使用WEB风格排名和多个语言理解引擎的对话状态追踪的制作方法
口语对话系统经由口语语言与用户进行交互从而帮助他们实现目标。对于输入而言,口语对话系统依赖于自动话音识别(ASR)将话音转换为词语,并且口语语言理解(SLU)对词语进行翻译从而确定局部含义,局部含义是被包含于一个回合(turn)的用户话音之中的含义。然而,ASR和SLU易于发生错误。如果未经过检查,错误实质性地损害用户体验并且最终会使得对话系统毫无用处。甚至看似很低的错误率在对话系统中也会存在问题。例如,如果识别错误仅在5%的回合中发生而平均对话为20个回合,则大部分对话(65%)包含至少一个错误。认识到错误的可能性,ASR和SLU除了它们的最佳猜测之外还在被称作N最佳(N-best)列表的列表上输出备选。
对话状态追踪克服了口语对话系统中的很大一部分识别错误;然而,对话状态追踪的多个方面仍然存在问题。在对话状态追踪中所使用的两种主要方法是生成模型和判别模型。诸如n-gram(n元)模型、Bayes分类器和隐马尔科夫模型的生成模型依赖于话语(utterance)的概念和语音成分的联合概率来确定含义。相比之下,判别模型基于在给定话语的语义成分的情况下的概念的条件概率而学习分类函数。
总体上,所解决的技术问题是改进统计对话状态追踪中的准确性。本发明正是针对这些和其它考虑事项所作出。虽然讨论了相对具体的问题,但是应当理解的是,这里所公开的方面并不应当限于解决
背景技术:
中所标识的具体问题。
技术实现要素:
提供该发明内容而以简化形式对以下将在具体实施方式中进一步进行描述的概念的选择进行介绍。该发明内容并非意在标识所请求保护主题的关键特征或必要特征,其也并非意在被用来帮助确定所请求保护主题的范围。
对话状态追踪系统和相关方法的多个方面包括使用多个自动话音识别器(ASR)引擎和/或多个口语语言理解(SLU)引擎。在存在诸如错误识别话语的错误的情况下,每个附加ASR或SLU引擎增大了该对话状态追踪系统所考虑的对话状态假设的集合将会包括正确对话状态的机会。如果正确对话状态并不存在于该对话状态假设的集合中,则该对话系统没有办法有效地理解用户的目标并适当作出响应。另外,每个附加ASR或SLU引擎提供了用于对每种对话状态进行打分的附加特征。
每个SLU可以与对话状态打分器/排名器(DSR)引擎进行配对。一个附加方面是使用来自单个带注释训练数据集的不同子集对SLU/DSR配对进行训练。该训练数据集可以被划分为对应于所要训练的SLU/DSR配对的数目的多个部分。该SLU引擎使用该训练数据集的第一部分进行训练。该对话状态打分/排名模型利用该训练数据集的其它部分进行训练。该数据集的多个部分可以被反转并且该处理被重复以对另外的SLU/DSR配对进行训练。另外,可以通过使用不同的训练参数对两个附加的DSR进行训练。
另一个方面是使用具有自动生成的特征结合的判别模型来基于对话状态特征而进行的web风格的对话状态排名。这可以通过使用web风格(即,学习-排名(learning-to-rank))算法来构建对话状态排名模型而替代传统的生成或判别对话打分方法。web风格排名任务的目标是在给定查询的情况下按照相关性对N个文档的集合进行排序。web风格排名算法的输入是查询Q以及文档集合X={D1,…,DN},其中每个文档针对该文档的特征以及查询φ(Di,Q)进行描述。输出是每个文档的得分,其中最高得分指示最为相关的文档。对话状态排名对web风格排名进行适配从而对与对话状态φ(Xi)相关联的特征而不是文档特征和查询φ(Di,Q)进行排名。web风格排名算法允许特征结合得以被自动构建。
该对话状态追踪系统的多个方面可以由SLU模块、对话管理器和ASR中一个或多个来实现。因此,该对话状态追踪系统可以包含SLU模块、对话管理器的多个部分、以及可选地ASR。每个方面独立地改进对话状态追踪的准确性并且可以以各种组合方式进行组合以便实现更大改进。
附图说明
本公开另外的特征、方面和优势将通过参考以下附图而得到更好地理解,其中要素并非依比例绘制从而更为清楚地示出细节,并且其中同样的附图标记贯穿多个视图而指示同样的要素:
图1是图示对话状态追踪系统的多个方面的系统示图;
图2提供了对话状态追踪的概况;
图3A到图3C是示出用于训练SLU和DSR的配对以实现本发明的多个方面的可扩展方法的示意图;
图4A到图4C图示了采用多个ASR和/或SLU模块的对话状态追踪系统的多个方面;
图5图示了依据本发明多个方面的使用web风格排名算法所生成的单个决策树的示例;
图6A是图示图1的系统所执行的用于对话状态追踪的方法的多个方面的高阶流程图;
图6B是使用web风格排名对对话状态进行打分的对话状态打分/排名操作的流程图;
图7是图示适合于实施本发明多个方面的计算设备的物理组件的框图;
图8A图示了适合于实施本发明多个方面的移动计算设备;
图8B是图示了适合于实施本发明多个方面的移动计算设备的架构的框图;和
图9是本发明的多个方面可以利用其进行实施的分布式计算系统的简化框图。
具体实施方式
以下将参考形成本发明一部分并示出各具体示例性方面的附图更完整地描述本发明的各个方面。然而,本发明可以以许多不同的形式来实现,而并不应当将其解释为限于此处所阐述的方面;相反地,提供这些实施例以使得本公开透彻和完整,并且会将各方面的范围完全传达给本领域普通技术人员。各个方面可以实施为方法、系统或设备。因此,各实现方式可以使用硬件、软件或者软件和硬件和软件的组合来实施。因此,以下详细描述并非在限制意义上进行。
