混音器及混音方法与流程
本发明涉及一种混音技术,具体为一种混音器及混音方法。
背景技术:
电视会议和电话会议是通过通信网络召开的会议形式,它们均能在异地空间为参加会议者提供实时语音交流。为获得接近真实的会议交流氛围,混音技术不可或缺,并且混音技术会直接影响到会议的语音质量。混音技术具体分为模拟混音技术和数字混音技术,其中,数字混音技术由于具有精度高、动态范围大和噪声低等优势而得到广泛应用。数字混音技术的基本原理是将各路语音信号经过模数转换之后的数字信号相互叠加而形成一路混音输出信号。
由于数字语音信号存在量化上限和下限的问题,叠加运算可能会造成结果溢出,所以数字混音技术的需求表现在以下两个方面:①保证混音之后的信号不会频繁溢出;随着语音路数的增加,溢出现象会越来越频繁,如果对这些溢出信号直接进行饱和运算,则会引入噪声,使得混音后的声音听起来不连续或者出现爆破声。②保证各路语音质量;各路语音的大小、频率各不相同,良好保证这些信号在混音之后的质量是衡量数字混音技术的一项重要标准。
作者为张传永的现有文献《混音技术及其在IP电话会议系统中的应用》中公开了一种加权法混音技术,其主要思想是对每一路语音信号计算出一个加权值,之后对加权后的信号进行叠加;而加权的目的是减少或消除溢出,从而保证语音质量。该加权法混音技术的具体实现方式如下:假设有N路信号,每路信号一帧有M个样本,其中f(i,j)为第j路信号的第i个样本值,则其对应的权重值为:
最后输出为:
其中,weight(i,j)为第j路信号的第i个样本的权重,Output(i)为第i个样本输出。该现有文献公开的加权法混音技术存在如下问题:各路语音信号在混音时,信号幅度越小则其权重也会越小,这导致了小信号混音之后变得更小,易导致较大的失真;其次,一般视频会议同时发言的人不会超过4个,而此方式把没有说话的线路信号(含有噪声)未经过任何处理直接参加混音,易降低混音后的语音的信噪比。
作者为周敬利等的现有文献《一种新的多媒体会议实时混音方案》中公开了一种自动门限混音技术,其在混音之前对各路信号根据其短时能量来判断是否为语音信号(即静音检测),把没有语音的线路判断为“无发言状态”,这些“无发言状态”信号不会参加混音;混音时,此方式根据音频数据的自身短时能量大小来计算其衰减因子,当音频短时能量超过某一个门限值时以一定的比例进行衰减,而低于门限值则不需要进行衰减,进而各路信号的权重只与自己的短时能量相关。该现有文献公开的自动门限混音技术存在如下问题:由于被判断为“无发言状态”的信号不参加混音,所以混音之后的声音里丝毫没有“无发言状态”信号,使得这些“无发言状态”的与会者毫无存在感;同时,与会者从沉默到说话时会出现起伏,影响听觉;其次,此方式虽然保证了小信号的权重≥1,但仍然无法保证小信号的语音质量。
由上可见,现有的混音技术中,或各路信号(不管是否有语音)未经过任何处理而直接参加混音,或采用静音检测来减少参加混音的信号路数;如果不采用静音检测,混音过程中会加入不必要的噪声,从而影响语音质量。如果采用静音检测来减少混音路数,则“无发言状态”的与会者会变得毫无参与感;另外,现有的混音技术中,是以语音信号的幅度作为标准来确定各路信号的权重再进行叠加,但是语音的响度不完全等于其幅度,它取决于语音信号的幅度与频率。
技术实现要素:
本发明针对以上问题的提出,而研制一种能够提高语音质量,也体现出了对各与会者的公平性的混音器及混音方法。
本发明的技术手段如下:
一种混音器,包括:
分帧单元,用于对参与混音的各路信号分别进行分帧;
与所述分帧单元相连接的语音检测单元;所述语音检测单元用于对分帧后的各路信号是否均含有语音信号进行检测;所述语音检测单元通过检测一路信号中当前帧是否处于有语音信号状态,来确定该路信号是否含有语音信号;
与所述语音检测单元相连接的时变滤波器;所述时变滤波器用于根据所述语音检测单元的检测结果,对分帧后的各路信号分别进行时变低通滤波处理;当一路信号中当前帧处于有语音信号状态时,所述时变滤波器的通带宽度逐渐变宽,当一路信号中当前帧处于无语音信号状态时,所述时变滤波器的通带宽度逐渐变窄;
与所述语音检测单元相连接的响度计算单元;所述响度计算单元用于根据所述语音检测单元的检测结果,来分别计算分帧后的各路信号在当前预定时间段内的平均响度;
