一种基于人工智能的实验台教学系统的制作方法
本发明涉及实验教学设备,具体是指一种基于人工智能的实验台教学系统。
背景技术:
1、实验台是医院、学校、化工厂、科研院所等单位进行实验检测及存放仪器所使用的平台。人工智能教育注重理论与实践的结合,在人工智能的实践教学中,教学实验台起到重要的支撑作用。
2、然而,目前市场上的人工智能教育的教学实验台,实验台、控制系统、机器人以及其他教具是分开设置的,这样设置占有的空间较大,且在实际操作时受限,不利于进行人工智能的教育。
3、此外,由于设备和教师资源的限制,学生通常无法得到实时和个性化的反馈和指导,即教师在进行教学性实验演示的时候,出于安全的考虑,学生无法进行实验操作过程,而是在教师演示结束后再进行实验,这样就无法得到针对性的反馈指导,进而导致实验操作的效果不理想。并且,化学实验台使用过程中,存在着部分有害物质产生,需要对实验台的通风环境以及废弃物回收等方向进行严格管理。
技术实现思路
1、本发明目的在于提供一种基于人工智能的实验台教学系统,用于教学人员在进行语言教学时同步进行演示教学。
2、本发明通过下述技术方案实现:
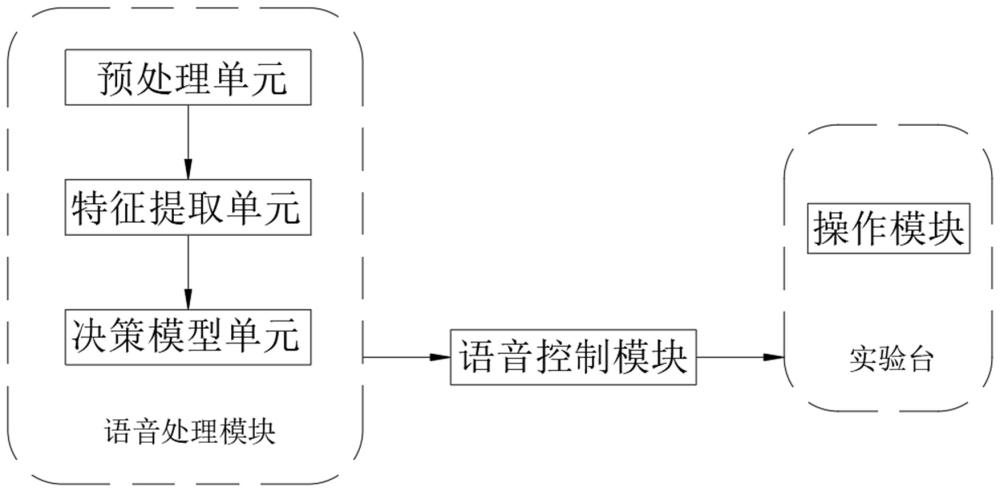
3、一种基于人工智能的实验台教学系统,包括实验台,还包括操作模块、语音处理模块以及语音控制模块,所述操作模块设置在所述实验台上,用于进行教学实验演示;所述语音处理模块用于进行语音输入与语音处理,语音处理完成后产生特征信号;所述语音控制模块与所述语音处理模块信号连接,用于根据所述特征信号产生指令信号;所述操作模块与所述语音控制模块信号连接,用于根据所述指令信号进行教学实验演示;其中,所述语音处理模块包括信号连接的预处理单元、特征提取单元以及决策模型单元,所述预处理单元进行的语音预处理过程依次包括:预加重、端点检测以及分帧加汉明窗处理;所述特征提取单元进行的特征提取过程依次包括:求mfcc系数以及求mfcc与lpcc结合的系数;所述决策模型单元基于hmm算法模型训练得到匹配模板,再通过匹配模板得到所述特征信号,所述hmm算法模型中,状态转移矩阵的对角线元素全为0,即各状态没有自转移弧。
4、需要说明的是,现有技术中,由于设备和教师资源的限制,学生通常无法得到实时和个性化的反馈和指导,即教师在进行教学性实验演示的时候,出于安全的考虑,学生无法进行实验操作过程,而是在教师演示结束后再进行实验,这样就无法得到针对性的反馈指导,进而导致实验操作的效果不理想。尽管现有技术中已经存在部分带有语音控制的机械系统,但是并未用于实验室教学环境下,并且由于实验室教学的复杂环境,包括但不限于学生的语言噪声、学生的动作噪声、设备的工作噪声等,均会对语音控制过程造成影响,再结合实验操作的实时性,就存在了发生衍生事故的风险。针对上述问题,提出了一种基于人工智能的实验台教学系统,通过将教师的操作演示实验与理论教学实验区分开,即实验台教学系统进行操作演示实验,教师同步进行理论教学实验,学生也能够同步跟随实验台教学系统进行实际演示,在这个过程中,教师能够在理论教学与巡视监管中切换,确保实验环境的安全进行,也极大程度地提高了教学效率。此外,还针对传统的语音控制系统应用于实验教学环境下,存在较多噪声干扰,控制不灵敏的问题,通过语音处理模块对输入的语音进行处理,处理过程包括预加重、端点检测以及分帧加汉明窗处理等,在处理过程中,通过将状态转移矩阵的对角线元素改进为0,即各状态没有自转移弧,克服了传统的hmm算法模型持续时间具有较大局限性的问题,进而更加突出语音信号的特征。
5、进一步地,所述语音处理模块还包括与所述预处理单元信号连接的时延分区单元,所述时延分区单元利用互相关函数的峰值对应的时间点为语音输入信号之间的时间延迟求解得到预处理区间,所述语音预处理过程在预处理区间内进行处理。需要说明的是,对于实验教学环境,其应用环境存在较多的噪声干扰,如学生的语言噪声、学生的动作噪声、设备的工作噪声等,对于传统的语音控制过程中的噪声处理,其处理的噪声并不是语音段中实际的噪声值,而是语音起点前那一段的噪声平均值,但是由于实际的噪声并不是平稳的而是随机变化的,这就会导致进行噪声处理时由于每帧的噪声不同而使去噪后的语音信号在不同帧之间会保留部分的残余噪声。区别于上述手段,在本技术中,通过时延分区单元来将到达语音处理模块内的语音信号间的时延来进行分区,进而分离出不含特征命令信号的区间单元,对于不含特征命令信号的区间单元不进行直接处理,对包含特征命令信号的区间单元进行后续处理来分离出特征信号。
