处理装置、管理装置、光刻装置和物品制造方法与流程
1.本发明涉及处理装置、管理装置、光刻装置和物品制造方法。
背景技术:
2.提供了用于提高控制对象的控制精度的各种技术。日本专利特许公开no.2006-128685描述了在通过组合反馈控制器和前馈控制器获得的控制系统中,通过迭代学习来更新前馈控制器的参数。
3.近年来,提出了使用神经网络对控制对象进行控制并提高精度的技术。神经网络针对每个控制对象进行优化。优化后的神经网络被称为学习到的网络。使用学习到的神经网络对控制对象进行控制。
4.使用神经网络的控制装置可以通过执行强化学习来决定神经网络的参数值。但是,由于控制对象的状态会随着时间而改变,因此即使在给定时间优化的神经网络也不再是最优的,这是因为此后控制对象的状态已经改变。因此,控制装置的控制精度会由于控制对象的状态改变而劣化。
技术实现要素:
5.本发明提供了有利于抑制由控制对象的状态变化引起的控制精度劣化的技术。
6.本发明在其一个方面提供了一种处理装置,其包括被配置成驱动控制对象的驱动器,以及被配置成通过基于控制误差生成对驱动器的命令值来控制驱动器的控制器,其中控制器包括被配置成基于控制误差来生成第一命令值的第一补偿器,被配置成基于控制误差来生成第二命令值的第二补偿器,以及被配置成通过将第一命令值和第二命令值相加来获得命令值的加法器,第二补偿器包括通过学习为其决定参数值的神经网络,并且被输入到神经网络的输入参数除了控制误差之外还包括驱动器的驱动条件和控制对象的周围的环境条件中的至少一个。
7.本发明在其第二方面提供了一种用于管理在第一方面中定义的处理装置的管理装置,该管理装置包括被配置成基于控制器对控制对象的控制结果通过学习来重新决定参数值的学习设备,其中学习设备在改变驱动条件和环境条件中的至少一个的同时重复学习。
8.本发明在其第三方面提供了一种用于执行将原版(original)的图案转印到基板的处理的光刻装置,其包括被配置成驱动控制对象以进行所述处理的驱动器,以及被配置成通过基于控制误差生成对驱动器的命令值来控制驱动器的控制器,其中控制器包括被配置成基于控制误差来生成第一命令值的第一补偿器,被配置成基于控制误差来生成第二命令值的第二补偿器,以及被配置成通过将第一命令值和第二命令值相加来获得命令值的加法器,第二补偿器包括通过学习为其决定参数值的神经网络,并被配置成使用神经网络来控制驱动器,并且被输入到神经网络的输入参数除了控制误差之外还包括驱动器的驱动条件和控制对象的周围的环境条件中的至少一个。
9.本发明在其第四方面提供了一种物品制造方法,其包括使用在第三方面中定义的光刻装置将原版的图案转印到基板,并且处理已经历转印的基板,其中物品是从经过处理的基板获得的。
10.本发明的进一步特征将从(参考附图)对示例性实施例的以下描述中变得清楚。
附图说明
11.图1是示出制造系统的构造的框图;
12.图2是示出处理装置的布置的框图;
13.图3是例示图2中所示的处理装置的布置的框图;
14.图4是例示学习序列中的管理装置的操作的流程图;
15.图5是例示扫描曝光装置的布置的视图;
16.图6是例示扫描曝光装置的实际序列中的操作的流程图;以及
17.图7a和图7b是示出根据实施例的控制对象的控制误差的减小效果的曲线图。
具体实施方式
18.在下文中,将参考附图详细描述实施例。注意的是,以下实施例并非旨在限制要求保护的发明的范围。在实施例中描述了多个特征,但不限于要求所有这些特征的发明,并且可以适当地组合多个这样的特征。此外,在附图中,相同的附图标记被赋予相同或类似的构造,并且省略对其的重复描述。
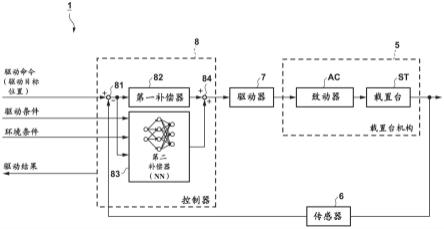
19.《第一实施例》