与响度计算单元相连接的权重计算单元;所述权重计算单元用于根据所述响度计算单元的计算结果,分别计算参与混音的各路信号中当前帧所包括的各样本权重;
与所述时变滤波器和所述权重计算单元相连接的混音单元;所述混音单元用于根据各路信号分别经过时变低通滤波处理后的当前帧输出信号,以及各路信号中当前帧所包括的各样本权重,获得并输出各路信号当前帧混音后的一路当前帧信号;
与所述混音单元相连接的后处理单元;所述后处理单元用于根据混音单元输出的一路当前帧信号,计算混音后信号当前帧所包括的各样本权重和各输出样本;
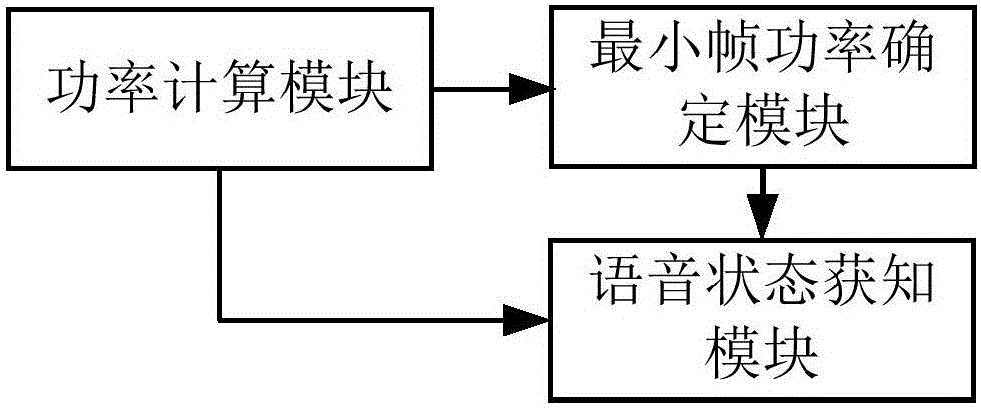
进一步地,所述语音检测单元包括:
功率计算模块,用于分别计算分帧后的各路信号中当前帧的功率;
与所述功率计算模块相连接的最小帧功率确定模块;所述最小帧功率确定模块用于根据所述功率计算模块的计算结果,来分别获得分帧后的各路信号在当前预定时间段内最小的帧功率;
与所述功率计算模块和所述最小帧功率确定模块相连接的语音状态获知模块;所述语音状态获知模块用于通过对一路信号中当前帧的功率与所述最小的帧功率之间的比较来检测一路信号中是否含有语音信号;
进一步地,
所述功率计算模块通过公式来计算一路信号中当前帧的功率,式中:pow表示当前帧的功率,x[i]表示当前帧第i个输入数据,N表示一帧中的样本数量;
所述当前预定时间段表示从当前帧的前r帧至当前帧的持续时间T;所述最小帧功率确定模块通过公式pow_min=min{当前帧功率,当前帧前1帧功率,···,当前帧前r帧功率}来获得一路信号在当前预定时间段内最小的帧功率,式中:min{}表示大括号中所有数据的最小值、ceil(x)表示接近x且大于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;
所述语音状态获知模块通过设定VAD来表示一路信号中是否含有语音信号,并对VAD赋初值使得VAD=1;当pow≥32·pow_min,且VAD=0时所述语音状态获知模块将VAD置1,表示该路信号处于有语音信号状态;当pow≤4·pow_min,且VAD=1时所述语音状态获知模块将VAD置0,表示该路信号处于无语音信号状态;在pow与pow_min之间的比较结果为其它情况时,所述语音状态获知模块将VAD保持不变;
进一步地,所述时变滤波器通过公式f[i]=(1-b)*x[i]+b*f[i-1]获得一路信号中当前帧的第i个滤波输出值,式中:f[i]表示一路信号中当前帧的第i个滤波输出值、x[i]表示当前帧第i个输入数据、N表示一帧中的样本数量、0≤i<N、b表示滤波系数,在当前帧处于有语音信号状态时,在当前帧处于无语音信号状态时,当b<0.18,取b=0.18,当b>0.956,取b=0.956,p1表示b从0.956变至0.18的时间长度内的采样点数,p2表示b从0.18变至0.956的时间长度内的采样点数;
进一步地,
所述响度计算单元包括:DFT变换模块、与DFT变换模块相连接的响度获得模块和与响度获得模块相连接的平均响度获得模块;
当一路信号中当前帧处于有语音信号状态时,通过所述DFT变换模块对该路信号中当前帧进行DFT变换,之后通过所述响度获得模块计算所述当前帧的响度值,最后通过所述平均响度获得模块计算该路信号当前预定时间段内的平均响度;
当一路信号中当前帧处于无语音信号状态时,该路信号当前预定时间段内的平均响度等于在当前帧之前的含有语音信号的上一预定时间段内的平均响度;
进一步地,
所述DFT变换模块通过公式对一路信号中当前帧进行DFT变换,式中,s表示离散频率、x[i]表示当前帧第i个输入数据、X[s]表示x[i]经过DFT变换后得到的结果、j表示虚数单位,j2=-1;
所述响度获得模块利用公式对所述当前帧的响度值进行计算,式中,loudness表示当前帧的响度值、X[s]表示x[i]经过DFT变换后得到的结果、Equal[s]表示具有预设数值的等响度数组、s20=ceil(20*N/Fs)、s20000=floor(20000*N/Fs)、ceil(x)表示接近x且大于等于x的整数、floor(x)表示接近x且小于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;
