焦面显示的制作方法
焦面显示
1.本技术是申请日为2018年1月8日,申请号为201880018483.4,发明名称为“焦面显示”的申请的分案申请。
2.背景
3.本公开总体上涉及增强来自电子显示器的图像,并且特别地涉及改变光学器件的焦距以增强图像。
4.头戴式显示器(hmd)可以用于模拟虚拟环境。传统的双目hmd用在虚拟场景中呈现给观看用户的信息来改变对视觉辐辏(vergence)的刺激,同时对调节(accommodation)的刺激如由观察光学系统(viewing optics)创建的,保持固定在显示器的视距处。持续的视觉辐辏调节冲突(vac)与视觉不适相关联,激发了用于实现接近恰当的调节提示的许多建议。
5.视觉辐辏是两只眼睛在相反方向上的同时移动或旋转以获得或维持与眼睛的调节有关联的双眼单视(single binocular vision)。在正常条件下,改变眼睛的焦点以看在不同距离处的对象自动引起视觉辐辏和调节。例如,当现实对象移动得更靠近看该现实对象的用户时,用户的眼睛向内旋转以保持逼近该对象。当对象变得更靠近用户时,眼睛必须通过减小焦强或焦距来“适应”于更近的距离,这通过每只眼睛改变它的形状来自动实现。因此,在现实世界中的正常条件下,视觉辐辏深度对应于用户正在看的地方,这也等于用户的眼睛的焦距。
6.然而,一些三维(3d)电子显示器常常出现视觉辐辏和调节之间的冲突。例如,当虚拟对象被再现在3d电子显示器上以移动得更靠近看该对象的用户时,用户的每只眼睛向内旋转以保持逼近该对象,但是每只眼睛的焦强或焦距没有减小;因此,用户的眼睛不如在现实世界中一样的适应。不是减小焦强或焦距以适应于更近的视觉辐辏深度,而是眼睛保持调节在与3d电子显示器相关的距离处。因此,对于显示在3d电子显示器上的对象,视觉辐辏深度常常不等于人眼的焦距。在视觉辐辏深度和焦距之间的这个差异被称为“视觉辐辏调节冲突”。只经历视觉辐辏或调节(而不是同时经历两者)的用户可能经历某种程度的疲劳或恶心,这对于虚拟现实系统创建者是不希望有的。
7.概述
8.头戴式显示器(hmd)使用空间可编程的聚焦元件(例如在相位调制模式中操作的空间光调制器)来调整从电子显示器接收的虚拟场景的光的相位。例如,头戴装置(headset)接收虚拟场景的虚拟场景数据,该虚拟场景数据包括在虚拟场景中的不同部分或点的场景几何数据或深度值。在虚拟场景的光由观看虚拟场景的用户的眼睛接收到之前,空间光调制器(slm)调整虚拟场景的光的聚焦模式或波阵面(wavefront)。虽然传统的头戴式显示器通常实现单个固定焦面(focal surface),但是slm作为具有在空间上变化的焦距的可编程透镜来进行操作,允许hmd的显示的不同像素的虚拟图像(从hmd的出射光瞳)看起来形成在虚拟场景内的不同深度处,从而使合成焦面成形以符合虚拟场景几何形状。
9.为了确定在虚拟场景中的焦面的位置,虚拟场景的深度值的范围基于场景几何数据来被近似到一组一个或更多个离散深度值。在一个实施例中,虚拟场景中的场景点基于
它们的相关深度值被聚集,以识别对应于每个集群(cluster)的平均深度值的该组一个或更多个离散深度值。虚拟场景的深度然后被分割成在虚拟场景内的一个或更多个离散深度值中的每一个处的一个或更多个焦平面(focal plane)。因此,对于每个焦平面,焦平面的形状被调整以最小化焦平面到集群中的每个场景点的距离。这将焦平面的形状扭曲(warp)到开始将焦平面称为焦面是合理的情况,因为焦平面被弯曲、扭曲和/或调整以符合在虚拟场景中的最接近焦平面的一组场景点、部分或特征。由此产生的焦面的形状是连续的分段平滑三维曲线,与具有位于固定焦深处的平坦表面的多焦点显示不同。因此例如,场景可以被分割成三个焦面(近、中间、远),每个焦面被不同地弯曲或扭曲以分别符合在虚拟场景中的(近、中间、远)对象。
10.给定一组焦面,为每个焦面生成相位函数。相位函数当由slm执行时使slm再现对应于每个焦面的聚焦模式。这通过slm将相位延迟添加到来自电子显示器的光的波阵面来实现。相位延迟使波阵面的形状被弯曲并扭曲成每个焦面的形状,从而产生符合场景几何形状的聚焦模式。
