针对目标对象的语音增强系统及语音增强方法与流程
本发明涉及一种利用信号处理演算法及声学模型来针对目标对象的数字语音信号增强的方法,本发明进一步涉及利用麦克风阵列信号处理及说话人辨识的语音增强系统。
背景技术:
语音/声音在人与人的互动中扮演着重要的角色,然而,无所不在的环境噪音与干扰,会显著地降低麦克风所撷取到的语音信息的品质,某些应用程序(例如自动说话人辨识(automaticspeechrecognition,asr)及说话人识别)特别容易受到该些环境噪音及干扰的影响,听力受损者亦受到语音品质降低之苦,虽然具有正常听力者可容忍所撷取到的语音信号中相当的噪音与干扰,但听者的听力疲劳度容易随着暴露于低信噪比(signaltonoiseratio,snr)的语音下的时间的增加而升高。
在许多装置上(例如智能手机、平板电脑或笔记型电脑),不易设置有一个以上的麦克风,使用麦克风阵列可藉由波束成形(beamforming)、盲源分离(blindsourceseparation,bss)、独立分量分析(independentcomponentanalysis,ica)及其他适当的信号处理演算法的手段来提升语音品质,然而,在麦克风阵列设置的音场中,可能有多个语音来源,而该些信号处理演算法无法决定要保留哪一个音源信号,且无法决定哪一个须与噪音及干扰一同被抑制。在现有技术中是使用线性阵列,并假设所欲音源的声波是由阵列的中间或两端方向贯入阵列,因此相对应地,是使用宽边波束成形或端射波束成形来增加所欲的语音信号,故至少对部分情况而言,该些现有技术限制了麦克风阵列的效能。另一种选择,是自麦克风阵列所录得的音频混合信号中,撷取与预先设定的说话人模型或说话人特征数据最匹配的语音信号,此种求解方案在目标说话人是可预期或事先已知的情况下为最佳。举例而言,对个人化装置如智能手机而言,最可能的目标说话人为该装置的所有者,只要建立该装置的所有者的说话人特征数据,除了明确设定为不以此方式操作以外,该装置可以始终聚焦于其所有者的声音,并将其他声音视为干扰。
技术实现要素:
本发明的目的在于提供一种对多个目标说话人中至少一个说话人的语音增强系统及方法,是利用麦克风阵列纪录的盲源分离(bss)以及依据预设说话人特征数据表的说话人辨识。
为达上述目的,本发明提供一种对多个目标说话人中至少一个说话人的语音增强方法,其使用多个音频混合信号中的至少两个执行于一数字电脑,所述数字电脑具有可执行的程序码及数据储存单元,其中所述方法包含以下步骤:
以一盲源分离信号处理器来分离多个音频混合信号中的至少两个成为相同数量的音频分量;
加权且混合所述音频分量中的至少两个成为一所撷取的语音信号,其中藉由将音频分量与目标说话人特征数据相比较来产生多个语音混合权重;
加权并混合多个音频分量中的至少两个成为一所撷取的噪声信号,其中藉由将音频分量与多个中的至少一个噪声特征数据、或不具有噪声特征数据的目标说话人特征数据相比较来产生多个噪声混合权重;
利用维纳滤波,将所述所撷取的噪声信号的功率谱与所述所撷取的语音信号的功率谱相匹配,来先整形所述所撷取的噪声信号的功率谱,再从所述所撷取的语音信号的功率谱中减去整型后的所述所撷取的噪声信号的功率谱,来增强所撷取的语音混合信号。
为达上述目的,本发明还提供一种对多个目标说话人中至少一个说话人的语音增强系统,其使用多个音频记录中的至少两个执行于一数字电脑,所述数字电脑具有可执行的程序码及数据储存单元,其中包含有:
一盲源分离模块,其以对各频率点的一分离矩阵来分离多个音频混合信号中的至少两个而成为频域下相同数量的音频分量;