所述平均响度获得模块通过公式
来计算一路信号当前预定时间段内的平均响度;当前预定时间段表示从当前帧的前r帧至当前帧的持续时间T;式中:ceil(x)表示接近x且大于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;
进一步地,
所述权重计算单元通过公式得出第k路信号中当前帧权重,并通过公式weightk[i]=weightk 0≤i<N获得第k路信号中当前帧第i个样本的权重;式中:weightk表示第k路信号中当前帧权重,LOUDk表示第k路信号在当前预定时间段内的平均响度,M表示参与混音的信号路数,k=1、2、…、M,weightk[i]表示第k路信号中当前帧第i个样本的权重;
所述混音单元通过公式得出各路信号当前帧混音后的一路当前帧信号,式中:Mix[i]表示混音后的一路当前帧信号的第i个样本,M表示参与混音的信号路数,f_k[i]表示经过时变低通滤波处理后的第k路信号中当前帧第i个样本输出信号,weightk[i]表示第k路信号中当前帧所包括的第i个样本的权重,k=1、2、…、M;
所述后处理单元还用于获得混音后信号当前帧中的最大样本、以及计算混音后信号的当前帧权重;
进一步地,
所述权重计算单元还用于分别对参与混音的各路信号中的各帧权重进行平滑处理;
进一步地,
所述权重计算单元对一路信号中的各帧权重进行平滑处理的实现过程为:
当一路信号中当前帧为第一帧时,所述权重计算单元通过公式weightk[i]=weightk 0≤i<N获得第k路信号中当前帧第i个样本的权重;
当一路信号中当前帧不为第一帧时,所述权重计算单元通过公式
获得第k路信号中当前帧第i个样本的权重;其中,weightk[i]表示第k路信号中当前帧第i个样本的权重、N表示一帧中的样本数量、P表示weightk[i]从当前帧前1帧权重逐渐变至当前帧权重的采样点数;
所述后处理单元通过公式signalmax=max{|Mix[0]|,|Mix[1]|,···|Mix[N-1]|}获得混音后信号当前帧中的最大样本,式中:signalmax表示混音后信号当前帧所包括的最大样本、max{}表示大括号中数据的最大值、Mix[0]表示混音后信号当前帧第0样本的输出信号、Mix[1]表示混音后信号当前帧第1样本的输出信号、Mix[N-1]表示混音后信号当前帧第N-1样本的输出信号;
当signalmax≤32768时,所述后处理单元计算出混音后信号的当前帧权重weightmix=1,当signalmax>32768时,所述后处理单元计算出混音后信号的当前帧权重
当混音后信号的当前帧为第一帧时,所述后处理单元通过公式weightmix[i]=weightmix,0≤i<N获得混音后信号当前帧第i个样本的权重,当混音后信号的当前帧不为第一帧时,所述后处理单元通过公式获得混音后信号当前帧第i个样本的权重,式中:weightmix[i]表示混音后信号当前帧第i个样本的权重、Q表示weightmix[i]从混音后当前帧前1帧权重逐渐变至混音后当前帧权重的采样点数;
所述后处理单元通过公式得出混音后信号当前帧的第i个输出样本y[i],式中:final[i]=Mix[i]*weightmix[i]、0≤i<N。
一种混音方法,包括如下步骤:
步骤1:对参与混音的各路信号分别进行分帧;
步骤2:对分帧后的各路信号是否均含有语音信号进行检测;通过检测一路信号中当前帧是否处于有语音信号状态,来确定该路信号是否含有语音信号;
步骤3:根据语音信号检测结果,对分帧后的各路信号分别进行时变低通滤波处理:当一路信号中当前帧处于有语音信号状态时,通带宽度逐渐变宽,当一路信号中当前帧处于无语音信号状态时,通带宽度逐渐变窄;
步骤4:根据语音信号检测结果,来分别计算分帧后的各路信号在当前预定时间段内的平均响度;
步骤5:根据平均响度计算结果,分别计算参与混音的各路信号中当前帧所包括的各样本权重;
步骤6:根据各路信号分别经过时变低通滤波处理后的当前帧输出信号,以及各路信号中当前帧所包括的各样本权重,获得并输出各路信号当前帧混音后的一路当前帧信号;
步骤7:根据各路信号当前帧混音后的一路当前帧信号,计算混音后信号当前帧所包括的各样本权重和各输出样本。
