一种融合视觉信息的机器人遥操作力觉临场感构建方法与流程
本发明属于遥操作临场感构建领域,尤其是涉及了一种融合视觉信息的机器人遥操作力觉临场感构建方法。
背景技术:
1、随着机器人技术的发展,遥操作技术在众多领域中得到广泛应用,包括工业作业、深空探索和深海开发等。遥操作临场感是评估遥操作系统性能的重要指标之一,指通过技术手段使操作者在远距离操作过程中能够真实地感受到参与其中的身临其境感。
2、遥操作临场感主要包括力觉临场感和视觉临场感两个方面,目前的研究大多将它们作为独立的实现进行探索,而缺乏有效利用视觉信息来增强力觉临场感的构建方法。现有技术缺少一种融合视觉信息的机器人遥操作力觉临场感构建方法,该方法能将视觉信息引入到虚拟力觉的构建过程,以实现力觉临场感的增强。
技术实现思路
1、本发明针对现有的研究中力觉临场感缺乏视觉信息指导的问题,提出了一种融合视觉信息的机器人遥操作力觉临场感构建方法,能够为操作者提供融合视觉信息的力觉临场感,可以帮助操作者引导机器人躲避障碍物、接近任务目标,减轻操作者的工作负担。
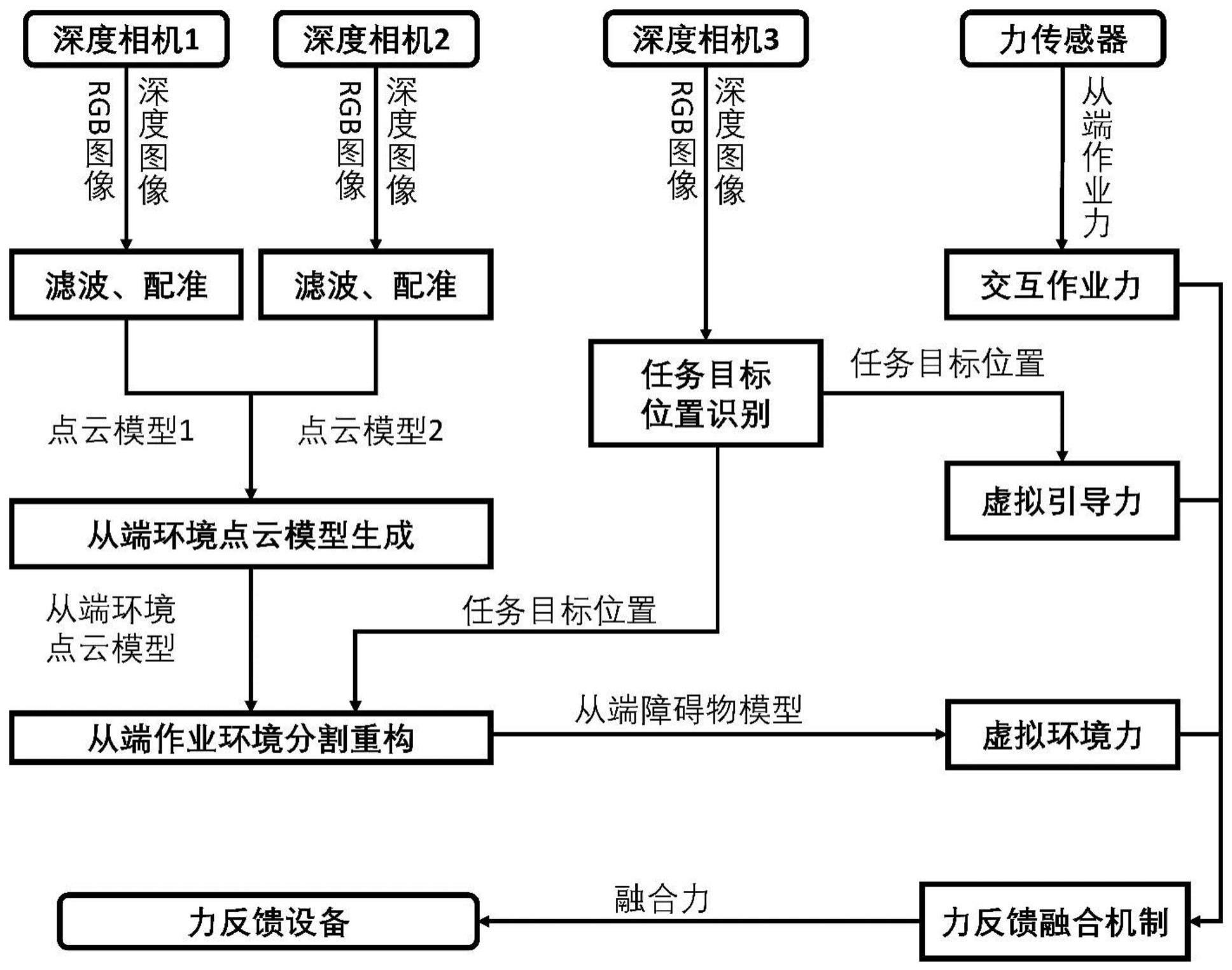
2、本发明所采用的技术方案如下,包括以下步骤:
3、步骤一:通过三个深度相机,基于点云与目标识别的作业环境视觉信息获取方法,获取任务目标位置和从端障碍物模型;
4、步骤二:首先通过力传感器获得交互作业力,通过任务目标位置获得目标虚拟引导力,通过从端障碍物模型获得虚拟环境力,然后根据交互作业力、目标虚拟引导力和虚拟环境力构建基于融合视觉信息的融合力;
5、步骤三:将融合力传输至力反馈设备,形成最终的遥操作力觉临场感。
6、步骤一中,基于点云与目标识别的作业环境视觉信息获取方法包括从端环境点云模型生成、从端作业环境分割重构、任务目标位置识别三个步骤,具体为:
7、步骤s1、从端环境点云模型生成:
8、首先,通过深度相机1和深度相机2分别获得各自对应的n帧深度图像f1,f2…fi…fn,分别对所有的深度图像fi进行降采样操作,得到降采样后的深度图像fi,接着对降采样后的深度图像fi进行空间滤波和时序滤波处理,建立从端环境点云模型;
9、步骤s2、从端作业环境分割重构
10、步骤s2.1:基于从端环境点云模型搜索最大平面
11、首先,在从端环境点云模型中随机选择一个小部分样本来拟合作业平面,以形成待检测作业平面;接着,获得待检测作业平面的平均误差距离,最后从多个待检测作业平面中选出一个最优作业平面;
12、步骤s2.2:基于最优作业平面,去除从端环境点云模型中的非必要数据,得到点云集合pr;
13、步骤s2.3:根据点云集合pr,进行从端环境点云聚类分割,得到多个目标邻域点集;
14、步骤s2.4:曲面重构:采用泊松曲面重构算法,将每个目标邻域点集转换为各自对应的一个表面连续的物体模型,并将每个物体模型作为潜在从端障碍物模型;
15、步骤s3、任务目标位置识别
16、利用深度相机3获得对应的rgb图像,将深度相机3的rgb图像输入到任务目标检测算法中,得到任务目标在rgb图像中的像素位置,然后通过内参矩阵和位姿矩阵获取任务目标位置,接着根据任务目标位置对潜在从端障碍物模型进行分类:
17、若任务目标位置位于潜在从端障碍物模型中,则将该潜在从端障碍物模型作为任务目标物体模型;
18、若任务目标位置不在潜在从端障碍物模型中,则将该潜在从端障碍物模型作为从端障碍物模型。