一语音混合器,其与盲源分离模块相连接,其依据各音频分量与目标说话人特征数据的相关性来加权各音频分量,并相对应混合所述加权后的音频分量,来使混合后的音频分量成为一所撷取的语音信号;
一噪声混合器,其与盲源分离模块相连接,其依据各音频分量与噪声的相关性来加权各音频分量,并相对应混合所述加权后的音频分量,来使混合后的音频分量成为一所撷取的噪声信号;
一后处理模块,其与语音混合器及噪声混合其相连接,其利用维纳滤波将所撷取的噪声信号视为一噪声参考信号,来抑制在所述所撷取的语音信号中剩余的噪声。
本发明bss演算法将来自数个麦克风所录得的混音加以分离而成统计独立的音频分量,对各音频分量而言,多个预设目标说话人模型中的至少一个模型是用来评估各音频分量属于目标说话人的可能性,对音源分量加权并混合以产生最匹配于目标说话人模型的单一撷取语音信号,后处理是用以进一步抑制所撷取的语音信号中的噪声及干扰。
以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
附图说明
图1为现有技术的模块图;
图2为本发明第一实施例的模块图;
图3为本发明第二实施例的模块图;
图4为频域下图2及图3中所示的bss模块的模块图;
图5为图2及图3中所示的语音混合器的模块图;
图6为图2及图3中所示的噪声混合器的模块图;
图7为本发明的后处理程序的流程图。
具体实施方式
下面结合附图对本发明的结构原理和工作原理作具体的描述:
本发明的概述
本发明描述一种对多个目标说话人中至少一个说话人的语音增强方法,是使用多个麦克风中的至少两个来撷取音频混合信号,利用盲源分离(bss)演算法或独立分量分析(ica)演算法来将该些音频混合信号分离为接近统计独立的音频分量,对各音频分量而言,多个预设目标说话人特征数据中的至少一笔数据系用来评估所选择的音频分量属于所欲的目标说话人的机率或可能性,接着对所有的音频分量依据前述的可能性进行加权后再混合以产生最匹配于目标说话人模型的单一撷取语音信号。另一相似地作法,对于各音频分量而言,多个噪声模型中的至少一个、或多个不具有噪声模型的目标说话人模型中的至少一个,是用来评估该被考虑的音频分量为噪声或不包含来自目标说话人的任何语音信号的机率或可能性,接着对所有的音频分量依据前述的可能性进行加权后再混合以产生单一撷取噪声信号,利用该所撷取的噪声信号,藉由维纳滤波(wienerfiltering)或频谱滤波法来进一步抑制所撷取的语音信号中剩余的噪声和干扰。
图1为相关现有技术的模块图,自两个语音来源100、102的声波贯入二纪录装置,即麦克风104、106,一bss或ica模块108将音频混合信号分离为两个音源分量,多个说话人特征数据中的至少一个是储存于储存单元110中,一音频通道选择器112选择一个最匹配于所欲的说话人特征数据的音频分量,并将其输出为所选择的语音信号114。因使用硬性的切换故所述现有技术对于静态的混合信号及离线处理的效果较佳,对于动态或时间变化的混合条件的应用环境,由于涉及动态或时间变化的在线bss的实施,则难以或不可能将音频混合信号分离为音频分量,因此,只有依音频分量包含所欲的语音信号,举例而言,在bss程序的过渡阶段中,所有的音频分量均可能包含所欲的语音信号、噪声及干扰,再者,bss输出可切换频道,使得所欲的语音信号在某一次在某一频道占支配地位,但于另一次又在另一频道占支配地位。具体而言,如图1所示的硬件开关无法正确地处理该些情形,且可能产生严重失真的语音信号。本发明是利用分离-混合程序来克服该些难题,以恰当的维持所欲的语音信号,纵使在动态语音环境下亦同,并利用后处理模块来进一步增强所欲的语音信号。