20.图1示出根据该实施例的制造系统ms的构造。制造系统ms例如可以包括:处理装置1、控制处理装置1的控制装置2、以及管理处理装置1和控制装置2的管理装置(学习装置)3。处理装置1是像制造装置、检查装置、监视装置等那样的对处理目标对象执行处理的装置。处理的概念可以包括对处理目标对象的加工、检查、监视、和观察。
21.处理装置1可以包括控制对象并且使用通过强化学习为其决定参数值的神经网络来对控制对象进行控制。控制装置2可以被配置成向处理装置1发送驱动命令并从处理装置1接收驱动结果或控制结果。管理装置3可以执行决定处理装置1的神经网络的多个参数值的强化学习。更具体而言,管理装置3可以通过重复向处理装置1发送驱动命令并从处理装置1接收驱动结果的操作,同时改变多个参数值的全部或一些,来决定神经网络的多个参数值。管理装置3可以被理解为学习装置。
22.控制装置2的功能的全部或一些可以并入到管理装置3中。控制装置2的功能的全部或一些可以并入到处理装置1中。处理装置1、控制装置2、管理装置3可以在物理上一体形成或者分开形成。处理装置1可以作为整体由控制装置2控制,或者可以包括由控制装置2控制的部件和不受控制装置2控制的部件。
23.图2例示出处理装置1的布置。处理装置1可以包括载置台机构5,该载置台机构5包括作为控制对象的载置台(保持器)st。处理装置1还可以包括检测载置台st的位置或状态的传感器6、驱动载置台机构5的驱动器7、以及接收来自传感器6的输出并且将命令值提供给驱动器7的控制器8。载置台st可以保持定位目标对象。载置台st可以由引导件(未示出)引导。载置台机构5可以包括使载置台st移动的致动器ac。驱动器7驱动致动器ac。更具体而
言,例如,驱动器7可以向致动器ac供给与从控制器8给予的命令值对应的电流(电能)。致动器ac可以通过与从驱动器7给出的电流对应的力(机械能)来移动载置台st。控制器8可以使用通过强化学习为其决定参数值的神经网络来控制作为控制对象的载置台st的位置或状态。驱动命令部9给出作为控制对象的载置台st的驱动目标位置和驱动器7的驱动条件。环境传感器10检测载置台st的周围的环境条件并将检测到的环境条件提供给控制器8。
24.图3是例示出图2中所示的处理装置1的布置的框图。控制器8可以包括减法器81、第一补偿器82、第二补偿器(神经网络)83和加法器84。减法器81可以将控制误差计算为从控制装置2给出的驱动命令(例如,目标位置)与从传感器6输出的检测结果(例如,载置台st的位置)之间的差。第一补偿器82可以通过对从减法器81提供的控制误差执行补偿计算来生成第一命令值。第二补偿器83包括神经网络。除了从减法器81提供的控制误差之外,神经网络还可以输入从驱动命令部9输入的驱动条件和由环境传感器10测得的环境条件作为输入参数,并通过执行补偿计算来生成第二命令值。驱动条件和环境条件是不被输入到第一补偿器82的信息。加法器84可以通过将第一命令值和第二命令值相加来生成命令值。控制器8、驱动器7、载置台机构5和传感器6形成反馈控制系统,该反馈控制系统基于控制误差来控制作为控制对象的载置台st。
25.第一补偿器82例如可以是pid补偿器,但可以是其他补偿器。例如,当l表示输入的数量、m表示中间层的数量并且n表示输出的数量(l、m和n都是正整数)时,第二补偿器83例如可以是由l
×
m的矩阵和m
×
n的矩阵的乘积定义的神经网络。神经网络的多个参数值可以通过由管理装置3执行的强化学习来决定或更新。第一补偿器82不总是必需的,可以仅由第二补偿器83生成提供给驱动器7的命令值。
26.从驱动命令部9输入的驱动条件例如可以包括载置台的当前位置、目标位置、驱动方向、驱动冲程(stroke)、速度、加速度、加加速度(jerk)和锁扣(snap)中的至少一个,但可以是其他驱动条件。此外,条件可以是诸如一系列驱动操作中的最大值、平均值或方差之类的值。可替代地,条件可以是当前值、特定时间处的过去历史或经过给定时间之后的未来目标值。
