一种语音会话样本的身份识别方法、装置及设备与流程
本发明涉及数据处理技术领域,尤其涉及一种语音会话样本的身份识别方法、装置及设备。
背景技术:
公司的发展往往是靠业务拉动的,销售和客服积累了公司的众多业务信息,销售/客服和客户的沟通电话,汇集了众多的动态业务信息,对于公司来说,如果能从这些录音中挖掘有用的商业线索数据,对于公司把握市场,洞察先机,能够赢得客户,至关重要。
然而,目前销售、客服与客户的会话内容融合在一起,无法对语音会话内容进行身份识别。
技术实现要素:
有鉴于此,本发明实施例提供一种语音会话样本的身份识别方法、装置及设备,以对语音会话样本中会话语句所属用户进行身份识别。
第一方面,本发明实施例提供了一种语音会话样本的身份识别方法,包括:
识别语音会话样本的声学特征,并依据识别结果,确定所述语音会话样本中包含的会话语句;
依据所述语音会话样本中包含的会话语句的声学特征,对不同用户的会话语句进行聚类;
将每一用户的会话语句翻译成会话文本,并基于预先训练得到的身份分类器,确定所述每一用户的身份信息。
第二方面,本发明实施例提供了一种语音会话样本的身份识别装置,包括:
语句确定模块,用于识别语音会话样本的声学特征,并依据识别结果,确定所述语音会话样本中包含的会话语句;
语句聚类模块,用于依据所述语音会话样本中包含的会话语句的声学特征,对不同用户的会话语句进行聚类;
身份信息确定模块,用于将每一用户的会话语句翻译成会话文本,并基于预先训练得到的身份分类器,确定所述每一用户的身份信息。
第三方面,本发明实施例提供了一种设备,包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序,
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明实施例所述的方法。
本发明实施例提供的技术方案,通过对语音会话样本进行声学特征识别,确定语音会话样本中包含的会话语句,并依据会话语句的声学特征对不同用户的会话语句进行聚类,随后,将每一用户的会话语句翻译成会话文本并基于身份分类器确定每一用户的身份信息,即实现了对语音会话样本中不同会话语句所属用户的身份识别,为后续为不同身份用户提供个性化服务奠定了基础。
附图说明
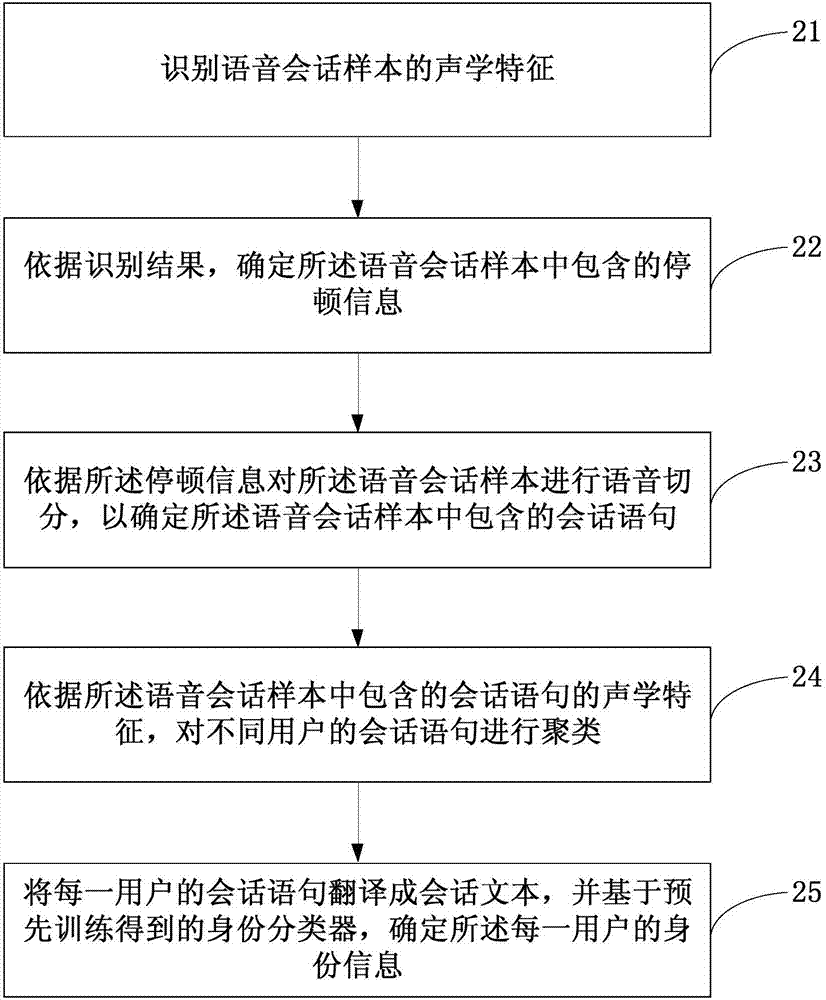
图1是本发明实施例一提供的一种语音会话样本的身份识别方法的流程图;
图2是本发明实施例二提供的一种语音会话样本的身份识别方法的流程图;
图3是本发明实施例二提供的一种语音会话样本的身份识别方法的示意图;
图4是本发明实施例三提供的一种语音会话样本的身份识别装置的结构图;
图5是本发明实施例四中的一种电子设备的结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1是本发明实施例一提供的一种语音会话样本的身份识别方法的流程图。本实施例的方法可以由语音会话样本的身份识别装置来执行,该装置可通过硬件和/或软件的方式实现。本实施例的方法一般可适用于对语音会话样本所属用户进行身份识别的情形。参考图1,本实施例提供的语音会话样本的身份识别方法具体可以包括如下:
s11、识别语音会话样本的声学特征,并依据识别结果,确定所述语音会话样本中包含的会话语句。
在本实施例中,语音会话样本指的是不同身份用户之间的语音会话内容,且不同身份用户的语音会话内容混杂在一起,用户身份信息可以包括客户、销售和客服等。例如,语音会话样本可以是企业呼叫中心收集的客户与销售或客服的电话沟通内容。
可选的,声学特征可以包括时长、基频、能量、共振峰频率、宽带、频率微扰、振幅微扰、过零率和梅尔频率倒谱参数中的至少一种。其中,时长、基频和能量属于语音的韵律特征,共振峰频率、宽带、频率微扰和振幅微扰属于语音的声音质量特征。
