一种基于模型不确定性估计的机械臂强化学习控制方法与流程
本发明涉及机械臂控制,具体涉及一种基于模型不确定性估计的机械臂强化学习控制方法。
背景技术:
1、传统的机械臂控制方法通常使用预先建立的动力学模型和控制器进行控制,但是这些方法忽略了模型不确定性带来的影响。随着对机械臂性能要求的日益提高,机械臂的模型存在很大的不确定性,如控制系统中通常存在未知的干扰和不确定性,包括建模误差、外部干扰和测量误差等,这些不确定性都可能会导致系统控制性能下降甚至失效。因此,需要考虑机械臂在建模中一切存在的不确定性因素,这样才能保证机械臂执行任务时的稳定性和精确性。
2、强化学习中model-free(不基于模型)的算法不依赖于对环境的建模,而是直接利用与环境交互得到的经验来学习策略。在面对复杂的任务时model-free方法可能需要大量的训练样本,学习过程的时间较长,数据采样效率低。因此,利用model-free算法对机械臂进行控制通常需要从大量的试错中学习策略,对数据的需求比较大,可能需要大量的实验来获得足够的数据。
技术实现思路
1、本发明为了克服以上技术的不足,提供了一种提高机械臂控制的稳定性和精度的基于模型不确定性估计的机械臂强化学习控制方法。
2、本发明克服其技术问题所采用的技术方案是:
3、一种基于模型不确定性估计的机械臂强化学习控制方法,包括:
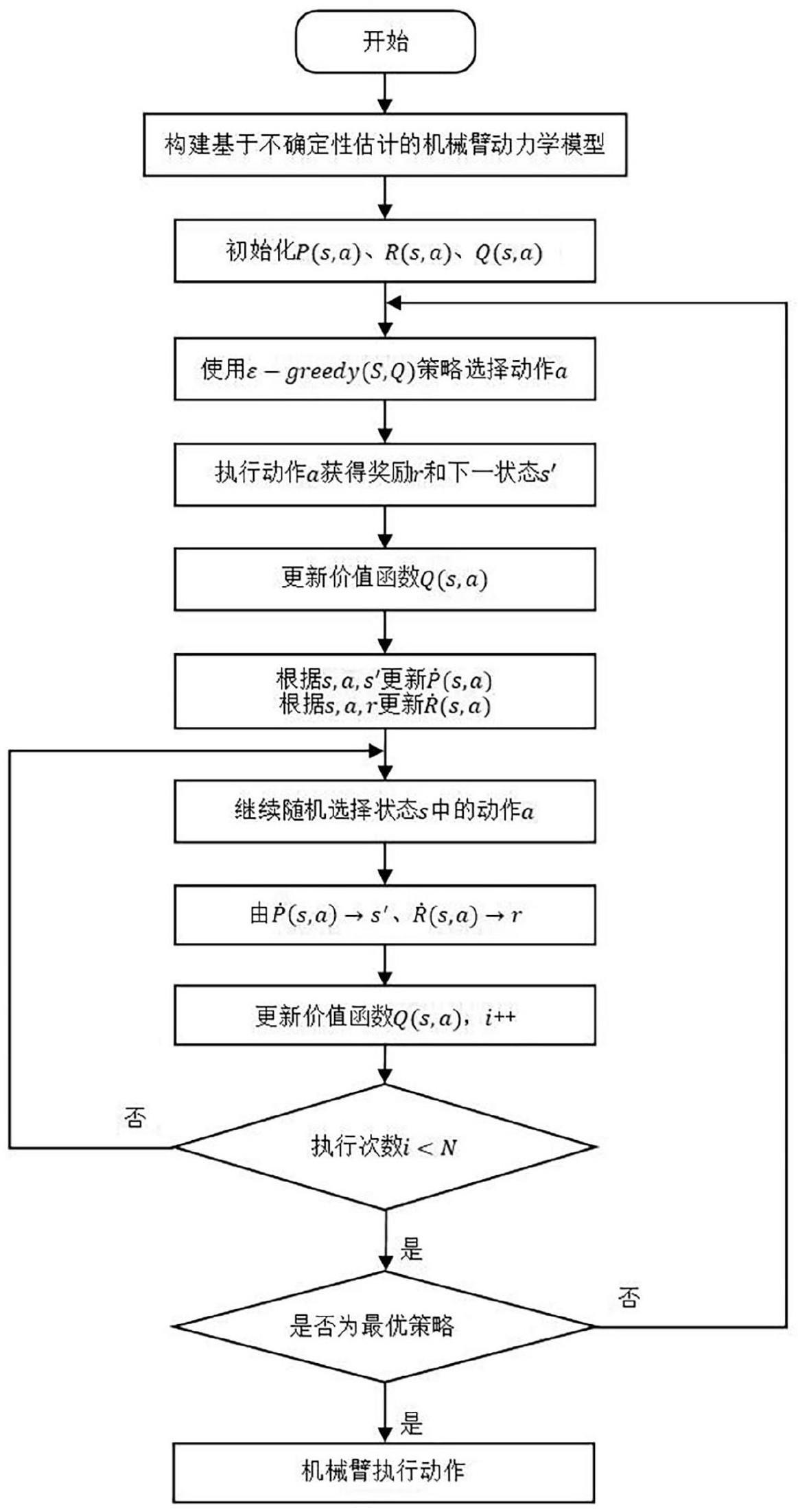
4、a)建立不确定性估计的机械臂动力学模型其中为融合不确定性的机械臂的关节力矩,τ为机械臂的动力学模型的机械臂的关节力矩,δ为机械臂理论位置和实际位置的误差;
5、b)初始化得到机械臂状态模型p(s,a),其中s为不确定性估计的机械臂动力学模型中机械臂的当前位置状态,a为将融合不确定性的机械臂的关节力矩输入到机械臂的对应的关节的驱动器中,得到的机械臂要执行的动作;
6、c)通过奖励函数r初始化得到奖励函数模型r(s,a);
7、d)初始化机械臂的当前位置状态s采取机械臂要执行的动作a的价值函数q(s,a);
8、e)根据机械臂当前位置状态s利用贪婪策略选择机械臂要执行的动作a;
9、f)将步骤e)中机械臂要执行的动作a输入到奖励函数模型r(s,a)中,得到奖励函数r,将步骤e)中机械臂要执行的动作a输入到机械臂状态模型p(s,a)中,得到机械臂下一个状态s′,根据动作a和机械臂下一个状态s′得到新的状态模型
10、g)根据步骤f)中的机械臂要执行的动作a、机械臂的当前位置状态s、奖励函数r、机械臂下一个状态s′计算得到更新的价值函数q′(s,a);
11、h)根据步骤f)中的机械臂要执行的动作a、机械臂的当前位置状态s、奖励函数r计算得到新的奖励函数模型i)随机选择一个机械臂的当前位置状态s,在该当前位置状态s出现过的动作中随机选取一个动作a,将该动作a输入到新的状态模型中,得到机械臂下一个状态s″,将该动作a输入到新的奖励函数模型中,得到奖励函数r;
12、j)利用步骤i)中的机械臂的当前位置状态s、根据动作a和机械臂下一个状态s″计算得到更新的价值函数q″(s,a);
13、k)重复执行步骤i)至步骤j)n次,得到最后更新的价值函数q″(s,a);
14、l)根据最后更新的价值函数q″(s,a)计算得到当前状态下价值函数最大的动作a*;
15、m)将动作a*作为输入到机械臂的关节驱动器中,实现机械臂的控制。
16、进一步的,步骤a)包括如下步骤:
17、a-1)机械臂动力学模型为其中q为机械臂的关节位置向量,为机械臂的角速度向量,为机械臂的角加速度向量,m(q)为质量惯性矩阵,为向心力与哥氏力矩阵,g(q)为重力矩阵;
18、a-2)通过公式计算得到机械臂理论位置和实际位置的误差δ,式中δm(q)为质量惯性矩阵参数的实际值与标称值之间的偏差,为向心力与哥氏力矩阵参数的实际值与标称值之间的偏差,δg(q)为重力矩阵参数的实际值与标称值之间的偏差,δ~cnp(mζ,kζ),δ服从于cnp,cnp为深度高斯过程学习系统建模,mζ为高斯函数的均值向量,kζ为高斯函数的协方差函数。
19、进一步的,步骤b)中不确定性估计的机械臂动力学模型中机械臂的当前位置状态s包括机械臂的关节角度、机械臂的角速度、机械臂末端执行器的位置、机械臂末端执行器的速度、机械臂的力。
20、进一步的,步骤c)包括如下步骤:
21、c-1)通过公式计算得到奖励函数r,式中q为机械臂当前关节位置向量,q=(x,y,z),x为机械臂在世界坐标系中当前关节位置的x轴坐标,y为机械臂在世界坐标系中当前关节位置的y轴坐标,z为机械臂在世界坐标系中当前关节位置的z轴坐标,qd为机械臂期望关节位置向量,qd=(x′,y′,z′),x′为机械臂在世界坐标系中的期望关节位置的x轴坐标,y′为机械臂在世界坐标系中的期望关节位置的y轴坐标,z′为机械臂在世界坐标系中的期望关节位置的z轴坐标,f为机械臂力向量,f={fx,fy,fz},fx为当前机械臂执行动作a时在世界坐标系下x轴方向所受到的力,fy为当前机械臂执行动作a时在世界坐标系下y轴方向所受到的力,fz为当前机械臂执行动作a时在世界坐标系下z轴方向所受到的力,fd为机械臂期望力向量,fd={fxd,fyd,fzd},fxd为当前机械臂执行动作a时在世界坐标系下x轴方向所期望受到的力,fyd为当前机械臂执行动作a时在世界坐标系下y轴方向所期望受到的力,fzd为当前机械臂执行动作a时在世界坐标系下z轴方向所期望受到的力;
22、c-2)利用监督学习的方法训练奖励函数r,得到奖励函数模型r(s,a)。
23、进一步的,步骤g)中通过公式q′(s,a)=q(s,a)+α[r+γmaxaq(s′,a)-q(s,a)]计算得到更新的价值函数q′(s,a),式中α为学习效率值,0<α<1,γ为对未来奖励的衰减值,0<γ<1,maxaq(s′,a)为机械臂下一个状态s′所采取的动作a的价值函数的最大值。
24、进一步的,步骤h)中通过公式计算新的奖励函数模型
25、进一步的,步骤j)中通过公式q″(s,a)=q′(s,a)+α[r+γmaxaq′(s″,a)-q′(s,a)]计算得到更新的价值函数q″(s,a),式中maxaq(s″,a)为机械臂下一个状态s″所采取的动作a的价值函数的最大值。
26、优选的,n取值为100。
27、进一步的,步骤l)中通过公式计算得到当前状态下价值函数最大的动作a*。
28、本发明的有益效果是:考虑到机械臂在建模时存在的不确定性因素,通过不确定性估计来构建机械臂的动力学模型。然后再利用基于机械臂不确定性估计模型的强化学习dyna-q算法,通过与模型的交互产生的数据更新状态模型和奖励函数模型,从模型中获得大量虚拟数据,再利用真实数据与虚拟数据更新价值函数,从而能够高效的产生和利用经验,提高采样效率,选择最佳动作使得机械臂在执行任务中能够获得更优的策略。
- 还没有人留言评论。精彩留言会获得点赞!