27.从环境传感器10输入的环境条件例如可以包括载置台st的周围的压力、温度、湿度、振动、风速和流速(flow rate)中的至少一个,但可以是其他条件,只要它可以由传感器测量即可。该值可以是当前值、给定时间之前的过去值或根据过去的改变预测的未来值。可以使用通过对传感器的测得的值执行滤波处理而获得的值。
28.当根据处理装置1的控制器8对载置台st的控制结果得到的奖励(reward)不满足预定标准时,管理装置3可以用作执行学习序列的学习设备或再学习设备。在学习序列中,可以通过强化学习来决定或重新决定由第二补偿器(神经网络)83的多个参数值构成的参数值集合。
29.图4例示出管理装置3在学习序列中的操作。在步骤s101中,管理装置3可以初始化第二补偿器(神经网络)83的多个参数值(参数值集合)。在步骤s102中,管理装置3可以向处理装置1发送命令以驱动作为控制对象的载置台st。更具体而言,在步骤s102中,管理装置3可以经由控制装置2向处理装置1的控制器8发送驱动命令。响应于此,处理装置1的控制器8可以使驱动器7根据驱动命令驱动载置台st,从而控制载置台st的位置。
30.在步骤s103中,管理装置3可以经由控制装置2从处理装置1的控制器8取得指示出
在步骤s102中作为控制对象的载置台st的驱动状态的驱动数据。驱动数据例如可以包括来自传感器6的输出和来自减法器81的输出中的至少一个。在步骤s104中,管理装置3可以基于在步骤s103中取得的驱动数据来计算奖励。奖励可以基于预定义的公式被计算。例如,如果基于控制误差计算奖励,那么可以根据给出控制误差的倒数的公式、给出控制误差的对数的倒数的公式、给出控制误差的二次函数的倒数的公式等来计算奖励,但可以根据其他公式进行计算。在一个示例中,随着奖励的值越大,第二补偿器(神经网络)83越优越。相反,随着奖励的值越小,第二补偿器(神经网络)83可能越优越。
31.在步骤s105中,管理装置3通过改变第二补偿器(神经网络)83的多个参数值中的至少一个来生成新的参数值集合,并在第二补偿器(神经网络)83中设置新的参数值。步骤s106、s107和s108可以分别与步骤s102、s103和s104相同。在步骤s106中,管理装置3可以向处理装置1发送命令以驱动载置台st。更具体而言,在步骤s106中,管理装置3可以经由控制装置2向处理装置1的控制器8发送驱动命令。响应于此,处理装置1的控制器8可以使驱动器7根据驱动命令驱动载置台st,从而控制载置台st的位置。在步骤s107中,管理装置3可以经由控制装置2从处理装置1的控制器8取得指示出步骤s106中载置台st的驱动状态的驱动数据。在步骤s108中,管理装置3可以基于在步骤s107中取得的驱动数据计算奖励。
32.在步骤s109中,管理装置3确定在步骤s108中计算出的奖励是否比在步骤s104中计算出的奖励有所提高。然后,如果在步骤s108中计算的奖励与在步骤s104中计算的奖励相比有所提高,那么在步骤s110中,管理装置3采用在步骤s105中执行改变操作之后获得的参数值集合作为最新的参数值。另一方面,如果在步骤s108中计算出的奖励与在步骤s104中计算出的奖励相比没有提高,那么在步骤s111中,管理装置3不采用在步骤s105中执行改变操作之后获得的参数值集合,并返回到步骤s105。在这种情况下,在步骤s105中,在第二补偿器(神经网络)83中设置新的参数值集合。
33.如果执行步骤s110,那么在步骤s112中,管理装置3确定在紧接在前执行的步骤s108中计算出的奖励是否满足预定标准。如果奖励满足预定标准,那么图4中所示的处理结束。这意味着在紧接在前执行的步骤s105中生成的参数值集合被决定为强化学习之后的参数值集合。设有在强化学习之后设置的参数值的神经网络可以被称为学习到的模型。另一方面,如果在步骤s112中确定在紧接在前执行的步骤s108中计算出的奖励不满足预定标准,那么管理装置3重复从步骤s105开始的处理。
