机器人及其控制方法、装置、计算机设备和可读存储介质与流程
本发明涉及机器人,具体而言涉及一种机器人的控制方法、一种机器人的控制装置、一种机器人、一种计算机设备和一种可读存储介质。
背景技术:
1、相关技术中,具有语音控制的机器人,通常只能通过语音调用机器人按照编好的程序号进行执行,其无法做到对环境的感知,只是被动的执行编辑好的动作,进而在生产过程中,需要不断的修改程序,以适应不同的工况环境,从而影响生产效率。
技术实现思路
1、本发明旨在至少解决现有技术中存在的具有语音控制功能的机器人,只是被动的按照语音调用的一套程序,执行相应的动作,若改变动作需要重新编程,导致其效率较低的技术问题之一。
2、为此,本发明的第一方面提出了一种机器人的控制方法。
3、本发明的第二方面提出了一种机器人的控制装置。
4、本发明的第三方面提出了一种机器人。
5、本发明的第四方面提出了一种机器人。
6、本发明的第五方面提出了一种计算机设备。
7、本发明的第六方面提出了一种可读存储介质。
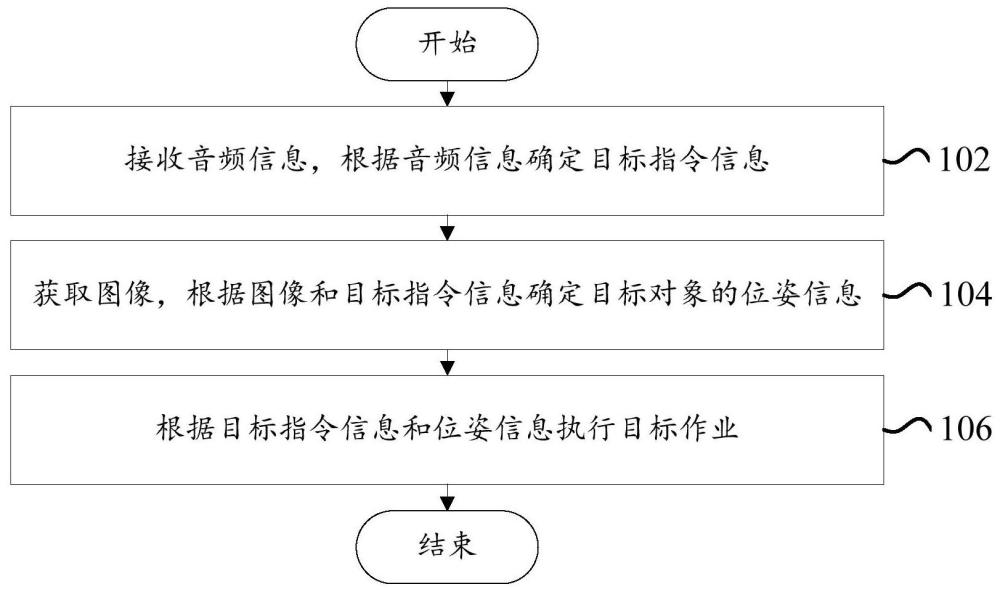
8、有鉴于此,根据本发明的第一方面,本发明提出了一种机器人的控制方法,包括:接收音频信息,根据音频信息确定目标指令信息;获取图像,根据图像和目标指令信息确定目标对象的位姿信息;根据目标指令信息和位姿信息执行目标作业。
9、本发明提出的机器人的控制方法,包括机器人接收音频信息,分析音频信息,得到目标指令信息,获取图像,分析图像并在图像中确定目标指令信息所对应的目标对象,从而确定目标对象的位姿信息,之后机器人根据位姿信息对目标对象执行目标作业,进而将语音控制和视觉功能结合,在实际使用中,只需通过语音下达命令,机器人可以自行识别目标对象,并对目标对象执行目标作业,无需频繁的修改编程,提升生产效率。
10、另外,根据本发明提供的上述技术方案中的机器人的控制方法,还可以具有如下附加技术特征:
11、在上述技术方案的基础上,进一步地,在执行目标作业的过程中,根据力反馈调整目标作业的动作。
12、在该技术方案中,在机器人根据位姿信息对目标对象执行目标作业的过程中,结合执行组件受到的力反馈,调整执行组件的动作,以准确的执行目标作业。
13、在上述任一技术方案的基础上,进一步地,接收音频信息,根据音频信息确定目标指令信息的步骤,具体包括:接收音频信息;提取音频信息中的多个语义词,根据多个语义词确定目标对象、目标目的和目标动作;根据目标对象、目标目的和目标动作确定目标指令信息。
14、在该技术方案中,机器人接收音频信息,分析音频信息,得到目标指令信息的步骤,具体包括:接收音频信息,提取音频信息中的语义词,并且,语义词具有多个,以实现对目标对象、目标目的和目标动作的确定,机器人要实现工作,需要有目标对象、目标目的和目标动作,将目标对象、目标目的和目标动作所对应的程序指令,组合成一段程序,该段程序为目标指令信息,进而机器人可以根据目标指令信息进行一系列的动作。
15、在上述任一技术方案的基础上,进一步地,基于目标对象、目标目的和目标动作中任一个具有多个的情况下,根据目标对象、目标目的和目标动作,按照音频信息中的顺利逻辑,确定目标指令信息。
16、在该技术方案中,目标对象、目标目的和目标动作中的任意一个都可以具有多个,而在目标对象、目标目的和目标动作中的至少一个具有多个时,需要对多个目标对象、多个目标目的或多个目标动作进行排序,以确保机器人可以顺利完成动作,进而提取音频信息中的顺利逻辑,以顺利逻辑为基准,排列多个目标对象、多个目标目的或多个目标动作,从而在自动化自行复杂动作时,也可以通过语音实现控制,提升生产效率。
17、在上述任一技术方案的基础上,进一步地,获取图像,根据图像和目标指令信息确定目标对象的位姿信息的步骤,具体包括:获取图像,根据图像生成场景点云信息;根据目标指令信息和场景点云信息,确定目标对象的位姿信息。
