系δ'考虑了任务约束,同时增加了反应任务时序逻辑的死区状态,因此任务规划结果不会违背给定的任务时序逻辑,提高了规划结果的安全性。
(2)本发明将任务时序逻辑纳入到奖励函数的设定中,不仅有奖励还有惩罚值,进一步提高了规划结果的安全性。
(3)本发明针对任意任务均可以通过训练完成规划,保证了任务规划算法的有效性。
(4)任务规划在训练过程需要一定量的迭代更新计算保证最后规划结果的收敛性,但是在使用过程中无需复杂计算,只需要按照训练得到的策略执行动作即可,所以提高了任务规划的实时性。
附图说明
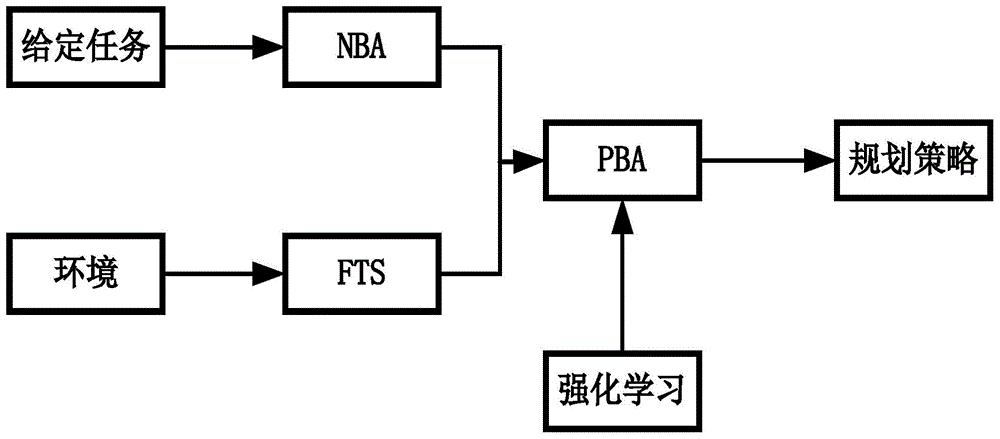
图1—基于强化学习的时序逻辑任务规划框架;
图2—实际环境和栅格区域对应动作空间;
图3—有限状态转移系统;
图4—非确定性büchi自动机;
图5—规划策略;
图6—规划结果。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
本发明完全不同于背景技术中所提及的两种方案以及未列出的现有方案。针对时序逻辑任务规划问题,提出了一种全新的基于强化学习的时序逻辑任务规划方法。首先使用线性时序逻辑语言和非确定性büchi自动机对任务进行建模,并使用有限状态转移系统对环境进行描述;根据强化学习的需求,创新性的设定组合状态、状态转移关系、奖励函数;最后使用q-learning的方法进行训练得到规划结果。
为了实现该时序逻辑任务规划方法,首先需要对本发明创造的生成式büchi自动机进行说明。该生成式büchi自动机是在现有的有限状态转移系统(weightedfinite-statetransitionsystem,fts)和非确定性büchi自动机(nondeterministicbüchiautomaton,nba)的基础上建立起来的。该生成式büchi自动机就是面向强化学习的时序逻辑任务框架。
(1)有限状态转移系统——fts
fts用于对实际环境进行描述建模,表达了任务中的地理转换关系。如图3所示,将地理环境划分为多个栅格区域,栅格为顶点,顶点之间的边表达栅格区域间的转换关系,边和顶点以及另外4个描述量构成了fts的多元组表达tc。fts的定义参见定义1。
定义1.有限状态转移系统(fts)的组成是一个多元组tc:
tc=(π,→c,π0,ap,lc,wc)
其中:
π={π1,π2,...,πn}表示各个栅格区域,是fts图中的顶点,参见图3中的(0,2)、(1,1)等;
ap表示任务集合;一个完整的任务可以划分成多个子部分,称子部分为原子命题,由原子命题组成的集合记为ap;
每一个区域都会具有一定的属性,称之为标签。例如,π1区域有一个篮球,那么篮球就是π1区域的标签。lc:π→2ap表示标签函数,lc(πi)表示区域πi具有的标签;如图3中的{x}、{u}、{v}就是区域(0,2)(1,2)(2,0)的标签。
(2)非确定性büchi自动机
根据线性时序逻辑语言理论,任何一个时序逻辑任务,都可以用线性时序逻辑(lineartemporallogic,ltl)语言进行描述建模,记为
nba的定义参见定义2。
定义2.