19、步骤二中融合视觉信息的力觉临场感构建方法包括交互作业力、虚拟引导力、虚拟环境力、力反馈融合机制四部分,具体为:
20、步骤s1、根据力传感器构建交互作业力fm;
21、步骤s2、根据任务目标位置构建目标虚拟引导力fgvf;
22、步骤s3、根据从端障碍物模型获得虚拟环境力fe;
23、步骤s4、力反馈融合机制
24、结合基于力传感器获得的交互作业力、任务目标位置获得的虚拟引导力、从端障碍物模型获得的虚拟环境力,获得融合力fmix:
25、fmix=kmfm+kgvffgvf+kefe
26、其中,km,kgvf,ke分别为交互作业力、虚拟引导力以及虚拟环境力的权重系数,权重系数按照以下公式处理得到:
27、
28、其中,k1,k2,k3,k4为常数。
29、所述步骤一的s1中,根据降采样后深度图像建立从端环境点云模型的具体步骤为:
30、步骤s1.1:设置一个长、宽分别为2m和2n的矩形滑动窗口,根据降采样后深度图像fi的每一个像素深度值,获得以点(a,b)为窗口中心的局部均值mab:
31、
32、其中,dcd表示降采样后的深度图像fi中像素点(c,d)对应的深度值;
33、步骤s1.2:获得以点(a,b)为窗口中心的局部方差vab:
34、
35、步骤s1.3:根据局部均值mab和局部方差vab,对降采样后的深度图像fi进行深度值更新,更新后深度图像fi中像素点(a,b)对应的深度值按照以下公式处理得到:
36、
37、kab=vab/(vab+σ)
38、其中,dab表示降采样后深度图像fi更新前像素点(a,b)对应的深度值;σ为预设的常数;
39、步骤s1.4:根据更新深度值后的深度图像fi,以步长为1移动矩形滑动窗口,重复步骤s1.1~步骤1.3直至降采样后深度图像fi所有位置的像素都被遍历,得到该帧深度图像fi对应的空间滤波图像fi,l;
40、步骤s1.5:对于n帧深度图像f1,f2…fi…fn,获得各自对应的空间滤波图像f1,l,f2,l…fi,l…fn,l;然后,对空间滤波图像中每个像素点位置进行遍历,获得每个深度相机各自对应的一个时序滤波深度图像,时序滤波深度图像中每个像素点(x,y)的深度值dn(x,y)按照以下公式处理得到:
41、dn(x,y)=med(d1(x,y),d2(x,y),d3(x,y)...di(x,y)...dn(x,y))
42、其中,med()表示取中值操作,di(x,y)表示在像素点(x,y)位置处,第i帧空间滤波图像fi,l中的深度值;
43、步骤s1.6;最后,通过深度相机1和深度相机2分别获得一个各自对应的rgb图像,利用内参矩阵将时序滤波深度图像配准到对应的rgb图像中,获得配准图像,将深度相机1和深度相机2对应的配准图像分别作为点云模型1和点云模型2,利用相机位姿矩阵将点云模型1和点云模型2拼接成从端环境点云模型。
44、所述步骤一中s2.1基于从端环境点云模型搜索最大平面的具体步骤为:
45、步骤s2.1.1:首先,进行初始参数设置:设置迭代次数numr、最大误差阈值disthreshold以及点集最少个数nr;
46、步骤s2.1.2:接着,在从端环境点云模型中随机选取三个不共线的点p1,p2,p3,生成待检测作业平面,由三个点构成的待检测作业平面如下式所示:
47、arx+bry+crz+dr=0
48、其中,x,y,z为待检测作业平面上的各点坐标,ar,br,cr,dr为待检测作业平面的参数;
