一种仿人机器人的踢球动作生成系统及方法与流程
本发明属于机器人技术领域,更具体的说是涉及一种仿人机器人的踢球动作生成系统及方法。
背景技术:
足球有“世界第一运动”的美誉,是最具影响力的单项体育运动。让机器人像人一样踢足球,并最终战胜人类足球队,已作为机器人世界杯(robocup)赛事的实际目标。尽管机器人个体在足球赛中的角色实时可变,但如同人类足球运动员一样,处于进攻阶段且处于控球状态的队员最受瞩目,其对球的处理对于比赛态势具有直接影响,并能有效反映出该球员所具有的技战术能力。对处于进攻阶段且处于控球状态的机器人而言,需要解决的问题包括“球在哪?”、“往哪踢?”、“如何踢?”。
因此,如何提供一种仿人机器人的踢球动作生成系统及方法是本领域技术人员亟需解决的问题。
技术实现要素:
有鉴于此,本发明提供了一种仿人机器人的踢球动作生成系统及方法,以实现反应更为迅速敏捷且准确的踢球动作生成为目标,可快速、准确地识别足球方位和生成踢球动作,并适于在不同实际规格的仿人机器人系统中推广使用。
为了实现上述目的,本发明采用如下技术方案:
一种仿人机器人的踢球动作生成系统,包括足球方位识别训练子系统、足球方位实时测量子系统、目标方位实时获取子系统、踢球动作轨迹规划子系统和踢球动作执行子系统;
所述足球方位识别训练子系统,用于在已知足球与仿人机器人间相对位置及相对方向的条件下,依据仿人机器人中的视觉系统所获取的图像信息,构建所述相对位置及相对方向与所述图像信息间关联关系的足球方位数学模型;
所述足球方位实时测量子系统,用于依据已经构建得到的所述足球方位数学模型,以及仿人机器人中的视觉系统所获取的图像信息,实时计算获得足球与仿人机器人间的相对位置及相对方向,将其记录为足球方位;
所述目标方位实时获取子系统,用于通过直接指定目标方位,或通过自主识别球门方位,或通过自主规划传球方位的方式,在线计算获得踢碰足球后,所期望足球能够到达的与仿人机器人间的相对位置及相对方向,将其记录为目标方位;
所述踢球动作轨迹规划子系统,用于依据当前获得的所述足球方位与所述目标方位,规划适用于所述仿人机器人的踢球动作,将其记录为踢球动作轨迹;
所述踢球动作执行子系统,用于依据当前所获得的所述踢球动作轨迹,令所述仿人机器人执行踢球动作。
优选的,所述足球,是指球形的可滚动物体,且其在球场中的数量为1;所述足球与仿人机器人间的相对位置,是指足球的球心与仿人机器人间的相对位置;所述足球与仿人机器人间的相对方向,是指足球的球心与仿人机器人间的相对方向;
所述球场,由足球场地区域、球门、场地标记组成,所述场地标记包含实体边界、颜色标线、颜色区域、信息显示板、不可见的电子标记;
所述踢球动作,指所述仿人机器人为了将所述足球由所述足球方位撞击到所述目标方位,而所需要进行的一系列身体动作。
优选的,所述仿人机器人,具有用于获取场景图像的视觉系统,且所述视觉系统具有观测角度的调节能力;
所述仿人机器人,其双腿各具有不少于6个运动自由度,位于腿部末端的足部为具有一定形状的硬质结构;
所述仿人机器人具有机器人方位坐标系,所述机器人方位坐标系的原点位于所述仿人机器人身体腰部中心位置在地面的投影点,所述机器人方位坐标系的x轴正向指向所述仿人机器人身体正前方朝向,所述机器人方位坐标系的z轴正向指向重力的反方向。
