迁移支持装置的制作方法
本发明涉及所谓的遗留系统迁移(下面有时简称为“迁移”)的技术,尤其涉及伴随字符代码体系切换的迁移技术。
背景技术:
近年来,希望进行用于将此前在当前计算机中运行的业务系统(遗留系统)转移至新计算机的迁移服务的企业、自治团体等较多。作为迁移的形式,例如存在从通用的主机计算机(或者办公计算机)向WINDOWS(注册商标)、UNIX(注册商标)、LINUX(注册商标)等OS(Operating System:操作系统)所运行的开放式的服务器计算机迁移的形式。此外,与迁移有关的技术已被大量公开,例如被专利文献1所公开。
但是,存在如下情况,即利用预定的字符代码体系(例:EBCDIK(Extended Binary Coded Decimal Interchange Kana Code:扩充的二进制编码的十进制交换假名编码)、KEIS(Kanji processing Extended Information System:汉字处理扩充信息系统)、JIS8、SJIS(Shift JIS)。下面有时称为“旧字符代码体系”)来处理数据的主机计算机登记有大量在其字符代码体系中未登记在标准中的非标准字符(主机计算机的非标准字符区域为9024字符的量)。此时,无法实现向仅可提供较小的非标准字符区域的OS(WINDOWS所提供的非标准字符区域为1880字符的量)所运行的服务器计算机的迁移。
另外,近年来,相对于可使用的字符数有限的当前计算机,在大多数企业、自治团体等中产生了想要在新计算机中增加可使用的字符数的愿望。具体来说,伴随着国际化,有了以下的愿望:希望不只是汉字,还能够表现简体字或朝鲜字符等外国字符,而为了准确表示个人也能够表现旧汉字等。
因此,作为针对这些情况的对策,考虑向将UTF(Unicode Transformation Format:统一码转换格式)-8、UTF-16等更大规模的字符代码体系作为新字符代码体系来进行处理的新计算机迁移。
在迁移中,主要进行:(1)业务系统上已有数据的转移;以及(2)存取这种数据的、在业务系统上运行的已有程序的转移。因此,所转移的已有字符数据需要转换字符数据,以与新字符代码体系相对应。另外,已有程序(例如,以COBOL语言记述的程序)需要转换为能够读入对字符代码进行转换后的字符数据。
但是,在现有技术中,存在相较于被分配给字符数据的字符代码的转换,程序转换非常繁琐且困难的问题。该问题的产生是因为通过旧字符代码体系与新字符代码体系的组合,即使是相同的字符,表现该字符的字节列的字节数在两字符代码体系之间也不一样,并且已有程序为了存储字符的字节列而指定的存储器上的区域长度为固定长。在程序进行转换时,需要考虑这些情况来适当修正程序的记述内容(若不修正,则将产生字符数据溢出、位置偏移等,程序将取得与作为目标的字符数据不同的字符数据)。但是,修正模式根据存储在区域中的字符的字节列而不同,因此修正变为非常繁琐且困难的作业。在包含专利文献1的技术的现有技术中,均不存在针对这种作业的改善方案。
现有技术文献
专利文献
专利文献1:日本专利第4405571号公报
技术实现要素:
发明要解决的课题
因此,本发明鉴于这种情况而完成,其目的在于,在伴随向不同的字符代码体系切换的迁移中,使成为迁移对象的程序的转换变得容易。
用于解决课题的手段
