一种基于目标检测的巡检机器人视觉伺服方法与流程
设备巡检机器人是基于自主导航、精确定位、自动充电的室内、外全天候移动平台,集成可见光、红外、声音等传感器;基于激光扫描导航系统,实现巡检机器人的最优路径规划和双向行走,将被检测目标设备的视频、图像数据通过无线网络传输到监控室;巡检后台系统通过对待检设备的图像处理和模式识别等技术,结合设备图像模板库,实现对设备缺陷、外观异常的判别,以及开关闭合状态、仪表读数、油位计位置的识别;并配合数据服务系统输出巡检结果报告及异常状态分析报告。
在日常的机器人巡检任务中,实时采集的待检测设备的图像经常会产生视野的偏差,导致需要检测的设备区域不能居于图像的中心位置,甚至设备区域会部分或全部偏出图像,这样将导致机器人无法正常的进行设备目标定位以及工作状态的识别,造成巡检场所设备安全运行的隐患。这种机器人采集图像时产生的偏离误差的原因,在参考1中进行了详细的描述。
参考1:“发明专利,专利号:zl201610457745.x,《基于视觉伺服的变电站巡检机器人云台控制方法》,发明人:房桦,隋吉超等。”
当前巡检机器人的目标设备定位模式大多采用实时图像与设备模板图像匹配的方式,如中国第201510229248.x发明《一种基于图像比对的电力设备外观异常检测方法》中描述利用巡检机器人采集图像进行与原图匹配的方法进行目标设备定位。设备模板图像是由后台操作员人工控制机器人云台及相机进行拍摄采集,一般情况下配置设备区域位于图像的中央部分,以此保存云台角度与相机焦距等相关的参数,而机器人在执行巡检任务时无操作人员对其进行干涉,机器人行进至每一设备的检测点预置位后,调用该设备模板图像的拍摄参数,进行云台转动控制及相机拉焦,自主采集实时设备状态图像,缺乏设备区域是否偏出图像视野范围的验证。
基于此原因,在参考1中该专利发明人提出了一种视觉伺服解决方法,即采用图像特征匹配算法计算实时的巡检图像与设备模板图像之间的视野角度差,以此角度为云台补偿值调用云台转动到合适位置采集准确的目标设备图像。在光照条件良好,机器人采集的图像特征丰富、目标设备未完全偏出图像边界时,该方法可行,经过视觉伺服功能的启用可以较准确的采集到完整的目标设备图像,进而输出有效的识别结果。但是,在以下状况发生时该方法仍然会出现错误:
(1)图像特征匹配算法对光照强度的影响非常敏感,在机器人巡检任务中经常会出现逆光条件下采集图像的情况,实时图像与模板图像的光照差异明显,造成图像特征配置失败,因此无法计算视角偏移量
(2)设备区域表面比较平滑,没有明显的边缘、角点等特征,并且背景较为单一,如墙面、天空,在图像特征匹配过程中,计算出的可用于匹配的图像特征稀疏,造成实时图像与模板图像无法进行图像匹配;
(3)当巡检机器人的停车位置存在误差时,调用的采集参数并不能获得与模板图像一致的、清晰的图像,如发生拍摄角度水平偏转、虚焦、尺度变化等现象,这种质量的图像无法保证图像特征匹配的准确性。
近年来,计算机视觉领域中广泛的采用了深度学习技术,在人脸识别、智能驾驶、场景分类等任务中收获了丰富的成果。尤其在目标检测(目标定位)算法中,采用深度学习的检测模型逐渐取代了以目标图像为模板的图像匹配算法。深度学习是当前人工智能研究的主要方向,深度学习的概念源于人工神经网络的研究,含多隐层的多层感知器就是一种深度学习结构2。目标检测对于计算机来说,输入的图像是一些值为0-255的数组,因而很难直接得到图像中具体存在某种物体这种高层语义概念,也不清楚目标出现在图像中哪个区域。图像中的目标可能出现在任何位置,目标的形态可能存在各种各样的变化,图像的背景千差万别,目标检测功能可以采用深度学习主要是卷积神经网络(convolutionneuralnetwork:cnn)和候选区(regionproposal)算法来实现。采用深度学习技术的目标检测算法,受光照条件的影响小,对于不同尺度、角度偏转、模糊噪音的鲁棒性高。
参考2“孙志军,薛磊,许阳明,王正.深度学习研究综述.计算机应用研究.2012(08)”。
