一种同步语音及虚拟动作的方法、系统及机器人与流程
本发明涉及机器人交互技术领域,尤其涉及一种同步语音及虚拟动作的方法、系统及机器人。
背景技术:
机器人作为与人类的交互工具,使用的场合越来越多,例如一些老人、小孩较孤独时,就可以与机器人交互,包括对话、娱乐等。而为了让机器人与人类交互时更加拟人化,发明人研究出一种虚拟机器人的显示设备和成像系统,能够形成3D的动画形象,虚拟机器人的主机接受人类的指令例如语音等与人类进行交互,然后虚拟的3D动画形象会根据主机的指令进行声音和动作的回复,这样就可以让机器人更加拟人化,不仅在声音、表情上能够与人类交互,而且还可以在动作等上与人类交互,大大提高了交互的体验感。
然而,虚拟机器人如何将回复内容中的语音和虚拟动作进行同步是一个比较复杂的问题,如果语音和动作不能匹配,则会大大影响用户的交互体验。
因此,如何提供一种同步语音及虚拟动作的方法、系统及机器人,提升人机交互体验成为亟需解决的技术问题。
技术实现要素:
本发明的目的是提供一种同步语音及虚拟动作的方法、系统及机器人,提升人机交互体验。
本发明的目的是通过以下技术方案来实现的:
一种同步语音及虚拟动作的方法,包括:
获取用户的多模态信息;
根据用户的多模态信息和生活时间轴生成交互内容,所述交互内容至少包括语音信息和动作信息;
将语音信息的时间长度和动作信息的时间长度调整到相同。
优选的,所述将语音信息的时间长度和动作信息的时间长度调整到相同的具体步骤包括:
若语音信息的时间长度与动作信息的时间长度的差值不大于阈值,当语音信息的时间长度小于动作信息的时间长度,则加快动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
优选的,当语音信息的时间长度大于动作信息的时间长度,则加快语音信息的播放速度或/和减缓动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
优选的,所述将语音信息的时间长度和动作信息的时间长度调整到相同的具体步骤包括:
若语音信息的时间长度与动作信息的时间长度的差值大于阈值,当语音信息的时间长度大于动作信息的时间长度时,则将至少两组动作信息进行排序组合,使组合后的动作信息的时间长度等于所述语音信息的时间长度。
优选的,当语音信息的时间长度小于动作信息的时间长度时,则选取动作信息中的部分动作,使选取的部分动作的时间长度等于所述语音信息的时间长度。
优选的,所述机器人的生活时间轴的参数的生成方法包括:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人的生活时间轴。
优选的,所述将机器人的自我认知进行扩展的步骤具体包括:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。
优选的,所述对机器人的自我认知的参数与生活时间轴中的参数进行拟合的步骤具体包括:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。
优选的,其中,所述生活时间轴指包含一天24小时的时间轴,所述生活时间轴中的参数至少包括用户在所述生活时间轴上进行的日常生活行为以及代表该行为的参数值。
一种同步语音及虚拟动作的系统,包括:
获取模块,用于获取用户的多模态信息;
人工智能模块,用于根据用户的多模态信息和生活时间轴生成交互内容,所述交互内容至少包括语音信息和动作信息;
控制模块,用于将语音信息的时间长度和动作信息的时间长度调整到相同。
优选的,所述控制模块具体用于:
若语音信息的时间长度与动作信息的时间长度的差值不大于阈值,当语音信息的时间长度小于动作信息的时间长度,则加快动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
优选的,当语音信息的时间长度大于动作信息的时间长度,则加快语音信息的播放速度或/和减缓动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
优选的,所述控制模块具体用于:
若语音信息的时间长度与动作信息的时间长度的差值大于阈值,当语音信息的时间长度大于动作信息的时间长度时,则将至少两组动作信息进行组合,使组合后的动作信息的时间长度等于所述语音信息的时间长度。
优选的,当语音信息的时间长度小于动作信息的时间长度时,则选取动作信息中的部分动作,使选取的部分动作的时间长度等于所述语音信息的时间长度。
优选的,所述系统包括处理模块,用于:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人的生活时间轴。
优选的,所述处理模块具体用于:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。
优选的,所述处理模块具体用于:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。
优选的,其中,所述生活时间轴指包含一天24小时的时间轴,所述生活时间轴中的参数至少包括用户在所述生活时间轴上进行的日常生活行为以及代表该行为的参数值。
本发明公开一种机器人,包括如上述任一所述的一种同步语音及虚拟动作的系统。
相比现有技术,本发明具有以下优点:本发明的同步语音及虚拟动作的方法包括:获取用户的多模态信息;根据用户的多模态信息和生活时间轴生成交互内容,所述交互内容至少包括语音信息和动作信息;将语音信息的时间长度和动作信息的时间长度调整到相同。这样就可以通过用户的多模态信息例如用户语音、用户表情、用户动作等的一种或几种,来生成交互内容,交互内容中至少包括语音信息和动作信息,而为了让语音信息和动作信息能够同步,将语音信息的时间长度和动作信息的时间长度调整到相同,这样就可以让机器人在播放声音和动作时可以同步匹配,使机器人在交互时不仅具有语音表现,还可以具有动作等多样的表现形式,机器人的表现形式更加多样化,使机器人更加拟人化,也提高了用户于机器人交互时的体验度。
附图说明
图1是本发明实施例一的一种同步语音及虚拟动作的方法的流程图;
图2是本发明实施例二的一种同步语音及虚拟动作的系统的示意图。
具体实施方式
虽然流程图将各项操作描述成顺序的处理,但是其中的许多操作可以被并行地、并发地或者同时实施。各项操作的顺序可以被重新安排。当其操作完成时处理可以被终止,但是还可以具有未包括在附图中的附加步骤。处理可以对应于方法、函数、规程、子例程、子程序等等。
计算机设备包括用户设备与网络设备。其中,用户设备或客户端包括但不限于电脑、智能手机、PDA等;网络设备包括但不限于单个网络服务器、多个网络服务器组成的服务器组或基于云计算的由大量计算机或网络服务器构成的云。计算机设备可单独运行来实现本发明,也可接入网络并通过与网络中的其他计算机设备的交互操作来实现本发明。计算机设备所处的网络包括但不限于互联网、广域网、城域网、局域网、VPN网络等。