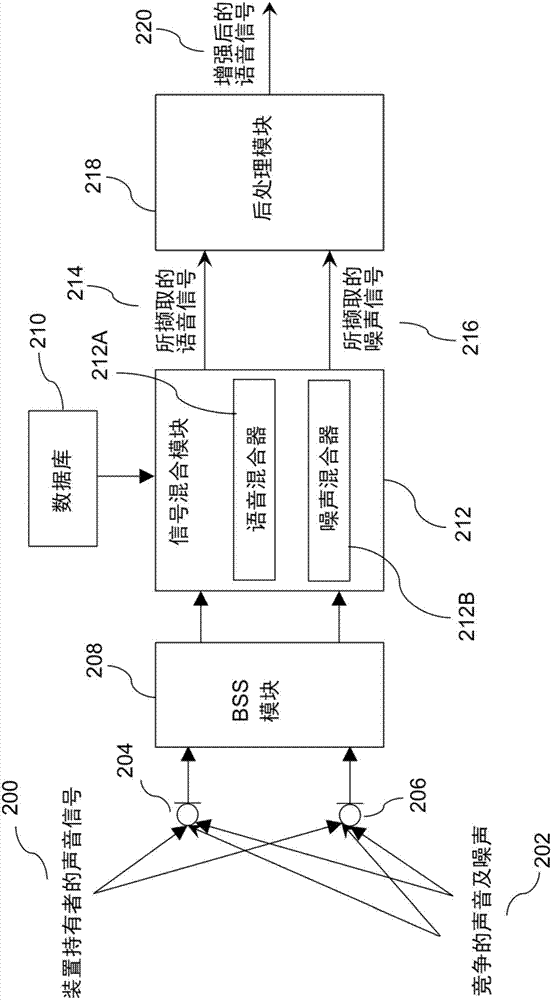
图2为本发明的一实施例的模块图,其中装置持有者的声音信号200已被撷取,竞争的声音及噪声202则被抑制,在本实施例中,该装置可为智能手机、平板电脑、个人电脑等。两个所记录的音频混合信号204、206被传送入bss模块208中,装置持有者的说话人特征数据是储存于数据库210中,说话人特征数据可对应于同一装置、或对应于其他装置并随后传送至所欲的装置。一信号混合模块212将分离的音频分量进行加权,再适当的加以混合以产生一所撷取的语音信号214及一所撷取的噪声信号216,所撷取的语音信号214及所撷取的噪声信号216传送至一后处理模块218,以藉由维纳滤波(wienerfiltering)或频谱滤波法进一步抑制语音信号214中剩余的噪声及竞争的声音,进而产生增强后的语音信号220。在一实施例中,所述信号混合模块212进一步包含一语音混合器212a及一噪声混合器212b,其详细模块图分别示于图5及图6中。
图3为本发明另一实施例的模块图,其中涉及多个说话人及使用多个音频混合记录单元,本实施例的典型例示为会议纪录单元,其涉及数个关键说话人的语音信号需要被撷取及增强。于本实施例中,三个说话人300、302、304处于同一录制环境中,其语音信号可能会在时间上重叠,三个音频混合记录器,即语音信号由麦克风305、306、307所记录后传送入bss模块308中,再分离为三个音频分量,一数据库310可储存多个中至少一个说话人特征数据,藉由所选择的说话人特征数据,一信号混合模块312产生一所撷取的语音信号314及一所撷取的噪声信号316,一后处理模块318进一步增强所撷取的语音信号314以产生增强的语音信号320。
盲源分离
图4为用来说明图2及图3中bss模块208、308的较佳实施态样的模块图,为了清楚说明,图4为用来说明在频域下的bss,藉由独立向量分析(independentvectoranalysis,iva)或联合盲源分离(jointblindsourceseparation,jbss)来分离两个音频混合信号,然而,可以理解的是,本发明不限于在频域下的bss实施且不限于用来分离两个音频混合信号,在其他交换域下的bss实施也同样可以使用,例如子带域、子波域、或甚至原始时域,需要被分离的音频混合信号的数量可为两个或任何不小于2的整数,任何适当形式的bss实施,例如iva、jbss或两阶段bss解法,其中第一阶段以bss或ica解法将各频率点(bin)中的混合信号独立分离,而第二阶段利用到达方向(direction-of-arrival,doa)信息及语音信号的特定统计性质来求解频率点(frequencybin)的置换,例如自同一语音信号中跨越所有频率点的相似振幅包络。
在图4中,两个分析滤波器组404、406将两个音频混合信号400、402转换为频域,所述两个分析滤波器组404、406应具有相同的结构及参数,且应存在有一综合滤波器组与所述分析滤波器组404、406成对,故当频率信号不再被改变时,其可最佳地或接近最佳地重建原始时域信号,举例而言,所述分析/综合滤波器组为短时距傅立叶转换(short-timefouriertransform,stft)及离散傅立叶转换(discretefouriertransform,dft)调变滤波数据库。对各频率点而言,一iva或jbss模块408用分离矩阵(demixingmatrix)将两个音频混合信号分离成两个音频分量,所述频率置换问题通过利用来自相同语音信号源的频率点中的统计相关性而求解,iva及jbss的特征。所述音频分量410被传送至单一混合模组212、312中以进一步处理。
