基于改进DQN算法的茶叶采摘机械手路径规划
基于改进dqn算法的茶叶采摘机械手路径规划
技术领域
1.本发明涉及路径规划技术领域,具体涉及是基于改进dqn算法的茶叶采摘机械手路径规划。
背景技术:
2.茶叶类型较多,由于我国地域的气候环境复杂,茶叶种植方式较多,所以茶叶的形态特征各异,其中名优茶作为茶叶中的优品,其形态可将茶叶分为单芽、单芽单叶、单芽双叶、单芽三叶,茶叶采摘需要根据茶叶特征进行采摘,名优茶的采摘形式较多,采摘形式主要包括人工采摘、半自动采摘、全自动采摘等方式,其中依靠全自动采摘设备的智能采摘方式效率较高,但是在实际运用过程中也存在采摘精度、嫩芽识别误差大等问题。
技术实现要素:
3.本发明针对以上问题,提供基于改进dqn算法的茶叶采摘机械手路径规划。
4.采用的技术方案是,基于改进dqn算法的茶叶采摘机械手路径规划,其中包括以下步骤:s1.建立茶叶采摘机械手的目标函数;s2.建立茶叶采摘机械手的q值网络模型;s3.设置茶叶采摘机械手与环境交互的经验回收;s4.设置奖励函数作用q值网络模型;s5.通过仿真规划茶叶采摘机械手运动路径规划。
5.可选的,s1中,茶叶采摘机械手为三自由度的机械手。
6.进一步的,s1中,目标函数通过q-learing构建得到,利用公式1得到茶叶采摘机械手的更新后的动作值和状态值:
ꢀꢀꢀꢀꢀ
(公式1) 其中(s,a)表示当前的状态和动作值,表示下一步的状态和动作值,而表示更新后的状态值,当运动到s状态时则可以得到奖励值r,然后对其进行评估计算。
7.可选的,s1中,对于目标状态—动作值函数可以利用贝尔曼方程表示如公式2所示:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式2)。
8.进一步的,s1中,由此损失函数的均方差损失函数表达式如式3所示,ω为神经网络结构的权值参数:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式3)。
9.可选的,s2中,通过梯度下降法获得公式4,其中利用目标网络和预测网络评估当前状态-动态值函数,目标网络基于神经网络得到目标q值,利用当前目标q值估计下一时刻的目标q值,预测网络则可以使用随机梯度下降法,不断更新网络参数,实现端到端的学习
控制:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式4)。
10.进一步的,s3中,机器人和环境交互时,可获得样本数据,把样本数据存储到建立的经验池中,从经验池中随机抽取小部分数据用于训练样本,再将训练样本送入神经网络中训练。
11.可选的,s4中,奖励函数中包含茶叶采摘机械手根据切割点到采摘点的空间位置距离、运动的速度、角速度。
12.可选的,s4中,奖励函数的表达式如下:
ꢀꢀ
(公式5)其中表示当前速度、角速度和距离误差值状态变化函数。
13.进一步的,s5中,基于ros系统中的gazebo平台,搭建茶叶采摘机械手的运动模型,通过算法结构调整控制参数,进行茶叶采摘机械手运动路径规划。
14.本发明的有益效果至少包括以下之一;1、根据图像识别技术实现采摘对象的嫩芽识别以及位置空间的确定,然后利用改进型的深度强化学习算法进行强化训练,实现对采摘路径的规划,达到提高采摘效率的目的。
15.2、通过设置的包含速度、角速度、距离误差等参数作为主要的参考值,基于深度强化学习建立的奖励函数,使其在路径探索过程中具有导向性,减小探索时间,提高路径的优化效率。
16.3、通过仿真结果验证得到,改进dqn算法能够在传统dqn算法基础上实现对采摘路径规划效率的提高,同时对采摘路径中的障碍进行避让,实现对嫩芽叶茎位的准确切割,提高了茶叶的采摘效率。
附图说明
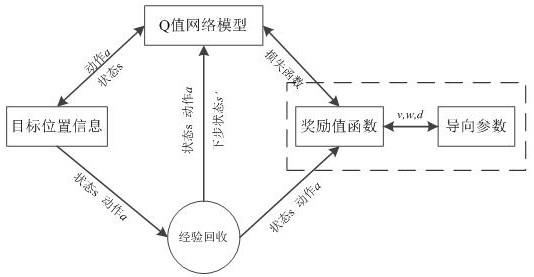
17.图1为机械手工作模型图;图2为三自由度机械手运动空间范围图;图3为现有dqn算法模型图;图4为改进dqn算法模型图;图5为茶树外形特征模型图;图6为奖励值变化图;图7为训练次数与采摘点距离变化关系图;图8为损失函数的对比效果图。
具体实施方式
18.为了使本发明的目的、技术方案及优点能够更加清晰明白,以下结合实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明保护内容。