为了实现所述目的,本发明提供一种迁移支持装置,对从第1计算机向第2计算机的迁移进行支持,其特征在于,该迁移支持装置具备:字符代码转换部,其参照存储部具有的字符代码转换表,将被分配给所述第1计算机具有的第1文档文件中的字符数据的第1字符代码转换为被分配给所述第2计算机具有的第2文档文件中的字符数据的第2字符代码;程序转换部,其将所述第1计算机具有的、用于处理所述第1文档文件的第1程序转换为所述第2计算机具有的、用于处理所述第2文档文件的第2程序;交换信息生成部,其通过使所述第2程序读入被分配了所述第2字符代码的字符数据,针对读入的所述字符数据生成交换信息,该交换信息将所述第2程序指定的存储器上的区域数量决定为与表现被分配给所述字符数据的第1字符代码的字节列的字节数相同;以及区域存储部,其在由所述交换信息决定的数量构成的所述区域中存储被分配给读入的所述字符数据的1个所述第2字符代码。
对于其他手段将进行后述。
作为遗留软件的第1程序将字符数据的大小(项目的长度)当作字节列的字节数,并在存储器上指定与字节数相同数的区域来存储字符数据的字节列。也就是说,像以往那样,第1程序将存储器上指定的区域设为用于存储1字节的数据的区域,以字节数单位来处理字符数据。另外,第1程序的源代码的记述内容将与其处理相对应。
与此相对,转换后的第2程序在通过字符代码的转换,对表现1个字符的字节列的字节数不同的字符数据进行处理时,通过参照交换信息,可以使用与第1程序使用的区域数量相同数量的区域。也就是说,第2程序可以将存储器上指定的区域设为用于存储1个字符的数据的1个或者多个区域,并以字符数单位来处理字符数据。因此可以使由第2程序构建的逻辑与由第1程序构建的逻辑相同,无需修正在第2程序的源代码的记述内容之中,与逻辑有关的部分(例如,COBOL语言中的位数)。
因此,在伴随向不同字符代码体系的切换的迁移中,可以使成为迁移对象的程序的转换变得容易。
发明效果
根据本发明,在伴随向不同字符代码体系的切换的迁移中,可以使成为迁移对象的程序的转换变得容易。
附图说明
图1是表示本实施方式的迁移支持装置的功能结构的图。
图2是表示交换信息的数据构造的图。
图3是表示本实施方式的迁移支持装置的处理的流程图。
图4是用于说明作为比较例,在与从EBCDIK+KEIS代码向UTF-8代码的转换相配合地转换COBOL语言的程序时,设为需要修正源代码的记述内容的情况的图,其中,(a)表示转换前程序的源代码之中数据部工作节的记述例、以及将该记述例具体化后的区域的示意图,(b)是转换后程序的源代码之中数据部工作节的记述例、以及将完成预定修正后的记述例具体化后的区域的示意图。
图5是用于说明作为本实施例,在与从EBCDIK+KEIS代码向UTF-8代码的转换相配合地转换COBOL语言的程序时,设为不需要修正源代码的记述内容的情况的图,其中,(a)表示使转换前程序的源代码之中数据部工作节的记述例、以及将该记述例具体化后的区域的示意图,(b)是转换后程序的源代码之中数据部工作节的记述例、以及将不需要预定修正的记述例具体化后的区域的示意图。
具体实施方式
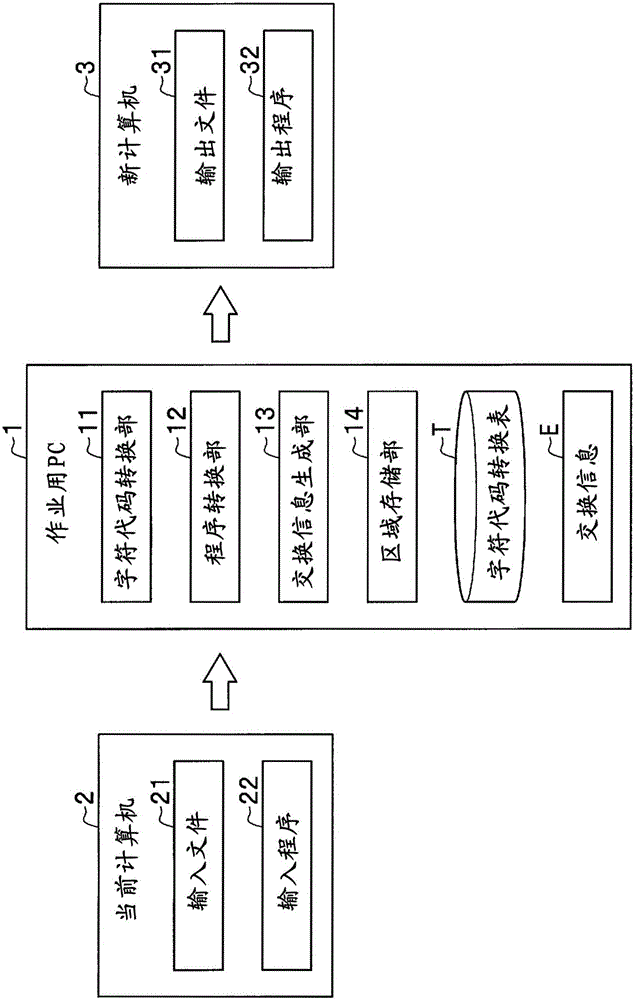
如图1所示,作业用PC1是负责从当前计算机2向新计算机3的迁移的作业员所操作的计算机,为本实施方式的迁移支持装置。作业用PC1从当前计算机2取得输入文件21及输入程序22,并进行预定的转换(详细内容将予以后述)后,作为输出文件31及输出程序32输出至新计算机3。
