基于知识驱动感知的服务机器人抓取方法、系统及机器人
本发明属于服务机器人抓取检测,具体涉及一种基于知识驱动感知的服务机器人抓取方法、系统及机器人。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、目前的抓取检测技术研究主要集中在以深度学习技术为条件的数据驱动方法的设计上,通过人类专家的大量注释进行训练。然而,当面对有限的数据和不可预见的情况时,这些数据驱动的方法会遭受严重的性能下降。此外,数据收集过程过度耗时耗力、并且导致了机器人技术的广泛部署的不实用性。现有的方法缺乏利用历史先验知识和未能充分利用机器人具身特性,无法发挥器自身的操作能力,或获得的数据仍然需要人类二次校正,缺乏很大的灵活性,无法实现机器人的长期自主学习。因此,当遇到测试场景的分布转移时,有必要将一个预先训练好的抓取检测网络与来自视觉传感器的未标记数据进行适当的调整,以保证机器人的性能,即如何实现高效具身感知与主动探索。
3、由于不同场景之间的领域差距,机器人抓取检测在实际应用中具有很大的挑战性。现有的方法侧重于通过手动或半手动的方法收集rgb-d图像和注释来优化网络。此外,他们通常会忽略机器人自身固有的探索能力。先前的研究并未将机器人端、交互段和云端结合,因此,难以将理论分析应用于实际评价。
技术实现思路
1、为了解决上述问题,本发明提出了一种基于知识驱动感知的服务机器人抓取方法、系统及机器人,本发明为了提升服务机器人抓取检测系统在不同场景的动态适应能力,通过其具身感知和知识检索能力在不断变化的场景中持续工作,能够通过机器人对环境的自主感知和探索,在新场景下无需人类干预收集合适的样本来优化自身的抓取能力,从而实现机器人的长久自治。
2、根据一些实施例,本发明的第一方案提供了一种基于知识驱动感知的服务机器人抓取方法,采用如下技术方案:
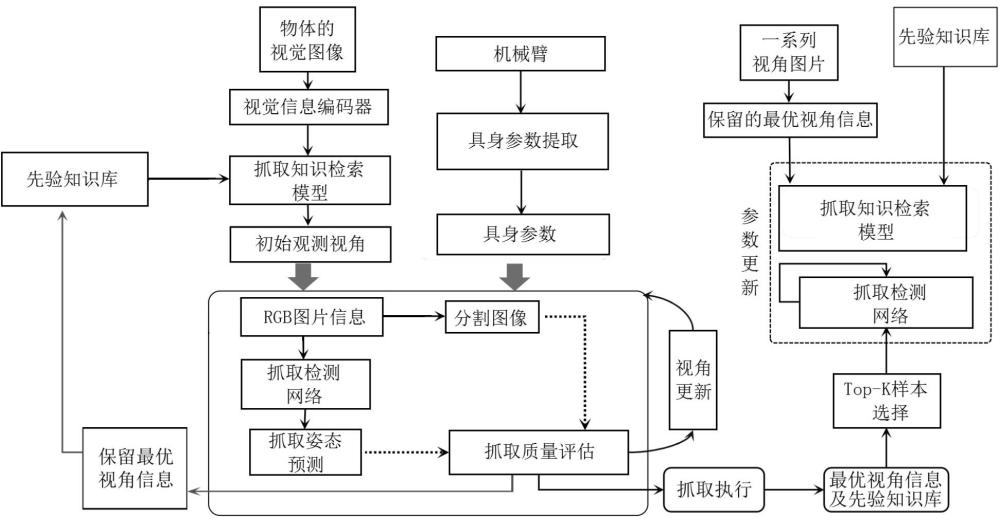
3、基于知识驱动感知的服务机器人抓取方法,包括:
4、基于先验知识库中的抓取知识向量矩阵和物体的视觉图像,确定初始观测视角;
5、在初始观测视角下,获取当前视角的rgb图片信息,并对rgb图片信息进行分割,得到rgb分割图像;
6、基于rgb图片信息,利用预先训练好的通用抓取检测网络模型进行抓取姿态预测,得到抓取姿态预测结果;
7、利用抓取姿态预测结果、rgb分割图像以及机器人自身物理参数,基于具身判断原则对当前抓取过程进行质量评估,确定最优的抓取姿态,并根据最优的抓取姿态执行抓取。
8、进一步地,所述方法在训练时利用评估后最优的抓取姿态以及先验知识库对通用抓取检测网络模型进行参数更新,具体为:
9、利用评估后最优的抓取姿态进行抓取以获取对应的视角序号和视角图片,作为最优视角信息;
10、根据最优视角信息以及先验知识库中保留的最优视角信息构建带有伪标签的rgb视角样本图像;
11、基于带有伪标签的rgb视角样本图像对待训练的通用抓取检测网络模型进行参数更新;
12、利用交叉熵损失函数对训练过程中的通用抓取检测网络模型进行损失计算;
13、直到交叉熵损失最小,得到对应的训练好的通用抓取检测网络模型。
14、进一步地,所述基于先验知识库中的抓取知识向量矩阵和物体的视觉图像,确定初始观测视角,具体为:
15、获取物体的视觉图像,利用预先训练好的视觉信息编码器进行图像降维,得到视觉图像特征向量;
16、基于余弦相似度匹配策略,计算先验知识库中的抓取知识向量矩阵和视觉图像特征向量的相似度系数;
17、抓取知识向量矩阵和视觉图像特征向量的相似度系数大于设定相似阈值时,则利用当前最相似的抓取知识向量矩阵,确定初始观测视角。
18、进一步地,所述利用当前最相似的抓取知识向量矩阵,确定初始观测视角,具体为:
19、基于当前最相似的抓取知识向量矩阵和预先设定好的多个物体观测点,利用两个全连接层组成的抓取知识检索模型进行预测;
20、得到多个物体观测点的遍历概率,选择概率数值最大的观测点,作为初始观测视角。