具体的,对语音会话样本进行声学特征提取,依据语音会话样本的声学特征对语音会话样本进行语音切分,得到语音会话样本中包含的会话语句。
s12、依据所述语音会话样本中包含的会话语句的声学特征,对不同用户的会话语句进行聚类。
由于不同用户的语音的声学特征不同,因而依据语音会话样本中包含的会话语句的时长、基频和能量等韵律特征,共振峰频率、宽带、频率微扰和振幅微扰等声音质量特征,梅尔倒谱参数等结合支持向量机(supportvectormachine,svm)对不同用户的会话语句进行聚类,得到不同用户的所有会话语句。例如,一段语音会话样本中包含100个会话语句,经过基于声学特征的语句聚类,得到100个会话语句中有60个会话语句属于第一用户,另外40个会话语句属于第二用户。
s13、将每一用户的会话语句翻译成会话文本,并基于预先训练得到的身份分类器,确定所述每一用户的身份信息。
在本实施例中,身份分类器是依据不同预设身份用户的会话文本训练得到的,用于区分会话文本所属用户的身份信息。
具体的,依据聚类结果得到每一用户的会话语句,并可以采用光学字符识别(opticalcharacterrecognition,ocr)技术将每一用户的会话语句处理成会话文本,并基于身份分类器确定会话文本所属用户的身份信息,即确定每一用户的身份信息。
本实施例提供的技术方案,通过对语音会话样本进行声学特征识别,确定语音会话样本中包含的会话语句,并依据会话语句的声学特征对不同用户的会话语句进行聚类,随后,将每一用户的会话语句翻译成会话文本并基于身份分类器确定每一用户的身份信息,即实现了对语音会话样本中不同会话语句所属用户的身份识别,为后续为不同身份用户提供个性化服务奠定了基础。
示例性的,确定所述每一用户的身份信息之后,可以包括:
获取任一身份用户的所有语音内容;
依据获取的语音内容,为所述任一身份用户提供服务。
具体的,可以分析同一客户类用户的全国通话,得到客户的需求,了解客户的疑虑等;也可以通过分析同一销售类用户的通话,得到销售类用户的话术,或者识别销售类用户是否存在非法词等。例如,通过对同一客户的全部通话进行分析,可以洞察这个客户的谈单流程,每个阶段的问题,便于销售确定后续应该从哪些方向进行突破,提高成单机会。
实施例二
本实施例在上述实施例一的基础上提供了一种新的语音会话样本的身份识别方法。图2是本发明实施例二提供的一种语音会话样本的身份识别方法的流程图。参考图2,本实施例提供的语音会话样本的身份识别方法具体可以包括如下:
s21、识别语音会话样本的声学特征。
其中,语音会话样本指的是不同身份用户的语音会话内容,且不同身份用户的语音会话内容混杂在一起。可选的,声学特征可以包括时长、基频、能量、共振峰频率、宽带、频率微扰、振幅微扰、过零率和梅尔频率倒谱参数中的至少一种。
s22、依据识别结果,确定所述语音会话样本中包含的停顿信息。
其中,停顿信息指的是语音会话样本中的短暂停歇,停顿信息可以包含停顿起点信息和停顿终点信息。例如,可以将时长在预设范围内的静音确定为短暂停歇。
具体的,可以依据语音会话样本的能量和过零率对语音会话样本进行静音识别,依据静音识别结果确定语音会话样本中包含的停顿信息。
s23、依据所述停顿信息对所述语音会话样本进行语音切分,以确定所述语音会话样本中包含的会话语句。
s24、依据所述语音会话样本中包含的会话语句的声学特征,对不同用户的会话语句进行聚类。
依据语音会话样本中包含的会话语句的时长、基频和能量等韵律特征,共振峰频率、宽带、频率微扰和振幅微扰等声音质量特征,梅尔倒谱参数等结合支持向量机(supportvectormachine,svm)对不同用户的会话语句进行聚类,得到不同用户的所有会话语句。