一般而言,数个分析滤波器组将数个时域下的音频混合信号转换为数个频域下的音频混合信号,可以如下所示:
x(n,t)→x(n,k,m)(公式1)
其中x(n,t)为第n个音频混合信号在离散时间t下的时域信号,而x(n,k,m)为在第n个音频混合信号、第k个频率点及第m个框或区段的频域信号,对各频率点而言,形成一个向量如x(k,m)=[x(1,k,m),x(2,k,m),…,x(n,k,m)],而对第m个区段,求解一分离矩阵(separationmatrix)w(k,m)以将该些音频混合信号分离成音频分量为
[y(1,k,m),y(2,k,m),…,y(n,k,m)]=w(k,m)x(k,m)(公式2)
其中n为音频混合信号的数量,一具有步长足够小的随机梯度下降演算法(stochasticgradientdescentalgorithm)是用来求解w(k,m),因此w(k,m)缓慢地基于其框序m逐步展开。形成一频率源向量如y(n,m)=[y(n,1,m),y(n,2,m),…,y(n,k,m)],熟知的频率置换问题系通过利用来自不同源向量中的统计独立性及来自相同源向量的分量中的统计相关性而求解,即iva之名。尺度不确定性(scalingambiguity)为另一在bss实施上熟知的问题,一现有用来去除所述不确定性的方式,是于各频率点中缩放所述分离矩阵,使得其所有对角元素将具有单位振幅及零相位。
语音混合器
图5为说明语音混合器212a、312a将两个音频分量结合为单一撷取语音信号的附图,然而,图5仅为了能清楚呈现,故仅以两个音频分量来作为范例,故不应被理解为所示的语音混合器212a、312a仅能用来混合两个音频分量。
在图5中,两个相同的声学特征撷取器506、508分别由音频分量500、502中撷取声学特征,一数据库504储存特征在来自目标说话人的声学特征的概率密度函数(probabilitydensityfunction,pdf)的说话人模型,藉由比对声学特征撷取器506、508所撷取到的声学特征和说话人特征数据中的声学特征,一语音混合权重产生器510产生两个语音混合权重,且模块512、514相对应将该两增益值应用在音频分量500、502上,对各频率点而言。一矩阵混合器516利用该频率点的分离矩阵的逆矩阵来混合所述加权后的音频分量,一延迟估计器518估算两个再混合音频分量之间的时间延迟,且延迟线520、522对齐所述两再混合音频分量,最后,模块524将两延迟对齐的再混合音频分量相加以产生单一撷取语音信号214、314。
说话人特征数据可为一参数模型,该参数模型是描述撷取自给定说话人的声学信号的声学特征的概率密度函数,一般所使用的声学模型为线性预测倒频谱系数(linearpredictioncepstralcoefficients,lpcc)、感知线性预测(perceptuallinearprediction,plp)倒频谱系數、及梅尔倒频谱系數(mel-frequencycepstralcoefficients,mfcc),plp倒频谱系数及mfcc可直接由频域信号呈现中得出,故为在频域下bss的较佳选择。
