自适应英语词汇学习分级推题装置及计算机学习系统的制作方法
本发明涉及一种在线学习装置,尤其是涉及一种自适应英语词汇学习分级推题装置及计算机学习系统。
背景技术:
随着计算机网络的广泛应用与移动端设备的普及,不同阶段的用户群体在碎片时间使用手机软件进行学习的场景越来越多,词汇作为学习英语的基础,其占比在上述描述的场景中也较大。
在目前市面上的产品中,大多数词汇学习产品均以某本词书为目标导向,向用户提供的所有待学习知识点均为提前人工设置的,而没有根据用户自身情况定制学习内容或动态修改学习目标;并且国内外的词汇学习产品,单个知识点的学习路径非常固定,没有考虑不同能力的学生对各题型的接受程度。
此外,目前国内外面向学生的自动推荐技术研究尚不深入,尤其是在探索基于主观性特征及其结合查询意图特征的评论价值自动评估,以及最佳学习内容的自动识别、匹配、组织与推荐方面的研究尚属空白。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种自适应英语词汇学习分级推题装置及计算机学习系统。
本发明的目的可以通过以下技术方案来实现:
一种自适应英语词汇学习分级推题装置,包括:
图谱划分模块,用于对英语词汇学习进行知识点划分及各知识点下的题目难度等级划分;
存储模块,用于存储默认学习路径;
输入模块,用于获取用户的学习目标;
采集模块,用于采集并保存用户学习行为数据;
推送模块,用于根据所述学习目标调用所述默认学习路径,同时分析所述用户学习行为数据,结合分析结果生成实时学习路径,根据该实时学习路径推送题目。
进一步地,每个所述知识点上带有至少一个学习目的标签。
进一步地,所述学习目的标签采用大数据技术采集多用户的学习行为数据动态调整。
进一步地,所述难度等级划分根据题型本身难度、知识点难度以及题干选项难度确定。
进一步地,一条所述默认学习路径与一个知识点对应。
进一步地,所述用户学习行为数据包括答题时间、答题日志和讲义查看时长与深度。
进一步地,保存所述用户学习行为数据的同时,保存数据产生时间,时间越早的数据,分析价值越低。
进一步地,所述分析结果包括知识点独立水平、用户综合水平、题型综合适应度和错误类型。
进一步地,该装置还包括:
检测模块,用于对所述学习目标进行兼容冲突检测,并在检测到冲突时向所述输入模块发送警告提示。
本发明还提供一种自适应英语词汇计算机学习系统,包括如权利要求1所述的自适应英语词汇学习分级推题装置。
与现有技术相比,本发明具有以如下有益效果:
1、本发明对英语词汇进行了图谱划分,可以根据用户学习目标及历史学习行为数据产生最适合用户的实时学习路径,动态调整实时,针对性强,有效提高用户学习效率。
2、本发明通过人工智能的算法,根据用户的答题时间和答题难度,可以精确的了解到用户的薄弱知识点。
3、本发明可精确的了解到用户对不同题型的接受程度,以优化词汇学习中为不同人群推荐的题目范围,进一步提高学习效率。
4、本发明对用户学习行为数据进行分析时,时间越早的数据,其分析价值会变得越低,实现对用户学习行为数据的动态分析调整,以更加适应于用户学习状态的变化,提高学习效率。
5、本发明还设置检测模块,可以学习目标的兼容性进行检测,提高学习路径产生的准确率。