当前计算机2(第1计算机)为通用的主机计算机。
新计算机3(第2计算机)为开放式的服务器计算机。
输入文件21(第1文档文件)为包含字符数据的文档文件,是当前计算机2的遗留软件。输入文件21中的字符数据将按照当前计算机2所处理的字符代码体系。当前计算机2所处理的字符代码体系对于半角英数字符、半角记号以及半角假名字符的字符数据为EBCDIK,对于全角字符的字符数据为KEIS。在本实施方式中,有时将分配至输入文件21中的字符数据的字符代码称为“EBCDIK+KEIS代码”。
此外,EBCDIK针对半角英数字符、半角记号以及半角假名字符以1个字节来表现1个字符(字节数=1)。KEIS对于全角字符以2个字节来表现1个字符(字节数=2)。
输入程序22(第1程序)为用于处理输入文件21的程序,是当前计算机2的遗留软件。输入程序22通过COBOL语言来记述,其记述内容符合由EBCDIK兼KEIS构成的字符代码体系。
输出文件31(第2文档文件)为包含字符数据的文档文件。输出文件31中的字符数据按照新计算机3所处理的字符代码体系。新计算机3所处理的字符代码体系针对半角英数字符、半角记号、半角假名字符及全角字符中任一种字符的字符数据均为UTF-8。在本实施方式中,有时将分配至输出文件31中的字符数据的字符代码称为“UTF-8代码”。
此外,UTF-8针对半角英数字符及半角记号以1个字节来表现1个字符(字节数=1),针对半角假名字符及全角字符以3个字节来表现1个字符(字节数=3)。
输出程序32(第2程序)是用于处理输出文件31的程序。在本实施方式中,将输出程序32设为以COBOL语言来记述。但是,通过实施周知形式的记述,可以以JAVA(注册商标)语言来记述输出程序32。
此外,作业用PC1包含输入部、输出部、控制部以及存储部这样的硬件。例如,在控制部由CPU(Central Processing Unit)构成的情况下,基于包含该控制部的计算机的信息处理通过基于CPU的程序执行处理来实现。另外,该计算机所包含的存储部对CPU所指示且用于实现该计算机的功能的程序进行存储。由此实现软件与硬件的协作。所述程序记录在记录介质中、或者经由网络而被提供。
如图1所示,作业用PC1具有:字符代码转换部11、程序转换部12、交换信息生成部13、区域存储部14这样的功能部,并将字符代码转换表T、以及交换信息E存储在存储部中。
字符代码转换部11参照字符代码转换表T,将分配至输入文件21中的字符数据的EBCDIK+KEIS代码(第1字符代码)转换为分配至输出文件31中的字符数据的UTF-8代码(第2字符代码)。
程序转换部12将输入程序22转换为输出程序32,使得与基于字符代码转换部11的字符代码转换相对应。程序转换部12可以将输出程序32的记述语言转换为与输入程序22的记述语言相同,(例:COBOL→COBOL),也可以转换为不同(例:COBOL→JAVA)。
交换信息生成部13通过使输出程序32读入被分配了UTF-8代码的字符数据,针对已读入的字符数据生成交换信息E,该交换信息E将输出程序32指定的存储器上的区域数量确定为与表现分配至字符数据的EBCDIK+KEIS代码的字节列的字节数相同。
输出程序32读入的、被分配了UTF-8代码的字符数据例如为从输出文件31提取的字符数据。
区域存储部14在由通过交换信息E确定的数量所构成的所述区域中,存储被分配至在输出程序32中已读入的字符数据的1个UTF-8代码。