49、步骤s2.1.3:首先,获得除上述三点p1,p2,p3以外的其他所有点pi到该待检测作业平面的欧式距离disr(pi):
50、
51、其中,xi,yi,zi表示点pi的坐标;
52、然后,判断点pi是否属于该待检测作业平面:
53、若disr(pi)≤disthreshold,则认为点pi属于该待检测作业平面,将该点pi放入目标点集中;
54、否则,则认为点pi不属于待检测作业平面,将该点pi作为目标点集外的点;
55、接着,所有点pi的欧式距离采集完毕后,获得目标点集中点的个数:
56、若目标点集中的点数超过点集最少个数nr,则将该待检测作业平面作为合格的拟合作业平面,并将目标点集内所有点pi到待检测作业平面的欧式距离的平均值作为该待检测作业平面的平均误差距离er;
57、若目标点集中的点不超过点集最少个数nr,则认为该待检测作业平面为不合格的拟合作业平面;
58、步骤s2.1.4:重复多次步骤步骤s2.1.2~步骤s2.1.3,获得多个合格的拟合作业平面,选择平均误差距离er最小时对应的待检测作业平面作为最优作业平面。
59、所述步骤一中s2.2基于最优作业平面得到点云集合的具体操作为:
60、步骤s2.2.1:选取从端环境点云模型的点云数据点pk(xk,yk,zk),获取最优作业平面的法向量获取最优作业平面中任一点指向点云数据pk的向量将向量和向量点乘,获得点乘结果:
61、若点乘结果为正,则认为该点云数据pk为有效数据,保留该点云数据pk;
62、否则,则认为该点云数据pk为非必要数据,在从端环境点云模型中删除该点云数据pk;
63、步骤s2.2.2:重复多次步骤s2.2.1,直至没有新的点云数据点,完成所有非必要数据的去除,将所有保留下来的点云数据pk构成点云集合pr。
64、所述步骤一中s2.3进行从端环境点云聚类分割得到目标邻域点集的步骤为:
65、步骤s2.3.1:进行初始参数设置:设置领域半径eps以及最小邻域点数min_sampels;
66、步骤s2.3.2:首先,选取点云集合pr中的任意一个点作为初始基点pd,在点云集合pr中通过kdtree获得与基点pd相邻的点作为该基点pd对应的相邻点,并判断相邻点是否为基点pd的邻域点pe:
67、若基点pd和相邻点之间的距离小于等于eps,则该相邻点为基点pd的邻域点pe,将该邻域点pe添加入初始基点pd对应的点集npd中;
68、否则,则认为该相邻点不为基点pd的邻域点,舍弃该点;
69、然后,遍历所有的相邻点,直到没有新的相邻点;
70、步骤s2.3.3:选取点集npd中的邻域点pe作为新的基点pd,重复步骤s2.3.2以获得新基点pd对应的邻域点,并将新基点pd对应的邻域点也添加到初始基点pd对应的点集npd中;
71、遍历点集npd中的所有点,直到没有新的邻域点,将当前点集npd作为目标邻域点集;
72、步骤s2.3.4:重新选取点云集合pr中的另一个点作为下一个初始基点pd,并建立新的点集npd,重复步骤s2.3.2~步骤s2.3.3,得到另一个新的目标邻域点集;
73、遍历点云集合pr中的所有点,直到没有新的点,得到所有的目标邻域点集。
74、所述步骤二中s1根据力传感器构建交互作业力的具体步骤如下:
75、首先,按照下式处理得到径向基神经网络的环境估计器的最优作业力估计参数
76、