21、进一步地,所述利用抓取姿态预测结果、rgb分割图像以及机器人自身物理参数,基于具身判断原则对当前抓取过程进行质量评估,确定最优的抓取姿态,具体为:
22、利用抓取姿态预测结果、rgb分割图像以及机器人自身物理参数,计算当前观测点的候选抓取点的具身得分,计算公式如下:
23、;
24、其中,和为权重平衡系数,表示为不同的候选抓取点,表示为候选抓取点的总数,表示当前的观测点,为预先设定的多个固定观测点的观测轨迹,表示为计算当前数值的二范数,表示为在观测点的第个生成的预测抓取中心点位置,为当前物体在观测点时真实的中心对称点,为在观测点的第个预测的抓取宽度, s表示为当前观测点的候选抓取点的具身得分;
25、若当前观测点的候选抓取点的具身得分大于设定得分阈值时,则判定当前的抓取姿态是合适的,便执行抓取动作,并且保留当前抓取点的视角序号和视角图片;
26、反之,则继续探索当前观测点的下一个候选抓取点,直到完成对当前观测点的不同候选抓取点的具身得分,并将保留下的视角序号和视角图片按照得分高低进行排序保存。
27、进一步地,所述抓取姿态预测结果包括抓取点、抓取角度和抓取宽度。
28、进一步地,在完成抓取姿态预测结果的质量评估后,将得分最高的抓取姿态的视角序号和视角图片保存到先验知识库中。
29、进一步地,所述方法在训练时,利用得分最高的抓取姿态的视角序号和视角图片以及先验知识库,对抓取知识检索模型进行参数更新,具体为:
30、将得分最高的抓取姿态的视角序号和视角图片作为最优视角信息;
31、根据最优视角信息以及先验知识库中保留的最优视角信息构建带有伪标签的rgb视角样本图像;
32、基于带有伪标签的rgb视角样本图像对待训练的抓取知识检索模型进行参数更新;
33、利用交叉熵损失函数对训练过程中的抓取知识检索模型进行损失计算;
34、直到交叉熵损失最小,得到对应的训练好的抓取知识检索模型。
35、根据一些实施例,本发明的第二方案提供了一种基于知识驱动感知的服务机器人抓取系统,采用如下技术方案:
36、基于知识驱动感知的服务机器人抓取系统,包括:
37、初始观测视角确定模块,被配置为基于先验知识库中的抓取知识向量矩阵和物体的视觉图像,确定初始观测视角;
38、rgb图片信息分割模块,被配置为在初始观测视角下,获取当前视角的rgb图片信息,并对rgb图片信息进行分割,得到rgb分割图像;
39、抓取姿态预测模块,被配置为基于rgb图片信息,利用预先训练好的通用抓取检测网络模型进行抓取姿态预测,得到抓取姿态预测结果;
40、预测结果评估抓取模块,被配置为利用抓取姿态预测结果、rgb分割图像以及机器人自身物理参数,基于具身判断原则对当前抓取过程进行质量评估,确定最优的抓取姿态,并根据最优的抓取姿态执行抓取。
41、根据一些实施例,本发明的第三方案提供了一种机器人。
42、一种机器人,包括:
43、机器人本体;及
44、搭载在所述机器人本体上的机器人抓取执行机构、机器人抓取控制器以及存储在机器人抓取控制器上被其执行的计算机程序;
45、所述机器人抓取控制器执行所述计算机程序时实现如上述第一方案所述的基于知识驱动感知的服务机器人抓取方法中的步骤。
46、与现有技术相比,本发明的有益效果为:
47、本发明为了提升服务机器人抓取检测系统在不同场景的动态适应能力,提出了一种基于知识驱动感知的服务机器人抓取方法,用于不同场景下的机器人自主抓取检测,并根据机器人自身的能力提高机器人在未见过环境中抓取技能的泛化性能。
48、本发明旨在基于机器人在新环境下的基于具身感知能力来自主的采集样本,并根据自身的操作空间约束、爪子开合角度、物体中心位置对预测的物体抓取点进行评估打分,从而获取无需人类干预的带有伪标签的样本,完善自己的抓取模型和知识检索模型,提高新环境下抓取技能的泛化性能,实现长久自治性;借助采集的样本提升自身的抓取能力,以消除人为干预,实现自主性。以采集的伪标签样本和观测视角为条件,可以优化抓取检测过程和知识注入模型。可以通过其具身感知和知识检索能力在不断变化的场景中持续工作。
- 还没有人留言评论。精彩留言会获得点赞!