本发明涉及机器人,具体涉及一种基于扩展现实的人型机器人多模态训练方法及系统。
背景技术:
1、人型机器人作为机器人领域的重要分支,具备高度的灵活性和适应性,广泛应用于工业制造、服务业、灾难救援等多个领域。随着计算机图形与仿真技术的飞速发展,扩展现实技术已成为连接虚拟与现实世界的桥梁,为机器人训练提供了全新的可能性。然而,在复杂的训练环境中,人型机器人可能面临多种不确定性和异常状况,这些异常状况不仅影响训练效果,还可能对机器人本身造成损害。然而,传统的人型机器人训练方法多基于单一传感器数据判断,存在监测范围有限、准确性不高的缺点,难以在复杂多变的场景中实现高效训练。
技术实现思路
1、为了克服上述的技术问题,本发明的目的在于提供一种基于扩展现实的人型机器人多模态训练方法及系统,解决了传统的人型机器人训练方法多基于单一传感器数据判断,存在监测范围有限、准确性不高的缺点,难以在复杂多变的场景中实现高效训练的问题。
2、本发明的目的可以通过以下技术方案实现:
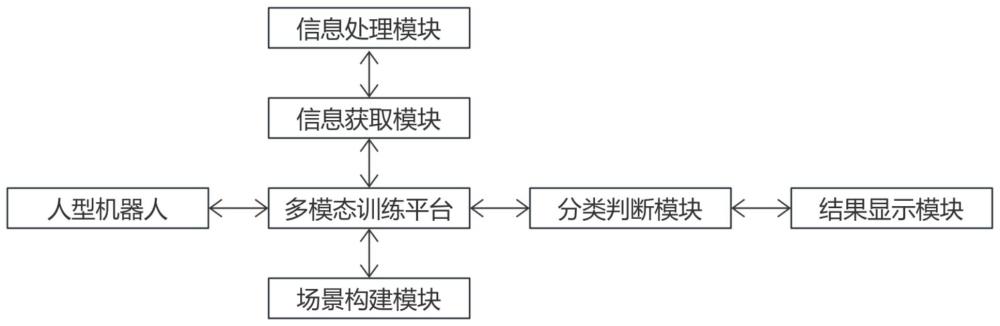
3、一种基于扩展现实的人型机器人多模态训练系统,包括:
4、信息处理模块,用于根据训练监控信息获得训练异常系数xli,并将训练异常系数xli发送至分类判断模块;
5、所述信息处理模块获得训练异常系数xli的具体过程如下:
6、将时间信息sj、移动信息yd以及运动信息mo的数值按照预设的信息处理函数进行量化运算,得到训练异常系数xli,并将训练异常系数xli发送至分类判断模块;
7、其中,信息处理函数如下所示:
8、
9、式中:
10、κ为预设的误差调节因子,取κ=0.938;
11、π和e均为数学常数;
12、x1、x2以及x3分别为设定的时间信息sj、移动信息yd以及运动信息mo对应的预设权重因子,x1、x2以及x3满足x2>x3>x1>1.594,取x1=1.88,x2=3.07,x3=2.41;
13、分类判断模块,用于根据训练异常系数xli将训练场景i分类为训练异常场景、训练合格场景,并将训练异常场景发送至结果显示模块,并获取训练评价信息,并根据训练评价信息获得训练评价值xp,并根据训练评价值xp生成训练不合格指令或者训练合格指令,并将训练不合格指令或者训练合格指令发送至结果显示模块;其中,训练评价信息包括异比值yb、训均值xj;
14、结果显示模块,用于根据训练异常场景、训练不合格指令以及训练合格指令进行显示。
15、作为本发明进一步的方案:所述分类判断模块将训练场景i分类的具体过程如下:
16、将训练异常系数xli与预设的训练异常阈值xly进行比较,比较结果如下:
17、如果训练异常系数xli≥训练异常阈值xly,则将训练异常系数xli对应的训练场景i标记为训练异常场景,并将训练异常场景发送至结果显示模块;
18、如果训练异常系数xli<训练异常阈值xly,则将训练异常系数xli对应的训练场景i标记为训练合格场景。
19、作为本发明进一步的方案:所述分类判断模块生成训练不合格指令或者训练合格指令的具体过程如下:
20、获取人型机器人按照所有的训练场景i完成训练操作后,获取训练异常场景的数量和训练场景i的数量两者的比值,并将其标记为异比值yb;
21、获取人型机器人按照所有的训练场景i完成训练操作后,获取所有的训练异常系数xli的平均值,并将其标记为训均值xj;