34.执行步骤s102时的驱动条件和环境条件不是恒定的,并且一些或全部的可能的条件会改变。即,管理装置3(学习设备)在改变驱动条件和环境条件中的至少一个的同时重复强化学习。此外,在学习步骤中,在驱动条件和环境条件的第一数量的第一组合模式之中改变组合模式的同时,学习被重复地执行。如果在学习被重复地执行的同时奖励超过预定值,那么可以增加驱动条件和环境条件的组合模式。即,在这种情况下,可以在第二数量的第二组合模式之中改变组合模式的同时重复地执行学习,该第二数量大于第一数量。
35.本发明人发现,即使控制误差的历史相同,控制对象的未来行为也可能由于控制对象的驱动条件或周围的环境条件的差异而改变。在这个实施例中,为了应对这种情况,被输入到神经网络的输入参数除了控制误差之外还可以包括驱动条件和环境条件中的至少一个。因此,神经网络被学习以将能够抑制控制误差的命令值输出到驱动器7。
36.处理装置1可以在对处理目标对象执行处理的序列(下文中称为实际序列)中作为
包括在上述学习序列中获得的学习到的模型(第二补偿器83)的装置进行操作。在一个示例中,处理装置1可以在管理装置3的管理下执行实际序列。但是,在另一个示例中,处理装置1可以独立于管理装置3的管理来执行实际序列。
37.《第二实施例》
38.下面将参考图6描述将上述制造系统ms应用于图5中所示的扫描曝光装置500的示例。扫描曝光装置500是步进扫描曝光装置,其通过由狭缝构件成形的狭缝光执行对基板14的扫描曝光。扫描曝光装置500可以包括:照明光学系统23、原版载置台机构12、投影光学系统13、基板载置台机构15、第一位置测量设备17、第二位置测量设备18、基板标记测量设备21、基板输送部22、以及控制器25。
39.控制器25控制照明光学系统23、原版载置台机构12、投影光学系统13、基板载置台机构15、第一位置测量设备17、第二位置测量设备18、基板标记测量设备21和基板输送部22。控制器25控制将原版11的图案转印到基板14的处理。此外,控制器25可以包括根据第一实施例的控制器8的功能。控制器25例如可以由诸如现场可编程门阵列(fpga)之类的可编程逻辑器件(pld)、专用集成电路(asic)、安装有程序的通用计算机、或者这些部件的全部或一些的组合形成。
40.原版载置台机构12可以包括保持原版11的原版载置台rst和驱动原版载置台rst的第一致动器rac。基板载置台机构15可以包括保持基板14的基板载置台wst和驱动基板载置台wst的第二致动器wac。照明光学系统23照亮原版11。照明光学系统23通过诸如遮蔽叶片之类的遮光构件将从光源(未示出)射出的光整形为例如在x方向上较长的带状或弧形的狭缝光,并用这个狭缝光照亮原版11的一部分。原版11和基板14分别由原版载置台rst和基板载置台wst保持,并且经由投影光学系统13被布置在几乎光学共轭的位置(在投影光学系统13的物面和像面上)。
41.投影光学系统13具有预定的投影倍率(例如,1、1/2或1/4),并通过狭缝光将原版11的图案投影在基板14上。基板14上投影有原版11的图案的区域(用狭缝光照射的区域)可以被称为照射区域。原版载置台rst和基板载置台wst被配置成可在与投影光学系统13的光轴方向(z方向)正交的方向(y方向)上移动。原版载置台rst和基板载置台wst被以与投影光学系统13的投影倍率对应的速度比率彼此同步地相对扫描。这相对于照射区域在y方向上扫描基板14,从而将形成在原版11上的图案转印到基板14的压射区。然后,通过在移动基板载置台wst的同时对基板14的多个压射区依次执行这种扫描曝光,完成对一个基板14的曝光处理。