对话状态追踪系统和相关方法的多个方面在这里进行描述并且在附图中有所图示。该系统的一个方面是使用多个ASR和/或多个SLU引擎,它们生成竞争结果,这些结果改进了该系统能够得到正确对话状态的似然性并且提供了用于对对话状态假设进行打分的附加特征。一个附加方面是使用来自单个带注释训练数据集的不同子集对SLU引擎和DSR引擎进行训练。一个另外方面是对来自该带注释训练数据集的反转子集的多个SLU/DSR配对进行训练。另一个方面是对于使用具有自动生成的特征结合的判别模型来基于对话状态特征进行的web风格的对话状态排名的使用。另外的方面包括使用多个参数集对每个对话状态排名引擎进行训练以产生另外的排名引擎并且对从多个排名引擎所获得的排名进行平均。每个方面独立地改进对话状态追踪的准确性并且可以以各种组合方式进行组合以便实现更大改进。
这里所描述的对话状态追踪系统能够被应用于使用各种形态,输入和输出二者的对话系统,诸如话音、文本、触摸、手势以及它们的组合(例如,多模式对话系统)。如这里所使用的,术语“话语”宽泛地涵盖了任意类型的谈话输入,包括但并不限于话音、文本输入、触摸和手势。对于任何特定形态的对话系统或谈话输入的引用或描述应当宽泛地被理解为连同相对应的硬件和/或软件修改一起涵盖其它形态或谈话输入从而实现其它的形态。对于口语对话系统的引用和描述仅是对从这里所描述的对话状态追踪系统所获益的对话系统形态的一种适合实施方式的说明,而并不应当被理解为将范围限于话音形态或单一形态。
图1是图示该对话状态追踪系统的多个方面的系统示图。对话状态追踪系统100在诸如口语对话系统的对话系统102的环境中进行图示。对话系统102包括接受来自用户的输入的用户接口104。用户接口104可以包括软件组件,诸如用户代理108(即,客户端应用),和/或促成与用户代理108和/或对话系统102进行交互的硬件组件。例如,用户接口104可以包括一个或多个用于接受用户话语的输入设备110,诸如用于接受音频输入(即,口语话语)的麦克风110a或者用于接受文本输入(即,键入话语)的键盘110b(物理键盘或者经由触摸屏的虚拟键盘)。类似地,用户接口104可以包括一个或多个用于呈现对话系统102的输出的输出设备112,诸如用于产生视觉输出的显示屏112a和/或用于生成听觉输出(例如,计算机所生成的话音)的音频变换器112b(例如,扬声器)。
对话系统102可以包括自动语音识别器(ASR)模块114(即,话语解码器),其将口语话语转换为计算机可读文本以便由对话系统102进行处理。由于话音识别易于出错,所以识别结果可以包含对应于口语话语的可能识别结果并且被展现为加权的备选的多种文本表示。例如,ASR模块114可以生成N最佳列表或词语混淆网络(word confusion network)。如这里所描述的,对话状态追踪系统100的ASR模块114可以包含一个或多个ASR引擎。
口语语言理解(SLU)模块116将ASR模块的输出转换为对应于用户话语的含义表示。SLU模块116对计算机可读文本进行分解和解析。该计算机可读文本被转换为可以被机器所理解并处理的语义表示。如同ASR输出一样,该含义表示可以包含计算机可读文本的备选含义。如这里所描述的,对话状态追踪系统100的SLU模块116可以包含一个或多个SLU引擎。
对话管理器118作用于SLU模块116的输出。对话管理器118是对话系统102中具有状态的组件,其最终负责对话的展开(即谈话)。对话管理器118通过更新对话会话120以反映当前对话状态而保持对谈话的追踪,控制谈话的展开,并且基于当前对话状态(即,参与谈话/对用户作出响应)执行适当机器动作。对话会话120是可以存储用户106和对话系统102之间的交互的任意和所有方面的数据集。对话会话120所存储的对话状态信息的类型和数量可以基于对话系统102的设计和复杂度而有所变化。例如,大多数对话系统所存储的基本对话状态信息包括但并不局限于话语历史、来自用户的最后命令,以及最后的机器动作和当前对话状态。
对话管理器118基于SLU模块116的输出列举对话状态假设的集合并且从来自SLU模块116、对话会话120以及可选地ASR模块114的输出提取特征以追踪对话状态。该对话状态假设可以以平面列表进行列举,或者以诸如分区集合的其它结构进行列举。对话状态打分器/排名器(DSR)模块122基于所提取的特征对对话状态假设进行打分或排名。对话管理器118选择打分或排名最高的对话状态假设作为当前对话状态,执行对应于该当前对话状态的适当机器动作,并且更新对话会话120。如这里所描述的,对话状态追踪系统100的DSR模块122可以包含一个或多个DSR引擎。
输出呈现器124生成传送对话系统102的响应的输出,其可以经由用户代理而被展现给用户。该输出生成器可选地包括可选自然语言生成组件,其将响应转换为自然(即,人类)声音文本以便展现给用户。该输出生成器可选地包括文本至话音组件,其将自然语言输出翻译为话音并且允许对话系统102与用户进行口头交互。该输出经由客户端设备的一个或多个输出设备被呈现给用户。
对话状态追踪系统100的多个方面可以由SLU模块116、对话管理器118和ASR 114中的一个或多个来实现。因此,对话状态追踪系统100可以包含SLU模块116、对话管理器118的多个部分、以及可选地ASR 114。