s25、将每一用户的会话语句翻译成会话文本,并基于预先训练得到的身份分类器,确定所述每一用户的身份信息。
示例性的,所述身份分类器通过如下方式得到:依据不同身份用户的会话文本中包含的关键字以及关键字频次,训练得到所述身份分类器。具体的,获取不同身份用户的大量会话文本,对不同身份用户的会话文本进行切词,确定不同身份用户的会话文本中包含的关键字以及关键词频次,并且依据不同身份用户对应的关键字以及关键字频次进行分类训练得到身份分类器。
例如,获取10000句销售类用户的会话文本以及10000句客户类用户的会话文本,经处理确定销售类会话文本中包含“我是某某公司销售”、“您有什么需要”、“有什么可以帮您”和“能耽误您几分钟吗”等关键字,并统计不同关键字的出现频次;相应的,客户类会话文本中包含“推荐几款产品”、“有什么优惠”、“保修吗”和“包退货吗”等关键字,并统计不同关键字的出行频次。随后,依据销售类会话文本中包含关键字以及关键字频次以及客户类会话文本中包含关键字以及关键字频次进行分类训练得到身份分类器。
综上,参考图3,该方法依据客户类用户与销售类用户之间的电话沟通内容,确定语音会话样本,在语音分离阶段:对语音会话样本进行声学特征提取,依据提取结果对语音会话样本进行静音识别,并依据静音识别结果对语音会话样本进行语音切分,得到语音会话样本中包含的会话语句;在身份识别阶段:将语音会话样本中包含的会话语句翻译成会话文本,并通过身份分类器确定会话文本所属用户的身份信息。在身份识别之后的语音分析阶段:可以依据销售类用户的语音内容分析销售所处的阶段,为销售类用户提供销售话术,以及识别销售类用户的语音内容中是否包含异常内容;也可以依据客户类用户的语音内容对客户信息进行分析,以了解客户的行业、情绪和意愿等,进行为下一通电话的策略打下基础。
本实施例提供的技术方案,通过识别语音会话样本的声学特征,依据识别结果,确定语音会话样本中包含的停顿信息,并依据停顿信息对语音会话样本进行语音切分,得到语音会话样本中包含的会话语句。随后,依据会话语句的声学特征对不同用户的会话语句进行聚类,将每一用户的会话语句翻译成会话文本并基于身份分类器确定每一用户的身份信息,即实现了对语音会话样本中不同会话语句所属用户的身份识别,为后续为不同身份用户提供个性化服务奠定了基础。并且,本实施例中还具体提供了身份分类器的训练方法。
实施例三
图4是本发明实施例三提供的一种语音会话样本的身份识别装置的结构图。该装置一般可适用于对语音会话样本所属用户进行身份识别的情形。参见图4,本实施例提供的语音会话样本的身份识别装置的具体结构如下:
语句确定模块31,用于识别语音会话样本的声学特征,并依据识别结果,确定所述语音会话样本中包含的会话语句;
语句聚类模块32,用于依据所述语音会话样本中包含的会话语句的声学特征,对不同用户的会话语句进行聚类;
身份信息确定模块33,用于将每一用户的会话语句翻译成会话文本,并基于预先训练得到的身份分类器,确定所述每一用户的身份信息。
示例性的,上述装置可以包括:
分类器训练模块,用于依据不同身份用户的会话文本中包含的关键字以及关键字频次,训练得到所述身份分类器。
示例性的,所述语句确定模块31可以包括:
声学特征识别单元,用于识别所述语音会话样本的声学特征;
停顿信息确定单元,用于依据识别结果,确定所述语音会话样本中包含的停顿信息;
语音切分单元,用于依据所述停顿信息对所述语音会话样本进行语音切分,以确定所述语音会话样本中包含的会话语句。
示例性的,所述声学特征可以包括时长、基频、能量、共振峰频率、宽带、频率微扰、振幅微扰、过零率和梅尔频率倒谱参数中的至少一种。
示例性的,上述装置可以包括服务提供模块,具体用于:
在确定所述每一用户的身份信息之后,获取任一身份用户的所有语音内容;
依据获取的语音内容,为所述任一身份用户提供服务。
本实施例提供的语音会话样本的身份识别装置,与本发明任意实施例所提供的语音会话样本的身份识别方法属于同一发明构思,可执行本发明任意实施例所提供的语音会话样本的身份识别方法,具备执行语音会话样本的身份识别方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明任意实施例提供的语音会话样本的身份识别方法。
实施例四
如图5所示,为本发明实施例四提供的设备的硬件结构示意图,如图5所示,该设备包括:
一个或多个处理器410,图5中以一个处理器410为例;
存储器420;
所述电子设备还可以包括:输入装置430和输出装置440。
所述电子设备中的处理器410、存储器420、输入装置430和输出装置440可以通过总线或者其他方式连接,图5中以通过总线连接为例。
存储器420作为一种非暂态计算机可读存储介质,可用于存储软件程序、计算机可执行程序以及模块,如本申请实施例中的数据存储方法对应的程序指令/模块(例如,附图4所示的语句确定模块31、语句聚类模块32和身份信息确定模块33)。处理器410通过运行存储在存储器420中的软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例的语音会话样本的身份识别方法。
存储器420可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据电子设备的使用所创建的数据等。此外,存储器420可以包括高速随机存取存储器,还可以包括非暂态性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态性固态存储器件。在一些实施例中,存储器420可选包括相对于处理器410远程设置的存储器,这些远程存储器可以通过网络连接至终端设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
输入装置430可用于接收输入的数字或字符信息,以及产生与电子设备的用户设置以及功能控制有关的键信号输入。输出装置440可包括显示屏等显示设备。
也即:上述电子设备包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序,
当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现时,进行如下操作:
识别语音会话样本的声学特征,并依据识别结果,确定所述语音会话样本中包含的会话语句;
依据所述语音会话样本中包含的会话语句的声学特征,对不同用户的会话语句进行聚类;
将每一用户的会话语句翻译成会话文本,并基于预先训练得到的身份分类器,确定所述每一用户的身份信息。
进一步的,所述身份分类器通过如下方式得到:
依据不同身份用户的会话文本中包含的关键字以及关键字频次,训练得到所述身份分类器。
进一步的,识别语音会话样本的声学特征,并依据识别结果,确定所述语音会话样本中包含的会话语句,包括:
识别所述语音会话样本的声学特征;
依据识别结果,确定所述语音会话样本中包含的停顿信息;
依据所述停顿信息对所述语音会话样本进行语音切分,以确定所述语音会话样本中包含的会话语句。
进一步的,所述声学特征包括时长、基频、能量、共振峰频率、宽带、频率微扰、振幅微扰、过零率和梅尔频率倒谱参数中的至少一种。
进一步的,确定所述每一用户的身份信息之后,包括:
获取任一身份用户的所有语音内容;
依据获取的语音内容,为所述任一身份用户提供服务。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!