19.在本发明的描述中,需要说明的是,可能使用到的术语
ꢀ“
上”、“下”等指示的方位或位置关系为基于所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是
指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制;可能使用到的术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性,此外,除非另有明确的规定和限定,可能使用到的术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
20.基于改进dqn算法的茶叶采摘机械手路径规划,其中包括以下步骤:s1.建立茶叶采摘机械手的目标函数;s2.建立茶叶采摘机械手的q值网络模型;s3.设置茶叶采摘机械手与环境交互的经验回收;s4.设置奖励函数作用q值网络模型;s5.通过仿真规划茶叶采摘机械手运动路径规划。
21.这样设计的目的在于,根据图像识别技术实现采摘对象的嫩芽识别以及位置空间的确定,然后利用改进型的深度强化学习算法进行强化训练,实现对采摘路径的规划,达到提高采摘效率的目的,通过设置的包含速度、角速度、距离误差等参数作为主要的参考值,基于深度强化学习建立的奖励函数,使其在路径探索过程中具有导向性,减小探索时间,提高路径的优化效率,通过仿真结果验证得到,改进dqn算法能够在传统dqn算法基础上实现对采摘路径规划效率的提高,同时对采摘路径中的障碍进行避让,实现对嫩芽叶茎位的准确切割,提高了茶叶的采摘效率。
22.在具体实施时,如图1所示,机械手工作模型图中机械手 主要组成部分包括两个机械手臂、一个旋转机械切割爪,通过联动控制可以实现切割爪的抓取,其中根据每个自由度旋转点建立了局部坐标系分别为x
a-y
a-za、x
b-y
b-zb、x
c-y
c-zc、x
d-y
d-zd,便于空间坐标系运动点的表示。机械手基座在空间运动坐标表示则是基于全局坐标系x-y-z。坐标系x
a-y
a-za通过控制za轴旋转可使得手臂在x
a-ya平面旋转运动,旋转o
b-xb轴,可实现o
b-oc手臂在z
b-yb平面运动,再旋转o
c-xc使得o
c-od在y
c-zc平面运动,最后通过对o
d-zd轴的运动控制即可得到切割爪在x
d-o
d-yd平面上做旋转运动,三自由度机械手的运动控制需要符合采摘机械手的运动特点,同时由于机械手的运动空间范围有限,所以对机械手的运动极限空间进行分析,根据如图2所示为三自由度机械手运动空间范围图,机械切割手爪的旋转直径为φd,虚线内的运动空间为机械手的活动空间,所以采摘过程需要满足机械手运动空间覆盖嫩芽的采摘范围。
23.机械手联动控制主要是基于图像识别的嫩芽采摘点,从而带动机械手的联动控制,利用已知坐标点的变换带动多坐标系的位置变化。全局坐标系中令嫩芽采摘位置点的空间坐标位置为[x,y,z],机械手的固定基座在全局坐标系的空间坐标为a[xa,ya.za],已知oa-ob轴的距离为l
ab
,ob-oc轴的距离为l
bc
,oc-od轴的距离为l
cd
,采摘切割点到od原点的距离为l,所以采摘点在末端坐标系x
d-y
d-zd中坐标值为n[xd,yd,-l]。
[0024]
全局坐标系需要对于局部坐标系进行空间转换,所以{d}坐标系通过{c}、{b}、{a}坐标系的转换实现采摘点坐标在全局坐标中的位置确定,通过公式6可得坐标系的连续转换关系。
[0025]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式6)机械手的固定基座在全局坐标中的位置坐标。坐标系之间的转换,主要分为平移转换、旋转、复合旋转等方式,其中oa坐标系转换到ob坐标系为的方式为平移转换,如公式7所示。
[0026]
ꢀꢀꢀꢀꢀꢀꢀ
(公式7)坐标系ob到坐标系oc之间的转换关系为y轴方向的位置变化,即可得到ob坐标系在oc坐标系中的坐标转换,如公式8所示。
[0027]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式8)d坐标系与c坐标系之间的转换过程不仅需要平移,还需要按照o
c-xc轴旋转才能实现坐标转换,其中r表示为旋转矩阵,通过转换可转换坐标,如公式9所示。
