一种用于智能设备的语音交互方法及语音控制系统与流程
本发明涉及智能设备的语音控制领域,尤其涉及一种用于智能设备的语音交互方法及语音控制系统。
背景技术:
语音控制技术在多类智能终端设备上都已经广泛配备。目前,用户与设备间的语音交互方式多为两段式交互,即包括唤醒交互和内容交互。如苹果手机的“siri”,用户需要对手机麦克风说出预先设定的唤醒词—“hey,siri!”,随后系统进入siri交互界面,聆听用户的语音指令内容。
这样的交互方式存在以下问题:(1)用户需要先说出对应语音控制系统的唤醒词,等待系统进入内容交互状态,使得用户需要在间隔时间前后说出两段语音才能将命令传递给语音控制系统,不够智能;(2)市面上不同类设备间存在多种不同唤醒词,如安卓类手机的唤醒词为“ok,google!”,加剧了语音控制领域的接口分化现象,以及增加了用户学习成本,不利于标准整合;(3)在嘈杂环境或多人语音环境,系统难以分清用户是否说了唤醒词,导致出现语音系统无法唤醒或误唤醒的情况。
技术实现要素:
本发明的目的在于提供一种智能、高效语音控制方案,在该方案下,用户可以免去需要先说出特定唤醒词的步骤,解决了上述技术问题。
为实现上述目的,本发明的第一方面提供了一种用于智能设备的语音交互方法,包括以下步骤:
步骤s1:接收语音输入,识别该语音输入的语音内容;
步骤s2:提取上述语音输入的声学特征参数,并据其判别该次输入的语音是否构成增益音源;若判别为构成增益音源,则执行s3;
步骤s3:直接执行与所述语音内容相应的语音指令。
一实施例中:在执行步骤s1的同时还执行了步骤a1:采集设备所处的任务场景;
在执行步骤s1与步骤a1之后,执行步骤s3之前,还执行以下步骤:
步骤a2:判别所述语音内容是否与上述任务场景相匹配;
若步骤s2与步骤a2的判别结果均为肯定,则执行步骤s3。
一实施例中:所述步骤a2在步骤s2之前执行,若步骤a2的判别结果为肯定,则执行步骤s2。
一实施例中:所述步骤s2包括如下步骤:
步骤s21:构件音源的特征参数库,该特征参数库包含了预设的能构成增益音源的声学特征参数的有效范围;
步骤s22:提取语音输入中的人声片段,并从中提取其声学特征参数;
步骤s23:比对提取出的声学特征参数是否在上述特征参数库的有效范围内,若在范围内,则判定为该次输入的语音构成增益音源,否则,判别为不构成。
一实施例中:所述增益音源包含音量增益音源和/或正交增益音源;
当所述增益音源为正交增益音源时,对应的声学特征参数为音源相对于设备的语音输入装置的输入角度;
当所述增益音源为音量增益音源时,对应的声学特征参数为音源的音量。
一实施例中:设备的语音输入装置为麦克风;
在所述设备上设有多个麦克风,以组成麦克风阵列,当麦克风阵列接收语音输入时,通过对语音进行取样、处理、计算等过程,获取输入音源相对于设备的语音输入装置麦克风阵列的输入角度。
一实施例中:所述步骤a1中的任务场景对应于设备所需处理的任务;
所述步骤a1包括如下步骤:
步骤a11:对设备所需处理的任务分配对应的场景标识符,构建场景标识库;
步骤a12:当设备启动某一任务时,输出对应该任务的场景标识符;
步骤a13:识别所述场景标识符。
一实施例中:所述步骤a2包括如下步骤:
步骤a21:构建语音指令集,该语音指令集为对应各任务场景下的可用的语音指令的集合;
步骤a22:将语音输入转化为设备可读形式的语音内容,并将该可读形式的语音内容转化与上述语音指令格式相同的假拟语音指令;
步骤a23:提取步骤a1中识别出的任务场景下的所有可用的语音指令,采用步骤a22中得到的假拟语音指令与上述可用的语音指令逐一比对;
步骤a24:若假拟语音指令覆盖了某一该任务场景下可用的语音指令,则结束比对,并判别为语音内容与任务场景相匹配,否则,判别为不匹配。
为实现上述目的,本发明的第二方面提供了一种用于智能设备的语音控制系统,包括:语音输入设备、微处理器;
所述微处理器内置有增益音源判别单元、指令执行单元以及内容识别单元;所述内容识别单元连接语音输入设备以识别语音输入的内容;
所述增益音源判别单元连接语音输入设备,并能提取语音输入的声学特征参数,以判别输入的语音是否构成增益音源;
