本发明属于语音信号处理领域,尤其涉及一种自适应的快速声纹识别方法及系统。
背景技术:
家用服务机器人是当今前沿高技术研究最活跃的领域之一,它可以完成有益于人类的服务工作,如提供家务、娱乐休闲、教育、安全监控等服务,拥有广泛的潜在客户群体与市场,现有的家用服务机器人广泛采用语音识别技术实现人机交互,让机器人能够听懂人类语音,以执行相应动作,然而,现有的机器人尚无法准确识别说话人身份,无法满足用户个性化的需求。随着计算机技术和数字信号处理理论的发展出现的声纹识别技术,通过从说话人的一段语音中,提取出反映该说话人生理、心理的语音特征参数,通过对语音特征参数进行分析建模与模式匹配,来实现辨认或确认未知说话人身份的目的。然而,现有的声纹识别系统往往是针对一特定的应用场景进行设计,当系统的应用场景发生改变时,自适应能力不强,无法实现人机自由交流,且由于声纹识别的速度过慢,造成用户体验差,这是本领域技术人员所不期望看到的。
技术实现要素:
为解决以上技术问题,提供一种自适应的快速声纹识别方法及系统,解决现有识别方法的缺陷。
具体技术方案如下:
一种自适应的快速声纹识别方法,其中,应用于家用机器人,具体工作步骤包括:
s1:采集语音信号;
s2:对所述语音信号进行预处理;
s3:自所述预处理后的语音信号中提取语音特征参数,所述语音特征参数包括线性预测得到的第一类特征参数及模拟人耳对声音频率的感知特性而提取的第二类特征参数;
s4:为每一个家庭成员建立一个码本存储在语音数据库中作为所述家庭成员的语音模板,所述家庭成员的所有码本构成一声学模型;
s5:预先根据使用频率将所述声学模型区分为第一声学模型和第二声学模型,所述第一声学模型的使用频率大于所述第二声学模型,并在通电时将所述第一声学模型加载至缓存中;其中,根据预定时间内的使用频率统计,实时对所述第一声学模型和第二声学模型进行更新;
s6:依据所述第一声学模型和第二声学模型对待测语音信号进行模式匹配,获取识别结果。
上述的自适应的快速声纹识别方法,所述步骤s2中,所述预处理的步骤依次包括:
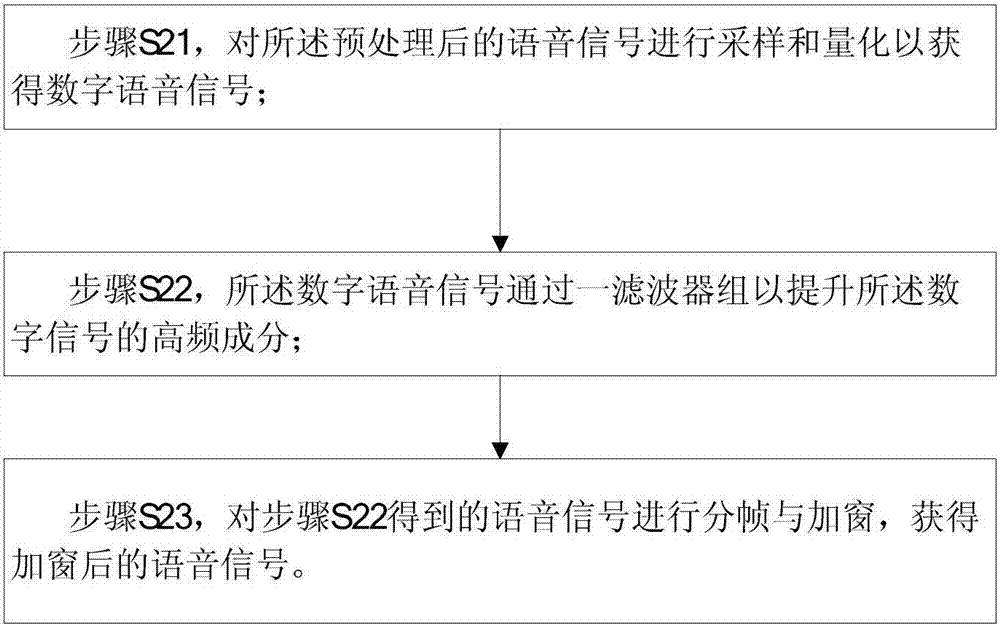
步骤s21,对所述预处理后的语音信号进行采样和量化以获得数字语音信号;
步骤s22,所述数字语音信号通过一滤波器组以提升所述数字信号的高频成分;
步骤s23,对步骤s22得到的语音信号进行分帧与加窗,获得加窗后的语音信号。
上述的自适应的快速声纹识别方法,所述步骤s3中提取所述第一类特征参数为线性预测系数,提取步骤如下:
步骤s31a,定义短时语音信号和误差信号;
步骤s32a,计算所述短时语音信号和所述误差信号的误差平方和;
步骤s33a,对所述误差平方和求导数,并求解方程组获得所述第一类特征参数。
上述的自适应的快速声纹识别方法,所述步骤s3中提取所述第二类特征参数的步骤包括:
步骤s31b,对所述预处理后的语音信号进行傅里叶变换得到线性频谱;
步骤s32b,对所述线性频谱通过一三角形带通滤波器组得到相应的梅尔频谱;
步骤s33b,计算所述梅尔频谱的对数频谱;