在这里可能使用了术语“第一”、“第二”等等来描述各个单元,但是这些单元不应当受这些术语限制,使用这些术语仅仅是为了将一个单元与另一个单元进行区分。这里所使用的术语“和/或”包括其中一个或更多所列出的相关联项目的任意和所有组合。当一个单元被称为“连接”或“耦合”到另一单元时,其可以直接连接或耦合到所述另一单元,或者可以存在中间单元。
这里所使用的术语仅仅是为了描述具体实施例而不意图限制示例性实施例。除非上下文明确地另有所指,否则这里所使用的单数形式“一个”、“一项”还意图包括复数。还应当理解的是,这里所使用的术语“包括”和/或“包含”规定所陈述的特征、整数、步骤、操作、单元和/或组件的存在,而不排除存在或添加一个或更多其他特征、整数、步骤、操作、单元、组件和/或其组合。
下面结合附图和较佳的实施例对本发明作进一步说明。
实施例一
如图1所示,本实施例中公开一种同步语音及虚拟动作的方法,包括:
S101、获取用户的多模态信息;
S102、根据用户的多模态信息和生活时间轴300生成交互内容,所述交互内容至少包括语音信息和动作信息;
S103、将语音信息的时间长度和动作信息的时间长度调整到相同。
本发明的同步语音及虚拟动作的方法包括:获取用户的多模态信息;根据用户的多模态信息和生活时间轴生成交互内容,所述交互内容至少包括语音信息和动作信息;将语音信息的时间长度和动作信息的时间长度调整到相同。这样就可以通过用户的多模态信息例如用户语音、用户表情、用户动作等的一种或几种,来生成交互内容,交互内容中至少包括语音信息和动作信息,而为了让语音信息和动作信息能够同步,将语音信息的时间长度和动作信息的时间长度调整到相同,这样就可以让机器人在播放声音和动作时可以同步匹配,使机器人在交互时不仅具有语音表现,还可以具有动作等多样的表现形式,机器人的表现形式更加多样化,使机器人更加拟人化,也提高了用户于机器人交互时的体验度。
对于人来讲每天的生活都具有一定的规律性,为了让机器人与人沟通时更加拟人化,在一天24小时中,让机器人也会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。因此本发明将机器人所在的生活时间轴加入到机器人的交互内容生成中去,使机器人与人交互时更加拟人化,使得机器人在生活时间轴内具有人类的生活方式,该方法能够提升机器人交互内容生成的拟人性,提升人机交互体验,提高智能性。交互内容可以是表情或文字或语音或动作等一种或几种的组合。机器人的生活时间轴300是提前进行拟合和设置完成的,具体来讲,机器人的生活时间轴300是一系列的参数合集,将这个参数传输给系统进行生成交互内容。
本实施例中的多模态信息可以是用户表情、语音信息、手势信息、场景信息、图像信息、视频信息、人脸信息、瞳孔虹膜信息、光感信息和指纹信息等其中的其中一种或几种。
本实施例中,基于生活时间轴具体是:根据人类日常生活的时间轴,按照人类的方式,将机器人本身在日常生活时间轴中的自我认知的数值做拟合,机器人的行为按照这个拟合行动,也就是得到一天中机器人自己的行为,从而让机器人基于生活时间轴去进行自己的行为,例如生成交互内容与人类沟通等。假如机器人一直唤醒的话,就会按照这个时间轴上的行为行动,机器人的自我认知也会根据这个时间轴进行相应的更改。生活时间轴与可变参数可以对自我认知中的属性,例如心情值,疲劳值等等的更改,也可以自动加入新的自我认知信息,比如之前没有愤怒值,基于生活时间轴和可变因素的场景就会自动根据之前模拟人类自我认知的场景,从而对机器人的自我认知进行添加。生活时间轴中不仅包括语音信息,也包括了动作等信息。
