一种基于声管的语音合成方法与流程
本发明涉及一种语音合成方法。特别是涉及一种考虑噪声源模型和流体动压的基于声管的语音合成方法。
背景技术:
语音合成指利用电子计算机及一些专业装置来模拟人制造语音的技术,是当前人机语音交互的主要技术之一。现阶段,语音合成的研究还是集中到文字到语音的合成这一阶段,也就是tts合成系统。
语音合成主要被分成两种方法,就是参数合成法以及波形拼接法。经过多年的发展,衔接合成是目前主要的高质量语音合成方法。从长远来看,似乎最有前途的是发音语音合成,它不受任何基本的限制,并且超出纯文本-语音合成的应用程序。而基于声管的语音合成是基于发音机理的语音合成方法的重要组成部分。
关于人类声道的数学模型,一直以来就有两种说法:第一个观点是将声道看成是由多个横截面积不一样的声管串联而形成的声道系统,被叫作声管模型;而第二个观点是将声道看成一个谐振腔,腔体的谐振频率由共振峰表示,用该方法来描述声道的模型即为共振峰模型。本发明中采用的是第一种,也就是声管模型。
有不同的技术来模拟离散管中声波的传播模型。最常用的技术是基于波数字滤波器,或者基于传输线电路模型的直接数值模拟,或者是基于时域-频域的混合仿真系统模拟声道。每种方法都有其特有的优点和缺点。
技术实现要素:
本发明所要解决的技术问题是,提供一种不仅可以生成元音而且可以生成辅音,提高了生成元音准确度的基于声管的语音合成方法。
本发明所采用的技术方案是:一种基于声管的语音合成方法,包括如下步骤:
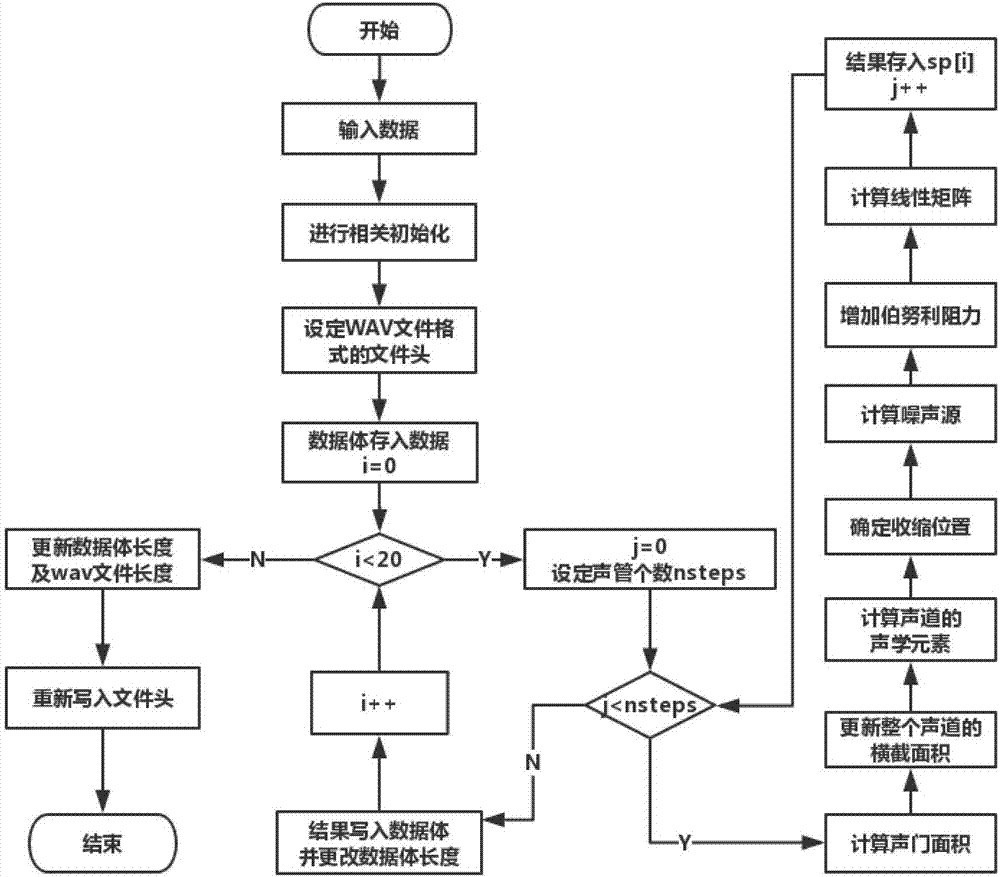
1)输入数据包括发音时所有对应位置声管的面积函数值及声管的长度值,进行相关初始化,并设定声管个数为500;
2)计算第n个声管的声学元素,所述的声学元素是传统输电线电路模型所需要的各个变量,n初始化为1,每循环一次,n加1;
3)确定声管的收缩位置,是分别确定声管的收缩入口及收缩出口,然后对所述的收缩入口及收缩出口求取平均值;
4)在确定声管的收缩位置的基础上确定磁单极子和偶极子源的位置,磁单极子放在收缩的最前部分,偶极子源放在一个具有代表性的障碍位置处,所述的具有代表性的障碍位置是由流动分离点与牙齿的距离来决定;
5)判断是否要激活噪声源,当收缩中雷诺数的平方re2大于一定的阈值
活噪声源,反之则不激活噪声源,其中re=vcdc/v是收缩中的雷诺数,
6)增加伯努利阻力,是将额外的阻力
其中,
7)重复步骤2)~步骤6),直至更新完成所有的声管,并将数据处理结果写入wave文件的数据体,更新数据体长度;
8)重复步骤2)~步骤7),更新wave文件长度和wave文件的数据头,得到最终的wave文件。
步骤1)所述的初始化包括:设定声道上牙齿的位置和声门面积,根据输入的数据加载声道的初始化形状,以及设置wave文件头格式。