42.第一位置测量设备17例如包括激光干涉仪,并且测量原版载置台rst的位置。例如,激光干涉仪用激光束照射在原版载置台rst中提供的反射板(未示出),并通过由反射板反射的激光束与由参考面反射的激光束之间的干涉来检测原版载置台rst的位移(相对于参考位置的位移)。第一位置测量设备17可以基于该位移取得原版载置台rst的当前位置。在这个示例中,第一位置测量设备17可以通过位置测量设备(例如,编码器)而不是激光干涉仪来测量原版载置台rst的位置。基板标记测量设备21例如包括光学系统和图像传感器,并且可以检测在基板14上提供的标记的位置。
43.第二位置测量设备18例如包括激光干涉仪,并且测量基板载置台wst的位置。例如,激光干涉仪用激光束照射在基板载置台wst中提供的反射板(未示出),并通过由反射板
反射的激光束与由参考面反射的激光束之间的干涉来检测基板载置台wst的位移(相对于参考位置的位移)。第二位置测量设备18可以基于该位移取得基板载置台wst的当前位置。在这个示例中,第二位置测量设备18可以通过位置测量设备(例如,编码器)而不是激光干涉仪来测量基板载置台wst的位置。
44.传感器30、31、32被布置在控制对象附近,并且可以检测压力、温度、湿度、振动、风速、流速等作为控制对象的周围的环境条件。在图5中所示的示例中,传感器30被布置在基板载置台wst附近,传感器31被布置在原版载置台rst附近,并且传感器32被布置在投影光学系统13附近。
45.扫描曝光装置500被要求将原版11的图案准确地转印到基板14的目标位置。为了实现这一点,重要的是在扫描曝光期间准确地控制原版载置台rst上的原版11相对于基板载置台wst上的基板14的相对位置。因此,作为奖励,可以采用用于评估原版载置台rst与基板载置台wst之间的相对位置误差(同步误差)的值。为了提高基板14的标记的检测精度,将基板载置台wst准确地定位在基板标记测量设备21的下方是重要的。因此,作为奖励,可以采用用于在对标记成像的同时评估基板载置台wst的控制误差的值。为了提高吞吐量,增大基板的输送速度是重要的。此外,在装载和卸载基板时,基板输送部22和基板载置台wst的控制误差在完成驱动之后的短时间内收敛到预定值以下是重要的。因此,作为奖励,可以采用用于评估基板输送部22和基板载置台wst的收敛时间的值。基板载置台机构15、原版载置台机构12和基板输送部22中的每个是执行将原版11的图案转印到基板14的处理的操作的操作单元的示例。
46.图6例示出扫描曝光装置500的实际序列。当管理装置3指示扫描曝光装置500的控制器25执行实际序列(基板处理序列)时,这个实际序列开始。基板处理序列例如可以包括作为多个子序列的步骤s301、s302和s303。
47.在步骤s301中,控制器25控制基板输送部22将基板14装载(输送)到基板载置台wst。在步骤s302中,控制器25可以控制基板载置台机构15以使得基板14的标记落入基板标记测量设备21的视场内,并控制基板标记测量设备21检测基板14的标记的位置。可以针对基板14的多个标记中的每个执行这个操作。在步骤s303中,控制器25控制基板载置台机构15、原版载置台机构12、照明光学系统23等,以使得原版11的图案被转印到基板14的多个压射区中的每个(曝光步骤)。在步骤s304中,控制器25控制基板输送部22卸载(输送)基板载置台wst上的基板14。
48.在步骤s301中,为了使基板输送部22将基板14准确地放置在基板载置台wst上,要求基板输送部22的定位精度。在这种情况下,作为被输入到第二补偿器83的驱动条件,可以获得基板输送部22的速度、加速度和加加速度。作为环境条件,可以获得当基板输送部22吸附基板14时的压力,或者当基板输送部22被驱动时来自在基板输送部22上提供的加速度传感器的输出。