附图说明
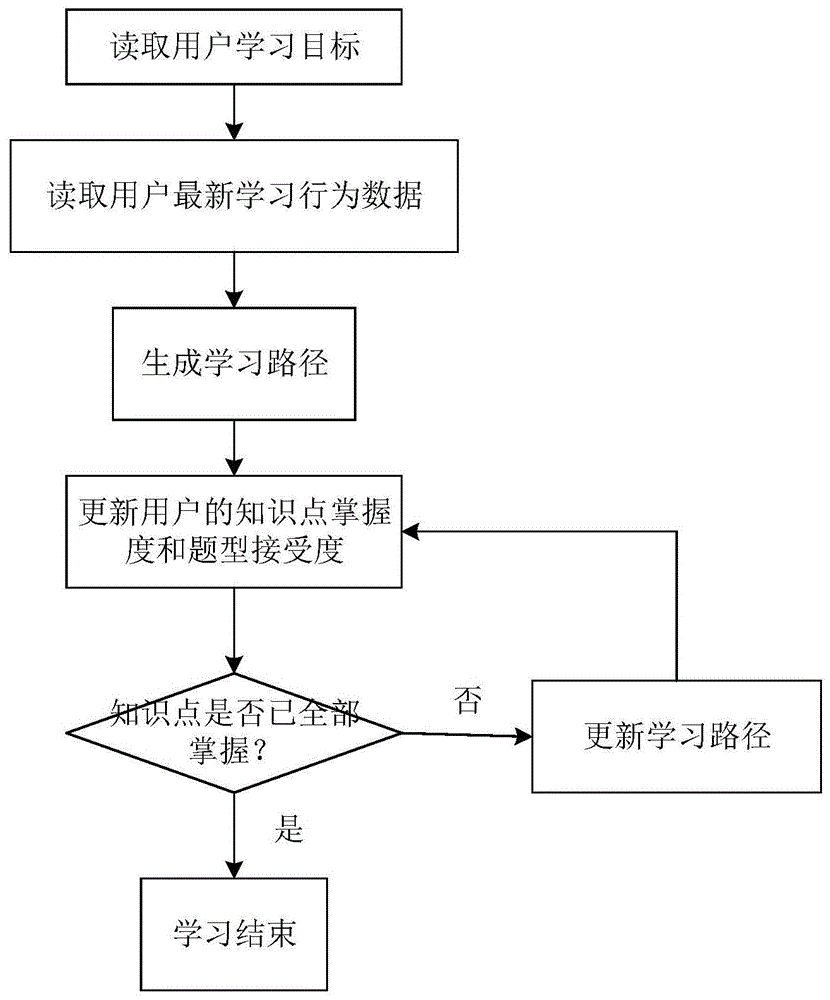
图1为本发明装置的工作流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例1
本发明提供一种自适应英语词汇学习分级推题装置,包括图谱划分模块、存储模块、输入模块、采集模块和推送模块,其中,图谱划分模块用于对英语词汇学习进行知识点划分及各知识点下的题目难度等级划分;存储模块用于存储默认学习路径;输入模块用于获取用户的学习目标;采集模块用于采集并保存用户学习行为数据;推送模块用于根据所述学习目标调用所述默认学习路径,同时分析所述用户学习行为数据,结合分析结果生成实时学习路径,根据该实时学习路径推送题目。
图谱划分模块中,按专题、分类法划分每个知识点,并建立前后置关系,为每个知识点打上自己所属的学习目的标签,并对每个词汇知识点进行难度等级的划分。前后置关系如:mother和grandmother同属于人物称谓中的家庭关系称谓,但mother会作为grandmother的前置知识点之一,他们的关联系数可能是0.75(此处举例的0.75并非实际系统中参数值)。
所述学习目的标签采用大数据技术采集多用户的学习行为数据动态调整,标签属性包括答题时间和题目难度。每个所述知识点上带有至少一个学习目的标签,单个知识点存在对应多标签的情况。
每一题目都有很多大量用户做题后动态生成的标签属性。基于标签属性,可根据用户的答题时间和答题难度从多维度的更精准的得出用户对于该知识点的掌握程度即能力值。
本实施例中,难度等级共划分为9级。所述难度等级划分根据题型本身难度、知识点难度以及题干选项难度确定。
存储模块中一条所述默认学习路径与一个知识点对应。本实施例中,默认学习路径为一条部分可跳过的学习路径。学习路径一般包含词汇音、形、义的学习,其中音、形、义各自的学习路径均由算法根据用户实时数据得出。
所述用户学习行为数据包括答题时间、答题日志和讲义查看时长与深度,通过对用户学习行为数据的分析,可获得用户的每个知识点的掌握度及各题型的接受度等,所述分析结果包括知识点独立水平(如0.1~10.0级)、用户综合水平(如0.1~10.0级)、题型综合适应度(如0.1~10.0级)和错误类型(包含细分知识点),推送模块可根据分析结果计算并更新该用户各知识点的能力值、各题型的认知与适应程度,推荐最合适用户学习的题目。
本发明的另一实施例中,该装置还包括检测模块,用于对所述学习目标进行兼容冲突检测,并在检测到冲突时向所述输入模块发送警告提示。学习目标间需要相互兼容,在检测模块中存储有无法同时满足的学习目的(需要具体说明),这种关系类似“既要向东又要向西走”,如:应试类的学习目标与专业术语类学习目标是相对独立甚至部分不兼容的,以使学习路径的推荐更加准确可靠。
保存所述用户学习行为数据的同时,保存数据产生时间,时间越早的数据,分析价值越低。
如图1所示,上述自适应英语词汇学习分级推题装置的推题过程具体为:
读取用户学习目标;
读取用户最新学习行为数据;
生成学习路径,产生并推送用户在每个知识点需要做的题目;
实时根据答题结果、答题耗时、题型、知识点能力值等信息更新用户的知识点掌握度和题型接受度;