字符代码转换表T针对预定的字符集合(例如,当前计算机2所处理的由EBCDIK兼KEIS构成的字符代码体系中规定的字符的字符集合)中包含的字符,将分配至该字符的、EBCDIK+KEIS代码和UTF-8代码对应起来。对应的详细内容周知,从而省略说明。
交换信息生成部13生成的交换信息E,按被分配了UTF-8代码的字符数据,将该字符数据的大小(项目的长度)即字节数、以及输出程序32所指定的存储器上的区域数量进行对应。
如图2所示,分配至各种字符数据的UTF-8代码可以分类为表示半角英数记号的字符(半角英数字符+半角记号)的字符代码、表示半角假名字符的字符代码、以及表示全角字符的字符代码。对于被分类的字符代码,决定上述“字节数”及“区域数量”。
针对表示半角英数记号字符的字符代码,如上所述,UTF-8以1个字节来表现对应的1个字符,因此“字节数”为“1”。另外,如上所述,EBCDIK针对半角英数字符及半角记号以1个字节来表现1个字符,因此通过交换信息生成部13的功能,“区域数量”为“1”。
针对表示半角假名字符的字符代码,如上所述,UTF-8以3个字节来表示对应的1个字符,因此“字节数”为“3”。另外,如上所述,EBCDIK针对半角假名以1个字节来表现1个字符,因此通过交换信息生成部13的功能,“区域数量”为“1”。
针对表示全角字符的字符代码,如上所述,UTF-8以3个字节来表示对应的1个字符,因此“字节数”为“3”。另外,如上所述,KEIS针对全角字符,以2个字节来表现1个字符,因此通过交换信息生成部13的功能,“区域数量”为“2”。
交换信息E的内容根据由当前计算机2处理的字符代码体系与由新计算机3处理的字符代码体系的组合来决定。
《处理》
针对本实施方式的处理进行说明。该处理的主体为作业用PC1的控制部,但是为了说明上的方便,省略“控制部”这样的词语。
如图3所示,作业用PC1每次进行从当前计算机2向新计算机3的迁移,都从步骤S1开始处理。
在步骤S1中,作业用PC1从当前计算机2取得输入文件21及输入程序22。在步骤S1之后,转入步骤S2。
在步骤S2中,作业用PC1通过字符代码转换部11,针对已取得的输入文件21中的字符数据,将字符代码从EBCDIK+KEIS代码转换为UTF-8代码,生成输出文件31。在步骤S2之后,转入步骤S3。
在步骤S3中,作业用PC1通过程序转换部12,将已取得的输入程序22转换为输出程序32。在步骤S3之后,转入步骤S4。
在步骤S4中,作业用PC1通过输出程序32读入被分配了UTF-8代码的字符数据。在步骤S4之后,转入步骤S5。
在步骤S5中,作业用PC1通过交换信息生成部13,针对步骤S4中已读入的字符数据,生成交换信息E。在步骤S5之后,转入步骤S6。
在步骤S6中,作业用PC1通过区域存储部14,在由交换信息E确定的数量构成的区域(输出程序32所指定的存储器上的区域)中,将对应的UTF-8代码、也就是被分配至步骤S4中已读入的字符数据的UTF-8代码存储。在步骤S6之后,结束图3的处理。
通过作业用PC1生成的输出文件31、输出程序32、以及交换信息E被输出至新计算机3。这里,由于通过新计算机3来执行预定的业务处理,因此考虑输出程序32打开输出文件31的情况。此时,输出程序32参照交换信息E,按照输出程序32确定的顺序,对在输出程序32所指定的存储器上的区域中存储的UTF-8代码进行存取。