77、其中,arg min[x]表示当x取到最小值时的ωs,sup(y)表示当y取到最大值时的psd,ωs和均为有界集,ωs为作业环境中的作业力特征参数,为径向基神经网络矩阵,psd为输入矩阵;
78、然后,根据最优作业力估计参数获得交互作业力fm:
79、
80、其中,t表示时间,t(t)表示延时,为径向基神经网络矩阵。
81、所述步骤二中s2构建目标虚拟引导力的具体步骤如下:
82、步骤s2.1、将当前机器人末端执行器的位置作为起始点ps,将任务目标位置作为路径终点pe;
83、步骤s2.2、构建柱形引导力
84、首先,获取位于路径终点pe正上方且距离路径终点pe为dmin的点pt(xt,yt,zt)作为柱形引导力末端,基于起始点ps(xs,ys,zs)与点pt(xt,yt,zt)构建期望路径f(p),以f(p)为轴线、r为半径构建出一个柱形引导力场,并按照下式处理得到期望路径长度
85、
86、然后,实时获取机器人末端位置pf(xf,yf,zf),获得期望路径f(p)中与机器人末端位置pf距离最近的点
87、
88、接着,获得机器人末端和期望路径f(p)之间的偏差σmin(pf),并获得机器人末端和柱形引导力末端之间的距离
89、
90、最终,构建机器人末端在柱形引导力场下的虚拟引导力fgvfci:
91、
92、其中,kgvf1、kgvf2为两个正增益参数;f1为方向由pf指向pmin的单位分力;f2为方向由pf指向pt的单位分力;
93、步骤s2.3、构建锥形引导力
94、首先,以柱形引导力末端点pt为起始点,任务目标位置点pe为终点构建期望路径,并以该期望路径为轴线构建一个锥形引导力场,锥形引导力场的圆锥开口角度为θf,圆锥的中心轴线的单位向量αf表示为:
95、
96、接着,实时获取机器人末端位置pf(xf,yf,zf),将pf与任务目标位置点pe的连线分解为沿着圆锥轴线方向的分量ni(pf)以及正交方向的分量nr(pf),并获得机器人末端位置pf处锥形引导力边界到圆锥轴线的距离cone(pf):
97、
98、其中,i为3×3的单位矩阵;
99、当||nr(pf)||≤cone(pf)时,则表明机器人末端点pf在锥形引导力场内部,获得机器人末端点pf与期望路径的径向偏差e(pf)=||nr(pf)||;
100、当||nr(pf)||>cone(pf)时,则表明机器人末端点pf在锥形引导力场范围外,重新建立新的锥形引导力场,直至机器人末端点pf在锥形引导力场内部;
101、最终,构建机器人末端在锥形引导力场下的虚拟引导力fgvfco:
102、
103、其中,kgvf3,kgvf4为两个增益参数;
104、步骤s2.4、构建目标虚拟引导力fgvf
105、若机器人末端执行器位置ps和任务目标位置的之间距离将锥形引导力场下的虚拟引导力fgvfco作为目标虚拟引导力fgvf;
106、否则,将柱形引导力场下的虚拟引导力fgvfci作为目标虚拟引导力fgvf。
107、所述步骤二中s3构建虚拟环境力的具体步骤为:
108、步骤s3.1、首先,将所有的从端障碍物模型组成一个从端障碍物模型集合mc,通过轴对齐包围盒算法获得每个从端障碍物模型对应的一个包围盒,并得到各个从端障碍物模型的相对位置以及各个包围盒的大小;
