一种轨道交通运输仿真培训的语音行为考核评价方法与流程
[0001]
本发明涉及轨道交通运输仿真培训技术领域,更具体地说,它涉及一种轨道交通运输仿真培训的语音行为考核评价方法。
背景技术:
[0002]
轨道交通运输已成为我国最主要的交通运输方式之一,已经成为我国经济发展的动脉,以其独有的安全、运量大、快速、准时、舒适等优点,深受广大社会群众的喜爱。
[0003]
随着轨道交通运输的发展,越来越多的岗位对人才的需求量不断增大,现在的人才培训方式成效已经较传统的人才培养方式成效有所提高。传统的人才培训过程中,主要通过人工评价学员的语言指令是否正确和规范,其评价结果过于主观化、随意化,易受判断人员的专业知识影响,同时学员无法及时得知自己语音指令是否正确和规范。目前,部分的仿真系统通过对需要的语音指令进行语言识别后,提取语音信息中主要的关键词作为识别评价的主要因素,但这种方式不仅容易受环境噪声影响,且受关键词直接对比结果影响,导致评价结果的精确度跨度较大,评价结果误差大,无法实现高精度评价;此外,实时语音推送给教员评价的方式占用大量带宽,增加教员的工作量,灵活性较差。
[0004]
因此,如何研究设计一种一种轨道交通运输仿真培训的语音行为考核评价方法是我们目前急需解决的问题。
技术实现要素:
[0005]
为解决现有轨道交通全专业培训仿真系统在各专业学员培训过程中无法客观、准确的对学员语音进行评价以及学员无法得知自己语音指令是否正确和规范的问题,本发明的目的是提供一种轨道交通运输仿真培训的语音行为考核评价方法。
[0006]
本发明的上述技术目的是通过以下技术方案得以实现的:一种轨道交通运输仿真培训的语音行为考核评价方法,包括以下步骤:
[0007]
s101:通过智能语音识别技术对培训过程中学员的语音交流信息进行识别后转化为文字信息;
[0008]
s102:通过关键词识别技术判断并提取整个语句中的所有关键词,并将提取的关键词依次按照语义相关、设备相关、专业术语相关进行分类;
[0009]
s103:通过深度神经网络自动识别语音交流信息后得到标准语音数据,将标准语音数据与语音评价数据库匹配后得到唯一匹配的标准评价数据;
[0010]
s104:将标准语音数据与标准评价数据比较分析后判断语音交流信息的语义以及触发时机是否正确;
[0011]
s105:若语义、触发时机判断均正确,则将语音交流信息中提取的关键词与标准评价数据中的标准关键词进行关联关系对比分析,并通过模糊控制函数得到语义相关、设备相关、专业术语相关的关键词隶属函数;
[0012]
s106:根据语义相关关键词隶属函数、设备相关关键词隶属函数、专业术语相关关
键词隶属函数的权重系数建立综合隶属函数,并依据综合隶属函数进行综合计算后得到语音交流信息的自主评价分数。
[0013]
进一步的,所述语音交流信息识别转化具体为:利用windows speech sdk开发包中tts引擎、sapi接口和win32api接口,在mfc框架下建立语音转换文本的应用程序单元,语音交流信息输入应用程序单元后自动转换成文本信息。
[0014]
进一步的,所述关键词识别提取具体为:
[0015]
将语音交流信息与关键词数据库一一对比,分别得到语音交流信息中所含的语义相关关键词、设备相关关键词、专业术语相关关键词;
[0016]
关键词数据库通过读取语音评价数据库中语义相关、设备相关、专业术语相关的关键词进行构建,结构具体为:
[0017][0018]
其中,设备相关关键词用于识别学员间描述设备信息的准确性,语义相关关键词用于识别学员间描述的语义进行判断,专业术语关键词用于识别学员间描述专业信息的专业性。
[0019]
进一步的,所述标准语音数据识别具体为:
[0020]
通过gbk编码将语音交流信息转化为数字,并将每个数字转化为输入矩阵x
t
中的一个元素x
i
,得到输入矩阵x
t
;
[0021]
通过对前一刻的语音交流信息与前一刻的隐藏值进行运算,得到当前的隐藏层值,具体如下:
[0022][0023]
其中,矩阵u表示输入矩阵x
t
的权重系数矩阵,维度为n*m,根据培训不同的工种进行切换数值;s表示隐藏层值向量,维度为n;w表示隐藏层值的权重系数矩阵,维度为n*m;
[0024]
通过输出方程计算,得到输出函数矩阵,具体为:
[0025]
o
t
=g(vs
t
)*ξ
[0026]
其中,o
t
表示输出函数矩阵;g为运算法则;v表示隐藏层权重系数矩阵;s
t
表示当前隐藏层数值;ξ表示触发时机判断系数,触发时机正确,则ξ赋值为1;触发时机错误,则ξ赋值为0;
[0027]