优选的,所述视觉系统,通过调节所述仿人机器人的部分身体关节和/或通过调节视觉系统自身设置,来实现包括俯仰方向和偏航方向在内的观测角度的调节能力。
一种仿人机器人的踢球动作生成方法,包含如下步骤:
步骤s1,对足球方位识别训练子系统进行识别训练,获得所述足球方位数学模型;
步骤s2,视觉系统获取当前场景图像,将图像信息输入足球方位实时测量子系统,获得足球方位;
步骤s3,目标方位实时获取子系统获得目标方位;
步骤s4,踢球动作轨迹规划子系统获得踢球动作轨迹;
步骤s5,踢球动作执行子系统执行踢球动作;
所述步骤s1为训练阶段,在非踢球状态下预先执行一次即可;
所述步骤s2-步骤s5为踢球阶段,在踢球状态下重复执行。
优选的,所述步骤s1中对所述足球方位识别训练子系统进行识别训练的过程为:
步骤s11,调节所述仿人机器人的姿态使得视觉系统与地面间的距离为h;调节视觉系统的俯仰方向观测角,使得视觉系统前向方向在所述机器人方位坐标系x-z平面中的投影与x轴间的转角为θ_pitch;调节视觉系统的偏航方向观测角,并使得视觉系统前向方向在所述机器人方位坐标系x-y平面中的投影与x轴间的转角为θ_yaw;
步骤s12,令所述仿人机器人的当前位置与姿态保持不变,在所述视觉系统的可见范围内,设置一组分布的标记点,测量并记录各标记点与仿人机器人间的相对位置及相对方向;
步骤s13,将足球依次放置在步骤s12中所述的各标记点所在位置,对于每一个位置均令视觉系统采集图像,进而对图像进行处理以获得足球球心位置在该图像中的像素坐标,记录当前h、θ_pitch、θ_yaw的数据、标记点所在位置数据与图像中相应的像素坐标数据;
步骤s14,返回步骤s11并分别调整h、θ_pitch、θ_yaw的数值,重复执行步骤s12-步骤s13;
步骤s15,建立一个包括输入层、隐藏层、输出层在内的神经网络;
步骤s16,将步骤s13记录的数据分为训练集和测试集,并以此训练步骤s15中的神经网络,训练完毕所得到的神经网络,构建了在已知h、θ_pitch、θ_yaw数值的条件下,所述足球方位与足球图像像素坐标间的映射关系,即所述足球方位数学模型。
优选的,所述步骤s15中所建立的神经网络,其输入层与隐藏层的前向传播模型为yl=f(ul)=f(wlyl-1+bl),其中f(·)为relu激活函数,wl和bl分别为第l层中待优化的权重和偏置矩阵,yl为第l层的输出;其输出层的前向传播模型为yl=ul=wlyl-1+bl;损失函数采用均方误差
优选的,所述步骤s14并非必须,若跳过步骤s14,则所述h、θ_pitch、θ_yaw的数值均唯一。
优选的,所述步骤s2中所述足球方位实时测量子系统获得足球方位的过程为:
对所述视觉系统所获取的图像信息进行处理,检测该图像中足球的位置,获取足球球心位置在该图像中的像素坐标;将获得的所述像素坐标,以及所述仿人机器人当前h、θ_pitch、θ_yaw的数值共同输入至所述足球方位数学模型,求解并输出足球方位。
优选的,所述步骤s4中所述踢球动作轨迹规划子系统获得踢球动作轨迹的过程为:
步骤s41,预先获取或测量所述仿人机器人足部的边界轮廓形状,使用曲线拟合方法获取得到所述足部边界轮廓的拟合函数,记为足部轮廓boundaryx(y),对足部轮廓boundaryx(y)求导得到