对话系统100中的组件,包括用户接口、ASR模块114、SLU模块116和对话管理器118,包括DSR模块122,可以在单个计算设备中实现。备选地,一些或全部的对话系统组件可以被实现为分布式计算环境中的各个计算设备的一部分。例如,用户接口104可以在客户端设备124(例如,用户的个人计算设备)中实现,而其余对话系统组件则使用经由网络128与客户端设备进行通信的一个或多个远程计算设备126(例如,服务器或服务器群)来实现,上述网络128诸如为局域网、广域网或互联网。客户端设备和远程计算设备可以被实现为计算设备,诸如但并不限于服务器或台式计算机124a、膝上计算机124b、平板计算机124c、智能电话124d、智能手表、智能电器、车辆娱乐或导航系统、视频游戏系统和消费电子设备。
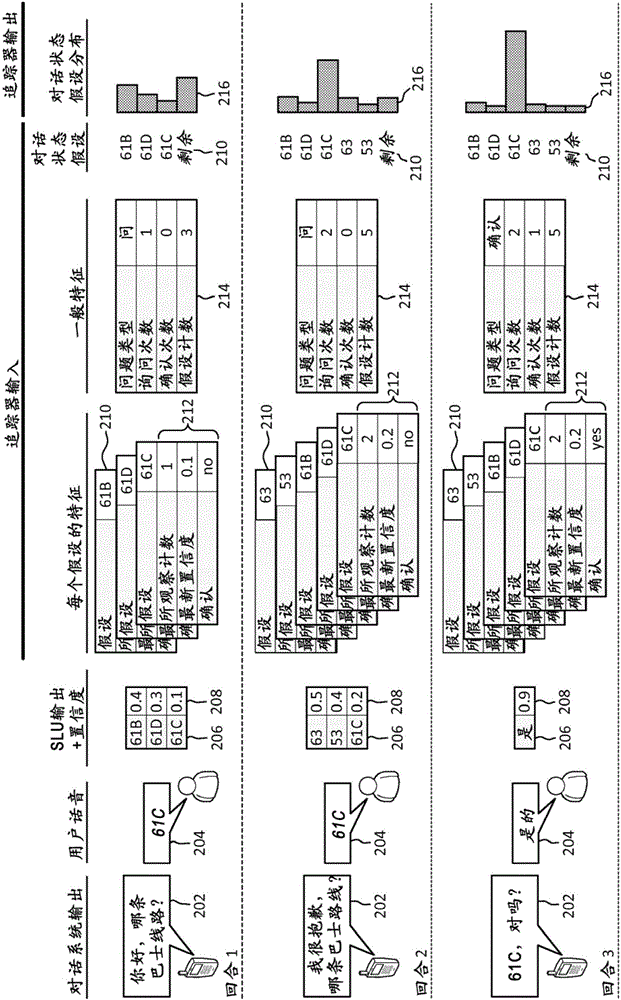
图2使用巴士调度信息作为示例而提供了对话状态追踪的概况。对话状态可能指示用户所期望的巴士路线、起点和目的地。如之前所提到的,对话状态追踪之所以困难是因为自动话音识别和口语语言理解错误是常见的,并且会导致系统误解用户的需求。与此同时,状态追踪之所以至关重要则是因为该系统依赖于所估计的对话状态来选择动作—例如,哪个巴士调度信息展现给用户。
该对话状态追踪问题能够进行如下形式化表示。对话中的每个系统回合是一个数据点。针对每个数据点,输入由三个项所组成:描述当前对话情境的K个特征的集合,G个对话状态假设,以及针对每个对话状态假设对该对话状态假设进行描述的H个特征。
在所描绘的示例中,对话状态包含用户所期望的巴士路线。在每个回合,系统产生口语输出202。用户的口语响应204被处理从而提取出口语语言理解结果206的集合,其中每一个都具有本地置信度得分208。G个对话假设210的集合通过考虑截至目前所观察到的所有SLU结果而形成,包括当前回合以及所有之前的回合。在该示例中,最初在回合1处产生三个对话状态假设(G=3),但是随着对话继续,对话状态假设210的集合扩展至五个(G=5)。针对每个状态假设,特征提取器产生特定于假设的特征212的集合(H=3),以及对当前对话情境进行描述的一般特征214的单个集合(K=4)。该对话状态追踪系统使用这些特征而产生对话状态假设的分布216,加上元假设,表示为“剩余”,其考虑到了没有一个对话状态假设210正确的可能性。
之前所描述的利用传统对话状态打分方法所存在的一些问题可以使用图2进行说明。例如,生成模型在第二回合之后可能无法给正确假设(61C)分配最高得分。作为对比,传统的判定方法虽然一般产生更为准确的分布,但是仅能够对有限数目的对话状态假设进行追踪。作为结果,传统判别模型可以考虑更多特征,但是仅是针对于前两个SLU结果。而包括正确假设(61C)在内的其余结果可能被丢弃,并且因此无法被选择为正确假定。
这里所描述的对话状态追踪系统100的多个方面包括使用多个SLU引擎。使用多个SLU引擎涉及到对传统对话状态追踪方法的各个方面的修改,但是提供了若干的优势。首先,增加SLU引擎由于每个SLU引擎的输出取决于他们各自的模型/方法会潜在地增加可用对话状态假设的数目。第二,每个附加SLU引擎提供用于根据输出的差异和从竞争输出的可用性而得出的信息二者对每个对话状态进行打分的附加特征。
在存在诸如错误识别话语的错误的情况下,每个附加SLU引擎增加了对话状态追踪系统100所考虑的对话状态假设的集合将包括正确对话状态的机会。如果正确对话状态并不在对话状态假设的集合中,则对话系统102无法有效地理解用户的目标并适当作出响应。
另外,每个附加SLU引擎提供用于对每个对话状态进行打分的附加特征。例如,每个SLU引擎可以随输出而产生置信度得分。如果两个单独的SLU引擎生成了相同的输出,但是一个置信度得分高而另一个置信度得分低,则该分歧指示包含该输出的对话状态的高度不确定性。相反地,如果两个置信度得分都高,则该一致性指示包含该输出的对话状态的高度确定性。换句话说,诸如多个SLU引擎的竞争输出之间的一致性或分歧之类的特征在为对话状态打分时提供了使精确度提高的附加信息。使用两个SLU引擎明显增加了每个联合目标的特征的数目。在测试中,在将第二SLU引擎添加至对话状态追踪系统100时,每个联合目标的特征的数目从1964增加至3140。
图3A是示出用于训练SLU和DSR的配对从而实施本发明的多个方面的可扩展方法的示意图。使用多个SLU的一个方面是一种用于使用单个训练数据集302对多个SLU和DSR进行训练的方法。实线表示在训练期间发生的活动。虚线则表示在运行时间发生的活动。
训练数据集302从在这里被表示为SLU 0的基线SLU引擎所收集。训练数据集302可以包括利用有关每个回合处的对话状态的多个方面的注释304进行标记的查询/文档配对。例如,该注释可以使用诸如“很好”、“好”、“正常”和“不相关”之类的若干级别来描述查询/文档配对的相关性。在对话状态排名的背景下,该注释级别也可以被简化为“正确”和“不正确”。当使用多个SLU引擎时,使用相同数据对每个SLU/DSR配对进行训练产生了不期望看到的偏差。该偏差可以通过将数据划分为多个部分并且使用多个部分的唯一组合来训练每个SLU/DSR配对而得以避免。部分的数目可以基于所要训练的折(fold)的数目进行选择,假设有充分训练数据可用从而每个部分包含充分的数据以便以有意义的方式对统计模型进行训练。例如,将训练数据对半分割将允许训练一个或两个折,将训练数据分割为三份则允许训练一至三个折,等等。