矩阵o
t
表示标准语音信号的gbk编码,通过gbk编码转化成汉字,可以得到语音交流信息的标准语音数据。
[0028]
进一步的,所述语音评价数据库具体为:
[0029]
语音评价数据库包含全专业各工种所用到的全部标准用语,共有语音数据i条,相对应的语音评价数据库结构如下:
[0030]
[0031]
将标准语音数据与语音评价数据库匹配后得到唯一匹配的标准语义及触发时机i
x
,i
x
表示标准的语音数据信号,将标准的语音数据信号作为输入信号进行自主、客观化的评价,具体结构为:
[0032]
[编号i
x
语义相关i
x
设备相关i
x
专业术语相关i
x
语句i
x
]
[0033]
其中,编号用于对语音评价数据库中每条数据进行编号管理;语义相关、设备相关、专业术语相关作为自主客观化评价的关键因素;语句表示该语句的标准描述方法,作为标准语音数据输入匹配的关键因素。
[0034]
进一步的,所述触发时机判断具体为:
[0035]
根据系统状态反馈信号和当前所处环境对学员触发的语音信号进行判断,通过触发时机判断得到语句隶属函数,具体为:
[0036][0037]
其中,a表示触发时机隶属临界值;当语音信号触发时机正确时,x>a;当语音信号触发时机错误时,x≤a。
[0038]
进一步的,所述语义相关关键词隶属函数具体为:
[0039]
y
dc
(y,b,c)=c/(|y-b|+c)
[0040]
其中,b表示语义最佳隶属值,代表语义判断与语音评价数据库完全一致,取值为语音评价数据库中语义相关关键词个数,通过系统特性计算得到c=0.4b;随着语义的简单表述或者复杂表述,其隶属值的下降;当隶属值达到b-c/b+c时,隶属函数隶属度下降至最高隶属度的1/3。
[0041]
进一步的,所述设备相关关键词隶属函数具体为:
[0042][0043]
其中,d表示设备相关关键词隶属度饱和点,此后设备隶属度函数值为1;d-e表示设备相关点,根据系统特性计算得知e=0.6d;当z∈(0,d-e)时,表示输入语音信号没有使用设备相关关键词;当z∈(d-e,d)时,表示输入语音信号使用设备相关关键词逐渐增加;当z∈(d,+∞)时,表示输入语音信号除了使用全部标准语句设备相关关键词外,还使用了其他相关设备关键词。
[0044]
进一步的,所述专业术语相关关键词隶属函数具体为:
[0045][0046]
其中,f表示专业术语表述完全准确,此时隶属度为1,随着专业术语的表述专业化下降,专业术语隶属度值不断下降,根据系统特性计算得知g=0.5f。
[0047]
进一步的,所述综合隶属函数具体为:
[0048]
u=(εy
dc
+λy
sc
+τy
rt
)
×
100
[0049]
其中,u表示该学员语音识别自主客观评价分数,代表学员在培训过程中语音规范水平;ε、λ、τ分别为语义相关关键词、设备相关关键词、专业术语相关关键词的权重系数;ε
∈[0,1]、λ∈[0,1]、τ∈[0,1],且ε+λ+τ=1。
[0050]
与现有技术相比,本发明具有以下有益效果:本发明通过深度神经网络技术与语音评价数据库经行匹配,可以得到完全规范、标准的语音数据。然后通过对输入语音进行关键词识别技术以及与标准语音数据库进行对比,可以对学员进行标准、客观的语音评价,杜绝了人工评价,增加系统的客观性,减轻教员的工作量,且直接通过与语音评价数据库进行对比,无需占用带宽,提升系统性能;本发明通过对对比结果进行评价计算后转换为百分制分数,能够精确、直观的展现学员的语音指令的规范程度和准确程度,实现可靠、合理、准确、快速的对轨道交通全专业培训仿真系统中各专业学员培训过程中的语音交流信息进行自主客观化的语音考核评价,学员能够通过自主客观评价分数直接得知自己语音指令是否正确和规范。
附图说明
[0051]
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
[0052]
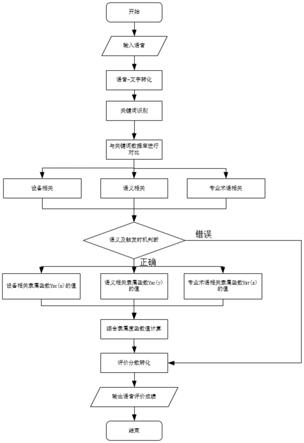
图1是本发明实施例中的整体流程图;
[0053]
图2是本发明实施例中的语义及触发时机判断函数示意图;
[0054]
图3是本发明实施例中的语义相关隶属函数示意图;
[0055]
图4是本发明实施例中的设备相关隶属函数示意图;
[0056]
图5是本发明实施例中的专业术语相关隶属函数示意图;
[0057]
图6是本发明实施例中的深度神经网络示意图。
具体实施方式