步骤2)所述的传统输电线电路模型所需要的各个变量包括:收缩部位的体积速度源、压力源及动态压降,非刚性壁声道内的压强p和体积速度v,声管内声压的振幅和力学阻力,声门末端及口腔出口的边界压强和体积速度,以及计算阻力时的粘滞系数。
步骤4)所述的磁单极子是收缩出口的体积速度源,所述的偶极子源是气流源击中一个障碍物或者击中声管表面部分时的压力源。
步骤4)所述的流动分离点是声管内气流流动分离的地方。
步骤5)所述的,re=vcdc/v式中,vc是收缩中最窄声管部分的速度,dc是声管的直径,v是运动粘度。
本发明的一种基于声管的语音合成方法,在传统输电线模型的基础上增加噪声源和采用考虑到流体动压的方法从而形成新的声道模型,完善了现有的声管模型,比现有的模型生成元音的准确度更高并且可以生成辅音。本发明的方法没有限制每个管部分的长度,完善现有的元音的声管模型,使得模型不仅可以生成元音而且可以生成辅音,提高了生成元音的准确度,并有效的避免了声伪像;对推进语音合成在更广泛的领域的应用提供了极大的帮助。
附图说明
图1是本发明一种基于声管的语音合成方法的流程图;
图2是本发明中声道模型中每个声管的二端口电路图;
图3是本发明中一个实例元音/e/的频谱图;
图4是本发明中一个实例辅音/s/的频谱图。
具体实施方式
下面结合实施例和附图对本发明的一种基于声管的语音合成方法做出详细说明。
本发明的一种基于声管的语音合成方法,将基于核磁共振(mri)数据,采用时域模拟方法,用传输线电路tlm来模拟声道,并加入了噪声源模型。模型中,控制声波生成和传播的声波方程通过应用一定的规则转化为离散变量,并在基于一个更现实的对流体动压变化的分布式考虑的基础上进行改进,同时考虑声道的分支将三个不同的稀疏矩阵运用数学方法合并成单一矩阵,以此来完善现有的元音的声管模型。
辅音与元音的不同之处主要有两点,一是计算辅音的时候需要在进行相关初始化之前设定牙齿的位置;另外一个就是在计算数据体的时候不需要计算声门的面积,因为计算辅音的时候声门的面积是一个常数。这两点是在辅音研究的实施例中需要自己手动进行的修改,并且这些都是由于声道在发元音及辅音的时候的不同生理机理而导致在研究中所需要做出的改变。
在得到wav文件之后,对wav文件通过不同的技术处理,得到对应声音文件的面积函数图,波形图及频谱图,主要通过比较这些声音的频谱图与实际发音得到的频谱图来判断结果的准确度。
如图1所示,本发明的一种基于声管的语音合成方法,包括如下步骤:
1)输入数据包括发音时所有对应位置声管的面积函数值及声管的长度值,进行相关初始化,并设定声管个数为500;所述的初始化包括:设定声道上牙齿的位置和声门面积,根据输入的数据加载声道的初始化形状,以及设置wave文件头格式。
2)计算第n个声管的声学元素,所述的声学元素是传统输电线电路模型所需要的各个变量,n初始化为1,每循环一次,n加1;所述的传统输电线电路模型所需要的各个变量包括:收缩部位的体积速度源、压力源及动态压降,非刚性壁声道内的压强p和体积速度v,声管内声压的振幅和力学阻力,声门末端及口腔出口的边界压强和体积速度,以及计算阻力时的粘滞系数。