18、在该技术方案中,获取图像,分析图像并在图像中确定目标指令信息所对应的目标对象,从而确定目标对象的位姿信息的步骤,具体包括:获取当前场景的图像,根据当前场景的图像生成场景点云信息,场景点云信息可以表示当前场景的物品的轮廓等,进而根据场景点云信息和目标指令信息中的目标对象,可以确定目标对象的位置和姿态,从而能够实现对目标对象进行目标作业,从而提升对目标对象识别的准确性。
19、在上述任一技术方案的基础上,进一步地,获取图像,根据图像生成场景点云信息的步骤,具体包括:获取场景彩色图像和场景深度图像,根据场景彩色图像和场景深度图像生成场景点云信息。
20、在该技术方案中,获取当前场景的图像,根据当前场景的图像生成场景点云信息的步骤,具体包括:获取当前场景的场景彩色图像和场景深度图像,进而结合场景彩色图像和场景深度图像可以得到当前场景的三维场景点云信息,进而可以确定目标对象的位置和姿态。
21、在上述任一技术方案的基础上,进一步地,根据目标指令信息和场景点云信息,确定目标对象的位姿信息的步骤,具体包括:根据场景点云信息,确定目标点云信息;根据目标指令信息,确定目标点云模型信息;根据目标点云信息和目标点云模型信息,确定位姿信息。
22、在该技术方案中,根据当前场景的三维场景点云信息,确定目标对象的位置和姿态的步骤,具体包括:对场景点云信息进行滤波等处理,得到目标点云信息,根据目标指令信息确定目标对象,再根据目标对象的目标点云模型信息以及目标点云信息,确定目标对象的位置和姿态,进而通过滤波和匹配提升视觉识别的准确性。
23、在上述任一技术方案的基础上,进一步地,根据目标点云信息和目标点云模型信息,确定位姿信息的步骤,具体包括:将目标点云信息划分为多个区域;将目标点云模型信息和目标点云信息进行粗匹配,确定粗匹配点云信息;将目标点云模型信息和粗匹配点云信息进行精匹配,确定精匹配点云信息;根据精匹配点云信息和区域,确定位姿信息。
24、在该技术方案中,根据目标对象的目标点云模型信息以及目标点云信息,确定目标对象的位置和姿态的步骤,具体包括:利用点云分割算法将目标点云信息划分成多个不同区域,在不同的区域中,将目标对象的目标点云模型信息和目标点云信息进行粗匹配,确定粗匹配点云信息,之后再将目标对象的目标点云模型信息和目标点云信息进行精匹配,从而得到目标对象的具体区域,从而确定出目标对象的位置和姿态,进而通过两次匹配提升对目标对象的位姿信息确定的准确性。
25、根据本发明的第二方面,本发明提出了一种机器人的控制装置,包括:接收单元,用于接收音频信息,根据音频信息和指令信息库确定目标指令信息;获取单元,用于获取图像,根据图像和目标指令信息确定目标对象的位姿信息;执行单元,用于根据目标指令信息和位姿信息执行目标作业。
26、本发明提出的机器人的控制装置,机器人接收音频信息,分析音频信息,得到目标指令信息,获取图像,分析图像并在图像中确定目标指令信息所对应的目标对象,从而确定目标对象的位姿信息,之后机器人根据位姿信息对目标对象执行目标作业,进而将语音控制和视觉功能结合,在实际使用中,只需通过语音下达命令,机器人可以自行识别目标对象,并对目标对象执行目标作业,无需频繁的修改编程,提升生产效率。
27、根据本发明的第三方面,本发明提出了一种机器人,包括:如上述技术方案中任一项提出的机器人的控制装置。
28、本发明提出的机器人,因如上述技术方案中任一项提出的机器人的控制装置,因此,具有如上述技术方案中任一项提出的机器人的控制装置的全部有益效果,在此不再一一陈述。