由于采用了上述技术方案,本发明提供的混音器及混音方法,提供了一种新的语音激活检测方式,即通过语音信号的平均功率来判断当前帧是否为语音信号;本发明通过时变滤波器的引入,解决了当前混音技术中各路信号直接参加混音而引入不必要噪声的问题,同时避免了采用静音检测来减少参加混音路数而造成的“无发言”与会者毫无存在感的问题;本发明采用等响度控制策略,通过计算各路信号的响度来得出各路信号的权重,最终使各路信号的平均响度接近相同,听觉效果也接近;本发明实现了语音信号尤其是小信号语音质量的提高,也体现出了对各与会者的公平性。
附图说明
图1是本发明所述混音器的结构框图;
图2是本发明所述语音检测单元的结构框图;
图3是本发明所述响度计算单元的结构框图;
图4是本发明所述混音器的工作流程图;
图5是本发明三路不同特性的语音信号的波形示意图;
图6是经过本发明响度计算单元和权重计算单元处理之后的三路语音信号的波形示意图;
图7是本发明混音器输出信号的波形示意图;
图8是本发明所述混音方法的流程图。
具体实施方式
如图1、图2、图3和图4所示的一种混音器,包括:分帧单元,用于对参与混音的各路信号分别进行分帧;与所述分帧单元相连接的语音检测单元;所述语音检测单元用于对分帧后的各路信号是否均含有语音信号进行检测;所述语音检测单元通过检测一路信号中当前帧是否处于有语音信号状态,来确定该路信号是否含有语音信号;与所述语音检测单元相连接的时变滤波器;所述时变滤波器用于根据所述语音检测单元的检测结果,对分帧后的各路信号分别进行时变低通滤波处理;当一路信号中当前帧处于有语音信号状态时,所述时变滤波器的通带宽度逐渐变宽,当一路信号中当前帧处于无语音信号状态时,所述时变滤波器的通带宽度逐渐变窄;与所述语音检测单元相连接的响度计算单元;所述响度计算单元用于根据所述语音检测单元的检测结果,来分别计算分帧后的各路信号在当前预定时间段内的平均响度;与响度计算单元相连接的权重计算单元;所述权重计算单元用于根据所述响度计算单元的计算结果,分别计算参与混音的各路信号中当前帧所包括的各样本权重;与所述时变滤波器和所述权重计算单元相连接的混音单元;所述混音单元用于根据各路信号分别经过时变低通滤波处理后的当前帧输出信号,以及各路信号中当前帧所包括的各样本权重,获得并输出各路信号当前帧混音后的一路当前帧信号;与所述混音单元相连接的后处理单元;所述后处理单元用于根据混音单元输出的一路当前帧信号,计算混音后信号当前帧所包括的各样本权重和各输出样本;进一步地,所述语音检测单元包括:功率计算模块,用于分别计算分帧后的各路信号中当前帧的功率;与所述功率计算模块相连接的最小帧功率确定模块;所述最小帧功率确定模块用于根据所述功率计算模块的计算结果,来分别获得分帧后的各路信号在当前预定时间段内最小的帧功率;与所述功率计算模块和所述最小帧功率确定模块相连接的语音状态获知模块;所述语音状态获知模块用于通过对一路信号中当前帧的功率与所述最小的帧功率之间的比较来检测一路信号中是否含有语音信号;进一步地,所述功率计算模块通过公式来计算一路信号中当前帧的功率,式中:pow表示当前帧的功率,x[i]表示当前帧第i个输入数据,N表示一帧中的样本数量;
所述当前预定时间段表示从当前帧的前r帧至当前帧的持续时间T;所述最小帧功率确定模块通过公式pow_min=min{当前帧功率,当前帧前1帧功率,···,当前帧前r帧功率}来获得一路信号在当前预定时间段内最小的帧功率,式中:min{}表示大括号中所有数据的最小值、ceil(x)表示接近x且大于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;所述语音状态获知模块通过设定VAD来表示一路信号中是否含有语音信号,并对VAD赋初值使得VAD=1;当pow≥32·pow_min,且VAD=0时所述语音状态获知模块将VAD置1,表示该路信号处于有语音信号状态;当pow≤4·pow_min,且VAD=1时所述语音状态获知模块将VAD置0,表示该路信号处于无语音信号状态;在pow与pow_min之间的比较结果为其它情况时,所述语音状态获知模块将VAD保持不变;进一步地,所述时变滤波器通过公式f[i]=(1-b)*x[i]+b*f[i-1]获得一路信号中当前帧的第i个滤波输出值,式中:f[i]表示一路信号中当前帧的第i个滤波输出值、x[i]表