输入程序22将输入文件21中的字符数据的大小(项目的长度)处理为字节列的字节数,在存储器上指定与字节数相同数的区域并存储字符数据的字节列。也就是说,像以前那样,通过当前计算机2,输入程序22将存储器上的指定的区域设为用于存储1个字节的数据的区域,按字节数单位来处理输入文件21中的字符数据,由此实质上逐个字符依次来处理字符数据。
通过将字符代码从EBCDIK+KEIS代码转换为UTF-8代码,针对字节列的字节数变更后的字符数据,交换信息E可以使输出程序32在存储器上指定的区域数量与输入程序22在存储器上指定的区域数量相同。例如,若从EBCDIK+KEIS代码转换为UTF-8代码,则针对字节列的字节数从“2”变更为“3”的全角字符的字符数据,输出程序32通过参照交换信息E,可以将存储器上指定的区域数量设为“2”,而不是像现有技术那样设为“3”。区域存储部14在(连续)2个区域中存储分配至该全角字符的1个UTF-8代码。
因此,输出程序32可以将存储器上指定的区域作为用于存储1个字符的数据的区域,而不是用于存储1个字节的数据的区域,可以按字符数单位来处理输出文件31中的字符数据。其结果是,与输入程序22逐个字符依次处理输入文件21中的字符数据同样地,在新计算机3中,输出程序32也可以逐个字符依次处理输出文件31中的字符数据。也就是说,即使进行伴随字符数据大小不同的字符代码的转换的迁移,也可以使由输出程序32构建的逻辑与由输入文件21构建的逻辑保持相同。进行迁移的作业者,无需修正输出程序32的源代码的记述内容之中与逻辑有关的部分。
此外,作业用PC1可以进行控制,以使输出程序32在存储器上另外指定逐个字节存储被分配了UTF-8代码的字符数据的字节列的规定个数(例如,如果是全角字符则为3个)的区域(用于存储1个字节的数据的区域)。并且,作业用PC1进行控制,以使区域存储部14存储1个UTF-8代码的1个或者2个区域、与所述规定个数的区域相关联。因此,在新计算机2中,输出程序32在对区域存储部14所存储的UTF-8代码进行存取时,通过对所述相关联的区域中存储的字节列进行存取,可以处理成为对象的字符数据。
《具体例》
参照图4、图5,对通过伴随字符代码体系切换的迁移来转换程序的具体例进行说明。在本具体例中,转换前程序(相当于输入程序22)以及转换后程序(相当于输出程序32)都用COBOL语言来记述。转换前程序所处理的字符代码为EBCDIK+KEIS代码,转换后程序所处理的字符代码为UTF-8代码。
在图4中示出了作为现有技术的比较例。在图4的(a)的上部示出了在转换前程序的源代码之中的数据部工作节的记述例。在集团项目DATA-A之中,DATA-A1及DATA-A2这样的变量(项目)按该顺序被声明。
在DATA-A1中,“PIC X”表示在存储器上确保每个字符1个字节的数据(EBCDIK)存储区域,“(03)”表示该区域有3个(位数为3)。因此,可以向DATA-A1(半角字符)输入3个字符的量的数据。
在DATA-A2中,“PIC N”表示在存储器上确保每个字符2个字节的数据(KEIS),“(03)”表示该区域有3个(位数为3)。因此,可以向DATA-A2(全角字符)输入3个字符的量的数据。
此外,COBOL语言以固定长来对变量进行声明。