其中,
q表示由非确定性büchi自动机中状态的集合,就是图4中的各个顶点;
δ:q×q表示状态之间的转换关系函数,即顶点之间的边;
状态之间的转换条件(如图中边上注释)是区域的属性,属性的集合称为字母表,记为2ap;
(3)本发明的生成式büchi自动机
强化学习需要一张带权的有向图进行训练,fts和nba都是有向图,且fts具有带权的特征。因此,本发明将fts和nba进行生成
定义3.生成式büchi自动机(weightedproductbüchiautomation,pba)由一个六元组组成:
其中:
δ'是生成式büchi自动机中的状态转换关系,是生成式büchi自动机状态图中的边。本发明的状态转换关系表达为δ'=q'→2q'.<πj,qn>∈δ'(<πi,qm>),其含义是当且仅当顶点之间的转换关系满足fts所表达的地理约束和nba所表达的任务约束,才将这两个顶点之间的边连通。例如,<(0,2),init>和<(0,2),1>之间的边,顶点(0,2)满足!u∧x条件,因此可以将<(0,2),init>和<(0,2),1>这两个顶点连通。采用公式表达就是:当且仅当(πi,πj)∈→c并且qn∈δ(qm,lc(πi)),δ(qm,lc(πi))表示从qm到qn的转换条件与lc(πi)相等。
可见,该状态转换关系的设置是本发明的一个重点,其考虑了任务约束,因此任务规划结果不会违背给定的任务时序逻辑,提高了规划结果的安全性。
q0'={<π,q>|π∈π0,q∈q0},表示智能体初始状态;
f'={<π,q>|π∈π0,q∈f},是由所有可接受状态组成的集合,即可接受状态集;在本实例中,图4中的可接受状态3扩展到生成式büchi自动机后,产生了9个可接受状态,<(0,2),3>~<(2,0),3>。
因此,由任务模型nba和环境模型fts组合而来的生成式büchi自动机就是面向强化学习的时序逻辑任务框架。
基于上述生成式büchi自动机的定义,要想完成任务规划算法,还需要定义几个变量和函数。
(1)组合状态s
对于时序逻辑任务规划问题,规划结果不仅要满足环境约束,同时要满足任务约束。因此,设定组合状态s的形式为s=〈π,q〉。
(2)动作空间
对于栅格网络,每一个栅格区域动作空间可以分为八个方向,用向量表示为:actions=[(0,0),(0,1),(1,1),(1,0),(1,-1),(0,-1),(-1,-1),(-1,0),(-1,1)]。对于边缘区域,如果执行某个动作会使得转换后的下一个区域超出边界,则舍去该动作。如图2所示,一个3×3的栅格网络,每个栅格区域可以执行的动作表示为蓝色的箭头,区域x的动作空间为[(0,0),(1,0),(1,-1),(0,-1)],区域v的动作空间为[(0,0),(0,1),(-1,1),(-1,0)]。因此,将栅格区域π的动作空间记为a(π)。
(3)状态转移关系
假设在任意组合状态s=〈π,q>,执行动作a,a∈a(π)。在实际环境中的表现为智能体执行动作a,到达区域π',记为π→π'。由定义3可知,büchi自动机的状态q根据区域π的标签函数发生改变,q'∈δ(q,lc(π))。
因此,有
(4)奖励函数
智能体任务规划过程中,当智能体动作后,需要计算该动作对整体任务执行带来的影响,采用奖励值表达。本发明将任务时序逻辑纳入到奖励值函数的设定中,不仅有奖励值还有惩罚值,从而提高了任务规划结果的安全性。
本发明奖励值函数设定为:
智能体所处组合状态属于可接受状态集f'时,表明该任务完成,给予较大的正的奖励值+k,k为设定的数值;当组合状态属于死区状态d'时,表明该行为违背任务,给予较大的负的惩罚值-k';组合状态处于其余状态时,表明正在执行任务,给予与移动距离dis成正比的负的惩罚值,0<β<1。因此,奖励值函数表示如下,其中s'表示状态转换后到达的组合状态:
从上述函数可以看出,本发明将任务时序逻辑纳入到奖励值函数的设定中,不仅有奖励值还有惩罚值,从而提高了任务训练结果的安全性。
基于上述定义,下面对本发明的时序逻辑任务规划过程进行描述。