例如,用户向机器人说话:“好困啊”,机器人听到后理解的为用户很困,然后结合机器人的生活时间轴,例如当前的时间为上午9点,那么机器人就知道主人是刚刚起床,那么就应该向主人问早,例如回答语音“早上好”作为回复,还可以唱一首歌,并配上相应舞蹈动作等。而如果用户向机器人说话:“好困啊”,机器人听到后理解的为用户很困,然后机器人的生活时间轴,例如当前的时间为晚上9点,那么机器人就知道主人需要睡觉了,那么就会回复语音“主人晚安,睡个好觉”等类似用语,并配上相应的晚安、睡眠动作等。这种方式要比单纯的语音和表情回复更加贴近人的生活,具有动作更加拟人化。
本实施例中,所述将语音信息的时间长度和动作信息的时间长度调整到相同的具体步骤包括:
若语音信息的时间长度与动作信息的时间长度的差值不大于阈值,当语音信息的时间长度小于动作信息的时间长度,则加快动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
当语音信息的时间长度大于动作信息的时间长度,则加快语音信息的播放速度或/和减缓动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
因此,当语音信息的时间长度与动作信息的时间长度的差值不大于阈值,调整的具体含义可以为压缩或拉伸语音信息的时间长度或/和动作信息的时间长度,也可以是加快播放速度或者减缓播放速度,例如将语音信息的播放速度乘以2,或者将动作信息的播放时间乘以0.8等等。
例如,语音信息的时间长度与动作信息的时间长度的阈值是一分钟,机器人根据用户的多模态信息生成的交互内容中,语音信息的时间长度是1分钟,动作信息的时间长度是2分钟,那么就可以将动作信息的播放速度加快,为原来播放速度的两倍,那么动作信息调整后的播放时间就会为1分钟,从而与语音信息进行同步。当然,也可以让语音信息的播放速度减缓,调整为原来播放速度的0.5倍,这样就会让语音信息经过调整后减缓为2分钟,从而与动作信息同步。另外,也可以将语音信息和动作信息都调整,例如语音信息减缓,同时将动作信息加快,都调整到1分30秒,也可以让语音和动作进行同步。
此外,本实施例中,所述将语音信息的时间长度和动作信息的时间长度调整到相同的具体步骤包括:
若语音信息的时间长度与动作信息的时间长度的差值大于阈值,当语音信息的时间长度大于动作信息的时间长度时,则将至少两组动作信息进行排序组合,使组合后的动作信息的时间长度等于所述语音信息的时间长度。
当语音信息的时间长度小于动作信息的时间长度时,则选取动作信息中的部分动作,使选取的部分动作的时间长度等于所述语音信息的时间长度。
因此,当语音信息的时间长度与动作信息的时间长度的差值大于阈值,调整的含义就是添加或者删除部分动作信息,以使动作信息的时间长度与语音信息的时间长度相同。
例如,语音信息的时间长度与动作信息的时间长度的阈值是30秒,机器人根据用户的多模态信息生成的交互内容中,语音信息的时间长度是3分钟,动作信息的时间长度是1分钟,那么就需要将其他的动作信息也加入到原本的动作信息中,例如找到一个时间长度为2分钟的动作信息,将上述两组动作信息进行排序组合后就与语音信息的时间长度匹配到相同了。当然,如果没有找到时间长度为2分钟的动作信息,而找到了一个时间长度为了2分半的,那么就可以选取这个2分半的动作信息中的部分动作(可以是部分帧),使选取后的动作信息的时间长度为2分钟,这样就可以语音信息的时间长度匹配相同了。
本实施例中,可以根据语音信息的时间长度,选择与语音信息的时间长度最接近的动作信息,也可以根据动作信息的时间长度选择最接近的语音信息。
这样在选择的时候根据语音信息的时间长度进行选择,可以方便控制模块对语音信息和动作信息的时间长度的调整,更加容易调整到一致,而且调整后的播放更加自然,平滑。