训练数据集302可以被分割为对应于所要训练的SLU/DSR配对的数目的多个部分。例如,如所图示的,当对两个SLU引擎进行训练时,训练数据集302被分割为两个部分—部分A 302a和部分B 302b。训练数据集302可以被划分为基本上相等的部分。第一SLU模型306a使用第一SLU引擎利用训练数据集的部分A 302a进行训练。第一对话状态打分/排名模型308a利用训练数据集的部分B 302b和训练参数集310a进行训练。该布置是指定折A 312a。该折的输出314a是可以从其选择当前对话状态的已打分/排名的对话状态假设。针对单个折,该折的输出314a是最终的DSR输出316。
图3B是图3A的训练示意图的扩展,其被扩展以示出两个折的训练。为了使得使用率最大化,训练数据集的部分302a、302b可以被反转并且在指定折B 312b的布置中重复该训练处理。换句话说,训练数据集的部分B 302b被用来训练第二SLU模型306b,而训练数据集的部分A 302a则被用来训练第二对话状态打分/排名模型308b。如所图示的,可以使用相同的训练参数集来训练第二对话状态打分/排名模型308b,或者可以使用不同的训练参数集。竞争输出314a、314b可以通过将得分进行平均被合并为组合输出318从而产生最终输出316。
两个折的组合是指定折AB 312c。如果对话状态假设仅由一些折所生成,则出于分数平均的目的,对话状态追踪系统100可以将并未生成该对话状态假设的折处理为对该对话状态假设打分为零。
图3C是图3B的训练示意图的扩展,其被扩展以示出每个折两个DSR的训练。通过针对每个折复制原始对话状态打分/排名模型308a、308b的训练,但是使用不同的训练参数310b(例如,每个树不同数目的叶子),可以针对每个折构建第二对话状态打分/排名模型308c、308d。同样,该训练示意图示出了对话状态打分/排名模型的每个配对,来自每个折的一个对话状态打分/排名模型308a、308b,使用相同的训练参数进行训练;然而,可以使用不同的训练参数集来训练个体对话状态打分/排名模型308a、308b中的一些或全部。例如,每个对话状态打分/排名模型308a、308b可以使用不同的参数集进行训练。就如其它输出一样,附加输出314c、314d被合并为组合输出318。
另一个方面是使用多于一个的ASR来进一步增加对话状态假设的集合将包括正确对话状态的机会并且提供用于为对话状态假设打分的附加特征。一些或全部的ASR可以使用不同的识别模型来产生备选的识别结果,它们使用相同的模型对单独SLU引擎进行反馈从而获得比较结果。备选地,来自使用相同识别模型的一个或多个ASR的识别结果可以使用不同模型被分布至单独的SLU引擎从而获得比较结果。另外,对使用不同模型的单独SLU引擎进行反馈的使用不同识别模型的ASR的组合可以被用来获得比较结果。
图4A图示了对话状态追踪系统100的多个方面,其中ASR 114包含对使用不同模型的多个SLU引擎116a-116d进行反馈的单个ASR引擎114a,并且该多个SLU引擎的输出由单个DSR 122a进行合并和打分。虽然每个SLU模块116接收相同的输入,但是使用不同模型可能产生不同的SLU结果。当所有SLU引擎116a-116d的结果被组合时,每个唯一的结果都增加了从其生成对话状态假设的数据集的大小。随着对话状态假设数目的增加,被对话状态追踪系统100所追踪的对话状态假设的集合包含正确的对话状态假设变得更可能。相反,如果正确的对话状态假设并未被包括在该对话状态假设的集合中,则其无法被选择,而这在并未认定对话状态追踪系统100失败的情况下也使准确性有所下降。图4B图示了对话状态追踪系统100的多个方面,其中ASR模块114包含对单个SLU引擎116a和单个DSR 122a进行反馈的多个ASR引擎114a-114d。图4C图示了对话状态追踪系统100的多个方面,其中多个ASR 114a-114d对多个SLU引擎116a-116d进行反馈,后者进而对多个DSR 122a-d进行反馈。
两个新的SLU引擎得以被构建以便随对话状态追踪系统100使用。每个SLU引擎由接受来自各种来源的各种输入特征的多个二进制分类器所组成。对话语中槽/值配对存在的似然性进行预测的二进制分类器针对每个槽/值配对而被估计。另一个二进制分类器针对每个用户对话动作被估计。第一SLU引擎接受来自由ASR所产生的N最佳列表的词语n-grams(n元),利用词语类别信息对其扩充。利用词语类别信息进行扩充导致如“在城镇的北面部分”的词语序列产生针对如下两个短语的特征:原始短语;以及其中所选择词语利用相对应词语类别被替代的短语,例如“在城镇的<位置>部分”。除了来自ASR的N最佳列表的词语n-grams之外还接受来自词语混淆网络的词语n-grams的第二SLU引擎同样利用词语类别信息进行扩充。
词语n-grams的处理可能基于训练数据中的出现频率而有所变化。例如,具有最小出现频率c(即,在训练数据中出现最小次数)的词语n-grams可以由二进制分类器所处理,而并不满足最小出现频率的那些词语n-grams则被映射至特殊UNK特征。该二进制分类器可以基于决策树、支撑矢量机(SVM)和深度神经网络,而并不限于此。基于交叉验证,SLU引擎被训练从而将在训练数据中至少出现两次的词语uni-grams和词语bi-grams(即,n=2且c=2)作为特征进行处理。针对词语混淆网络,第二SLU引擎被训练从而将uni-grams作为特征进行处理。bi-grams则并未改善性能。