[0058]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图1-6,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0059]
实施例1
[0060]
一种轨道交通运输仿真培训的语音行为考核评价方法,如图1所示,包括以下步骤:
[0061]
s101:通过智能语音识别技术对培训过程中学员的语音交流信息进行识别后转化为文字信息;
[0062]
s102:通过关键词识别技术判断并提取整个语句中的所有关键词,并将提取的关键词依次按照语义相关、设备相关、专业术语相关进行分类;
[0063]
s103:通过深度神经网络自动识别语音交流信息后得到标准语音数据,将标准语音数据与语音评价数据库匹配后得到唯一匹配的标准评价数据;
[0064]
s104:将标准语音数据与标准评价数据比较分析后判断语音交流信息的语义以及触发时机是否正确;
[0065]
s105:若语义、触发时机判断均正确,则将语音交流信息中提取的关键词与标准评价数据中的标准关键词进行关联关系对比分析,并通过模糊控制函数得到语义相关、设备相关、专业术语相关的关键词隶属函数;
[0066]
s106:根据语义相关关键词隶属函数、设备相关关键词隶属函数、专业术语相关关键词隶属函数的权重系数建立综合隶属函数,并依据综合隶属函数进行综合计算后得到语音交流信息的自主评价分数。
[0067]
语音交流信息识别转化具体为:利用windows speech sdk开发包中tts引擎、sapi接口和win32api接口,在mfc框架下建立语音转换文本的应用程序单元,语音交流信息输入应用程序单元后自动转换成文本信息。
[0068]
关键词识别提取具体为:将语音交流信息与关键词数据库一一对比,分别得到语音交流信息中所含的语义相关关键词、设备相关关键词、专业术语相关关键词;关键词数据库通过读取语音评价数据库中语义相关、设备相关、专业术语相关的关键词进行构建,结构具体为:
[0069][0070]
其中,设备相关关键词用于识别学员间描述设备信息的准确性,语义相关关键词用于识别学员间描述的语义进行判断,专业术语关键词用于识别学员间描述专业信息的专业性。
[0071]
如图6所示,标准语音数据识别具体为:通过gbk编码将语音交流信息转化为数字,并将每个数字转化为输入矩阵x
t
中的一个元素x
i
,得到输入矩阵x
t
;通过对前一刻的语音交流信息与前一刻的隐藏值进行运算,得到当前的隐藏层值,具体如下:
[0072][0073]
其中,矩阵u表示输入矩阵x
t
的权重系数矩阵,维度为n*m,根据培训不同的工种进行切换数值;s表示隐藏层值向量,维度为n;w表示隐藏层值的权重系数矩阵,维度为n*m。
[0074]
通过输出方程计算,得到输出函数矩阵,具体为:
[0075]
o
t
=g(vs
t
)*ξ
[0076]
其中,o
t
表示输出函数矩阵;g为运算法则;v表示隐藏层权重系数矩阵;s
t
表示当前隐藏层数值;ξ表示触发时机判断系数,触发时机正确,则ξ赋值为1;触发时机错误,则ξ赋值为0;矩阵o
t
表示标准语音信号的gbk编码,通过gbk编码转化成汉字,可以得到语音交流信息的标准语音数据。
[0077]
语音评价数据库具体为:语音评价数据库包含全专业各工种所用到的全部标准用语,共有语音数据i条,相对应的语音评价数据库结构如下:
[0078][0079]
将标准语音数据与语音评价数据库匹配后得到唯一匹配的标准语义及触发时机i
x
,i
x
表示标准的语音数据信号,将标准的语音数据信号作为输入信号进行自主、客观化的评价,具体结构为:
[0080]
[编号i
x
语义相关i
x
设备相关i
x
专业术语相关i
x
语句i
x
]
[0081]
其中,编号用于对语音评价数据库中每条数据进行编号管理;语义相关、设备相关、专业术语相关作为自主客观化评价的关键因素;语句表示该语句的标准描述方法,作为标准语音数据输入匹配的关键因素。
[0082]
如图2所示,触发时机判断具体为:根据系统状态反馈信号和当前所处环境对学员触发的语音信号进行判断,通过触发时机判断得到语句隶属函数,具体为:
[0083][0084]
其中,a表示触发时机隶属临界值;当语音信号触发时机正确时,x>a;当语音信号触发时机错误时,x≤a。
[0085]
如图3所示,语义相关关键词隶属函数具体为:
[0086]
y
dc
(y,b,c)=c/(|y-b|+c)
[0087]
其中,b表示语义最佳隶属值,代表语义判断与语音评价数据库完全一致,取值为语音评价数据库中语义相关关键词个数,通过系统特性计算得到c=0.4b;随着语义的简单表述或者复杂表述,其隶属值的下降;当隶属值达到b-c/b+c时,隶属函数隶属度下降至最高隶属度的1/3。