22、获取异比值yb、训均值xj两者的乘积,并将其标记为训练评价值xp;
23、将训练评价值xp与预设的训练评价阈值xpy进行比较,比较结果如下:
24、如果训练评价值xp≥训练评价阈值xpy,则生成训练不合格指令,并将训练不合格指令发送至结果显示模块;
25、如果训练评价值xp<训练评价阈值xpy,则生成训练合格指令,并将训练合格指令发送至结果显示模块。
26、作为本发明进一步的方案:所述的基于扩展现实的人型机器人多模态训练系统还包括:
27、场景构建模块,用于构建训练场景i,并将训练场景i发送至多模态训练平台。
28、作为本发明进一步的方案:所述场景构建模块构建训练场景i的具体过程如下:
29、利用扩展现实技术构建若干个高度逼真的虚拟训练环境,并将其依次标记为训练场景i,i=1、……、n,n为正整数,i为其中任意一个虚拟训练环境的编号,n为虚拟训练环境的总数量,并将训练场景i发送至多模态训练平台。
30、作为本发明进一步的方案:所述的基于扩展现实的人型机器人多模态训练系统还包括:
31、多模态训练平台,用于用户选择训练场景i,同时生成训练控制指令,并将训练控制指令发送至人型机器人。
32、作为本发明进一步的方案:所述的基于扩展现实的人型机器人多模态训练系统还包括:
33、人型机器人,用于接收到训练控制指令后按照训练场景i进行训练操作,同时生成信息获取指令,并将信息获取指令发送至信息获取模块。
34、作为本发明进一步的方案:所述的基于扩展现实的人型机器人多模态训练系统还包括:
35、信息获取模块,用于获取信息获取指令后获取训练监控信息,并将训练监控信息发送至信息处理模块;其中,训练监控信息包括时间信息sj、移动信息yd以及运动信息mo。
36、作为本发明进一步的方案:所述信息获取模块获取训练监控信息的具体过程如下:
37、获取信息获取指令后获取训练控制指令的生成时刻和人型机器人接收到训练控制指令的时刻,获取两者之间的时间差,并将其标记为接时值js,获取人型机器人接收到训练控制指令的时刻和人型机器人进行训练操作的时刻,获取两者之间的时间差,并将其标记为操时值cs,将接时值js、操时值cs进行量化处理,令接时值js、操时值cs的数值分别乘以其对应的预设比例系数,获得两者的和,并将其标记为时间信息sj;其中,接时值js、操时值cs对应的预设比例系数分别为s1、s2,且s1、s2满足s1+s2=1,0<s1<s2<1,取s1=0.38,s2=0.62;
38、获取人型机器人进行训练操作的移动轨迹,并将其标记为实际移动轨迹,获取实际移动轨迹的长度和预设的标准移动轨迹的长度两者的差值,并将其标记为长度值cd,将实际移动轨迹和预设的标准移动轨迹的起点重合,获取实际移动轨迹和预设的标准移动轨迹两者的非重合轨迹长度,并将其标记为非重值fc,将实际移动轨迹和预设的标准移动轨迹的起点重合,将实际移动轨迹和预设的标准移动轨迹的终点用线段连接,获取实际移动轨迹和预设的标准移动轨迹之间围成的区域面积,并将其标记为面积值mj,将长度值cd、非重值fc以及面积值mj进行量化处理,令长度值cd、非重值fc以及面积值mj的数值分别作为底数e的指数,并将其分别标记为长度幂值、非重幂值以及面积幂值,令长度幂值、非重幂值以及面积幂值分别乘以其对应的预设比例系数,获得三者的和的算术平方根,并将其标记为移动信息yd;其中,e为数学常数,长度幂值、非重幂值以及面积幂值对应的预设比例系数分别为d1、d2以及d3,且d1、d2以及d3满足d1+d2+d3=1,0<d1<d2<d3<1,取d1=0.21,d2=0.35,d3=0.44;