29、根据本发明的第四方面,本发明提出了一种机器人,包括:音频采集识别组件,用于采集音频信息,并输出目标指令信息;视觉识别组件,用于根据目标指令信息确定目标对象的位姿信息;执行组件,用于根据目标指令信息和位姿信息执行目标作业;控制组件,用于接收目标指令信息、位姿信息并发送至执行组件;其中,控制组件和音频采集识别组件、视觉识别组件以及执行组件通信连接。
30、本发明提出的机器人,包括音频采集识别组件、视觉识别组件、执行组件和控制组件,并且,音频采集识别组件、视觉识别组件以及执行组件都和控制组件形成通信连接,都能传递信息。
31、音频采集识别组件接收音频信息,分析音频信息,并输出目标指令信息,将目标指令信息传输到控制组件,控制组件处理并将目标指令信息转发到视觉识别组件,视觉识别组件获取当前场景的图像,并根据目标指令信息中的目标对象在图像中确定目标对象的位姿信息,将目标对象的位姿信息传输到控制组件,控制组件将目标对象的位姿信息以及目标指令信息转发到执行组件,执行组件对目标对象执行目标作业,在实际使用中,只需通过语音下达命令,机器人可以自行识别目标对象,并对目标对象执行目标作业,无需频繁的修改编程,提升生产效率。
32、在上述技术方案的基础上,进一步地,音频采集识别组件包括:接收器,用于接收音频信息;解码器,用于对音频信息进行解码;滤波器,用于对解码后的音频信息进行滤波;音频存储器,用于存储指令信息库;音频处理器,用于根据滤波后的音频信息和指令信息库,输出目标指令信息。
33、在该技术方案中,音频采集识别组件包括:接收器、解码器、滤波器、音频存储器和音频处理器,进而通过接收器接收音频信息,通过解码器对音频信息进行解码,通过滤波器对解码后的音频信息进行滤波处理,再通过音频处理器将滤波后的音频信息和音频存储器中存储的指令信息库进行匹配,将音频信息的携带的指令信息编辑在一起,得到目标指令信息,并输出。
34、在上述任一技术方案的基础上,进一步地,视觉识别组件包括:相机,用于采集图像;视觉处理器,用于根据图像确定目标对象的位姿信息。
35、在该技术方案中,视觉识别组件包括相机和视觉处理器,相机能够拍摄采集当前场景的图像,视觉处理器能够对当前场景的图像进行处理,以得到目标对象的位姿信息。
36、在上述任一技术方案的基础上,进一步地,执行组件包括:执行器,用于根据目标指令信息和位姿信息执行目标作业;力觉传感器,用于检测执行器的工作状态,并反馈至控制组件。
37、在该技术方案中,执行组件包括执行器和力觉传感器,执行器能够根据控制组件传输的目标指令信息和位姿信息,对目标对象执行目标作业,力觉传感器设置在执行器上,进而可以根据执行器的动作向控制组件反馈,以将当前执行器的状态反馈到控制组件,控制组件根据执行器的状态,调整执行器的动作,以实现对目标作业的完成。
38、根据本发明的第五方面,本发明提出了一种计算机设备,包括:存储器及存储在存储器上并可在处理器上运行的程序或指令,程序或指令被处理器执行时实现如上述技术方案中任一项提出的机器人的控制方法。
39、本发明提出的计算机设备,包括存储器和处理器,存储器中存储有计算机程序;处理器执行计算机程序以实现如上述技术方案中任一项提出的机器人的控制方法的步骤,因此,具有如上述技术方案中任一项提出的机器人的控制方法的全部有益效果,在此不再一一陈述。
40、根据本发明的第六方面,本发明提出了一种可读存储介质,可读存储介质上存储程序或指令,程序或指令被处理器执行时实现如上述技术方案中任一项提出的机器人的控制方法的步骤。
41、本发明提出的可读存储介质,存储程序或指令,程序或指令被处理器执行时实现如上述技术方案中任一项提出的机器人的控制方法的步骤,因此,具有如上述技术方案中任一项提出的机器人的控制方法的全部有益效果,在此不再一一陈述。
42、本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!