11.根据本发明的实施例在针对方法、存储介质和系统的所附权利要求中被具体公开,其中在一个权利要求类别(例如方法)中提到的任何特征也可以在另一个权利要求类别(例如系统、计算机程序产品)中被要求保护。在所附权利要求中的从属性或往回引用仅为了形式原因而被选择。然而,也可以要求保护由对任何前面的权利要求的有意往回引用(特别是多项引用)而产生的任何主题,使得权利要求及其特征的任何组合被公开并可以被要求保护,而不考虑在所附权利要求中选择的从属性。可以被要求保护的主题不仅包括如在所附权利要求中阐述的特征的组合,而且还包括在权利要求中的特征的任何其他组合,其中在权利要求中提到的每个特征可以与在权利要求中的任何其他特征或其他特征的组合相结合。此外,本文描述或描绘的实施例和特征中的任一个可以在单独的权利要求中和/或以与本文描述或描绘的任何实施例和特征的组合的形式或以与所附权利要求的任何特征的任何组合的形式被要求保护。
12.在实施例中,一种系统包括:
13.至少一个处理器;
14.电子显示元件,其被配置为显示虚拟场景;以及
15.存储器,其包括指令,该指令当由至少一个处理器执行时使至少一个处理器:
16.基于为虚拟场景获得的场景几何形状来将虚拟场景分割成在虚拟场景中的一组焦面,每个焦面与一组最近场景点相关联;
17.调整每个焦面的形状以最小化在对于焦面的一组最近场景点中的每个场景点与焦面之间的距离;
18.为每个焦面生成相位函数,用于调整与焦面的所调整的形状一致的虚拟场景的光的波阵面;以及
19.光学块(optics block),其包括空间可编程的聚焦元件,该聚焦元件被配置为:
20.从电子显示元件接收虚拟场景的光的波阵面;
21.针对该组焦面中的每个焦面,基于与焦面相关联的相位函数来调整波阵面;以及
22.经由系统的出射光瞳来向用户提供对于每个焦面的虚拟场景的光的所调整的波阵面。
23.在实施例中,存储器包括指令,该指令当由至少一个处理器执行时还使至少一个处理器:
24.聚集虚拟场景中的场景点,每个场景点与对应于虚拟场景中的场景点的位置的场景几何数据相关联;以及
25.基于所聚集的场景点和相关联的场景几何数据来确定该组焦面中的每一个焦面的位置。
26.在实施例中,存储器还包括指令,该指令当由至少一个处理器执行时使得至少一个处理器:
27.对于每个相位函数,确定待显示在电子显示元件上的虚拟场景的彩色图像。
28.在实施例中,每个焦面的所调整的形状是在空间上变化的分段平滑曲线。
29.在实施例中,调整每个焦面的形状以最小化对于焦面的该组最近场景点中的每个场景点与焦面之间的距离包括:
30.在对于焦面的该组最近场景点中的每一个之间应用非线性最小二乘法优化。
31.在实施例中,空间可编程的聚焦元件对针对该组焦面中的每个焦面的波阵面的调整进行时间多路复用。
32.在实施例中,每个相位函数通过引入与焦面的形状相关联的相位延迟来针对每个相应的焦面移动来自电子显示元件的光,并且其中,每个焦面是连续变化的形状或不连续的表面中的至少一种。
33.在实施例中,提供了一种头戴式显示器(hmd),其包括:
34.至少一个处理器;
35.电子显示元件,其被配置为显示虚拟场景;
36.空间光调制器(slm),其被配置为:
37.接收来自电子显示元件的对于虚拟场景的光的波阵面;
38.在一个或更多个第一时间调整来自电子显示元件的光的波阵面,以为相对于hmd的出射光瞳位于虚拟场景中的第一深度处的第一焦面提供聚焦;
39.在一个或更多个第二时间调整来自电子显示元件的光的波阵面,以为相对于hmd的出射光瞳位于虚拟场景中的第二深度处的第二焦面提供聚焦;以及
40.将为第一焦面和第二焦面提供聚焦的光的所调整的波阵面引导到hmd的出射光瞳,对于第一焦面和第二焦面的光的波阵面组合在一起。
41.在实施例中,slm在一个或更多个第一时间和一个或更多个第二时间之间,对针对第一焦面和第二焦面的波阵面的调整进行时间多路复用。
42.在实施例中,生成第一焦面和第二焦面包括:
43.基于为虚拟场景获得的场景几何形状来将虚拟场景分割成第一焦面和第二焦面,第一焦面与第一组最近场景点相关联,以及第二焦面与第二组最近场景点相关联;
44.调整第一焦面的第一形状以最小化在对于第一焦面的第一组最近场景点中的每个场景点与第一焦面之间的第一距离;
45.调整第二焦面的第二形状以最小化在对于第二焦面的第二组最近场景点中的每个场景点与第二焦面之间的第二距离;以及
46.为第一焦面和第二焦面中的每一个生成相位函数,以用于调整与第一焦面和第二
焦面的所调整的形状一致的虚拟场景的光的波阵面。
47.在实施例中,hmd还包括:
48.聚集虚拟场景中的场景点,每个场景点与对应于在虚拟场景中的场景点的位置的场景几何数据相关联;以及