根据其中一个示例,在将语音信息的时间长度和动作信息的时间长度调整到相同的步骤之后还包括:将调整后的语音信息和动作信息输出到虚拟影像进行展示。
这样就可以在调整一致后进行输出,输出可以是在虚拟影像上进行输出,从而使虚拟机器人更加拟人化,提高用户体验度。
根据其中一个示例,所述机器人的生活时间轴的参数的生成方法包括:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人的生活时间轴。
这样将生活时间轴加入到机器人本身的自我认知中去,使机器人具有拟人化的生活。例如将中午吃饭的认知加入到机器人中去。
根据其中另一个示例,所述将机器人的自我认知进行扩展的步骤具体包括:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。
这样就可以具体的将生活时间轴加入到机器人本身的参数中去。
根据其中另一个示例,所述对机器人的自我认知的参数与生活时间轴中的参数进行拟合的步骤具体包括:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。这样就可以具体的将机器人的自我认知的参数与生活时间轴中的参数进行拟合。其中概率算法可以是贝叶斯概率算法。
例如,在一天24小时中,使机器人会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。每个动作会影响机器人本身的自我认知,将生活时间轴上的参数与机器人本身的自我认知进行结合,拟合后,即让机器人的自我认知包括了,心情,疲劳值,亲密度,好感度,交互次数,机器人的三维的认知,年龄,身高,体重,亲密度,游戏场景值,游戏对象值,地点场景值,地点对象值等。为机器人可以自己识别所在的地点场景,比如咖啡厅,卧室等。
机器一天的时间轴内会进行不同的动作,比如夜里睡觉,中午吃饭,白天运动等等,这些所有的生活时间轴中的场景,对于自我认知都会有影响。这些数值的变化采用的概率模型的动态拟合方式,将这些所有动作在时间轴上发生的几率拟合出来。场景识别:这种地点场景识别会改变自我认知中的地理场景值。
实施例二
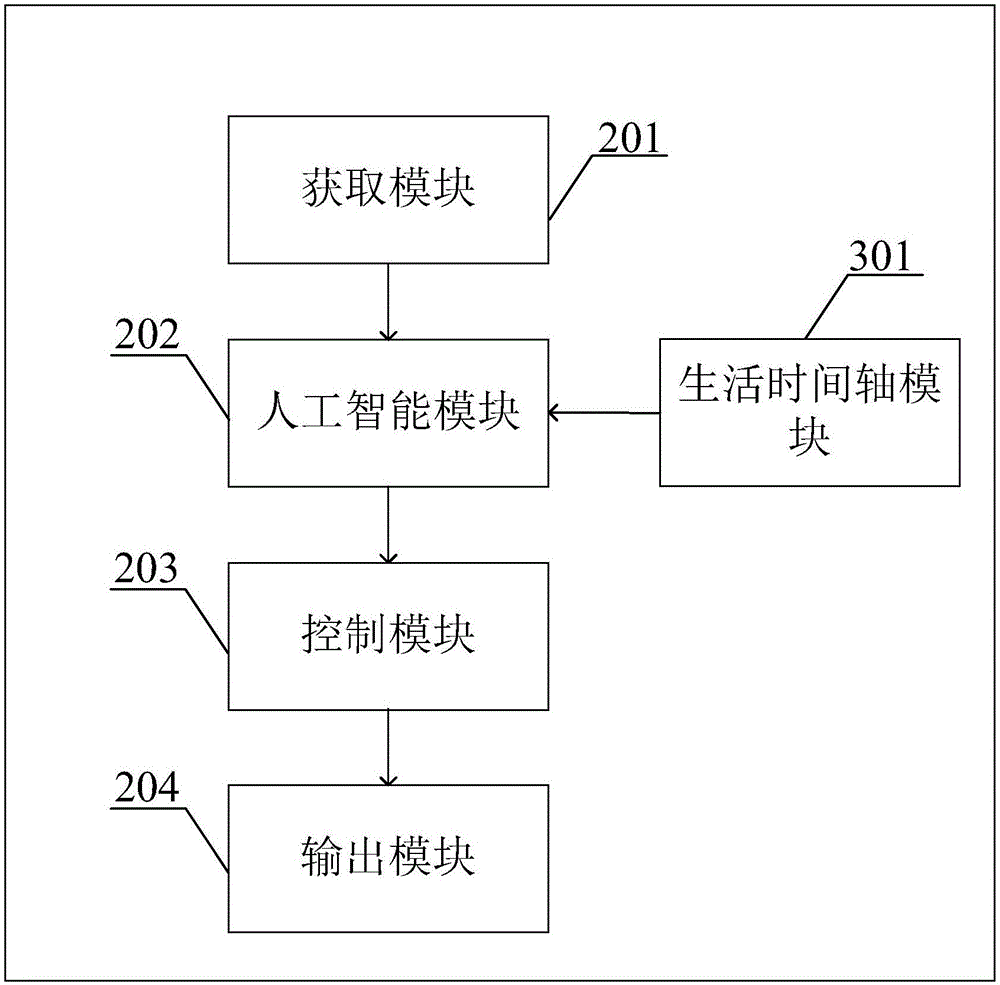
如图2所示,本实施例中公开一种同步语音及虚拟动作的系统,包括:
获取模块201,用于获取用户的多模态信息;
人工智能模块202,用于根据用户的多模态信息和生活时间轴生成交互内容,所述交互内容至少包括语音信息和动作信息,其中生活时间轴由生活时间轴模块301生成;
控制模块203,用于将语音信息的时间长度和动作信息的时间长度调整到相同。
这样就可以通过用户的多模态信息例如用户语音、用户表情、用户动作等的一种或几种,来生成交互内容,交互内容中至少包括语音信息和动作信息,而为了让语音信息和动作信息能够同步,将语音信息的时间长度和动作信息的时间长度调整到相同,这样就可以让机器人在播放声音和动作时可以同步匹配,使机器人在交互时不仅具有语音表现,还可以具有动作等多样的表现形式,机器人的表现形式更加多样化,使机器人更加拟人化,也提高了用户于机器人交互时的体验度。
对于人来讲每天的生活都具有一定的规律性,为了让机器人与人沟通时更加拟人化,在一天24小时中,让机器人也会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。因此本发明将机器人所在的生活时间轴加入到机器人的交互内容生成中去,使机器人与人交互时更加拟人化,使得机器人在生活时间轴内具有人类的生活方式,该方法能够提升机器人交互内容生成的拟人性,提升人机交互体验,提高智能性。交互内容可以是表情或文字或语音或动作等一种或几种的组合。机器人的生活时间轴300是提前进行拟合和设置完成的,具体来讲,机器人的生活时间轴300是一系列的参数合集,将这个参数传输给系统进行生成交互内容。