6、进一步地,所述预处理单元在一个预处理区间内基于双门限端点检测法进行端点检测。需要说明的是,在自动语音识别等需要从语音信号中提取语音特征的过程中,语音端点的准确检测是影响系统性能的一个重要因素,因此,在一个预处理区间内基于双门限端点检测法来分析短时过零率来判断语音情况,进而判定出特征信号区间的端点。
7、进一步地,所述语音处理模块还包括与所述预处理单元信号连接的语音降噪单元,所述语音降噪单元用于对语音信号当前帧的多窗谱功率谱密度估计值进行相邻帧之间的加权平均。语音降噪单元的主要功能是处理语音信号,减少噪声,具体来说,语音降噪单元会对每一帧语音信号的功率谱密度进行估计,其中,功率谱密度是一种量化信号频率内容的方式,它可以用来描述信号在不同频率上的能量分布,这个估计值可以帮助我们理解语音信号中的噪声成分。语音降噪单元对相邻帧之间进行加权平均,目的是通过平均多个帧的信息,减少随机噪声对单个帧的影响,加权平均会给近期的帧更高的权重。总的来说,通过对语音信号进行谱分析和加权平均,帮助提高语音信号的质量和可理解性。
8、进一步地,所述决策模型单元还搭载了bp神经网络模型,并将hmm算法模型中所有状态累积概率作为所述bp神经网络模型的输入。所述决策模型单元的决策过程为:设定所述hmm算法模型的隐含状态个数为4,并初始化hmm算法模型;通过训练样本对hmm算法模型进行训练得到多种不同类型的hmm算法模型,即匹配模板;再将特征提取后的语音信号输入至匹配模板内,解码求解出各类型hmm算法模型下所有的累积输出概率;最后对累积输出概率进行归一化处理并将处理后的数据输入至bp神经网络模型进行识别决策得到特征信号。需要说明的是,对于hmm算法模型,其在进行语音信号出的过程中,还存在着分类能力较弱的问题,通过另一神经网络模型与其结合,当模型中的实际输出信号与期望输出信号之间存在误差时,这种混合模型能够根据误差来更新权值和阈值,即能够提高和改善语音识别系统的性能并为操作模块的准确控制识别奠定基础。
9、进一步地,所述教学系统还包括信号连接的投影模块与教学模块,所述教学模块包括教学反馈生成单元,用于根据学生的语音输入或文本输入,生成相应的教学反馈,所述教学反馈生成单元进一步包括反馈生成算法,所述反馈生成算法基于深度学习的自然语言生成,采用transformer模型,具体为:假设处理的输入序列是x = [x1, x2, ..., xn],其中xi表示序列中的第i个元素,一个词或者一个字符,寻找一个能够将序列x映射到输出序列y =[y1, y2, ..., ym]的函数f,其中yj表示输出序列中的第j个元素,在transformer模型中,该函数f定义方式为:,其中,qi,ki,,vi分别是查询(query)、键(key)和值(value),其通过学习得到的矩阵wq,wk,wv与输入xi相乘得到,“.”表示矩阵乘法;“t”表示转置;“sqrt”表示平方根;dk表示键的维度,该公式用于计算输出序列中的每一个元素;所述投影模块用于将教学模块内生成的教学反馈进行投影。
10、需要说明的是,针对教学模块,教学模块会收集一系列的输入,包括学生的问题或指令、实验的当前状态,以及其他相关信息,然后,这些输入会被转换成一个序列x,输入到模型中,模型会生成一个输出序列y,代表了系统应该给出的反馈,最后,这个反馈会被转换成人类可理解的文本,进而通过投影模块显示给学生。
11、本发明与现有技术相比,具有如下的优点和有益效果:
12、1、本发明通过将教师的操作演示实验与理论教学实验区分开,即实验台教学系统进行操作演示实验,教师同步进行理论教学实验,学生也能够同步跟随实验台教学系统进行实际演示,在这个过程中,教师能够在理论教学与巡视监管中切换,确保实验环境的安全进行,也极大程度地提高了教学效率;
13、2、本发明还针对传统的语音控制系统应用于实验教学环境下,存在较多噪声干扰,控制不灵敏的问题,通过语音处理模块对输入的语音进行处理,处理过程包括预加重、端点检测以及分帧加汉明窗处理等,在处理过程中,通过将状态转移矩阵的对角线元素改进为0,即各状态没有自转移弧,克服了传统的hmm算法模型持续时间具有较大局限性的问题,进而更加突出语音信号的特征;
14、3、本发明通过教学模块能够实时理解和处理学生的问题和需求,生成个性化的反馈和指导,从而帮助学生更好地理解和掌握实验知识,提高教学效率和效果。
- 还没有人留言评论。精彩留言会获得点赞!