步骤s42,依据所述足球方位、所述目标方位、所述仿人机器人的双腿的当前位置与支撑状态,合理地选择踢球腿;
步骤s43,由所述足球方位中的相对位置pb=[pbx,pby,pbz]t和所述目标方位中的相对位置pt=[ptx,pty,ptz]t,计算踢球方向
步骤s44,以所述仿人机器人足部的踢球点位置的轮廓法线方向和踢球方向θ_kick相同为原则,令
步骤s45,使用多项式拟合方法获得所述仿人机器人足部的踢球点pr的踢球动作轨迹,所述踢球动作轨迹需经过所述足球上的踢触点pk。
本发明的有益效果在于:
(1)在机器人仅具有视觉系统的条件下即可完成球体识别训练和实战过程检测,训练过程简单,使用可靠。
(2)易于编程实现,适合于作为进攻型机器人射门动作生成、传球动作生成等机器人足球赛中主要进攻行为的基础算法;且模块划分清晰,既可根据需要对单一模块进行功能优化,也适合于将算法向更高层机器人足球控制框架中集成。
(3)踢球动作反应敏捷,为机器人球员提供了一种实现快速反应的途径。
(4)计算快速,对硬件要求低,适合于在经济型、教学型及竞赛专用型的仿人机器人产品中应用和推广。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1附图是本发明提供的一种机器人踢足球的场景示意图。
图2附图是本发明提供的一种仿人机器人的结构及踢球动作轨迹示意图。
图3附图是本发明提供的一种仿人机器人的踢球动作生成系统的示意图。
图4附图是本发明提供的一种足球方位识别训练子系统的训练场景示意图。
图5附图是本发明提供的一种足球方位识别训练子系统的训练流程图。
图6附图是本发明提供的一种踢球动作轨迹规划子系统的运行流程图。
图7附图是本发明提供的一种踢球动作轨迹规划子系统的方法示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
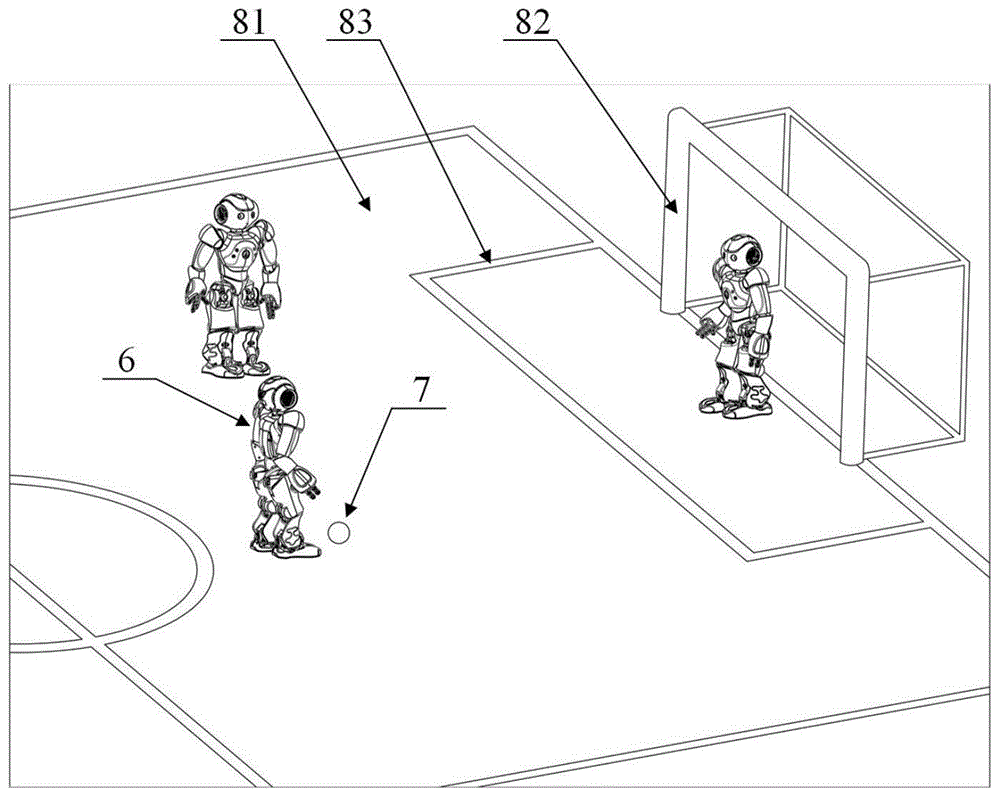
如图1所示,在机器人踢足球的场景中,包括若干台具有进行足球比赛能力的仿人机器人、足球7、球场;其中,球场由足球场地区域81、球门82、场地标记83组成,场地标记83包含实体边界、颜色标线、颜色区域、信息显示板、不可见的电子标记。在若干台具有进行足球比赛能力的仿人机器人中,处于进攻阶段且处于控球状态的机器人被标记为仿人机器人6;足球7,是指球形的可滚动物体,且其在球场中的数量为1;足球7与仿人机器人6间的相对位置,是指足球7的球心与仿人机器人6间的相对位置;足球7与仿人机器人6间的相对方向,是指足球7的球心与仿人机器人6间的相对方向。
如图2所示,仿人机器人6,具体形式可以为1台nao机器人,其具有用于获取场景图像的视觉系统61,且视觉系统61具有观测角度的调节能力,该观测角度是相对于固定的大地坐标系而言,通常包括偏航角、俯仰角、滚动角。视觉系统61,通过调节仿人机器人6的部分身体关节和/或通过调节视觉系统61自身设置,来实现包括俯仰方向和偏航方向在内的观测角度的调节能力。例如既可以通过调节腰部或脖颈部位的运动关节,来间接调整头部以及位于头部的视觉系统61的俯仰角,也可以通过调节视觉系统61内置的摄像头参数来调整俯仰方向的视角。