49.基于所聚集的场景点和相关联的场景几何数据来确定第一焦面的第一深度和第二焦面的第二深度。
50.在实施例中,hmd还包括:
51.对于每个相位函数,确定待显示在电子显示元件上的虚拟场景的彩色图像。
52.在实施例中,调整第一焦面的第一形状和第二焦面的第二形状包括:
53.通过在对于第一焦面的第一组最近场景点中的每一个之间应用非线性最小二乘法优化来确定第一焦面的第一形状;以及
54.通过在对于第二焦面的第二组最近场景点中的每一个之间应用非线性最小二乘法优化来确定第二焦面的第二形状。
55.在hmd的一个实施例中,每个相位函数通过引入与第一焦面的第一形状和第二焦面的第二形状相关联的相位延迟来针对第一焦面和第二焦面的每一个移动来自电子显示元件的光,并且其中,第一焦面和第二焦面中的每一个是连续变化的形状或不连续的表面中的至少一种。
56.在实施例中,一种方法包括:
57.获得包括识别与虚拟场景中的每个场景点相关联的深度的场景几何数据的虚拟场景;
58.基于场景几何数据来将虚拟场景分割成一组焦面,每个焦面与一组最近场景点相关联;
59.调整每个焦面的形状以最小化在对于焦面的该组最近场景点中的每个场景点与焦面之间的距离,所调整的形状是在空间上变化的分段平滑曲面;以及
60.对于每个焦面,生成针对空间光调制器(slm)的相位函数以调整从电子显示元件接收的虚拟场景的光的波阵面,相位函数当由slm应用时在波阵面中引入相位延迟,使得再现对应于焦面的所调整的形状的聚焦模式。
61.在实施例中,基于场景几何形状来将虚拟场景分割成一组焦面包括:
62.聚集虚拟场景中的场景点;以及
63.基于所聚集的场景点和相关联的场景几何数据来确定该组焦面中的每一个焦面的深度。
64.在实施例中,该方法还包括:
65.对于每个相位函数,确定对于每个焦面的待显示在电子显示元件上的虚拟场景的彩色图像。
66.在实施例中,slm和电子显示元件被包括在头戴式显示器中,并且slm基于相应的相位函数来对针对每个焦面的波阵面的调整进行时间多路复用以使虚拟场景的合成图像通过头戴式显示器的出射光瞳被提供给观看虚拟场景的用户。
67.在该方法的实施例中,每个相位函数通过引入与每个焦面的形状相关联的相位延迟来针对每个焦面移动来自电子显示元件的光,并且其中,每个焦面是连续变化的形状或
不连续的表面中的至少一种。
68.在实施例中,调整每个焦面的形状以最小化在对于焦面的该组最近场景点中的每个场景点与焦面之间的距离包括:
69.在对于焦面的该组最近场景点中的每一个之间应用非线性最小二乘法优化。
70.附图简述
71.图1示出了根据至少一个实施例的可以合并到头戴式显示器中的光学系统的示例光线图。
72.图2示出了根据至少一个实施例的示例系统。
73.图3示出了根据至少一个实施例的头戴式显示器的图示。
74.图4示出了根据至少一个实施例的用于减轻视觉辐辏调节冲突的示例过程。
75.附图仅为了说明的目的描绘本公开的实施例。本领域中的技术人员将从下面的描述中容易认识到,在本文中示出的结构和方法的替代实施例可以被采用而不偏离本文描述的本公开的原理或所推崇的益处。
76.详细描述
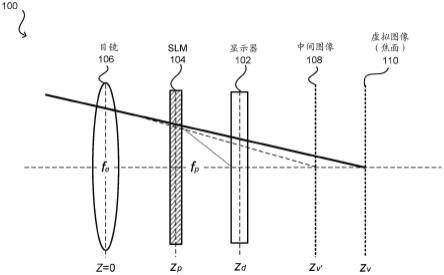
77.传统的头戴式显示器包含提供单个固定焦面的目镜和电子显示器。图1示出了焦面显示器100,其包括电子显示元件(“显示器”)102和在目镜106和显示器102之间的调相空间光调制器(slm)104。slm 104作为具有在空间上变化的焦距的可编程透镜来进行操作,允许显示器102的不同显示像素的虚拟图像110看起来形成在虚拟场景内的不同深度处。因此,slm 104充当动态自由透镜,使符合虚拟场景几何形状的合成焦面成形。因此,公开了用于将虚拟场景分解成这些焦面中的一个或更多个的系统和方法。
78.表示场景几何形状的深度图和对视网膜模糊(retinal blur)随着调节中的变化的改变进行建模的焦点堆栈(focal stack)被提供到系统作为输入。在一个实施例中,两个输入都从观看用户的入射光瞳的角度被再现,并且系统的输出是k个相位函数φ1,...,φk和彩色图像c1,...,ck以由slm 104和显示器102呈现。理想地,相位函数和彩色图像被联合优化;然而,这导致大的非线性问题。因此,近似被引入以确保该方法是在计算上易处理的。首先,不是说明在虚拟场景中的每个可能的深度,而是虚拟场景的深度图被分解或分割成一组平滑的焦面,虚拟场景的至少大部分(如果不是的话,全部)深度可以被逼近到这组平滑的焦面。然后,slm的相位函数被优化以逼近这些焦面。最后,彩色图像被优化以再现目标焦点堆栈。因此,虽然所公开的系统提供了多个焦面,但是单个焦面可以在理论上实现相似的视网膜模糊保真度;然而,相对于由其他现有的多焦点显示系统提供的单个焦面,多个焦面可以提供在系统复杂性(例如,对时间多路复用的需要)和图像质量(例如,压缩伪像的抑制)之间的有利折衷。