[0028]
ꢀꢀꢀꢀꢀꢀꢀꢀ
(公式9)最后通过坐标系的计算转换可以得到,采摘切割点在全局坐标系中空间坐标位置点。
[0029]
如图2所示,机械手运动控制主要是通过控制关节电机的运动,多自由度机械手则需要联动控制每个电机的运动位移和速度,并需要对机械手进行运动学分析,如式10所示的转换矩阵计算公式可以得到相邻转动关节的转换矩阵,其中i=1,2,3,4,s表示正弦函数,c表示余弦函数,di表示机械臂的长度,表示绕zi轴,从x
i-1
旋转到xi的角度,表示绕xi轴,从zi旋转到z
i+1
的角度。
[0030]
ꢀꢀꢀꢀꢀꢀꢀ
(公式10)利用转换矩阵的乘积可以计算机械手的运动学方程,通过转换矩阵可以得到坐标系{d}的位姿相对于全局坐标系中位姿如式11所示。
[0031]
ꢀꢀꢀꢀꢀꢀꢀ
(公式11)如图3所示,目前深度强化学习(deep q-learing,简称dqn)不仅结合深度学习在环境信息的感知能力而且还对强化学习的决策能力进行融合,生产了类似于人类思维方式的学习能力,根据识别对象的特征提出决策策略。dqn学习算法用于环境复杂、干扰因素多的茶叶采摘技术具有很大的优势:目标函数通过q-learing构建得到,利用公式1得到茶叶采摘机械手的更新后的动作值和状态值:
ꢀꢀꢀꢀꢀꢀꢀ
(公式1) 其中(s,a)表示当前的状态和动作值,表示下一步的状态和动作值,而表示更新后的状态值,当运动到s状态时则可以得到奖励值r,然后对其进行评估计算。
[0032]
对于目标状态—动作值函数可以利用贝尔曼方程表示如公式2所示:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式2)由此损失函数的均方差损失函数表达式如式3所示,ω为神经网络结构的权值参数:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式3)通过梯度下降法获得公式4,其中利用目标网络和预测网络评估当前状态-动态值函数,目标网络基于神经网络得到目标q值,利用当前目标q值估计下一时刻的目标q值,预测网络则可以使用随机梯度下降法,不断更新网络参数,实现端到端的学习控制:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式4)机器人和环境交互时,可获得样本数据,把样本数据存储到建立的经验池中,从经验池中随机抽取小部分数据用于训练样本,再将训练样本送入神经网络中训练。
[0033]
如图4所示,在dqn的基础上进行了改进,dqn在运动控制过程中,通过智能体和环境的交互利用奖励值函数,实现采摘过程的训练,得到优化的采摘路径。运动过程中从当前状态值到下个状态值分配的奖励值不同,则会影响训练的收敛速度和程度,茶叶采摘过程需要满足嫩芽实时性、准确性的采摘要求,故以准确识别采摘位置为目标,设计具有明确导向性的奖励值函数,通过强化学习得到最优动作策略,在训练过程中碰到阻挡物时即返回起始点,往复训练不断探索最优采摘路径。
[0034]
改进的奖励函数是根据切割点到采摘点的空间位置距离、运动的速度、角速度来实现奖惩机制的导向,同时由于强化学习在学习开始阶段可能出现全是负面学习,导致学习进度较慢,也会出现全是积极学习,导致学习过程不全面,所以奖励值函数从中间难度点开始学习,能够更加全面的掌握学习过程,所以改进后的奖励值函数表达式如式5所示。
[0035]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式5)其中r(v,w,e)表示当前速度、角速度和距离误差值状态变化函数,通过状态的变化可以得到具有明显导向性的奖励函数,趋近于目标状态时,奖励值就大,利用对数函数可以较高的趋向性,不同情况得到的奖励值不同,越趋近于目标状态,奖励值越大,反之越远或遇到障碍物则惩罚值越大。
[0036]
在进行仿真时,主要基于ros(robot operation system)系统中的gazebo平台,并搭建采摘机械手的运动模型,利用算法结构调整控制参数,实现采摘机械手运动路径规划。
[0037]
采摘机械手在进行茶叶采摘过程中需要根据茶树的外形特征进行环境适应判断,由于嫩芽的生长区域在茶树的顶端,所以茶树的外形特征对于采摘机械手的采摘路径设计有较大影响,根据常见茶树特征分析,茶树的基本外形特征如图5所示,茶叶采摘区域的高度为h,有效高度范围主要集中在h1和h2之间,茶树宽度在b1内。