步骤s34b,对所述对数频谱进行离散余弦变换得到第二类特征参数。
上述的自适应的快速声纹识别方法,所述步骤s4的具体步骤如下:
步骤s41,自所述语音信号中提取n个特征矢量,通过聚类法对所述特征矢量进行归类得到m个码本;
步骤s42,得到每个类对应的码本矢量;
步骤s43,建立每一个家庭成员的码本矢量的集合构成声学模型。
上述的自适应的快速声纹识别方法,所述步骤s6具体如下,
步骤s61,将待识别的语音信号依次与所述第一声学模型和第二声学模型作相似性匹配,并根据加权欧式距离测度进行判断;
步骤s62,选取适当的距离度量作为门限值;
步骤s63,满足门限值范围内的结果作为识别结果。
还提供,一种自适应的快速声纹识别系统,包括
语音输入模块,用于捕获语音信号;
预处理模块,与所述语音输入模块连接,用于对所述语音信号进行预处理;
第一特征参数提取模块,与所述预处理模块连接,用于获取所述语音信号中的第一特征参数;
第二特征参数提取模块,与所述预处理模块连接,用于获取所述语音信号中的第二特征参数;
训练模块,与所述第一特征参数提取模块和所述第二特征参数提取模块连接,用于建立每个家庭成员的语音模板,所述家庭成员的所有码本构成一声学模型;
分类处理模块,与所述训练模块连接,预先根据使用频率将所述声学模型区分为第一声学模型和第二声学模型,其中,所述第一声学模型的使用频率大于所述第二声学模型,并在通电时将所述第一声学模型加载至缓存中;
更新模块,与所述分类处理模块连接,根据预定时间内的使用频率统计,实时对所述第一声学模型和第二声学模型进行更新;
模板匹配模块,与所述分类处理模块连接,依据所述第一声学模型和第二声学模型对待测语音信号进行模式匹配,获取识别结果。
有益效果:以上技术方案可以自适应地实现声纹识别,并有效提高了声纹识别的速度,应对不同应用场景下的人机交流,有利于提升用户体验。
附图说明
图1为本发明的方法流程图;
图2为本发明的步骤2的方法流程图;
图3为本发明的系统结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
参照图1,一种自适应的快速声纹识别方法,其中,应用于家用机器人,具体工作步骤包括:
s1:采集语音信号;
s2:对语音信号进行预处理;
s3:自预处理后的语音信号中提取语音特征参数,语音特征参数包括线性预测得到的第一类特征参数及模拟人耳对声音频率的感知特性而提取的第二类特征参数;
s4:为每一个家庭成员建立一个码本存储在语音数据库中作为家庭成员的语音模板,家庭成员的所有码本构成一声学模型;
s5:预先根据使用频率将声学模型区分为第一声学模型(常用)和第二声学模型(不常用),第一声学模型的使用频率大于第二声学模型,并在通电时将第一声学模型加载至缓存中,将第二声学模型仍然存储在语音数据库中;其中,根据预定时间内的使用频率统计,实时对第一声学模型和第二声学模型进行更新;
s6:依据第一声学模型和第二声学模型对待测语音信号进行模式匹配,获取识别结果。
每个人由于发音器官的生理差异会导致发音方式和说话习惯各不相同,本发明结合线性预测得到的第一类特征参数及模拟人耳对声音频率的感知特性而提取的第二类特征参数,获得声学模型,以改善现有的声纹识别效果,提升用户体验。