79.系统概述
80.图2是控制台250操作于的系统环境。在该示例中,系统环境包括hmd 200、成像设备260和输入接口270,各自耦合到控制台250。虽然图2示出了单个hmd 200、单个成像设备260和单个输入接口270,但在其他实施例中任何数量的这些部件可以被包括在系统中。例如,可以有多个hmd 200,每个hmd 200具有相关联的输入接口270并且由一个或更多个成像设备260监控,每个hmd 200、输入接口270和成像设备260与控制台250通信。在替代配置中,不同的和/或附加的部件也可以被包括在系统环境200中。
81.hmd 200是向用户呈现内容的头戴式显示器(hmd)。示例内容包括图像、视频、音频或其某种组合。音频内容可以经由在hmd 200外部的单独设备(例如,扬声器和/或头戴式受话器(headphone))被呈现,该单独设备从hmd 200、控制台250或两者接收音频信息。hmd 200包括电子显示器202、光学块204、空间光调制器(slm)模块206、一个或更多个定位器208、惯性测量单元(imu)210、头部跟踪传感器212和场景再现模块214。
82.光学块204将来自显示器202的光经由slm块206引导到hmd 200的出射光瞳,用于由用户使用一个或更多个光学元件(例如光圈、菲涅耳透镜、凸透镜、凹透镜、滤波器等)来观看,并且可以包括不同光学元件的组合。在一些实施例中,在光学块204中的一个或更多个光学元件可以具有一个或更多个涂层,例如抗反射涂层。由光学块204对图像光的放大允许电子显示器202比更大的显示器在物理上更小、重量更小且消耗更少的功率。另外,图像光的放大可以增加所显示的内容的视场角。例如,所显示的内容的视场角使得所显示的内容使用用户的视场角的几乎全部(例如,150度对角线)以及在一些情况下全部视场角来被呈现。
83.空间光调制器(slm)块206包括控制电子显示器202的一个或更多个驱动器和产生并显示具有动态时空焦面的虚拟场景的图像的slm。与光学块204光学串联地设置的slm块206在仅相位模式进行操作,并且对于给定帧可以生成多个相位函数,每个相位函数对应于在虚拟场景中的不同深度范围的聚焦模式。在各种实施例中,slm块206可以集成到光学块204中。在一个实施例中,每个焦面调整聚焦模式以改变hmd 200的焦距(或光焦强),以在观看虚拟场景的内容的同时将用户的眼睛保持在舒适区中。
84.由于slm的有限分辨率,在hmd 200的光学系统中的slm块206的位置受制于设计规则,其基于相应的配置来限制某些性能参数。因此,在配置及其相关联的性能之间存在折衷。例如,可以基于slm块206相对于电子显示器202和光学块204的位置来限制hmd 200的对焦范围。在该示例中,当slm被定位成更靠近光学块204而不是显示器202时,更大的对焦范围被实现。因此,当slm被定位成更靠近显示器202时,对焦范围受到限制。此外,当slm被定位成更靠近光学块204而不是显示器202时,更大的视场角也是可实现的,以及因此当slm被定位成更靠近显示器202时,视场角受到限制。然而,当slm被定位成更靠近光学块204时,在虚拟场景中的边缘边界清晰度降低。因此,slm被定位成离显示器202越近,边缘边界就越清晰。因此,在边缘清晰度与对焦范围和视场角之间存在待寻求的设计折衷和平衡。
85.定位器208是相对于彼此并相对于在hmd 200上的特定参考点位于hmd 200上的特定位置的对象。定位器208可以是发光二极管(led)、锥体棱镜(corner cube reflector)、反射标记、与hmd 200操作于的环境形成对比的一种类型的光源或者其某种组合。有源定位器208(即,led或其他类型的光发射设备)可以发射在可见光波段(~380nm至750nm)中、在红外(ir)波段(~750nm至1mm)中、在紫外波段(10nm至380nm)中、电磁光谱的某个其他部分中或其某种组合的光。