判断知识点是否已全部掌握,若是,则学习结束,产生学习报告,若否,则更新学习路径,推送下一个知识点及相应题目。
实施例2
本实施例提供一种自适应英语词汇计算机学习系统,包括如实施例1所述的自适应英语词汇学习分级推题装置。
本实施例对新加入用户及用户常规学习过程进行具体学习过程说明。
对于新注册的用户需要确定自己的词汇学习目标,此目标可以由多个互不冲突的学习目标共同构成,如:过六级和考雅思;但两个相互冲突的目的则无法共存,如:学英音和学美音。
在常规学习流程中,用户从词汇的音、形、义三方面进行词汇学习,学习系统根据用户设定的目标,结合平台用户产生的平均数据,智能规划用户的词汇学习路径,即词汇学习顺序,此路径在后续的学习中不断由算法优化并进行调整。
在音、形、义的学习中,均已设置了分布于1~9共9个难度等级的题目,对于单个知识点,本实施例共设置了72条学习路径,其中还不包含单个路径(即单个题目)上的题干难度变化、误导项难度变化。
首先,学生进行发音练习,此类题型由于采集精度较低,对能力值的影响权重同样设置为最小,练习完成后开始知识点学习,包含知识点基础信息与音视频讲解,学习过程中同时根据用户对该知识点的发音准确率、答题时长为基本数据,同时辅以关联知识点的学习数据、学习页面停留时长、音视频讲解查看情况等综合考量,由智适应算法引擎计算得出用户在第一轮练习中(词义练习)需要做的题目。
从词义练习开始正式进入练习题流程,每道题的答题时长、作答情况(是否正确、错误时的选项)均会影响到知识点后续的学习路径,同时系统为了满足知识点学习密度的控制要求,设置初始x=10个知识点为一组,该变量由用户实际学习效果进行动态调整;词义练习的具体路径与路径长度对于每个用户、每个知识点均可能不同。
上述两轮练习中,对单个知识点的能力值计算均用到了加权平均公式:
其中,x1、x2…xk为该知识点及所有关联知识点的能力值,f11、f2…fk为系统预设的权重值,该权重值会定期(如:一周或新数据增量累积达到1w条时)根据平台用户的数据由算法进行离线微调。每次微调时,时间越早的数据,其参考价值会变得越低(相对占比和权重降低),而增量数据的权重会相对较高,具体调整公式由基础的机器训练模型和科学家提供的公式结合而成。
最后在用户关于形(拼写)的练习中,除了知识点能力值的应用外,题型的适应程度也同样作为一大考量因素,在拼写题的推荐过程中,算法主要考虑题干部分的是用词义还是音频,题目部分是全拼或是部分拼写,全拼与部分拼写的形式是输入型还是选择型;如果是选择型或是部分拼写,系统会根据用户对该知识点的最终能力值,匹配合适的干扰选项或挖空合适的部位;对能力值高的用户而言,干扰项与正确答案的相似度更高,挖空部分的规则越模糊;对于能力值较低的用户而言,干扰项的错误引导性更低,挖空部分的规则更清晰(如:词根词缀记忆法)。
综上为单个知识点的智适应分级推题系统的实现方法,对于一个用户的完整学习目标,系统需依据预先设定的目标值、历年考题情况等参数判断当前用户的目标完成比例,并根据此用户的综合学习情况准确定位用户词汇学习的漏洞。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!