示当前帧第i个输入数据、N表示一帧中的样本数量、0≤i<N、b表示滤波系数,在当前帧处于有语音信号状态时,在当前帧处于无语音信号状态时,当b<0.18,取b=0.18,当b>0.956,取b=0.956,p1表示b从0.956变至0.18的时间长度内的采样点数,p2表示b从0.18变至0.956的时间长度内的采样点数;进一步地,所述响度计算单元包括:DFT变换模块、与DFT变换模块相连接的响度获得模块和与响度获得模块相连接的平均响度获得模块;当一路信号中当前帧处于有语音信号状态时,通过所述DFT变换模块对该路信号中当前帧进行DFT变换,之后通过所述响度获得模块计算所述当前帧的响度值,最后通过所述平均响度获得模块计算该路信号当前预定时间段内的平均响度;当一路信号中当前帧处于无语音信号状态时,该路信号当前预定时间段内的平均响度等于在当前帧之前的含有语音信号的上一预定时间段内的平均响度;进一步地,所述DFT变换模块通过公式对一路信号中当前帧进行DFT变换,式中,s表示离散频率、x[i]表示当前帧第i个输入数据、X[s]表示x[i]经过DFT变换后得到的结果、j表示虚数单位,j2=-1;
所述响度获得模块利用公式对所述当前帧的响度值进行计算,式中,loudness表示当前帧的响度值、X[s]表示x[i]经过DFT变换后得到的结果、Equal[s]表示具有预设数值的等响度数组、s20=ceil(20*N/Fs)、s20000=floor(20000*N/Fs)、ceil(x)表示接近x且大于等于x的整数、floor(x)表示接近x且小于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;所述平均响度获得模块通过公式来计算一路信号当前预定时间段内的平均响度;当前预定时间段表示从当前帧的前r帧至当前帧的持续时间T;式中:ceil(x)表示接近x且大于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;进一步地,所述权重计算单元通过公式得出第k路信号中当前帧权重,并通过公式weightk[i]=weightk 0≤i<N获得第k路信号中当前帧第i个样本的权重;式中:weightk表示第k路信号中当前帧权重,LOUDk表示第k路信号在当前预定时间段内的平均响度,M表示参与混音的信号路数,k=1、2、…、M,weightk[i]表示第k路信号中当前帧第i个样本的权重;所述混音单元通过公式得出各路信号当前帧混音后的一路当前帧信号,式中:Mix[i]表示混音后的一路当前帧信号的第i个样本,M表示参与混音的信号路数,f_k[i]表示经过时变低通滤波处理后的第k路信号中当前帧第i个样本输出信号,weightk[i]表示第k路信号中当前帧所包括的第i个样本的权重,k=1、2、…、M;所述后处理单元还用于获得混音后信号当前帧中的最大样本、以及计算混音后信号的当前帧权重;进一步地,所述权重计算单元还用于分别对参与混音的各路信号中的各帧权重进行平滑处理;进一步地,所述权重计算单元对一路信号中的各帧权重进行平滑处理的实现过程为:当一路信号中当前帧为第一帧时,所述权重计算单元通过公式weightk[i]=weightk 0≤i<N获得第k路信号中当前帧第i个样本的权重;当一路信号中当前帧不为第一帧时,所述权重计算单元通过公式获得第k路信号中当前帧第i个样本的权重;其中,weightk[i]表示第k路信号中当前帧第i个样本的权重、N表示一帧中的样本数量、P表示weightk[i]从当前帧前1帧权重逐渐变至当前帧权重的采样点数;所述后处理单元通过公式signalmax=max{|Mix[0]|,|Mix[1]|,···|Mix[N-1]|}获得混音后信号当前帧中的最大样本,式中:signalmax表示混音后信号当前帧所包括的最大样本、max{}表示大括号中数据的最大值、Mix[0]表示混音后信号当前帧第0样本的输出信号、Mix[1]表示混音后信号当前帧第1样本的输出信号、Mix[N-1]表示混音后信号当前帧第N-1样本的输出信号;当signalmax≤32768时,所述后处理单元计算出混音后信号的当前帧权重weightmix=1,当signalmax>32768时,所述后处理单元计算出混音后信号的当前帧权重当混音后信号的当前帧为第一帧时,所述后处理单元通过公式weightmix[i]=weightmix 0≤i<N获得混音后信号当前帧第i个样本的权重,当混音后信号的当前帧不为第一帧时,所述后处理单元通过公式获得混音后信号当前帧第i个样本的权重,式中:weightmix[i]表示混音后信号当前帧第i个样本的权重、Q表示weightmix[i]从混音后当前帧前1帧权重逐渐变至混音后当前帧权重的采样点数;所述后处理单元通过公式得出混音后信号当前帧的第i个输出样本y[i],式中:final[i]=Mix[i]*weightmix[i]、0≤i<N。