本领域中,中国第201510785505.8发明《一种无人机机动目标定位跟踪中的视觉伺服控制方法》根据目标的成像序列,进行目标的定位及目标跟踪的姿态角给定值和航线跟踪的姿态角给定值的计算,完成视觉伺服控制;中国第201110216396.x发明《基于变电站巡检机器人的断路器状态模板匹配识别方法》采用了在模板图像中人工标记目标设备区域,通过采集的巡检图像与模板图像特征配准的方法将设备区域映射到采集图像中完成目标的定位;中国第201610874173.5发明《一种具有闯红灯取证功能的人行横道信号灯系统及方法》采用深度学习技术对行人及人脸区域进行目标检测,通过提取的目标区域及身份识别进行违法处罚。
如参考1中描述,基于图像特征匹配的视觉伺服流程为:在执行巡检任务前,需要将机器人拍摄的巡检场景内每一个预置位的设备图像都保存到模板库中,模板库中的设备图像和巡检场景中的设备是一一对应的,在向巡检机器人下达巡检任务时,要将在每个预置停车位拍摄模板图像的各项参数(如,云台角度,相机焦距等)明确的指出,在巡检机器人行进至此预置停车位后,依照该设备模板图像的采集方式进行姿态调整,拍摄实时的设备图像,通过实时图像与模板图像的特征匹配计算角度偏差,然后机器人自主控制云台进行角度补偿,将目标设备置于相机视野的中心位置。
由此可见,机器人对设备图像的采集质量,以及实时图像与模板图像之间特征匹配的准确度关系到整个视觉伺服运行的结果。设备的模板图像是由人工操作机器人进行采集,往往选择光线照射柔和、清晰度良好的图像作为该设备的模板。但是在实际的机器人巡检过程中,强烈阳光的照射、设备的反光、明亮的天空背景、眩光,以及机器人停车位置的误差等很多因素制约着图像特征匹配的精度。
更加有效的改进应当是给定一张包含某个设备的全景(或广角)图像,采用深度学习中视觉目标搜索的方式,在图像中找到那个与样本集实例设备相同的物体区域,计算检出区域中心与图像中心的夹角,并以此角度作为云台旋转角度的补偿,转动云台将目标设备置于相机视野中心,拉近焦距至适合进行图像识别的位置。
目前基于图像匹配的视觉伺服解决方案主要存在以下几方面问题:
1、为每一个待巡检的目标设备需要采集清晰的模板图像用以进行图像匹配,需要大量的人工工作参与;
2、模板图像采集的机器人参数被固定,用以在巡检任务中供机器人调用,如果目标设备距离机器人观测点较远时需要使用相机的长焦端采集,机器人的观测姿态稍有误差,则目标极易偏出观测视野,造成与模板图像匹配的失败;
图像特征匹配算法受到光照强度与特征点稀疏程度的影响,且对于尺度变换、噪音、旋转的图像匹配结果易产生误差,这些因素都制约着最终视觉伺服结果的准确度,应当使用更加鲁棒的算法去进行图像中的目标检测;
为此,我们提出了一种基于目标检测的巡检机器人视觉伺服方法来解决上述问题。
技术实现要素:
本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于目标检测的巡检机器人视觉伺服方法。
为了实现上述目的,本发明采用了如下技术方案:
一种基于目标检测的巡检机器人视觉伺服方法,包括以下步骤:
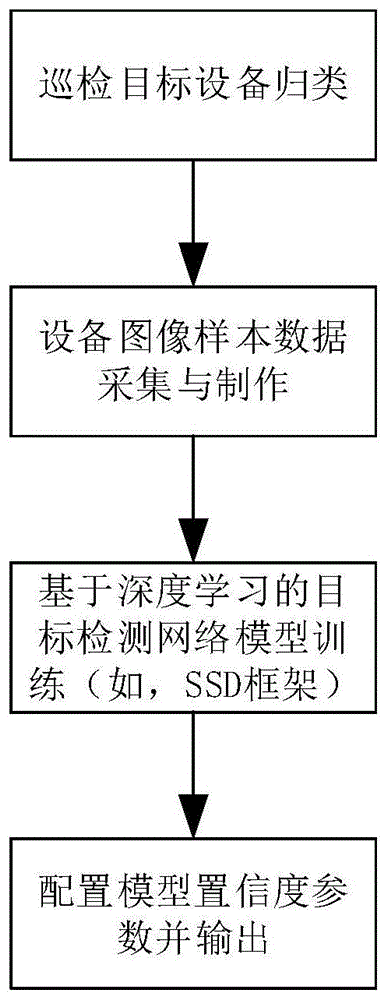
s1、采集与制作每一个类型设备的样本图像,根据机器人巡检时观测的角度、光照、缩放尺寸等条件,对设备图像进行样本繁殖,为每一个样本图像标注设备类别,将覆盖所有类别的带有标注的样本数据集合制作完成,数据将被输入深度学习的神经网络框架用于训练生成设备目标检测的网络模型;
s2、配置巡检机器人设备检测点预置位,为每一个目标设备在地图中配置观测点坐标,不再为目标设备配置模板图像;
s3、机器人在执行巡检任务过程中,按照预设的地图坐标停车,读取该观测点的姿态与相机参数,采集包含该目标设备的广角图像;
s4、将采集的巡检图像输入目标检测网络模型,按照该点的设备类别在图像中检测目标区域,如图像中存在目标设备,则计算目标区域轮廓最小外接矩形,完成目标定位工作;如果在图像中没有检测到目标设备,则将结果反馈给机器人姿态控制模块,首先校验机器人停车位置误差,通过再次加载姿态参数后采集全景图像以确保目标设备被包含其中,重新执行步骤s4;