对各源分量y(n,m)而言,一特征向量f(n,m)被撷取出且被与一个或多个说话人特征数据比较,以产生一非负分s(n,m),分数越高表示特征向量f(n,m)与所考虑的说话人特征数据间越匹配,在一般判别说话人的实务中,在此的特征向量可包含该框及前一框的信息,常见的特征组为mfcc、mfcc的差分值(delta-mfcc)、及mfcc的二次差分值(delta-delta-mfcc)。
高斯混合模型(gaussianmixturemodel,gmm)广泛的运用于说话人辨识的参数混合模型,且其可用来评价所需分数s(n,m),建立一通用背景模型(universebackgroundmodel,ubm)以描述来自目标族群的声学特征的概率密度函数,以相同gmm建立目标说话人特征数据,但其参数由ubm调整,一般而言,只有允许调整ubm中高斯分量的均值,如此,在数据库504中的说话人特征数据包含有两组参数:一组参数针对ubm包含所述均值、协方差矩阵及在ubm中的高斯分量的分量权重,另一组参数为针对仅包含gmm的调整后均值的说话人特征数据。
藉由说话人特征数据库及ubm,以下计算对数似然比(logarithmlikelihoodratio,llr)
r(n,m)=logp[f(n,m)|speakerprofiles]-logp[f(n,m)|ubm]
(公式3)
当使用多个说话人特征数据时,可能性p[f(n,m)|说话人特征数据]应被解读为各说话人特征数据上f(n,m)的可能性的总和,此llr是很杂乱的,则利用一指数加权移动平均(exponentiallyweightedmovingaverage)来计算较平滑的llr如
rs(n,m)=ars(n,m)+(1-a)r(n,m)(公式4)
其中0<a<1为遗忘因子。
一单调递增映射,即一指数函数,是用来将一已平滑的llr映射为一非负分s(n,m),则对各源分量而言,产生一语音混合权重作为一正规化的分数如
g(n,m)=s(n,m)/[s(1,m)+s(2,m)+…+s(n,m)+s0](公式5)
其中s0为一适当的正补偿量,故当所有分数均小到可以忽略时,g(n,m)接近零;而当s(n,m)够大时,g(n,m)接近1,如此,则对音频分量的语音混合权重将与其包含的所欲的语音信号的数量形成正相关。
在所述矩阵混合器516中,该加权后的音频分量被加以混合以产生n个混合信号如
[z(1,k,m),z(2,k,m),…,z(n,k,m)]
=w-1(k,m)[g(1,m)y(1,k,m),g(2,m)y(2,k,m),…,g(n,m)y(n,k,m)]
(公式6)
其中w-1(k,m)为w(k,m)的逆。
最后,以一延迟加总程序来结合混合信号z(n,k,m)于单一撷取语音信号214、314中,由于z(n,k,m)为频域下的信号,广义互相关函数(generalizedcrosscorrelation,gcc)方法为用来延迟估算的方便选择。一gcc方法计算频域下两个信号之间的加权互相关函数,并藉由离散傅立叶逆转换(inversedft)将频域下的互相关函数转换为时域下的互相关函数来寻找时域的延迟。相位变换(phasetransform,phat)为gcc实施的普遍选择,其仅保留针对时域下互相关函数计算的相位信息。在频域下,一延迟操作(delayoperation)是对应于相位偏移(phaseshifting),因此,被撷取的语音信号可写为
t(k,m)
=exp(jwkd1)z(1,k,m)+exp(jwkd2)z(2,k,m)+…+exp(jwkdn)z(n,k,m)
(公式7)
其中j为虚数单元,wk为第k个频率点的角频率(radianfrequency),而dn为第n个混合信号的延迟补偿,需注意的是,只有在混合信号间相对的延迟可被唯一地确定,且平均的延迟可为任意值,一现有作法是假定d1+d2+…+dn=0来唯一地确定延迟组。