如图8所示,本发明还提供了一种混音方法,包括如下步骤:
步骤1:对参与混音的各路信号分别进行分帧;
步骤2:对分帧后的各路信号是否均含有语音信号进行检测;通过检测一路信号中当前帧是否处于有语音信号状态,来确定该路信号是否含有语音信号;
步骤3:根据语音信号检测结果,对分帧后的各路信号分别进行时变低通滤波处理:当一路信号中当前帧处于有语音信号状态时,通带宽度逐渐变宽,当一路信号中当前帧处于无语音信号状态时,通带宽度逐渐变窄;
步骤4:根据语音信号检测结果,来分别计算分帧后的各路信号在当前预定时间段内的平均响度;
步骤5:根据平均响度计算结果,分别计算参与混音的各路信号中当前帧所包括的各样本权重;
步骤6:根据各路信号分别经过时变低通滤波处理后的当前帧输出信号,以及各路信号中当前帧所包括的各样本权重,获得并输出各路信号当前帧混音后的一路当前帧信号;
步骤7:根据各路信号当前帧混音后的一路当前帧信号,计算混音后信号当前帧所包括的各样本权重和各输出样本。
进一步地,所述步骤1具体包括如下步骤:
步骤11:分别计算分帧后的各路信号中当前帧的功率;
步骤12:根据各路信号中当前帧功率的计算结果,来分别获得分帧后的各路信号在当前预定时间段内最小的帧功率;
步骤13:通过对一路信号中当前帧的功率与所述最小的帧功率之间的比较来检测一路信号中是否含有语音信号;
进一步地,
一路信号中当前帧的功率通过公式进行计算,式中:pow表示当前帧的功率,x[i]表示当前帧第i个输入数据,N表示一帧中的样本数量;
所述当前预定时间段表示从当前帧的前r帧至当前帧的持续时间T;通过公式pow_min=min{当前帧功率,当前帧前1帧功率,···,当前帧前r帧功率}来获得一路信号在当前预定时间段内最小的帧功率,式中:min{}表示大括号中所有数据的最小值、ceil(x)表示接近x且大于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;
通过设定VAD来表示一路信号中是否含有语音信号,并对VAD赋初值使得VAD=1;当pow≥32·pow_min,且VAD=0时将VAD置1,表示该路信号处于有语音信号状态;当pow≤4·pow_min,且VAD=1时将VAD置0,表示该路信号处于无语音信号状态;在pow与pow_min之间的比较结果为其它情况时,将VAD保持不变;
进一步地,所述步骤2具体为:
通过公式f[i]=(1-b)*x[i]+b*f[i-1]获得一路信号中当前帧的第i个滤波输出值,式中:f[i]表示一路信号中当前帧的第i个滤波输出值、x[i]表示当前帧第i个输入数据、N表示一帧中的样本数量、0≤i<N、b表示滤波系数,在当前帧处于有语音信号状态时,在当前帧处于无语音信号状态时,当b<0.18,取b=0.18,当b>0.956,取b=0.956,p1表示b从0.956变至0.18的时间长度内的采样点数,p2表示b从0.18变至0.956的时间长度内的采样点数;
进一步地,
当一路信号中当前帧处于有语音信号状态时,所述步骤3具体包括如下步骤:
步骤31:对该路信号中当前帧进行DFT变换;
步骤32:计算所述当前帧的响度值;
步骤33:计算该路信号当前预定时间段内的平均响度;
当一路信号中当前帧处于无语音信号状态时,该路信号当前预定时间段内的平均响度等于在当前帧之前的含有语音信号的上一预定时间段内的平均响度;
进一步地,
通过公式对一路信号中当前帧进行DFT变换,式中,s表示离散频率、x[i]表示当前帧第i个输入数据、X[s]表示x[i]经过DFT变换后得到的结果、j表示虚数单位,j2=-1;