[0088]
如图4所示,设备相关关键词隶属函数具体为:
[0089][0090]
其中,d表示设备相关关键词隶属度饱和点,此后设备隶属度函数值为1;d-e表示设备相关点,根据系统特性计算得知e=0.6d;当z∈(0,d-e)时,表示输入语音信号没有使用设备相关关键词;当z∈(d-e,d)时,表示输入语音信号使用设备相关关键词逐渐增加;当z∈(d,+∞)时,表示输入语音信号除了使用全部标准语句设备相关关键词外,还使用了其他相关设备关键词。
[0091]
如图5所示,专业术语相关关键词隶属函数具体为:
[0092][0093]
其中,f表示专业术语表述完全准确,此时隶属度为1,随着专业术语的表述专业化下降,专业术语隶属度值不断下降,根据系统特性计算得知g=0.5f。
[0094]
综合隶属函数具体为:
[0095]
u=(εy
dc
+λy
sc
+τy
rt
)
×
100
[0096]
其中,u表示该学员语音识别自主客观评价分数,代表学员在培训过程中语音规范水平;ε、λ、τ分别为语义相关关键词、设备相关关键词、专业术语相关关键词的权重系数;ε∈[0,1]、λ∈[0,1]、τ∈[0,1],且ε+λ+τ=1。
[0097]
实施例2
[0098]
以语音交流信息为“机车稍行移动,允许速度5公里/小时,行至出站信号机前”作为输入信号进行说明。假设语音评价数据库语音为“机车允许速度5公里/小时,行至出站信号机前”。当系统识别到语音信号后,首先通过windows speech sdk开发包中tts引擎开发
的智能语音识别程序,将语音信息转化为文字信息。
[0099]
其中,关键词识别技术主要将输入信号与关键词数据库进行一一对比,可以分别得到输入信号中所含的语义相关关键词、设备相关关键词、专业术语相关关键词,该方法通过大词汇量的标准关键词数据库识别系统,检测这段输入信号是否包含了关键词,这种方法响应速度快。
[0100]
其中,标准关键词数据库其实就是读取的标准语音数据库中的数据,主要读取标准语音数据库中语义相关、设备相关、专业术语相关关键词,构成一个新的关键词数据库,其结构具体为:
[0101][0102]
通过与关键词数据库进行对比,可以得知该输入信号中语义相关关键词为4个、设备相关关键词为2个、专业术语相关关键词2个。
[0103]
触发时机判断主要通过系统的状态及当前所处的环境进行分析,对学员触发的语音信号进行判断。由于本例中触发时机正确,故y
sen
(x,a)=1。
[0104]
通过深度神经网络运算,得到输出信号矩阵,通过gbk汉字转化,得到标准输出语音信号为“机车允许速度5公里/小时,行至出站信号机前”。
[0105]
通过与语音评价数据库q进行对比,可以匹配到有且仅有一条标准的语义及触发时机都对应的语音评价数据库条目,假设其编号为11253,其结构为:
[0106]
[11253允许、公里、小时机车、出站信号机速度机车允许速度5公里/小时,行至出站信号机前]
[0107]
输入信号通过与语音数据库对比,可知,语音评价数据库语义相关关键词3个,设备相关关键词2个,专业术语相关关键词1个。
[0108]
对于语义相关关键词隶属函数y
dc
,由于语义相关关键词为3个,故b=3,由系统特性计算可知,c=1.2,具体为:y
dc
(y,b,c)=1.2/(|y-3|+1.2),进而计算出y
dc
=0.55。
[0109]
设备相关关键词隶属函数y
sc
,由于设备相关关键词个数为2个,故d=2,通过系统特性计算出e=1.2,可得进而计算y
sc
=1。
[0110]
专业术语相关关键词隶属函数y
rt
,由于专业术语相关关键词为1个,故f=1,此时g=1,可得可知y
rt
=0。
[0111]
对三个隶属函数进行整合分析,根据每个因素的权重比建立新的综合隶属函数,依据综合隶属函数进行综合计算,得出学员该语音信息自主评价分数;对于不同的场景,三因素拥有不同的权重系数,因素隶属函数的权重系数用ε、λ、t表示。通过对此处场景分析,得到ε=0.5、λ=0.3、t=0.2,综合隶属函数定义如下:
[0112]
u=(εy
dc
+λy
sc
+τy
rt
)
×
100=(0.5
×
0.55+0.3
×
1+0.2
×
0)
×
100=57.5
[0113]
故该学员的语音识别自主客观化评价考核分数为57.5分。
[0114]
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1