在图4的(a)的下部示出了将上述记述例具体化后的区域的示意图。若用1个箱子表示1个区域,则该箱子表示1字节的数据存储区域。根据该示意图,转换前程序针对DATA-A1在存储器上指定3字节的量的区域,由此能够向DATA-A1输入3个字符的量的数据。另外,针对DATA-A2在存储器上指定6字节(2字节×3)的量的区域,由此能够向DATA-A2输入3个字符的量的数据。这样,转换前程序像以往那样,按1个字节来指定存储字符数据的字节列的区域,按字节数单位来处理字符数据(从左开始逐个依次存取箱子内的字节列)。
这里,当在迁移中转换字符代码、也转换程序时,为了准确无误地处理表现1个字符的字节列的字节数不同的字符数据(为了可靠读取设为目标的字符数据),在现有技术中,需要以手动作业来修正转换后程序的逻辑。
在图4的(b)的上部示出了在转换后程序的源代码之中数据部工作节的记述例。为了在程序的转换前后使逻辑相同,对于图4的(a)的记述例,需要进行追加如图中的下划线部所示的记述的修正。
作为所述修正,针对DATA-A1,将位数从3变更为9。这样变更位数的理由是由于相对于EBCDIK以1个字节来表现半角假名的1个字符,UTF-8以3个字节来表现半角假名的1个字符,因此使DATA-A1具有9个字节的量的区域(3个字节×3个字符),从而能够应对向DATA-A1输入半角假名的3个字符的量的字节列的情况(为了防止数据的溢出)。
另外,作为所述修正,针对DATA-A2,将位数从3变更为5。这样变更位数的理由是由于相对于KEIS以2个字节来表现全角字符的1个字符,UTF-8以3个字节来表现全角字符的1个字符,因此使DATA-A2至少具有9个字节的量的区域(3个字节×3个字符),从而能够应对向DATA-A2输入全角字符的3个字符的字节列的情况。在图4的(b)的例子中,通过将DATA-A2的位数设为5,使DATA-A2具有10个字节的量的区域。
在图4的(b)的下部示出了将完成上述修正后的记述例具体化后的区域的示意图。图4的(b)所示的箱子与图4的(a)所示的箱子同样地,表示1个字节的数据存储区域。所述修正的结果,通过增加箱子数量,在转换后程序中仍保持如可以向DATA-A1输入3个字符的量的数据、以及可以向DATA-A2输入3个字符的量的数据这样的转换前程序的特性。但是,像增加这种箱子这样来修正程序中构建的逻辑,需要针对程序中的所有变量来进行,因此需要极大的作业量。
图5示出了本实施例。图5的(a)与图4的(a)相同。也就是说,能够向变量DATA-A1输入3个字符的量的数据,能够向变量DATA-A2输入3个字符的量的数据。
在图5的(b)的上部示出了转换后程序的源代码之中数据部工作节的记述例。在本实施例中转换程序时,可以使用已说明的交换信息E。
如已说明的那样,根据交换信息E,转换后程序在存储器上指定的区域将作为用于存储1个字符的数据的区域来发挥作用,而不是作为用于存储1个字节的数据的区域来发挥作用。这种情况与图5的(b)的下部所示,1个箱子将1个区域表示为半角英数记号假名字符的1个字符的数据存储区域同义。这里,像“半角英数记号假名字符”这样的词语是指将半角英数字符、半角记号及半角假名字符汇总后的词语。半角英数记号假名字符的1个字符的数据存储区域若并排2个,则可以表示全角字符的1个字符的数据存储区域。
因此,在图5的(b)的记述例中,DATA-A1的“PIC X(03)”可以表示在存储器上确保3个半角英数记号假名字符的1个字符的数据(UTF-8)存储区域。这种情况表示即使不如图4的(b)所示那样增加位数(即使不修正逻辑),也能够向变量DATA-A1输入3个字符的量的数据(被分配了UTF-8代码的字符数据)。