利用公式对所述当前帧的响度值进行计算,式中,loudness表示当前帧的响度值、X[s]表示x[i]经过DFT变换后得到的结果、Equal[s]表示具有预设数值的等响度数组、s20=ceil(20*N/Fs)、s20000=floor(20000*N/Fs)、ceil(x)表示接近x且大于等于x的整数、floor(x)表示接近x且小于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;
通过公式来计算一路信号当前预定时间段内的平均响度;当前预定时间段表示从当前帧的前r帧至当前帧的持续时间T;式中:ceil(x)表示接近x且大于等于x的整数、FS表示采样频率、N表示一帧中的样本数量;
进一步地,通过公式得出第k路信号中当前帧权重,并通过公式weightk[i]=weightk 0≤i<N获得第k路信号中当前帧第i个样本的权重;式中:weightk表示第k路信号中当前帧权重,LOUDk表示第k路信号在当前预定时间段内的平均响度,M表示参与混音的信号路数,k=1、2、…、M,weightk[i]表示第k路信号中当前帧第i个样本的权重;
进一步地,通过公式得出各路信号当前帧混音后的一路当前帧信号,式中:Mix[i]表示混音后的一路当前帧信号的第i个样本,M表示参与混音的信号路数,f_k[i]表示经过时变低通滤波处理后的第k路信号中当前帧第i个样本输出信号,weightk[i]表示第k路信号中当前帧所包括的第i个样本的权重,k=1、2、…、M;
所述方法还包括如下步骤:获得混音后信号当前帧中的最大样本、以及计算混音后信号的当前帧权重;
进一步地,在所述步骤4之后还具有如下步骤:分别对参与混音的各路信号中的各帧权重进行平滑处理;
进一步地,对一路信号中的各帧权重进行平滑处理的实现过程为:
当一路信号中当前帧为第一帧时,通过公式weightk[i]=weightk 0≤i<N获得第k路信号中当前帧第i个样本的权重;
当一路信号中当前帧不为第一帧时,通过公式
获得第k路信号中当前帧第i个样本的权重;其中,weightk[i]表示第k路信号中当前帧第i个样本的权重、N表示一帧中的样本数量、P表示weightk[i]从当前帧前1帧权重逐渐变至当前帧权重的采样点数;
通过公式signalmax=max{|Mix[0]|,|Mix[1]|,···|Mix[N-1]|}获得混音后信号当前帧中的最大样本,式中:signalmax表示混音后信号当前帧所包括的最大样本、max{}表示大括号中数据的最大值、Mix[0]表示混音后信号当前帧第0样本的输出信号、Mix[1]表示混音后信号当前帧第1样本的输出信号、Mix[N-1]表示混音后信号当前帧第N-1样本的输出信号;
当signalmax≤32768时,计算出混音后信号的当前帧权重weightmix=1,当signalmax>32768时,计算出混音后信号的当前帧权重
当混音后信号的当前帧为第一帧时,通过公式weightmix[i]=weightmix 0≤i<N获得混音后信号当前帧第i个样本的权重,当混音后信号的当前帧不为第一帧时,通过公式获得混音后信号当前帧第i个样本的权重,式中:weightmix[i]表示混音后信号当前帧第i个样本的权重、Q表示weightmix[i]从混音后当前帧前1帧权重逐渐变至混音后当前帧权重的采样点数;
通过公式得出混音后信号当前帧的第i个输出样本y[i],式中:final[i]=Mix[i]*weightmix[i]、0≤i<N。
本发明时变滤波器的通带宽度的上限为20kHz,通带宽度的下限为0.3kHz;当滤波通带大于上限或小于下限时,使其保持在上下限;在进行时变低通滤波处理之前,首先对时变滤波器进行初始化,具体为使f[-1]=0,b=0.18,此时时变滤波器的通带宽度为0~20kHz;本发明当前预定时间段可以取值当前4s;上一预定时间段指当前4s的上一个4s;本发明Equal[s]表示具有预设数值的等响度数组,所述等响度数组中的预设数值根据等响度曲线而得到,其具体数值如表1;
表1.等响度数组Equal[s]的数值表。
下面结合表1说明Equal[s]值的具体获得过程:①计算s*N/Fs的值;②根据s*N/Fs的值,在表1中查找该值所对应的频率范围;③根据表1中所得到的频率范围,求出对应的Equal[s]值;例如,当s*N/Fs=1时,其值落在表1(0.985~1.500)的频率范围内,故Equal[s]=1.5。