仿人机器人6的双腿各具有不少于6个运动自由度,以实现仿人类踢球动作所需的灵活运动能力,位于腿部末端的足部62为具有一定形状的硬质结构。仿人机器人6的踢球动作,指仿人机器人6为了将足球7由足球方位91撞击到目标方位92,而所需要进行的一系列身体动作。
仿人机器人6具有机器人方位坐标系97,机器人方位坐标系97的原点位于仿人机器人6的身体腰部中心位置在地面的投影点,机器人方位坐标系97的x轴正向指向仿人机器人6的身体正前方朝向,机器人方位坐标系97的z轴正向指向重力的反方向。
如图3所示,仿人机器人的踢球动作生成系统,包括足球方位识别训练子系统1、足球方位实时测量子系统2、目标方位实时获取子系统3、踢球动作轨迹规划子系统4、踢球动作执行子系统5。
足球方位识别训练子系统1,用于在已知足球7与仿人机器人6间相对位置及相对方向的条件下,依据仿人机器人6中的视觉系统61所获取的图像信息,构建相对位置及相对方向与图像信息间关联关系的足球方位数学模型90。
足球方位实时测量子系统2,用于依据已经构建得到的足球方位数学模型90,以及仿人机器人6中的视觉系统61所获取的图像信息,实时计算获得足球7与仿人机器人6间的相对位置及相对方向,将其记录为足球方位91。
目标方位实时获取子系统3,用于通过直接指定目标方位,或通过自主识别球门82的方位,或通过自主规划传球方位的方式,在线计算获得踢碰足球7后,所期望足球7能够到达的与仿人机器人6间的相对位置及相对方向,将其记录为目标方位92。
踢球动作轨迹规划子系统4,用于依据当前获得的足球方位91与目标方位92,规划适用于仿人机器人6的踢球动作,将其记录为踢球动作轨迹93。
踢球动作执行子系统5,用于依据当前所获得的踢球动作轨迹93,令仿人机器人6执行踢球动作。
如图3所示,仿人机器人6的踢球动作生成系统的工作方法,包括如下步骤:
步骤s1,对足球方位识别训练子系统1进行识别训练,获得足球方位数学模型90;
步骤s2,视觉系统61获取当前场景图像,将该图像信息输入足球方位实时测量子系统2,获得足球方位91;
步骤s3,目标方位实时获取子系统3获得目标方位92;
步骤s4,踢球动作轨迹规划子系统4获得踢球动作轨迹93;
步骤s5,踢球动作执行子系统5执行踢球动作。
步骤s1为训练阶段,在非踢球状态下预先执行一次即可。
步骤s2-步骤s5为踢球阶段,在踢球状态下重复执行。
如图4和图5所示,工作方法的步骤s1中,对足球方位识别训练子系统1进行识别训练的过程为:
步骤s11,调节仿人机器人6的姿态使得视觉系统61与地面间的距离为h;调节视觉系统61的俯仰方向观测角,使得视觉系统61的前向方向在机器人方位坐标系97的x-z平面中的投影611与x轴间的转角为θ_pitch;调节视觉系统61的偏航方向观测角,并使得视觉系统61的前向方向在机器人方位坐标系97的x-y平面中的投影612与x轴间的转角为θ_yaw。在图4(a)中,有x’轴平行于x轴,因此θ_pitch和θ_yaw均标注于x’轴旁。
步骤s12,令仿人机器人6的当前位置与姿态保持不变,在视觉系统61的可见范围内,设置一组分布的标记点94,测量并记录各标记点94与仿人机器人6间的相对位置941及相对方向。