86.定位器208可以位于hmd 200的外表面之下,该外表面对于由定位器208发射或反射的光的波长是透光的,或者足够薄而基本上不使由定位器208发射或反射的光的波长衰减。此外,hmd 200的外表面或其他部分在光的波长的可见光波段内可以是不透光的。因此,定位器208当在hmd 200的外表面下时可以发射在ir波段中的光,该外表面在ir波段中是透光的但在可见光波段中是不透光的。
87.imu 210是基于从一个或更多个头部跟踪传感器212接收的测量信号来生成快速校准数据的电子设备,头部跟踪传感器响应于hmd 200的运动而生成一个或更多个测量信号。头部跟踪传感器212的示例包括加速度计、陀螺仪、磁力计、适于检测运动、校正与imu 210相关联的误差的其他传感器或者其某种组合。头部跟踪传感器212可以位于imu 210的外部、imu 210的内部或者其某种组合。
88.基于来自头部跟踪传感器212的测量信号,imu 210生成指示相对于hmd 200的初始位置的hmd 200的所估计的位置的快速校准数据。例如,头部跟踪传感器212可以包括测量平移运动(向前/向后、向上/向下、向左/向右)的多个加速度计和测量旋转运动(例如,俯仰、偏航、横滚)的多个陀螺仪。例如,imu 210可以对测量信号进行快速采样,并根据所采样的数据来计算hmd 200的所估计的位置。例如,imu 210随时间的推移对从加速度计接收的测量信号求积分以估计速度矢量,并随时间的推移对速度矢量求积分以确定在hmd 200上的参考点的所估计的位置。参考点是可以用来描述hmd 200的位置的点。虽然参考点通常可以被定义为空间中的点,但是在各种实施例中参考点被定义为在hmd 200内的点(例如,imu 210的中心)。可选地,imu 210向控制台250提供所采样的测量信号,控制台250确定快速校准数据。
89.imu 210可以以附加地从控制台250接收一个或更多个校准参数。如下面进一步讨论的,一个或更多个校准参数用于保持hmd 200的跟踪。基于接收到的校准参数,imu 210可以调整一个或更多个imu参数(例如,采样率)。在一些实施例中,某些校准参数使imu 210更新参考点的初始位置以对应于参考点的下一个所校准的位置。将参考点的初始位置更新为参考点的下一个所校准的位置帮助减少与确定所估计的位置相关联的累积误差。也被称为漂移误差的累积误差使参考点的所估计的位置随着时间的推移“漂移”远离参考点的实际位置。
90.场景再现模块214从引擎256接收虚拟场景的内容,并提供该内容用于在电子显示器202上显示。另外,如下面进一步描述的,场景再现模块214基于跟踪模块254、头部跟踪传感器212或imu 210中的一个或更多个来确定待显示在电子显示器202上的内容的一部分。
91.成像设备260根据从控制台250接收的校准参数来生成慢速校准数据。慢速校准数据包括显示定位器208的所观察的位置的一个或更多个图像,这些位置由成像设备260可检测。成像设备260可以包括一个或更多个照相机、一个或更多个摄像机、包括一个或更多个定位器208的能够捕获图像的其他设备或者其某种组合。另外,成像设备260可以包括一个或更多个滤波器(例如,用于增加信噪比)。成像设备260被配置成在成像设备260的视场角中检测从定位器208发射或反射的光。在定位器208包括无源元件(例如,后向反射器)的实施例中,成像设备260可以包括照亮一些或所有定位器208的光源,其朝着成像设备260中的光源向后反射光。慢速校准数据从成像设备260被传递到控制台250,并且成像设备260从控制台250接收一个或更多个校准参数以调整一个或更多个成像参数(例如,焦距、焦点、帧速率、iso、传感器温度、快门速度、光圈等)。
92.输入接口270是允许用户向控制台250发送动作请求的设备。动作请求是执行特定动作的请求。例如,动作请求可以是开始或结束应用,或者在应用内执行特定动作。输入接口270可以包括一个或更多个输入设备。示例输入设备包括键盘、鼠标、游戏控制器或用于接收动作请求并将接收到的动作请求传递到控制台250的任何其他合适的设备。由输入接
口270接收到的动作请求可以被传递到控制台250,控制台250执行对应于动作请求的动作。在一些实施例中,输入接口270可以根据从控制台250接收到的指令来向用户提供触觉反馈。例如,当接收到动作请求时,输入接口470提供触觉反馈,或者控制台250向输入接口270传递指令,使输入接口270在控制台250执行动作时生成触觉反馈。