N最佳列表上的最前面的SLU输出可以通过获取所有二进制分类器的最可能有效的组合来形成。该N最佳列表上的每个附加SLU输出可以通过连续获取所有二进制分类器的下一个最可能有效的组合而形成。无效SLU组合在形成SLU的N最佳列表时可以不被考虑。例如,毫无争议的对话动作和槽/值配对的所提出的最可能的组合将被跳过。输出打分可以通过所有二进制分类器的乘积来实现并且可以结合一些分数平滑。
对话状态追踪系统100并不限于以上所描述的新的SLU引擎。可以使用不同的二进制分类器或输入特征来构建其它的SLU引擎。该SLU引擎可以接受来自一个或多个共同来源的一个或多个共同的输入特征。所接受的输入特征的数目可以在SLU引擎之间有所变化。一些SLU引擎还可以接受并未被所有其它SLU引擎所接受的一个或多个输入特征/来源的组合。换句话说,一些SLU引擎可以接受并未被至少一个其它SLU引擎所接受的至少一个输入特征/来源的组合。
对话状态追踪系统100的一个方面是使用web风格(即,学习-排名)算法来构建对话状态排名模型从而替代传统的生成或判别对话打分方法。web风格排名任务的目标是在给定查询的情况下按照相关性对N个文档的集合进行排序。web风格排名算法的输入是查询Q以及文档集合X={D1,…,DN},其中每个文档关于该文档的特征以及查询φ(Di,Q)进行描述。输出是每个文档的得分,其中最高得分指示最为相关的文档。对话状态排名对web风格排名进行适配从而对与对话状态φ(Xi)相关联的特征而不是文档特征和查询φ(Di,Q)进行排名。可以被用来构建对话状态排名模型的适当学习-排名算法的示例可以包括但并不限于决策树的随机森林、提升的决策树、多个相加回归树以及其它web风格/学习-排名算法。适用于训练对话状态排名器的学习-排名算法的具体示例是lambdaMART,但并不限于此。
lambdaMART构建决策树森林。每个决策树采用一个或多个二进制分支,其在叶子节点处终止。每个二进制分支指定被应用于单个输入特征的阈值。每个叶子节点与实值相关联。对话状态使用该决策树输出的加权和进行打分。训练目标是使得排名质量最大化。排名质量的一种适当量度是一最佳(one-best)准确性或者正确对话状态有多么频繁地被排名第一,而并不限于此。训练将决策树连续添加至森林从而改进排名质量。例如,决策树可以通过正则化的梯度下降进行学习。决策树的数目M和每个决策树的叶子节点的数目L可以使用调谐参数进行配置。使用交叉验证,本发明人发现其中每个决策树具有32个叶子节点的500个决策树产生了非常好的结果(即,M=500且L=32);然而,其它值可以产生适合或卓越的结果。
使用web风格排名算法使得包含了特征结合的模型得以被自动构建。在对话状态打分中包含结合已经显示出使得对话状态追踪的准确性有所改进;然而,传统的对话状态打分方法要求结合以手工制作。手工制作特征结合并不是一种可扩展的方式。另外,由于对话状态追踪使用整个对话来收集用来推导正确对话状态的信息,所以可能的结合的数目随着对话状态假设以及相对应特征的数目增长而以指数方式增加。将这些问题放在一边,手工制作结合之所以并不切合实际是因为难以提前预测哪些结合将改进对话状态追踪的准确性。
图5图示了根据本发明的多个方面使用web风格排名算法所生成的单个决策树的示例。特别地,该决策树使用lambdaMART所生成。该树在餐厅搜索域中。由矩形所表示的每个分支(即,非终止节点)使用应用于特征的阈值而描述了一种二进制测试。由圆形所表示的八个叶子(即,终止节点)中的每一个包含以线性方式对正评估的对话状态的得分有线性贡献的实值。指向终止节点的分支路径表示在沿该路径的非终止节点中进行测试的特征的结合。所图示决策树的复杂度暗示了人类设计人员将会发现难以指定良好结合特征的可追踪集合。
图6A是包含该对话状态追踪系统的多个方面的追踪对话状态的方法的高阶流程图。方法600以解码操作602开始,其接收作为针对对话状态追踪系统100的输入提供的用户话语并且对其进行解码。该解码操作在文本对话系统中可能并非是必要的。在口语对话系统中,该解码操作使用自动话音识别器来将口语话语解码为可以由对话系统102进行处理的词语。该解码操作可以产生单个已解码的话语或者例如可以在n最佳列表上提供多个备选。该输出还可以包括诸如识别置信度得分之类的附加信息。语言理解处理操作的多个方面包括使用一个或多个输入解码器(例如,自动话音识别)。
语言理解处理操作604向已解码的话语分配含义表示。语言理解处理可以使用各种语言理解方法来完成。在口语对话系统中,对话理解可以使用口语语言理解处理技术来完成。该语言理解方法可以基于手工制作或自动生成的规则和/或生成或判别统计模型。该语言理解处理操作可以输出含义表示或者例如可以在n最佳列表上提供多个备选。该输出还可以包括诸如置信度得分之类的附加信息。该语言理解处理操作的多个方面包括使用一个或多个语言理解处理器(例如,口语语言理解引擎)。