49.在步骤s302中,要求通过驱动基板载置台wst以便基板14上的标记位于基板标记测量设备21的正下方而使得基板载置台wst的误差尽快收敛。在这种情况下,被输入到第二补偿器83的驱动条件例如可以是基板载置台wst的速度、加速度和加加速度中的至少一个。可替代地,驱动条件可以是当在给定标记位于基板标记测量设备21正下方的状态下驱动基板载置台wst以使得接下来要测量的标记位于基板标记测量设备21的正下方时的方向和距
离中的至少一个。此外,环境条件可以是在基板载置台wst被驱动时由压力传感器测量的空间中的压力的改变和来自在基板标记测量设备附近提供的加速度传感器的输出中的至少一个。
50.在步骤s303中,被输入到第二补偿器83的驱动条件可以是以下信息中的至少一个。
51.·
用于将压射区指定为基板上的曝光目标的坐标
52.·
压射区在x方向和/或y方向上的尺寸
53.·
当在曝光时移动基板载置台或原版载置台时的速度、加速度、加加速度和/或驱动方向
54.被输入到第二补偿器83的环境条件可以是照射基板的曝光光的强度以及由传感器30、31和32检测到的压力、温度、湿度、振动、风速和流速中的至少一个。
55.针对其形成神经网络的控制对象的示例是基板载置台机构15、原版载置台机构12和基板输送部22,但是神经网络可以被并入在其他部件中。例如,诸如基板载置台机构15、原版载置台机构12、基板输送部22之类的多个部件可以由一个神经网络控制,或者多个部件可以由不同的神经网络分别控制。此外,作为学习到的模型,可以将相同的学习到的模型或不同的学习到的模型用于输送序列、测量序列和曝光序列。在奖励的计算中,对于输送序列、测量序列和曝光序列可以使用相同的公式或不同的公式。
56.图7a和图7b是示出当应用这个实施例时控制对象的控制误差的减小效果的曲线图。图7a示出作为一种驱动条件的加速度的时间轮廓。当将由实线指示的曲线图600与由虚线指示的曲线图601相互比较时,直到中点为止加速度的改变是相同的,但加速度返回到0的定时不同。参考图7b,曲线图603表示当控制对象以曲线图600的加速度轮廓被驱动时的控制误差,而曲线图604表示当控制对象以曲线图601的加速度轮廓被驱动时的控制误差。在加速度条件相同的区间602中,曲线图603和604指示完全相同的误差波形,但是误差转变在中间变得彼此不同。通过将加速度条件输入到神经网络,即使误差历史相同但由于未来加速度条件的差异而在误差中产生差异,也可以提供能够抑制误差的神经网络。
57.以上已经解释了将制造系统ms应用于扫描曝光装置500的示例。但是,制造系统ms可以应用于其他类型的曝光装置(例如,步进式曝光装置(stepper))或诸如压印装置之类的其他类型的光刻装置。在这种情况下,光刻装置是用于在基板上形成图案的装置,并且此概念包括曝光装置、压印装置和电子束描画装置。
58.下面将描述使用上述光刻装置制造物品(例如,半导体ic元件、液晶显示元件或mems)的物品制造方法。物品制造方法可以是包括使用光刻装置将原版的图案转印到基板的转印步骤和处理已经经历转印步骤的基板的处理步骤从而从已经经历处理步骤的基板获得物品的方法。
59.当光刻装置是曝光装置时,物品制造方法可以包括:对涂有感光剂的基板(基板、玻璃基板等)进行曝光的步骤,对基板(感光剂)进行显影的步骤,以及在其它已知步骤中处理显影的基板的步骤。其它已知步骤包括蚀刻、抗蚀剂移除、切割、接合和封装。根据这种物品制造方法,可以制造与传统物品相比品质更高的物品。当光刻装置是压印装置时,物品制造方法可以包括:通过使用模具模制在基板上的压印材料来形成由压印材料的固化产物制成的图案的步骤,以及使用该图案处理基板的步骤。
60.虽然已经参考示例性实施例描述了本发明,但是应该理解的是,本发明不限于所公开的示例性实施例。以下权利要求的范围应被赋予最广泛的解释,以涵盖所有此类修改以及等同的结构和功能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1