s5、计算被检测出的目标区域外接矩形中心位置在图像中的坐标,并计算该点到图像中心位置的水平像素偏移量与垂直像素偏移量;
s6、根据相机的成像原理计算像距与焦距的正切比例,将图像像素偏移量换算为云台转动角度补偿量,并将该角度转换为云台转动控制参数,调用云台转动,将目标设备置于图像视野的中心;
s7、用巡检图像的分辨率与步骤4检测出的设备区域外接矩形的长宽像素数,求得合适的倍率,并且在相机焦距倍率的变化范围之内调用相机调整焦距,使目标设备居于巡检图像的中心并且充满合适的空间,以便识别设备工作状态的细节;
s8、观测点的机器人视觉伺服功能调用完成,采集设备图像,识别工作状态,完成一个设备的巡检检测任务。
优选地,所述s1具有普适性,其产生的目标检测网络模型可以被多个不同巡检场景的机器人所共享加载,并不只针对某一巡检场景所特制。
优选地,所述s1中样本图像不限于机器人的巡检场景,互联网中的同类图像资源可以被利用。
优选地,所述s1中样本图像繁殖的方法包括:在限定的偏转角度范围内繁衍三维不同角度仿射变换的样本图像;在限定的图像亮度变化范围内繁衍亮度不同的样本图像;在限定的缩放尺寸范围内繁衍具有缩放比例差异的样本图像;在图像噪音允许的范围内繁衍叠加多种噪音的样本图像。
优选地,所述s1中样本数据包括待处理图像、目标位置及类别信息。
优选地,所述s2中观测点坐标为机器人云台旋转角度参数和采集图像适用的相机参数。
本发明实现了将深度学习算法部署在巡检机器人的视觉模块,用以在采集的实时全景图像中实现目标设备定位,在此基础上计算与视野中心的角度偏差,进行云台角度的精准调用,有效的解决了过往方法中对机器人采集图像的限制并导致视觉伺服功能失误造成的机器人巡检任务差错的问题,解放了大量人工配置工作,提高了机器人巡检工作的效率与质量。
本发明实现了将深度学习的算法应用于巡检机器人,使机器人更加智能化的对视觉采集的图像进行目标检测定位,提高了巡检机器人采集设备图像的准确度,另外采用先进的基于深度学习目标检测的算法在广角或全景图像中对目标设备进行定位,对采集图像中的目标检测成功率较之前方法显著提高,经视觉伺服功能执行后的采集图像准确率可以在99.5%以上,并且使机器人能够远距离大焦距下观测目标设备运行状态细节,实现了巡检机器人对多种环境、多种设备全覆盖进行观测的目标。
本发明在机器人图像配置阶段与巡检任务执行阶段都具有自主决策能力,提高了智能化水平,解放了后台操作人员繁琐的工作,节省了人工劳动资源,器人可携带可见光及红外摄像机应用本发明描述的视觉伺服功能,在本发明实施之后实现了机器人可以执行24小时全天候多场景的设备巡检任务,保障设备安全运行。
附图说明
图1为本发明中训练用于目标设备检测的深度学习网络模型图;
图2为本发明中巡检机器人应用在执行巡检任务时视觉伺服功能的流程图;
图3为本发明中步骤6中所涉及的目标设备偏离图像中心角度计算示意图图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
参照图1-3,一种基于目标检测的巡检机器人视觉伺服方法,包括以下步骤:
s1、采集与制作每一个类型设备的样本图像,但样本图像不限于机器人的巡检场景,互联网中的同类图像资源可以被利用。由于同一类型的设备可以在场景中多个位置存在,机器人巡检时观测的角度、光照、缩放尺寸等条件各不相同,因此需要对设备图像进行样本繁殖。样本图像繁殖的方法可以包括:在限定的偏转角度范围内繁衍三维不同角度仿射变换的样本图像;在限定的图像亮度变化范围内繁衍亮度不同的样本图像;在限定的缩放尺寸范围内繁衍具有缩放比例差异的样本图像;在图像噪音允许的范围内繁衍叠加多种噪音的样本图像。为每一个样本图像标注设备类别,这样覆盖了所有类别的带有标注的样本数据集合就制作完成了,样本数据包括待处理图像、目标位置及类别信息。数据将被输入深度学习的神经网络框架用于训练生成设备目标检测的网络模型;