步骤s13,将足球7依次放置在步骤s12中的各标记点94所在位置,对于每一个位置均令视觉系统61采集图像,进而对图像进行处理以获得足球7的球心位置在该图像中的像素坐标95。记录当前h、θ_pitch、θ_yaw的数据、标记点94所在位置941数据与图像中相应的像素坐标95数据;如图4(a)所示,足球7当前所在的标记点94所在位置941数据为(x_ball,y_ball);图4(b)所示为视觉系统61采集得到的图像的示意图,像素坐标95的值为(x_pixel,y_pixel)。
步骤s14,返回步骤s11并分别调整h、θ_pitch、θ_yaw的数值,重复执行步骤s12-步骤s13。
步骤s15,建立一个包括输入层、隐藏层、输出层在内的神经网络96。
步骤s16,将步骤s13记录的数据分为训练集和测试集,并以此训练步骤s15中的神经网络96,训练完毕所得到的神经网络96,构建了在已知h、θ_pitch、θ_yaw数值的条件下,足球方位91与足球图像像素坐标95间的映射关系,即足球方位数学模型90。如图4所示,足球方位数学模型90即(x_ball,y_ball)与(x_pixel,y_pixel)的相互映射关系。
步骤s15中所建立的神经网络96,其输入层与隐藏层的前向传播模型为yl=f(ul)=f(wlyl-1+bl),其中f(·)为relu激活函数,wl和bl分别为第l层中待优化的权重和偏置矩阵,yl为第l层的输出;其输出层的前向传播模型为yl=ul=wlyl-1+bl;损失函数采用均方误差
步骤s14并非必须,若跳过步骤s14,则h、θ_pitch、θ_yaw的数值均唯一。
工作方法的步骤s2中,足球方位实时测量子系统2获得足球方位91的过程为:对视觉系统61所获取的图像信息进行处理,检测该图像中足球7的位置,获取足球7的球心位置在该图像中的像素坐标95;将获得的像素坐标95,以及仿人机器人6当前h、θ_pitch、θ_yaw的数值共同输入至足球方位数学模型90,求解并输出足球方位91。
如图6和图7所示,工作方法的步骤s4中踢球动作轨迹规划子系统4获得踢球动作轨迹93的过程为:
步骤s41,预先获取或测量仿人机器人6的足部边界轮廓,使用曲线拟合方法获取得到足部边界轮廓的拟合函数,记为足部轮廓boundaryx(y),对足部轮廓boundaryx(y)求导得到
步骤s42,依据足球方位91、目标方位92、仿人机器人6的双腿的当前位置与支撑状态,合理地选择踢球腿。
步骤s43,由足球方位91中的相对位置pb=[pbx,pby,pbz]t和目标方位92中的相对位置pt=[ptx,pty,ptz]t,计算踢球方向
步骤s44,以仿人机器人6足部的踢球点位置的轮廓法线方向和踢球方向θ_kick相同为原则,令
步骤s45,使用多项式拟合方法获得仿人机器人6足部的踢球点pr的踢球动作轨迹93,踢球动作轨迹93需经过足球7上的踢触点pk。进一步,以踢触点pk为边界,可将踢球动作轨迹93分为2段,分别为q1(t)=a10+a11t+a12t2+a13t3和q2(t)=a20+a21t+a22t2+a23t3,且q1(t)和q2(t)在踢触点pk相交。
本发明以实现反应更为迅速敏捷且准确的踢球动作生成为目标,可快速、准确地识别足球方位和生成踢球动作,并适于在不同实际规格的仿人机器人系统中推广使用。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!