93.控制台250根据从成像设备260、hmd 200或输入接口270接收的信息来向hmd 200提供内容用于呈现给用户。在图2所示的示例中,控制台250包括应用商店252、跟踪模块254和虚拟现实(vr)引擎256。控制台250的一些实施例具有与结合图2描述的模块不同的或额外的模块。类似地,下面进一步描述的功能可以以不同于这里描述的方式分布在控制台250的部件当中。
94.应用商店252存储用于由控制台250执行的一个或更多个应用。应用是一组指令,其当由处理器执行时生成用于呈现给用户的内容。由应用生成的内容可以响应于经由hmd 200的移动或输入接口270而从用户接收的输入。应用的示例包括游戏应用、会议应用、视频回放应用或其他合适的应用。
95.跟踪模块254使用一个或更多个校准参数来校准系统,并且可以调整一个或更多个校准参数以减少在确定hmd 200的位置时的误差。例如,跟踪模块254调整成像设备260的焦点以获得在hmd 200上的被观察的定位器208的更准确的位置。此外,由跟踪模块254执行的校准还考虑从imu 210接收到的信息。另外,如果hmd 200的跟踪丢了(例如,成像设备260失去至少阈值数量的定位器208的视线),则跟踪模块254重新校准系统部件中的一些或全部。
96.此外,跟踪模块254使用来自成像设备260的慢速校准信息来跟踪hmd 200的移动,并且使用来自慢速校准信息的观察到的定位器和hmd 200的模型来确定在hmd 200上的参考点的位置。跟踪模块254还使用来自在hmd 200上的imu 210的快速校准信息的位置信息来确定在hmd 200上的参考点的位置。此外,跟踪模块254可以使用快速校准信息、慢速校准信息或其某种组合的部分来预测hmd 200的未来位置,其被提供给引擎256。
97.引擎256执行在系统内的应用,并从跟踪模块254接收hmd 200的位置信息、加速度信息、速度信息、所预测的未来位置或其某种组合。基于接收到的信息,引擎256确定要提供给hmd 200用于呈现给用户的内容(例如虚拟场景)。例如,如果接收到的信息指示用户向左看了,则引擎256为hmd 200生成对用户在虚拟环境中的移动进行镜像(mirror)或跟踪的内容。另外,引擎256响应于从输入接口270接收到的动作请求来执行在控制台250上执行的应用内的动作,并且向用户提供动作被执行的反馈。所提供的反馈可以是经由hmd 200的视觉或听觉反馈或者经由输入接口270的触觉反馈。
98.图3是根据至少一个实施例的hmd 200的图示。在该示例中,hmd200包括前刚性主体和绕在用户的头部周围的带。前刚性主体包括对应于电子显示器202、imu 210、头部跟踪传感器212和定位器208的一个或更多个电子显示元件。在该示例中,头部跟踪传感器212位于imu 210内。
99.定位器208相对于彼此并相对于参考点300位于前刚性主体上的固定位置。在该示例中,参考点300位于imu 210的中心处。定位器208中的每一个发射由成像设备260可检测到的光。如图3所示,定位器208或定位器208的部分位于前刚性主体的前侧、顶侧、底侧、右侧和左侧上。
100.焦面显示方法
101.图4示出了根据至少一个实施例的用于减轻视觉辐辏调节冲突的示例过程400。如上面所讨论的,头戴式显示器可以使用slm来提供焦点调节和景深模糊。因此,在该示例中,获得402用于显示虚拟场景的虚拟场景数据。在一个示例中,电子显示器的每个像素与单独深度值(例如在虚拟场景中显示的天空的无穷大、在桌子上的对象的一米以及在桌子表面的半米和一米之间的变化的距离、在虚拟场景中的远处墙壁的3米等)相关联。
102.使用场景几何数据,虚拟场景被分割404成一组焦面。为了确定在虚拟场景中的焦面的位置,虚拟场景的深度值的范围基于场景几何数据被近似到一组一个或更多个离散深度值。例如,给定目标虚拟场景,假定为沿着每个视角(θ
x
,θy)∈ω
θ
的深度(以屈光度为单位),对于穿过观看用户的瞳孔的中心的主光线,ω
θ
为一组离散的视网膜图像样本。如果相位slm可能产生任意拓扑的焦面,则不需要进一步的优化;然而,情况并非如此,因为焦面需要是平滑的。因此,虚拟场景的深度图被分割404成k个平滑焦面d1,...,dk。例如,如果对于每个视角(θ
x
,θy),存在靠近目标深度图的至少一个焦面沾(θ
x