对话状态列举操作606从该语言理解处理操作所产生的含义表示而列举对话状态假设。对于单个SLU输出U而言,该列举步骤为X′=G(s,U,X),其中U是来自单个SLU引擎的SLU假设的集合,X是对话状态的当前集合,且X'是要进行打分的对话状态假设的新的集合。多个SLU产生K个SLU输出U1,...,UK,并且该列举步骤变为X′=G(s,U1,...,UK,X)。为了适应该差异,这里所描述的对话状态追踪系统100的列举步骤可以通过采用所有SLU N最佳列表上的所有概念的联合并且从该联合而不是SLU输出列举对话状态而进行适配。
特征提取操作608从所列举的对话状态、对话会话、含义表示和/或已解码的话语中提取特征。在单SLU对话系统中,始终能够获得相同的特征。然而,在多SLU对话系统中,在不同SLU引擎所产生的特征中可能存在矛盾。例如,一些特征可能并不被所有SLU引擎所支持或者一个特征可能在任意给定回合从一个或多个SLU引擎的输出所缺失。因此,该特征提取操作可以进行适配从而应对这样的情形。
已修改的特征提取操作输出从所有SLU引擎所得出的特征。作为示例,如果特征包括来自SLU引擎的信息,则该信息被复制K次,即每个SLU引擎一次。由于槽值可能并非被所有SLU引擎所输出,所以对话状态追踪系统100增加二进制特征从而对每个SLU引擎是否输出该对话状态的槽值进行编码。这考虑到了其中特征针对一些SLU引擎并不存在的情形。这种可以或无法在使用多个SLU引擎时从所有SLU引擎所获得的信息的示例包括但并不限于置信度得分和N最佳列表位置。
对话状态打分/排名操作610基于所提取的特征而产生已排名的对话状态的集合。该已排名的对话状态的集合可以根据对话系统102的需求而包括单个成员(即,排名最高的对话状态)或多个成员。包括多个成员的已排名对话状态集合可以包括所有对话状态假设或对话状态假设的子集。例如,该已排名的对话状态集合可以包括所选择数目的排名最高的对话状态(例如,n最佳列表)。该已排名对话状态集合可以随每个已排名对话状态包括补充信息,诸如由对话状态打分/排名操作对该对话状态所给出的得分,而并不限于此。该对话状态打分/排名操作可以使用如这里所描述的web风格排名或者诸如这里所描述的多ASR/SLU对话系统中的传统对话状态打分方法。在单ASR或SLU对话系统中,该对话状态打分/排名操作包含了web风格排名的多个方面。如之前所讨论的,在对话状态打分/排名操作610中所使用的web风格排名模型利用能够自动构建结合的学习-排名算法进行构建。
机器动作选择操作612基于对话状态打分/排名操作的输出而确定对话系统102接下来应当采取什么动作。机器动作选择操作612可以考虑已排名对话状态集合的分布或者简单地考虑排名最高的对话状态来确定适当机器动作。机器动作选择操作612可选地可以在该决策中包含相关联的信息(例如,对话状态得分)。对话会话更新操作614基于对话状态打分/排名操作的输出而更新该对话会话。
图6B是对话状态打分/排名操作使用web风格排名对对话状态进行打分的流程图。对话状态打分/排名操作610以打分操作650作为开始,其中web风格排名算法的每个决策树基于构成该决策树的特征和阈值而针对对话状态输出得分分量。求和操作652使用决策树输出的加权和对对话状态进行打分。针对M个树的森林,对话状态x的得分为:
其中αm是树m的权重并且fm(x)是通过使用特征[φ1(x),...,φJ(x)]对决策树m进行评估所得到的叶子节点的值。在具有多个SLU引擎的对话系统中,平均操作654对来自所有SLU引擎的对话状态得分进行平均从而产生每个对话状态的最终得分。在单SLU对话系统中,该加权和是每个对话状态的最终得分。排名操作656基于该最终对话状态得分对对话状态进行排序。
对话状态追踪系统100可以有选择地包含这里所描述的一些或全部方面。例如,对话状态追踪系统100可以结合用于对对话状态假设进行排名的web风格排名算法而采用单SLU引擎。类似地,对话状态追踪系统100可以随传统对话状态打分算法而使用多SLU引擎。对话状态追踪系统100可以在具有或没有针对每个折的多种排名参数设置的情况下采用多个SLU引擎和web风格排名算法。对话状态追踪系统100可选地可以包含多个ASR,该ASR在具有或没有针对每个折的多种排名参数设置的情况下使用传统对话状态打分算法或web风格排名算法对多SLU引擎对话状态追踪器进行反馈。作为组合,这里所描述的多个方面产生了对话状态追踪系统100,其在采用单个SLU以及用于打分的手工编码规则的基线上显示出了23%的相对错误减少。
本申请的主题可以在各种实现方式中被实施为系统、设备和其它制品,或者实施为方法,诸如硬件、软件、计算机可读媒体或者它们的组合。这里所描述的方面和功能可以经由多种计算系统进行操作,包括但并不限于台式计算机系统、有线和无线计算系统、移动计算系统(如移动电话、上网本、平板或板式计算机、笔记本计算机和膝上型计算机)、手持设备、多处理器系统、基于微处理器或者可编程的消费电子产品、小型计算机和大型计算机。
各种类型的用户接口和信息可以经由板上计算设备显示器或者经由与一个或多个计算设备相关联的远程显示单元被显示。例如,各种类型的用户接口和信息可以在各种类型的用户接口和信息被投射于其上的墙壁表面上进行显示和交互。与本发明的方面可以利用其进行实施的许多计算系统的交互包括键击输入、触摸屏输入、语音或其它音频输入、手势输入,其中相关联的计算设备配备有用于捕捉和解释用于控制计算设备的功能的用户手势的检测(如相机)功能,等等。