s2、配置巡检机器人设备检测点预置位,为每一个目标设备在地图中配置观测点坐标,机器人云台旋转角度参数,采集图像适用的相机参数等,不再为目标设备配置模板图像;
s3、机器人在执行巡检任务过程中,按照预设的地图坐标停车,读取该观测点的姿态与相机参数,采集包含该目标设备的广角图像;
s4、将采集的巡检图像输入目标检测网络模型,按照该点的设备类别在图像中检测目标区域,如图像中存在目标设备,则计算目标区域轮廓最小外接矩形,完成目标定位工作;如果在图像中没有检测到目标设备,则将结果反馈给机器人姿态控制模块,首先校验机器人停车位置误差,通过再次加载姿态参数后采集全景图像以确保目标设备被包含其中,重新执行步骤s4;
s5、计算被检测出的目标区域外接矩形中心位置在图像中的坐标,并计算该点到图像中心位置的水平像素偏移量与垂直像素偏移量;
s6、根据相机的成像原理计算像距与焦距的正切比例,将图像像素偏移量换算为云台转动角度补偿量,并将该角度转换为云台转动控制参数,调用云台转动,将目标设备置于图像视野的中心;
s7、用巡检图像的分辨率与步骤4检测出的设备区域外接矩形的长宽像素数,求得合适的倍率,并且在相机焦距倍率的变化范围之内调用相机调整焦距,使目标设备居于巡检图像的中心并且充满合适的空间,以便识别设备工作状态的细节;
s8、观测点的机器人视觉伺服功能调用完成,采集设备图像,识别工作状态,完成一个设备的巡检检测任务。
步骤s5中的目标设备最小外接矩形中心坐标与图像中心点的像素位移偏差计算公式为:
pixofs(h,v)=cdev-cimg公式(1)
其中,pixofs(pixeloffset)表示为以像素为单位的偏移距离,(h)为水平方向,(v)为垂直方向;cdev(centerofdevice)表示为由目标检测算法标定出的设备区域最小外接矩形中心在图像中的坐标;cimg(centerofimage)表示为所采集图像的中心位置坐标。
步骤s6中,根据相机的成像原理像距与焦距的正切比例,计算目标设备区域中心偏离图像中心的角度,其计算公式为:
其中,
solofs(h,v)=pixofs(h,v)×solution公式(3)
angofs(angleoffset)表示为目标设备区域中心与图像中心之间的夹角,并将此角度分解为水平方向(h)夹角与垂直方向(v)夹角;solofs(solutionoffset)表示为像素偏移量在成像元器件上的物理偏移量;soluton表示为每一个像素在成像元器件上所占的实际距离;fnow为采集图像时所设置的相机焦距。
步骤s7中,在云台调整步骤6计算的补偿角度之后,目标设备位居图像视野的中心位置,由于用于视觉伺服修正云台角度的图像采用相机的广角端焦距拍摄,目标设备在图像中所占的区域过小以至于不能直接用于状态识别流程。在本步骤中需要计算合适的放大倍率,使得目标设备在图像中面积占比得当可更有利于进行模式识别算法。计算公式如下:
其中,rt表示为相机可调整的倍率,它的取值为三个参考值中的最小值。三个参考值分别为:图像高度(heightofimage)与目标设备区域最小外接矩形高度(heightofdevice)的比值;图像宽度wimg(widthofimage)与目标设备区域最小外接矩形宽度(widthofdevice)的比值;相机最大焦距fmax与当前焦距的比值。获得可放大倍率之后,则根据目标倍率调整相机焦距,计算公式如下:
fnext=fnow×rt公式(5)
其中,fnext表示为即将设置的相机焦距。
通过将焦距放大,目标设备在相机视野中可以居中并且以最大可视化效果进行图像采集,为后续的工作状态识别功能提供了优质的图像条件,通过深度学习目标检测的方法定位设备区域;通过对设备区域中心与图像中心夹角的计算,移动云台将目标设备置于相机视野中心位置;放大相机焦距适当的倍率,可采集目标设备清晰图像用于模式识别。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!