上述的自适应的快速声纹识别方法,参照图2,步骤s2中,预处理的步骤依次包括:
步骤s21,对预处理后的语音信号进行采样和量化以获得数字语音信号;
步骤s22,数字语音信号通过一滤波器组以提升数字信号的高频成分;
步骤s23,对步骤s22得到的语音信号进行分帧与加窗,获得加窗后的语音信号。
上述的自适应的快速声纹识别方法,步骤s3中提取第一类特征参数可以为线性预测系数,其提取步骤如下:
步骤s31a,定义短时语音信号和误差信号;
步骤s32a,计算短时语音信号和误差信号的误差平方和;
步骤s33a,对误差平方和求导数,并求解方程组获得第一类特征参数。
由于语音相邻样点间具有相关性,可以利用线性预测的方式,根据过去的语音样点值来预测现在或未来的样点值,即利用过去若干个语音抽样或它们的线性组合,来逼近语音现在的抽样值。
上述的自适应的快速声纹识别方法,步骤s3中提取第二类特征参数的步骤,包括:
步骤s31b,对预处理后的语音信号进行傅里叶变换得到线性频谱;
步骤s32b,对线性频谱通过一三角形带通滤波器组得到相应的梅尔频谱;
步骤s33b,计算梅尔频谱的对数频谱;
步骤s34b,对对数频谱进行离散余弦变换得到第二类特征参数。
上述的自适应的快速声纹识别方法,步骤s4的具体步骤如下:
步骤s41,自第一类特征参数和第二类特征参数中提取n个特征矢量,通过聚类法对特征矢量进行归类得到m个码本;
步骤s42,得到每个类对应的码本矢量;
步骤s43,建立每一个家庭成员的码本矢量的集合构成声学模型。
上述的自适应的快速声纹识别方法,步骤s6具体如下,
步骤s61,将待识别的语音信号依次与第一声学模型和第二声学模型作相似性匹配,并根据加权欧式距离测度进行判断;
步骤s62,选取适当的距离度量作为门限值;
步骤s63,满足门限值范围内的结果作为识别结果。
还提供,一种自适应的快速声纹识别系统,参照图3,包括
语音输入模块1,用于捕获语音信号;
预处理模块2,与语音输入模块1连接,用于对语音信号进行预处理;
第一特征参数提取模块3,与预处理模块2连接,用于获取语音信号中的第一特征参数;
第二特征参数提取模块4,与预处理模块2连接,用于获取语音信号中的第二特征参数;
训练模块5,与第一特征参数提取模块和第二特征参数提取模块连接,用于建立每个家庭成员的语音模板,家庭成员的所有码本构成一声学模型;
分类处理模块6,与训练模块5连接,预先根据使用频率将声学模型区分为第一声学模型和第二声学模型,其中,第一声学模型的使用频率大于第二声学模型,并在通电时将第一声学模型加载至缓存中,将第二声学模型仍然存储在语音数据库中;
更新模块7,与分类处理模块连接,根据预定时间内的使用频率统计,实时对第一声学模型和第二声学模型进行更新;
模板匹配模块8,与分类处理模块6连接,依次依据第一声学模型和第二声学模型对待测语音信号进行模式匹配,获取识别结果。
以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。