本实施例中的多模态信息可以是用户表情、语音信息、手势信息、场景信息、图像信息、视频信息、人脸信息、瞳孔虹膜信息、光感信息和指纹信息等其中的其中一种或几种。
本实施例中,基于生活时间轴具体是:根据人类日常生活的时间轴,按照人类的方式,将机器人本身在日常生活时间轴中的自我认知的数值做拟合,机器人的行为按照这个拟合行动,也就是得到一天中机器人自己的行为,从而让机器人基于生活时间轴去进行自己的行为,例如生成交互内容与人类沟通等。假如机器人一直唤醒的话,就会按照这个时间轴上的行为行动,机器人的自我认知也会根据这个时间轴进行相应的更改。生活时间轴与可变参数可以对自我认知中的属性,例如心情值,疲劳值等等的更改,也可以自动加入新的自我认知信息,比如之前没有愤怒值,基于生活时间轴和可变因素的场景就会自动根据之前模拟人类自我认知的场景,从而对机器人的自我认知进行添加。生活时间轴中不仅包括语音信息,也包括了动作等信息。
例如,用户向机器人说话:“好困啊”,机器人听到后理解的为用户很困,然后结合机器人的生活时间轴,例如当前的时间为上午9点,那么机器人就知道主人是刚刚起床,那么就应该向主人问早,例如回答语音“早上好”作为回复,还可以唱一首歌,并配上相应舞蹈动作等。而如果用户向机器人说话:“好困啊”,机器人听到后理解的为用户很困,然后机器人的生活时间轴,例如当前的时间为晚上9点,那么机器人就知道主人需要睡觉了,那么就会回复语音“主人晚安,睡个好觉”等类似用语,并配上相应的晚安、睡眠动作等。这种方式要比单纯的语音和表情回复更加贴近人的生活,具有动作更加拟人化。
本实施例中,所述控制模块具体用于:
若语音信息的时间长度与动作信息的时间长度的差值不大于阈值,当语音信息的时间长度小于动作信息的时间长度,则加快动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
当语音信息的时间长度大于动作信息的时间长度,则加快语音信息的播放速度或/和减缓动作信息的播放速度,使动作信息的时间长度等于所述语音信息的时间长度。
因此,当语音信息的时间长度与动作信息的时间长度的差值不大于阈值,调整的具体含义可以压缩或拉伸语音信息的时间长度或/和动作信息的时间长度,也可以是加快播放速度或者减缓播放速度,例如将语音信息的播放速度乘以2,或者将动作信息的播放时间乘以0.8等等。
例如,语音信息的时间长度与动作信息的时间长度的阈值是一分钟,机器人根据用户的多模态信息生成的交互内容中,语音信息的时间长度是1分钟,动作信息的时间长度是2分钟,那么就可以将动作信息的播放速度加快,为原来播放速度的两倍,那么动作信息调整后的播放时间就会为1分钟,从而与语音信息进行同步。当然,也可以让语音信息的播放速度减缓,调整为原来播放速度的0.5倍,这样就会让语音信息经过调整后减缓为2分钟,从而与动作信息同步。另外,也可以将语音信息和动作信息都调整,例如语音信息减缓,同时将动作信息加快,都调整到1分30秒,也可以让语音和动作进行同步。
此外,本实施例中,所述控制模块具体用于:
若语音信息的时间长度与动作信息的时间长度的差值大于阈值,当语音信息的时间长度大于动作信息的时间长度时,则将至少两组动作信息进行组合,使组合后的动作信息的时间长度等于所述语音信息的时间长度。