39、获取人型机器人上的所有预设的监测关节,并将其依次标记为监测对象j,j=1、……、m,m为正整数,j为其中任意一个监测关节的编号,m为监测关节的总数量,获取监测对象j进行训练操作的运动轨迹,并将其标记为实际运动轨迹ygj,获取实际运动轨迹ygj的长度和预设的标准运动轨迹ygb的长度两者的差值,并将其标记为长差值cci,获取最大的长差值cci,并将其标记为最长值zc,获取所有的长差值cci的和,并将其标记为总长值tc,获取最长值zc、总长值tc两者的乘积,并将其标记为运动信息mo;
40、将时间信息sj、移动信息yd以及运动信息mo发送至信息处理模块。
41、作为本发明进一步的方案:一种基于扩展现实的人型机器人多模态训练方法,包括以下步骤:
42、步骤一:场景构建模块构建训练场景i,并将训练场景i发送至多模态训练平台;
43、步骤二:用户利用多模态训练平台选择训练场景i,同时生成训练控制指令,并将训练控制指令发送至人型机器人;
44、步骤三:人型机器人接收到训练控制指令后按照训练场景i进行训练操作,同时生成信息获取指令,并将信息获取指令发送至信息获取模块;
45、步骤四:信息获取模块获取信息获取指令后获取训练监控信息,其中,训练监控信息包括时间信息sj、移动信息yd以及运动信息mo,并将训练监控信息发送至信息处理模块;
46、步骤五:信息处理模块根据训练监控信息获得训练异常系数xli,并将训练异常系数xli发送至分类判断模块;
47、步骤六:分类判断模块根据训练异常系数xli将训练场景i分类为训练异常场景、训练合格场景,并将训练异常场景发送至结果显示模块,并获取训练评价信息,其中,训练评价信息包括异比值yb、训均值xj,并根据训练评价信息获得训练评价值xp,并根据训练评价值xp生成训练不合格指令或者训练合格指令,并将训练不合格指令或者训练合格指令发送至结果显示模块;
48、步骤七:结果显示模块根据训练异常场景、训练不合格指令以及训练合格指令进行显示。
49、本发明的有益效果:
50、本发明的一种基于扩展现实的人型机器人多模态训练方法及系统,通过根据训练场景进行训练操作,并对训练操作过程进行数据采集和分析,获取训练监控信息,根据训练监控信息获得的训练异常系数能够综合衡量训练操作过程的异常程度,且训练异常系数越大表示异常程度越高,之后对出现训练操作异常的训练场景进行筛选出,之后对所有的训练场景进行整体评价,获得训练评价值,训练评价值能够综合衡量训练场景的整体异常程度,且训练评价值越大表示整体异常程度越高,最终进行结果显示;
51、本发明采用扩展现实技术构建多模态虚拟训练环境,实现了机器人训练场景的多样化和定制化,并对训练操作过程进行数据采集和分析,能够全面地反映人型机器人的训练操作状态,提高异常监测的准确性和全面性,并能够及时发现训练操作异常情况,并实现对多模态虚拟训练环境进行整体评价,提高了训练效率和准确度,实现了人型机器人训练能力的全面提升,为机器人在教育、医疗、服务多个领域的广泛应用提供了有力支持。