另外,DATA-A2的“PIC N(03)”可以表示在存储器上确保3个全角字符的1个字符的数据(UTF-8)存储区域。这种情况表示即使不如图4的(b)所示那样增加位数(即使不修正逻辑),也能够向变量DATA-A2输入3个字符的量的数据(被分配了UTF-8代码的字符数据)。
如已说明的那样,在1个或者2个半角英数记号假名字符的1个字符的数据存储区域中,存储1个UTF-8代码。因此,在执行预定业务处理时,转换后程序如果按预定的顺序对存储在区域中的UTF-8代码进行存取,则可以按字符数单位来处理字符数据。
这样,通过使用交换信息E,转换后程序改变存储器上指定的区域的处理,由此可以消除修正程序中构建的逻辑这样的极大的作业量。
《总结》
根据本实施方式,已转换的输出程序32通过字符代码的转换,在对表现1个字符的字节列的字节数不同的字符数据进行处理时,通过参照交换信息E,可以使用与输入程序32所使用的区域的数量相同数量的区域。也就是说,输出程序32可以将存储器上指定的区域设为用于存储1个字符的数据的1个或者多个区域,并按字符数单位来处理字符数据。因此,可以使输出程序32中构建的逻辑与输入程序32中构建的逻辑相同,无需修正在输出程序32的源代码的记述内容之中与逻辑有关的部分。
因此,在向不同字符代码体系的切换所伴随的迁移中,可以使成为迁移对象的程序的转换变得容易。
《其他》
在本实施方式中,针对从使用EBCDIK及KEIS的字符代码体系向使用UTF-8的字符代码体系的切换所伴随的迁移进行了说明。但是,针对从使用JIS8及SJIS的字符代码体系向使用UTF-8的字符代码体系的切换所伴随的迁移,也可以应用本发明。
此外,JIS8对于半角英数字符、半角记号及半角假名字符,以1个字节来表现1个字符(字节数=1)。SJIS对于全角字符以2个字节来表现1个字符(字节数=2)。
另外,在本实施方式中,区域存储部14在输出程序32所指定的存储器上的区域中存储有UTF-8代码。但是,不必是UTF-8代码,也可以存储能够识别相应字符数据的任意形式的数据。
另外,在本实施方式中,在交换信息生成部13生成交换信息E时,将输出程序32所读入的、被分配了UTF-8代码的字符数据设为例如从输出文件31提取的字符数据。但是,例如作业用PC1为了针对预定的字符集合(例如,在向处理UTF-8的开放式服务器计算机进行迁移时,由现有的所有字符构成的字符集合)中包含的所有字符生成交换信息E,也可以从外部事先取得被分配了UTF-8代码的字符数据,并使输出程序32读入已取得的字符数据。
另外,也可以实现对本实施方式中说明的各种技术进行适当组合后的技术。
可以将本实施方式中说明的软件实现为硬件,还可以将硬件实现为软件。
此外,针对硬件、软件、流程图等,在不脱离本发明的主旨的范围内可以进行适当变更。
符号说明
1 作业用PC(迁移支持装置);
11 字符代码转换部;
12 程序转换部;
13 交换信息生成部;
14 区域存储部;
2 当前计算机(第1计算机);
21 输入文件(第1文档文件);
22 输入程序(第1程序);
3 新计算机(第2计算机);
31 输出文件(第2文档文件);
32 输出程序(第2程序);
T 字符代码转换表;
E 交换信息。
- 还没有人留言评论。精彩留言会获得点赞!