图7至9以及相关联的描述提供了其中可实施本发明的方面的各种操作环境的讨论。然而,所图示和讨论的设备和系统是用于示例和说明的目的,而非对可被用于实施本文所述的本发明的各方面的大量计算设备配置的限制。
图7是示出适合于实施本发明的方面的计算设备的物理组件的框图。计算设备700的组件可以适合于实现计算设备,该计算设备包括但并不限于个人计算机、平板计算机、平面计算机和智能电话、或者这里所引用的任意其它计算设备。在基本配置中,计算设备700可以包括至少一个处理单元702和系统存储器704。取决于计算设备的配置和类型,系统存储器704可以包括但并不限于易失性存储设备(例如,随机存取存储器)、非易失性存储设备(例如,只读存储器)、闪存、或者这些存储器的任何组合。系统存储器704可以包括操作系统705和适合于运行软件应用720的一个或多个程序模块706,上述软件应用720诸如自动话音识别模块114、口语语言理解模块116和对话状态打分器/排名器模块122。操作系统705例如可适合于控制计算设备700的操作。此外,本发明的方面可结合图形库、其它操作系统或任何其它应用程序来实施,而并不限于任何特定应用或系统。该基本配置在图7中由虚线708内的那些组件示出。计算设备700可以具有附加特征或功能。例如,计算设备700还可以包括诸如例如磁盘、光盘或磁带之类的附加数据存储设备(可移动的和/或不可移动的)。这样的附加存储设备在图7中由可移动存储设备709和不可移动存储设备710所示出。
如上所述,在系统存储器704中可以存储多个程序模块和数据文件。在处理单元702上执行的同时,软件应用720可以执行包括但不限于对话状态追踪方法600的一个或多个阶段的处理。可以依据本发明的方面所使用的其它程序模块可以包括各应用电子邮件和联系人应用、词语处理应用、电子表格应用、数据库应用、幻灯片演示应用或计算机辅助绘图应用程序等。
此外,本发明的方面可在包括分立电子部件的电子电路、包含逻辑门的封装或集成电子芯片、利用微处理器的电路中进行实施,或者在包含电子部件或微处理器的单个芯片上进行实施。例如,可以通过片上系统(SOC)来实施本发明的各方面,其中所图示的每个或许多组件可以被集成到单个集成电路上。这样的SOC设备可以包括一个或多个处理单元、图形单元、通信单元、系统虚拟化单元以及各种应用功能,所有这些都作为单个集成电路被集成到(或“烧录到”)芯片基板上。当通过SOC操作时,在此所述的关于软件应用720的功能可以通过在单个集成电路(芯片)上集成有计算设备700的其它组件的专用逻辑来操作。本发明的方面还可使用能够执行诸如例如,AND(与)、OR(或)和NOT(非)的逻辑运算的其它技术来实施,包括但不限于机械、光学、流体和量子技术。另外,本发明的方面可在通用计算机或任何其它电路或系统中实施。
计算设备700还可以具有一个或多个输入设备712,诸如键盘、鼠标、笔、声音输入设备、触摸输入设备等。还可以包括输出设备714,诸如显示器、扬声器、打印机等。上述设备是作为示例并且可以使用其它设备。计算设备700可以包括允许与其它计算设备718进行通信的一个或多个通信连接716。适当通信连接716的示例包括但并不限于RF发送器、接收器和/或收发器电路;通用串行总线(USB)、并行和/或串行端口。
这里所使用的术语计算机可读介质可以包括计算机存储介质。计算机存储介质可以包括以任何方法或技术实现的用于存储诸如计算机可读指令、数据结构或程序模块等信息的易失性和非易失性、可移动和不可移动介质。系统存储器704、可移动存储设备709和不可移动存储设备710都是计算机存储介质(即,存储器存储设备)的示例。计算机存储介质可以包括RAM、ROM、电可擦除只读存储器(EEPROM)、闪存或其它存储器技术、CD-ROM、数字多功能盘(DVD)或其它光存储设备、磁带盒、磁带、磁盘存储设备或其它磁性存储设备,或者可用于存储信息且可以由计算设备700访问的任何其它制品。任何这样的计算机存储介质都可以是计算设备700的一部分。
图8A图示了适合于实施本发明各方面的移动计算设备800。适合的移动计算设备的示例包括,但不限于,移动电话、智能电话、平板计算机、平面计算机以及膝上型计算机。在基本配置中,移动计算设备800是具有输入部件和输出部件两者的手持式计算机。移动计算设备800通常包括显示器805以及允许用户将信息输入到移动计算设备800中的一个或多个输入按钮810。移动计算设备800的显示器805也可充当输入设备(例如,触摸屏显示器)。如果被包括,则可选的侧边输入部件815允许另外的用户输入。侧边输入部件815可以是旋转开关、按钮或任意其它类型的手动输入部件。移动计算设备800可包含更多或更少的输入部件。例如,显示器805可以不是触摸屏。移动计算设备800还可以包括可选的小键盘835。可选的小键盘835可以是物理小键盘或者在触摸屏显示器上生成的“软”小键盘。输出部件可以包括用于显示图形用户接口(GUI)的显示器805、可视指示器820(如发光二极管)和/或音频变换器825(如扬声器)。移动计算设备800可以包含振动变换器来向用户提供触觉反馈。移动计算设备800可以包含诸如音频输入(如麦克风插孔)、音频输出(如耳机插孔)、以及视频输出(如HDMI端口)之类的输入和/或输出端口,用于将信号发送到外部设备或从外部设备接收信号。