当语音信息的时间长度小于动作信息的时间长度时,则选取动作信息中的部分动作,使选取的部分动作的时间长度等于所述语音信息的时间长度。
因此,当语音信息的时间长度与动作信息的时间长度的差值大于阈值,调整的含义就是添加或者删除部分动作信息,以使动作信息的时间长度与语音信息的时间长度相同。
例如,语音信息的时间长度与动作信息的时间长度的阈值是30秒,机器人根据用户的多模态信息生成的交互内容中,语音信息的时间长度是3分钟,动作信息的时间长度是1分钟,那么就需要将其他的动作信息也加入到原本的动作信息中,例如找到一个时间长度为2分钟的动作信息,将上述两组动作信息进行排序组合后就与语音信息的时间长度匹配到相同了。当然,如果没有找到时间长度为2分钟的动作信息,而找到了一个时间长度为了2分半的,那么就可以选取这个2分半的动作信息中的部分动作(可以是部分帧),使选取后的动作信息的时间长度为2分钟,这样就可以语音信息的时间长度匹配相同了。
本实施例中,可以为所述人工智能模块具体用于:根据语音信息的时间长度,选择与语音信息的时间长度最接近的动作信息,也可以根据动作信息的时间长度选择最接近的语音信息。
这样在选择的时候根据语音信息的时间长度进行选择,可以方便控制模块对语音信息和动作信息的时间长度的调整,更加容易调整到一致,而且调整后的播放更加自然,平滑。
根据其中一个示例,所述系统还包括输出模块204,用于将调整后的语音信息和动作信息输出到虚拟影像进行展示。
这样就可以在调整一致后进行输出,输出可以是在虚拟影像上进行输出,从而使虚拟机器人更加拟人化,提高用户体验度。
根据其中一个示例,所述系统包括基于时间轴与人工智能云处理模块,用于:
将机器人的自我认知进行扩展;
获取生活时间轴的参数;
对机器人的自我认知的参数与生活时间轴中的参数进行拟合,生成机器人生活时间轴。
这样将生活时间轴加入到机器人本身的自我认知中去,使机器人具有拟人化的生活。例如将中午吃饭的认知加入到机器人中去。
根据其中另一个示例,所述基于时间轴与人工智能云处理模块具体用于:将生活场景与机器人的自我认识相结合形成基于生活时间轴的自我认知曲线。这样就可以具体的将生活时间轴加入到机器人本身的参数中去。
根据其中另一个示例,所述基于时间轴与人工智能云处理模块具体用于:使用概率算法,计算生活时间轴上的机器人在时间轴场景参数改变后的每个参数改变的概率,形成拟合曲线。这样就可以具体的将机器人的自我认知的参数与生活时间轴中的参数进行拟合。其中概率算法可以是贝叶斯概率算法。
例如,在一天24小时中,使机器人会有睡觉,运动,吃饭,跳舞,看书,吃饭,化妆,睡觉等动作。每个动作会影响机器人本身的自我认知,将生活时间轴上的参数与机器人本身的自我认知进行结合,拟合后,即让机器人的自我认知包括了,心情,疲劳值,亲密度,好感度,交互次数,机器人的三维的认知,年龄,身高,体重,亲密度,游戏场景值,游戏对象值,地点场景值,地点对象值等。为机器人可以自己识别所在的地点场景,比如咖啡厅,卧室等。
机器一天的时间轴内会进行不同的动作,比如夜里睡觉,中午吃饭,白天运动等等,这些所有的生活时间轴中的场景,对于自我认知都会有影响。这些数值的变化采用的概率模型的动态拟合方式,将这些所有动作在时间轴上发生的几率拟合出来。场景识别:这种地点场景识别会改变自我认知中的地理场景值。
本发明公开一种机器人,包括如上述任一所述的一种同步语音及虚拟动作的系统。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!