在此所述的加权与混合程序相较于硬件开关的方法而言,可较佳的维持所欲的语音信号,举例而言,考虑所欲的说话人在活跃及bss尚未收敛的瞬时阶段,目标语音信号散布在音频分量中,硬件开关的程序将不可避免的因仅选择一音频分量输出而扭曲所欲的语音信号,而前述的本发明的方法藉由权重来结合所有的音频分量,该权重为正比于目标信号在各音频分量中的所占的比例,因此可以保留目标语音信号。
噪声混合器
图6为噪声混合器212b、312b在加权并混合两bss以产生一所撷取的噪声信号时的模块图,在图6中,噪声特征数据、或不具有噪声特征数据的说话人特征数据系储存于数据库600中,两bss输出500、502送入一噪声混合权重产生器602以产生两增益值,模块604、606将所述增益值分别应用于bss输出,而模块608将加权后的bss输出相加以产生所撷取的噪声信号216、316,理想而言,被截取的噪声信号216、316应仅包含噪声及干扰,而所欲说话人的任何语音信号均被排除在外。
当使用n个麦克风时,将撷取到n个源分量,噪声混合权重产生器产生n个权重如h(1,m),h(2,m),…,h(n,m),简单的加权及相加的混合后产生所撷取的噪声信号e(k,m)如
e(k,m)=h(1,m)y(1,k,m)+h(1,m)y(1,k,m)+…+h(n,m)y(n,k,m)
(公式8)
当可取得噪声的gmm时,藉由将说话人特征数据的gmm更换为噪声特征数据的gmm,则用来计算语音混合权重产生的相同方法亦可用来计算噪声混合权重,当无法取得噪声的gmm时,较简便的选择为使用公式3的负llr作为噪声的llr,接着再以与语音混合权重产生的相同的程序来计算噪声混合权重。
后处理
图7为说明后处理模块218、318执行后处理步骤的流程图,对各频率点而言,维纳滤波或频谱滤波,步骤706计算一增益值并应用于所撷取的语音信号214、314以产生增强后的语音信号220。对各频率点而言,步骤704将所撷取的噪声信号216、316的功率谱(powerspectrum)整形以符合步骤706的噪声等级评价(noiselevelestimation)之用。
用来整形噪声谱的简单方法,是应用一正增益在所撷取的噪声信号的功率谱上,如b(k,m)|e(k,m)|2,均衡系数(equalizationcoefficient)b(k,m)可藉由在在噪声主导的时间段b(k,m)|e(k,m)|2and|t(k,m)|2匹配均衡前和均衡后的能量来加以估算,该周期为所欲说话人未活跃的周期。对于各频率点而言,所述均衡系数应在静态或缓慢的声学变化环境中接近常数,因此,可使用一指数加权移动平均方法来估算所述均衡系数。
另一用来决定频率点的均衡系数的简单方法为单纯指定其为一常数,当不需要积极的噪声抑制时,此简单方法为较佳者。
增强后的语音信号220、320由c(k,m)t(k,m)给出,其中c(k,m)为一非负增益值,其系由维纳滤波或频谱滤波所决定,一简单的频谱滤波决定该增益值为
c(k,m)=max[1-b(k,m)|e(k,m)|2/|t(k,m)|2,0](公式9)
该简单的方法可能对特定应用为佳,例如语音辨识,但对其他应用可能为不足,例如其导入水声(wateringsound),维纳滤波使用决策导向的方法,可平滑该增益波动,以抑制该水声至无法被听见的程度。
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!