图8B是示出适合于实施本发明的方面的移动计算设备的架构的框图。即,移动计算设备800可包含系统(即架构)802以实现本发明的某些方面。系统802可以被实现为能够运行一个或多个应用(如浏览器、电子邮件客户端、记事本、联系人管理器、消息收发客户端、游戏、以及媒体客户端/播放器)的智能电话。系统802可以被集成为计算设备,诸如集成的个人数字助理(PDA)和无线电话。
一个或多个应用程序865可被加载到存储器862中并在操作系统864上或与操作系统864相关联地运行。应用程序的示例包括电话拨号程序、电子邮件程序、个人信息管理(PIM)程序、词语处理程序、电子表格程序、因特网浏览器程序、消息收发应用等等。系统802还包括存储器862内的非易失性存储区868。非易失性存储区868可被用于存储在系统802断电的情况下不会丢失的持久信息。应用程序可使用信息并将信息存储在非易失性存储区868中,如电子邮件应用使用的电子邮件或其它消息等。同步应用(未示出)也驻留于系统802上且被编程为与驻留在主机计算机上的对应的同步应用交互,以保持非易失性存储区868中存储的信息与主机计算机处存储的相应信息同步。应当理解的,其它应用也可被加载到存储器862并在移动计算设备800上运行,包括本文所述的软件应用720。
系统802具有可被实现为一个或多个电池的电源780。电源780还可以包括外部功率源,诸如对电池进行补充或对电池充电的AC适配器或加电对接托架。
系统802还可以包括执行发送和接收射频通信的功能的无线电装置872。无线电装置872经由通信运营商或服务供应商而促成了系统802与外部世界之间的无线连接。来往无线电装置872的传输是在操作系统864的控制下进行的。换言之,无线电装置872接收的通信可通过操作系统864传播到应用程序120,反之亦然。
可以使用视觉指示符820来提供视觉通知和/或可以使用音频接口874来通过音频变换器825产生可听通知。例如,可视指示符820是发光二极管(LED),而音频变换器825是扬声器。这些设备可直接耦合到电源870,使得当被激活时,即使为了节省电池功率而可能关闭处理器860和其它组件,它们也保留一段由通知机制规定的时间。LED可被编程为无限地保持,直到用户采取动作指示该设备的通电状态。音频接口874用于向用户提供可听信号并从用户接收可听信号。例如,除了被耦合到音频变换器825之外,音频接口874还可被耦合到麦克风来接收可听输入,例如促成电话谈话。根据各本发明的各方面,麦克风也可充当音频传感器以促成对通知的控制,如下文将描述的。系统802可进一步包括支持板上相机830的操作的视频接口876,以记录静止图像、视频流等。
实施系统802的移动计算设备800可以具有附加特征或功能。例如,移动计算设备800还可以包括附加数据存储设备(可移动的和/或不可移动的),例如磁盘、光盘或磁带。这种附加存储设备用非易失性存储区868所图示。
由移动计算设备800生成或捕捉的且经系统802存储的数据/信息可以如上所述被本地存储在移动计算设备800上,或者数据可被存储在可由设备经由无线电装置872或经由移动计算设备800和关联于移动计算设备800的单独的计算设备之间的有线连接进行访问的任何数目的存储介质上,该单独的计算设备例如为诸如互联网之类的分布式计算网络中的服务器计算机。如所应当理解的,此类数据/信息可经移动计算设备800、经无线电装置872或经分布式计算网络进行访问。类似地,这些数据/信息可以根据已知的数据/信息传送和存储手段来容易地在计算设备之间进行传送以便存储和使用,这些手段包括电子邮件和协作数据/信息共享系统。
图9是本发明的多个方面可以在其中进行实施的分布式计算系统的简化框图。关联于软件应用720所开发、与之交互或编辑的内容可以存储在不同通信信道或其它存储类型中。例如,各个文档可以使用目录服务922、web门户924、邮箱服务926、即时消息收发存储928或社交网络站点930进行存储。软件应用920可以使用任何这些类型的系统等以便实现如这里所描述的数据利用。服务器920可以将软件应用720提供至客户端。作为一个示例,服务器920可以是通过web提供软件应用720的web服务器。服务器920可以通过网络915将软件应用720通过web提供至客户端。作为示例,客户端计算设备可以被实施为计算设备700并且嵌入在个人计算机918a、平板计算机918b和/或移动计算设备(例如,智能电话)918c中。客户端设备124的任何这些实现方式都可以从存储916获得内容。
描述和说明旨在为本领域技术人员提供对于主题的整个范围的彻底和完整的公开,而并非旨在以任何方式限制或约束所要求保护的发明的范围。本申请中提供的方面、实施例、示例和细节被认为是足以传达所有权并且使得本领域技术人员能够实施所要求保护的发明的最佳模式。被视为对本领域技术人员而言已知的结合、资源、操作和动作的描述可能简化或者省略,以避免模糊本申请的主题的少为人知的或者唯一的方面。所要求保护的发明不应被解释为限于本申请中所提供的任何方面、实施例、示例或细节,除非在此明确阐述。无论是总体还是单独地示出和描述,各种特征(结构上的和方法逻辑上的)都旨在被选择性地包括或省略从而产生具有特定的特征集的实施例。另外,所示出或描述的任意或全部功能和动作可以以任意顺序执行或者同时执行。在被提供以本申请的描述和说明的情况下,本领域的技术人员能够想到落在本申请中体现的一般发明构思的较宽泛方面的精神以内而并不背离所要求保护的发明的较宽泛范围的变型、修改和备选。
- 还没有人留言评论。精彩留言会获得点赞!