为了保证各路信号平均响度相同,需要计算出各路信号的等响度权重;本发明经过平滑处理步骤,使得各帧之间的权重有P个点的平滑处理过程,可以保证权重数据在各帧之间平稳变化,进而语音信号听起来更加平滑,有利于语音质量的保证;若权重计算单元对每路信号中各帧权重不进行优选的平滑处理过程,则第k路信号中当前帧所包括的各样本权重(weightk[i],i取值0、1、2…N-1)均等于第k路信号中当前帧权重weightk,具体地,若权重计算单元对每路信号中各帧权重进行优选的平滑处理过程,则当一路信号中当前帧为第一帧时,所述权重计算单元通过公式weightk[i]=weightk0≤i<N获得第k路信号中当前帧第i个样本的权重;当一路信号中当前帧不为第一帧时,所述权重计算单元通过公式
获得第k路信号中当前帧第i个样本的权重,即经过平滑处理过程后,第k路信号中当前帧所包括的各样本权重不全等于第k路信号中当前帧权重weightk;另外,在对各路信号混音之后,为了防止多路语音信号相加后可能出现的频繁溢出现象,则可以进行相应的后处理,同时通过后处理操作还可以保证各帧信号的权重数据之间保持平稳,进而有利于混音后语音的平滑性。本发明以各路语音信号的响度作为标准来计算其权重,使各路语音信号的平均响度相同,最后再进行溢出处理,进而各路语音信号经过混音后,其响度在听觉上接近相同,且溢出不会频繁。
下面通过对三路不同特性的语音信号采用本发明所述混音器进行混音来进一步说明本发明的有效性,其中,采样频率FS取48kHz,一帧信号中的样本数N取2048,当前预定时间段取当前4秒,帧数r取100,b从0.956变至0.18的时间长度内的采样点数p1取960,b从0.18变至0.956的时间长度内的采样点数p2取96000,weightk[i]从当前帧前1帧权重逐渐变至当前帧权重的采样点数P取100,weightmix[i]从混音后当前帧前1帧权重逐渐变至混音后当前帧权重的采样点数Q取100;
图5示出了本发明三路不同特性的语音信号的波形示意图,如图5所示,为了验证小信号的混音效果,第一路语音信号(信号1)幅度范围为-3500~3500,远小于其它两路语音信号;由于响度与幅度成正比,所以第一路语音信号的响度也远小于其它两路语音信号;为了验证语音检测单元与时变滤波器的有效性,第二路语音信号(信号2)的特点为“有语音”状态和“无语音”状态相互交替且加入了均匀白噪声;第三路语音信号(信号3)的特点为:前面一部分信号幅度较小,后面部分信号幅度较大,进而混音后可对比第三路语音信号前后幅度的变化,从而分析其前后响度的变化;图6是经过本发明响度计算单元和权重计算单元处理之后的三路语音信号的波形示意图,如图6所示,经过语音检测单元、时变滤波器、响度计算单元和权重计算单元的处理后,三路语音信号均发生了不同的变化;其中,第一路语音信号(信号1)幅度明显增大,其响度也随之增大;第二路语音信号(信号2)连续出现“无语音”状态时,信号中的均匀白噪声被滤去,信号幅度也有所减小;第三路语音信号(信号3)前面一部分信号的幅度有所增大,后面部分信号的幅度则有所减小;图7示出了本发明混音器输出信号的波形示意图,如图7所示,通过混音单元对三路语音信号进行叠加,再通过后处理单元使得最终输出信号溢出不频繁,且溢出已经过饱和处理。由以上测试结果可见,三路响度各不相同的语音信号,经过本发明混音器进行等响度控制之后,其平均响度接近相等;由于三路语音信号具有不同特性,也表明了了本发明良好的鲁棒性和稳定性。
本发明提供了一种新的语音激活检测方式,即通过语音信号的平均功率来判断当前帧是否为语音信号;本发明通过时变滤波器的引入,解决了当前混音技术中各路信号直接参加混音而引入不必要噪声的问题,同时避免了采用静音检测来减少参加混音路数而造成的“无发言”与会者毫无存在感的问题;本发明采用等响度控制策略,通过计算各路信号的响度来得出各路信号的权重,最终使各路信号的平均响度接近相同,听觉效果也接近;本发明实现了提高小信号语音质量的同时,也体现出了对各与会者的公平性。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!