[0038]
在仿真平台中机械手与运动路径轨迹,实验仿真平台的搭建主要模拟实际茶叶采摘环境,采摘机械手移动平台的运动效率是根据茶树的种植布局环境和地势特征决定,同时根据茶叶采摘的效率和速度进行实时调整。采摘机械手进行强化训练,随着训练次数的增加可以得到优化的路径,当训练得到最优运动路径则训练结束。
[0039]
根据dqn算法的原理可知,训练过程主要利用具有导向性的奖励函数实现对采摘路径的探索,为保证强化训练的效率,需对训练参数进行设置如表1所示。
[0040]
表1 训练参数设置通过训练参数的设置可在gazebo平台上经过强化训练,采摘机械手末端采摘爪从初始位置到采摘点的运动过程,为避免采摘老叶和茎梗,并为提高采摘效率,采摘路径通过强化训练得到的优化的采摘运动路径,主要利用导向性的奖励函数,根据速度、角速度、切点的距离误差的导向可以高效的实现嫩芽采摘路径的规划。
[0041]
主要以采摘机械手末端上的采摘机械爪为参考点,利用机械臂的旋转,可以准确到达采摘区域,最后旋转末端采摘手爪实现老叶和茎梗的躲避,控制切割爪的运动实现切割功能,由此产生的采摘运动路径即为强化训练后的优化路径。
[0042]
最后如图6至图8所示,对实验数据进行分析,根据仿真实验得到采摘机械手经过强化训练可规划出采摘路径,评价训练过程中的效果则可以通过奖励函数值进行判断,通过对比改进dqn算法和传统dqn算法可以得训练次数与采摘机械手运动规划奖励值的变化关系如图8所示。在图8中,上方的曲线为“改进dqn算法”,下方曲线为“dqn算法”,根据奖励值的变化趋势可知,由于本实施例的奖励函数为了避免开始阶段的出现全是负面奖励和积
极奖励,从中位开始,开始阶段的奖励值较大,随着训练次数的增加不断奖励值不断趋近于平稳,由于在末端需要避免障碍物的阻挡所以在3000次到5000次的时候遇到末端障碍物时则会出现奖励值降低幅度较大的情况,3000次之前路径探索奖励值从高奖励值降低,当达到目标点时则出现增加并逐渐达到稳定的奖励值。
[0043]
根据分析仿真数据结果可知采摘机械手末端的切割爪在强化训练次数不断 增加的情况下,可探索规划出运动路径,为验证运动路径的可靠性,可通过采 摘机械手末端切割点与茶叶采摘点之间的距离变化关系,判断本实施例算法的 有效性,如图7所示为位置误差变化曲线关系。其中曲线从上至下分别代表“训 练1000次”、“训练2000次”、“训练3000次”、“训练4000次”和“训 练5000次”,本实施例主要对比分析训练在1000次至5000次的位置误差变化 关系,如图7所示可知,随着训练次数的增加,位置误差变化速度越快,最后 切割位精度误差在0.005m范围内。
[0044]
实验仿真结果显示损失函数的收敛性和波动性可以判断本实施例算法的有效性,实验对比关系如图8所示,其中位于上方的曲线为“dqn算法”,位于下方的曲线为“改进dqn算法”,本实施例对比分析改进型dqn算法和传统dqn算法,可得改进dqn算法的损失函数在训练1000次之前的波动性较大,但在1000次到2000次之间的波动性逐渐降低,2000次后则趋近于稳定;传统dqn算法的波动性在2000次之前都没有趋近于稳定,但是2000次后逐渐趋于稳定收敛,通过对比也可知,改进型的收敛速度更快。
[0045]
这样根据图像识别技术实现采摘对象的嫩芽识别以及位置空间的确定,然后利用改进型的深度强化学习算法进行强化训练,实现对采摘路径的规划,达到提高采摘效率的目的,通过设置的包含速度、角速度、距离误差等参数作为主要的参考值,基于深度强化学习建立的奖励函数,使其在路径探索过程中具有导向性,减小探索时间,提高路径的优化效率,通过仿真结果验证得到,改进dqn算法能够在传统dqn算法基础上实现对采摘路径规划效率的提高,同时对采摘路径中的障碍进行避让,实现对嫩芽叶茎位的准确切割,提高了茶叶的采摘效率。
[0046]
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本实施例所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本实施例所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1