109、接着,在从端障碍物模型集合mc中选取任意一个从端障碍物模型ma,获取该从端障碍物模型ma对应包围盒的中心位置pa(xa,ya,za)以及包围盒的各边边长lax,lay,laz;在从端障碍物模型集合mc中选取除从端障碍物模型ma外的任意一个从端障碍物模型mb,获取从端障碍物模型mb对应包围盒的中心位置pb(xb,yb,zb)及以及该包围盒的各边边长lbx,lby,lbz,处理得到两个包围盒间最短距离lab:
110、
111、其中,kj为系数,下标j∈(x,y,z),系数kj按照下式处理得到:
112、
113、然后,在从端障碍物模型集合mc中选取除从端障碍物模型ma外的任意一个从端障碍物模型,重复上述步骤,在从端障碍物模型集合mc中选出与从端障碍物模型ma距离最小的从端障碍物模型mc,并将该从端障碍物模型mc作为从端障碍物模型ma对应的最近模型,然后根据下式处理得到从端障碍物模型ma的模型放大系数la:
114、
115、其中,kmin为权重系数,lac为从端障碍物模型ma和其对应的从端障碍物模型mc之间的距离;lcx,lby,lcz为从端障碍物模型mc对应包围盒的各边边长;
116、最后,将从端障碍物模型ma中各个顶点沿法线方向外扩la长度并重新建模、更新,将更新后的模型作为从端障碍物模型ma的虚拟斥力场模型;
117、在从端障碍物模型集合mc中选取一个新的从端障碍物模型,重复上述步骤以获取所有的从端障碍物模型对应的虚拟斥力场模型;
118、步骤s3.2、当力反馈点与虚拟斥力场模型接触并在虚拟斥力场模型内部发生移动时,设置一个虚拟接触点使得该虚拟接触点在斥力场模型的表面发生滑动,当虚拟接触点和力反馈点之间的距离最小时,把该虚拟接触点作为力反馈点对应的目标虚拟接触点;所述的力反馈点采用实时移动的机器人末端位置;按照以下公式处理得到虚拟环境力fe:
119、
120、其中,ε为力反馈点与目标虚拟接触点之间的距离;为力反馈点与目标虚拟接触点距离增长速率,ks为弹性系数,kd为阻尼系数。
121、本发明方法采用主从端机器人遥操作系统,所述系统主要由主端模块和从端模块组成,所述的主端模块包括操作者、力反馈设备和主端主机;所述从端模块包括机器人、力传感器、三个深度相机、作业平面、任务目标、障碍物和从端主机。力传感器安装于机器人末端执行器上,第一个深度相机1、第二个深度相机2和第三个深度相机3。
122、本发明采用三个深度相机,设计了基于点云与目标识别的作业环境视觉信息获取方法,通过从端环境点云模型生成、从端作业环境分割重构,获得从端障碍物模型,通过任务目标检测算法获得任务目标位置;设计了融合视觉信息的力觉临场感构建方法,融合了交互作业力、虚拟引导力和虚拟环境力,并最终得到融合力。其中,交互作业力基于径向基神经网络和力传感测得的从端作业力得到;虚拟引导力根据作业阶段不同,分为柱形引导力、锥形引导力两种引导方案;虚拟环境力通过轴对齐包围盒算法和基于点的力反馈模型获得;进而通过设计的力反馈融合机制将交互作业力、虚拟引导力和虚拟环境力融合得到融合力。最终,将融合力传输至力反馈设备,形成遥操作力觉临场感。
123、与现有技术相比,本发明具有如下有益效果:
124、本发明设计了融合视觉信息的力觉临场感构建方法,能够将从端交互作业力、虚拟引导力以及虚拟环境力有效融合,将视觉信息引入到虚拟力觉的构建过程,实现力觉临场感的增强,通过融合视觉信息的融合力,可以帮助操作者引导机器人躲避障碍物、接近任务目标,减轻操作者的工作负担。
- 还没有人留言评论。精彩留言会获得点赞!