,θy),那么可以用接近恰当的视网膜模糊来描绘每个场景元素,因为来自显示器102的光将看起来源自正确的场景深度。优化的混合方法仍然有利于遮蔽的(occluding)、半透光和反射对象的重现。给定该目标,下面的优化问题被公式示出。
[0103][0104]
如下面进一步讨论的,使用相位函数φ产生焦面可能引入光学像差。根据观察,如果焦面的二阶导数很小,则像差被最小化。这个观察在上面的优化问题中由边界约束进行反映。然而注意,没有明确的边界约束被强加在焦面的光焦强di上。这看起来与slm 104的最小可实现的焦距的该推导相矛盾。不是直接添加这些约束,而是目标深度图被截短到可实现的深度范围。
[0105]
因此,对于每个焦平面,焦平面的形状被调整406以最小化焦平面到集群中的每个场景点的距离。这将焦平面的形状扭曲到开始将焦平面称为焦面是有意义的地方,因为焦平面被弯曲、扭曲和/或调整以符合在虚拟场景中的最接近焦平面的一组场景点、部分或特征。由此产生的焦面的形状是连续的分段平滑三维曲线,与具有位于固定焦深处的平坦表面的多焦点显示器不同。应用非线性最小二乘法对等式1进行求解,该非线性最小二乘法拓展到大的问题尺寸。注意,目标涉及每个像素(θ
x
,θy)的非线性残差该残差不是可微分的,这是非线性最小二乘法的问题。然而,可以通过用“软最小值”(soft-min)代替min来获得接近的近似,有下面的定义:
[0106][0107]
其中t是针对给定应用进行调整的调节参数。
[0108]
将等式2应用于等式1以及将边界约束重新表示为软约束,产生下面的非线性最小二乘法问题:
[0109][0110]
其中是di在(θ
x
,θy)处的二阶偏导数的矢量,以及γ是加权参数。
[0111]
给定一组焦面,为每个焦面生成408相位函数。假定该组焦面di,下一步骤包括对一组相位函数φi进行求解以生成每个焦面。为了求解该问题,必须理解相位slm的光学特性。穿过透镜的光学路径长度的变化引起折射。类似地,跨slm的相位调制的差异导致衍射。经由波光学建模通过高分辨率slm进行的光传播的模拟目前在计算上是不可行的,但人们可以使用几何光学器件来近似这些衍射效应。
[0112]
因此,假定(p
x
,py)表示slm位置,ω
p
是一组离散的slm像素中心。与slm相交的光线根据相位φ被重定向。对于小角度(即,在傍轴近似下),偏转与φ的梯度成比例。如果入射光线具有方向矢量(x,y,1)并且在(p
x
,py)处与slm相交,则出射光线具有方向矢量:
[0113][0114]
其中λ是照明波长。因此,如果φ是线性函数,那么slm作为棱镜进行操作,将恒定偏移添加到每条光线的方向。(注意,在该推导中假设单色照明,对宽带照明源的实际考虑因素稍后被提出)。slm还可以通过如下呈现二次变化的相位来充当薄透镜。
[0115][0116]
注意,这些光学属性是局部的。单条光线的偏转仅取决于在与slm相交的点周围的相位的一阶泰勒级数(即,相位梯度)。类似地,与slm相交的∈尺寸的光线束的焦点的变化仅取决于二阶泰勒级数。特别地,如果在点(p
x
,py)处的φ的hessian由下式给出
[0117][0118]
其中i是2x2单位矩阵,那么在(p
x
,py)周围的∈尺寸的邻近区用作焦距f的透镜(即,等式6是等式5的hessian)。
[0119]
到现在为止,我们允许相位是任何实值函数。实际上,slm具有通常来自[0,2π]的有界范围。在此范围之外的相位被“卷绕”,以2π为模。此外,可实现的相位函数受到奈奎斯特极限的限制。相位可以在2δp的距离上改变不超过2π,其中δp是slm像素间距。
[0120]
因此,利用slm的该傍轴模型,确定最好地实现给定目标焦面d的相位函数φ。首
先,参考图1,确定slm 104的焦距f
p
(来自等式5)如何影响焦面距离zv。如图1所示,slm 104在焦面显示器100内操作,焦面显示器100由目镜106的距离(z=0)、slm 104的距离z
p
和显示器102的距离zd参数化。忽略目镜106,slm 104在距离zv
′
处产生显示器102的中间图像108。根据目镜106的焦距fe,中间图像108被转换成位于zv处的显示器102的虚拟图像110。这些关系通过应用薄透镜等式来被简洁地概括为:
[0121][0122]
通过将来自观看者的瞳孔的观看光线(θ
x
,θy)投射到slm 104且然后通过应用等式7,可以为每个slm像素(p
x
,py)分配目标焦距f
p
,以在期望焦面深度处创建虚拟图像110。为了实现这个焦距,等式6要求使用hessian的相位函数φ为:
[0123][0124]
可能没有满足该表达式的φ。事实上,这种φ仅在f为恒定的且φ为二次的(即,相位表示均匀透镜)时存在。因为等式8不能完全被满足,下面的线性最小二乘法问题被求解以获得尽可能接近的相位函数φ:
[0125][0126]
其中||
·
||
2f
是frobenius范数,以及其中h[
·
]是由φ的有限差分给出的离散hessian算子。注意,相位函数φ加上任何线性函数a+bx+cy具有相同的hessianh,因此我们另外约束φ(0,0)=0和
[0127]
在确定了对应于焦面di的k个相位函数φi之后,彩色图像ci被确定,用于呈现在显示器102上,以再现目标焦点堆栈。这个焦点堆栈由一组l个视网膜图像r1,...,rl表示。首先,描述视网膜模糊的光线跟踪模型,且然后应用该模型以评估求解表示优化混合的线性最小二乘法问题所需的前向和伴随算子(adjoint operator)。
[0128]
光线在几何光学模型下通过系统被跟踪,其中每条光线源自在观看者的瞳孔内的一点。光线然后穿过目镜106、slm 104的前部和后部,且然后射在显示器102上。在目镜106的表面处,使用透镜的曲率半径、它的光学折射率和旁轴近似来使光线折射。等式4通过slm 104对光传输进行建模。每条光线都被分配在它与显示器102相交的坐标处内插的颜色。在显示器上的位置由(q
x
,qy)表示,且该组显示像素中心由ωq表示。注意,错过目镜106、slm 104或显示器102的边界的任何光线都被剔除(即,被分配黑色)。
[0129]
为了对视网膜模糊进行建模,跨越观看者的瞳孔的光线被累积,其使用泊松分布被采样。以这种方式,观看者的眼睛被近似为在深度z处聚焦的理想透镜,深度z根据观看者的调节状态而变化。对于每一条主光线(θ
x
,θy)和深度z,一束光线从泊松采样瞳孔中跨过r
θx
,θ
y,z
被求和。当在深度z处聚焦时这产生视网膜模糊的估计。这些在前面的步骤中被定义为前向算子(forward operator)r=a
z,φ
(c),其接受相位函数φ和彩色图像c,并且当在距
离z处聚焦时预测所感知的视网膜图像r。
[0130]
对于固定相位函数φ和调节深度z,前向算子a
z,φ
(c)在彩色图像c中是线性的。再现算子(rendering operator)a
z,φi
(ci)相加地组合,所以我们的组合前向算子是az(c1,...,ck)=∑
i a
z,φi
(ci),其表示对多分量焦面显示的观看。前向再现可以针对多个调节深度z1,...,z1被连接在一起以用相应的线性算子a=[az1;...;az1]来估计重建的焦点堆栈。对于给定的一组彩色图像c,前向算子给出将在视网膜上产生的焦点堆栈r,最小化||ac-r||2给出了最好地近似于期望焦点堆栈的彩色图像。将视网膜图像样本映射到显示像素的az,φ的转置可以类似地用具有在彩色图像c而不是视网膜图像r中的累积的光线跟踪操作来被评估。总之,用迭代最小二乘法解算器来应用这些前向和伴随算子。
[0131]
相位函数在由slm执行时使slm再现对应于每个焦面的聚焦模式。这由将相位延迟添加到来自电子显示器的光的波阵面的slm实现。相位延迟使波阵面的形状被弯曲并被扭曲成每个焦面的形状,从而产生符合场景几何形状的聚焦模式。在一个实施例中,slm对针对每个焦面的波阵面的调节进行时间多路复用,以便向观看用户提供在虚拟场景中的不同焦面中的每一个的聚焦。例如,在第一时间,slm针对远深度调整波阵面;在第二时间,slm针对中间深度调整波阵面;以及在第三时间,slm针对近深度调整波阵面。这三个深度的时间多路复用调整出现的速度对于人眼来说通常太快而注意不到,且因此观看用户观察到焦点对准的虚拟场景,或者至少如所建模的和/或近似的。
[0132]
附加配置信息
[0133]
为了说明的目的,提出了实施例的前述描述;它并不旨在是无遗漏的或将专利权限制于所公开的精确形式。相关领域中的技术人员可以认识到,根据上述公开的许多修改和变化是可能的。
[0134]
在本说明书中使用的语言主要为了可读性和教学目的而被选择,并且它可以不被选择来描写或限制创造性主题。因此,意图是专利权的范围不由该详细描述限制,而是由在基于其的申请上发布的任何权利要求限制。因此,实施例的公开旨在是说明性的但不限制专利权的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1