时序逻辑任务的规划问题可以表示为:以最小化代价函数为目标,使智能体从初始状态开始,通过执行一系列动作完成状态转移,最终到达任意一个可接受状态。
本发明利用q-learning方法对生成式büchi自动机ap进行任务规划训练;在迭代训练训练过程中,当组合状态进入死区状态d'时,结束本轮迭代,跳转进入下一次迭代过程;同时,更新状态-动作值所使用的奖励函数包含当组合状态进入死区状态d'时给予惩罚值的设定。
训练的具体步骤如图1所示,包括:
①采用线性时序逻辑语言给定任务
②初始化w(s,a)。
定义组合状态s所对应栅格区域π的动作空间为a(s),动作空间中的执行动作记为a,a∈a(s);定义在组合状态s下执行动作a的状态-动作值为w(s,a),该函数值在训练中更新;在组合状态s应该执行的动作记为x(s),定义为组合状态s对应的动作空间a(s)中令状态-动作值最大的动作。
则本步骤初始化w(s,a)=0,
③初始化当前组合状态变量s=<π0,q0>,π0∈π0,q0∈q0;根据定义1,π0表示智能体初始位置,并使用随机算法在环境中任意选取位置。根据定义2,q0表示任务初始状态。
④以概率ε在当前组合状态s对应的动作空间a(s)随机选取动作,以概率1-ε在动作空间a(s)选取状态-动作值w(s,a)最大的动作。其具体做法是:随机产生一个数b,当b小于设定概率ε,则在当前组合状态s对应的动作空间a(s)随机选取动作;当b大于或等于ε,则在动作空间a(s)选取状态-动作值w(s,a)最大的动作。
然后,根据状态转换关系δ',确定执行所选取动作后即将跳转到的下一个组合状态,记为s';利用前述奖励函数确定从当前组合状态s跳转到组合状态s'所带来的奖惩值r(s')。
⑤令a'=x(s'),即将组合状态s'应该执行的动作x(s'),赋值给动作变量a'。如果之前的训练过程还没有训练到s',则x(s')取组合状态s'对应的动作空间a(s')中令状态-动作值w(s',a')最大的动作。
⑥更新当前组合状态s的状态-动作值:
本发明状态-动作值的更新公式为:
更新后w(s,a)=w(s,a)+α[r(s')+γw(s',a')-w(s,a)]
其中,α,γ∈(0,1),为设定的超变量。r(s')为步骤④确定的奖惩值;w(s',a')为组合状态s’执行组合动作a'的状态-动作值;当第一轮训练还没有训练到s’,w(s',a')取给定的初始值。在第t轮训练时,w(s',a')采用第t-1轮训练获得的值。
⑦更新x(s):
令x(s)=argmaxa"w(s,a″),在当前组合状态s对应的动作空间a(s)中选取使状态-动作值函数w(s,a″)最大的动作a″作为x(s),该x(s)是组合状态s应该执行的动作,也训练得到的任务规划策略。
⑧跳转到组合状态s',令当前组合状态s=s';
⑨如果s∈f'或s∈d',说明本轮训练内部的循环结束,继续下一步⑩;否则,返回④。本步骤增加了s∈d'的判断,只要状态s满足到达可接受状态,或者根据任务时序逻辑,当执行到这个状态时,违背了任务时序逻辑,则停止本来循环。
⑩令t自加1。如果t≤times,返回③;否则,结束训练,得到最终的规划策略x(s)。
实际案例
如图2所示,智能体所处的环境是一个3×3的栅格网络,对应的fts如图3所示。假设智能体的任务
该表达式表述的含义是:终点是u;不能去u,直到去了v;不能去v,直到去了x。
转换成对应的büchi自动机
按照设计的算法进行训练,将times设定为1000,其中,各参数设定为α=0.5,β=1,γ=0.8,k=100,k'=100。最终得到的x(s)如图5所示。其中,图5(1)表示组合状态s=<π,q>中的非确定性büchi自动机状态q=init时,不同栅格区域π对应的最佳动作策略。
假设智能体目前的位置为区域(0,0),根据训练得到的规划策略x(s),完成任务的路径如图6所示。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!