3)确定声管的收缩位置,计算噪声源的第一步需要确定收缩位置,本发明在确定收缩位置时,是分别确定声管的收缩入口及收缩出口,然后对所述的收缩入口及收缩出口求取平均值;
4)在确定声管的收缩位置的基础上确定磁单极子和偶极子源的位置,磁单极子放在收缩的最前部分,偶极子源放在一个具有代表性的障碍位置处,所述的具有代表性的障碍位置是由流动分离点与牙齿的距离来决定;其中,所述的磁单极子是收缩出口的体积速度源,所述的偶极子源是气流源击中一个障碍物或者击中声管表面部分时的压力源。所述的流动分离点是声管内气流流动分离的地方。
磁单极子总是放在收缩的最前部分,即假定流动分离的地方。偶极子源总是放在一个具有代表性的障碍位置。当流动分离点(fsp)距离牙齿小于4cm时,偶极子源就放在牙齿处,因为,这是用来发齿槽音和后齿龈音的。相反,当将声道墙作为障碍物,对于软腭音的摩擦音,它被放置在fsp下游0.5cm的地方。当fsp的牙齿处或牙齿下游时,偶极子源放置在嘴唇的地方。
5)判断是否要激活噪声源,当收缩中雷诺数的平方re2大于一定的阈值
6)增加伯努利阻力,是将额外的阻力
其中,
从而使得整个声管模型可以用统一的二端口网络图来表示,如图2所示,而,整个声道模型是由多个图2所示的二端口网络串联组成。同时这个方法还可以预防由于收缩位置改变造成的声伪像;
7)重复步骤2)~步骤6),直至更新完成所有的声管,并将数据处理结果写入wave文件的数据体,更新数据体长度;
8)重复步骤2)~步骤7),更新wave文件长度和wave文件的数据头,得到最终的wave文件。
本发明实例中采用了5个元音及6个摩擦音,摩擦音数据的面积函数初始化为40个离散值,牙齿的位置随着不同的发音而发生变化;元音数据的面积函数初始化为70左右的不同数量的管。
在得到wav文件之后,使用praat软件生成对应的波形图与频谱图,然后与实际发音的频谱图来比较,从而判断模型的准确度。
实验结果表明,本实例使用的5个元音的发音结果准确度都比较高,频谱与实际的发音频谱很相似,即使是最直接的人耳听起来也不会有太大的差别。这是一个令人满意的结果。本实例在改进传统输电线之后可以生成辅音,只是在本实例使用的六个辅音中,只有四个辅音发音结果准确度比较高,还有两个准确度相对来讲要差一些,准确度较高的频谱图与实际发音的频谱图整体都比较一致,而另外两个相比实际发音会出现些许偏差。结果示意图见图3、图4。图3显示的是元音中结果准确度较高的音/e/的频谱图,图4显示的是摩擦音中结果准确度比较高的音/s/的频谱图。
本实例在传统输电线模型的基础上增加噪声源和采用考虑到流体动压的方法从而形成新的声道模型,比现有的模型生成元音的准确度更高并且可以生成辅音。
- 还没有人留言评论。精彩留言会获得点赞!