所述指令执行单元分别连接到内容识别单元以及增益音源判别单元,当增益音源判别单元的判别结果为肯定时,所述指令执行单元执行对应所述语音内容应的语音指令。
一实施例中:还包括存储装置,所述存储装置储存有特征参数库,所述特征参数库包含了预设的能构成增益音源的声学特征参数的有效范围;
所述增益音源判别单元连接所述特征参数库,并比对所述提取出的声学特征参数是否在上述特征参数库的有效范围内。
一实施例中:所述增益音源包含音量增益音源和/或正交增益音源;当所述增益音源为正交增益音源时,对应的声学特征参数为音源相对于设备的语音输入装置的输入角度;当所述增益音源为音量增益音源时,对应的声学特征参数为音源的音量。
一实施例中:所述语音输入设备为多个麦克风,并组成麦克风阵列;
当麦克风阵列接收语音输入时,通过对语音进行取样、处理、计算等过程,获取输入音源相对于设备的语音输入装置麦克风阵列的输入角度,并将其输出至所述增益音源判别单元;
所述增益音源判别单元还包括音量检测单元,以检测语音输入的音量大小。
一实施例中:所述微处理器还内置有场景匹配单元,该场景匹配单元连接内容识别单元,以判别语音内容是否与设备所处的任务场景相匹配;
所述指令执行单元还连接到所述场景匹配单元,当场景匹配单元及增益音源判别单元的判别结果均为肯定时,所述指令执行单元执行对应所述语音内容应的语音指令。
一实施例中:还包括存储装置,所述存储装置储存有场景标识库、语音指令集;
所述场景标识库包含了与设备所需处理的任务分配对应的场景标识符;所述语音指令集为对应各场景标识符的可用的语音指令的集合。
一实施例中:微处理器还包括任务处理单元,用于处理设备的各项任务,其连接到所述存储装置的场景标识库和场景匹配单元;在设备启动某一任务时,所述任务处理单元向场景匹配单元输出对应该任务的场景标识符。
一实施例中:所述场景匹配单元连接所述存储装置的语音指令集,在场景匹配单元接收所述场景标识符后,所述场景匹配单元依据该场景标识符提取对应该任务场景下的所有可用的语音指令;
所述内容识别单元将语音输入转化为与上述语音指令格式相同的假拟语音指令,并将其输出至场景匹配单元,场景匹配单元将所述假拟语音指令与上述可用的语音指令逐一比对,以判别语音内容是否与设备所处的任务场景相匹配。
相较于现有技术,本发明具有以下优势:
本发明提供的语音交互方法和语音控制系统,主要基于设备所处的任务场景作为是否执行的条件之一,此外还需考虑到语音输入的音源需要构成增益音源,当两者均满足条件时,意味着所述任务场景使得用户是否在该场景下说了合适的语音指令,用户是在该特定的场景下对设备说话,此时设备应当处理用户刚才所说的话对应的指令,因而,设备便直接执行用户语音输入的内容,用户无需多说一次唤醒词。
这样一来,不但实现了一种智能、高效的语音交互方式,避免了出现无法唤醒或误唤醒的情况,降低了用户学习和使用的成本,而且这种语音交互方式还能统一推广,有利于语音控制行业的资源整合。
附图说明
图1示出了实施例一中,语音交互方法的流程图;
图2示出了实施例二中,语音交互方法的流程图;
图3示出了实施例三中,语音交互方法的流程图;
图4示出了实施例四中,语音控制系统的的系统构成示意图;
图5示出了实施例五中,语音控制系统的的系统构成示意图;
图6示出了实施例六中,语音控制系统的的系统构成示意图。
具体实施方式
本发明提供了一种用于智能设备的语音交互方法及语音控制系统,以下结合附图和实施例对本发明作进一步的说明。值得说明的是,本发明所述的所述智能设备可以为手机、平板电脑、计算机、智能机器人等终端设备,但并不局限于此。
请先参照图1,其示出了实施例一中语音交互方法的流程图,该方法包括以下步骤:
步骤s1:接收语音输入,识别该语音输入的语音内容;
步骤s2:提取上述语音输入的声学特征参数,并据其判别该次输入的语音是否构成增益音源;若判别为构成增益音源,则执行s3;
步骤s3:直接执行与所述语音内容相应的语音指令。
所述的增益音源,其体现了用户对设备的关注度,当用户对设备关注度提高时,他对设备的语音输入就能构成增益音源,这意味着用户希望设备聆听他说话的内容,并对其进行处理,此时设备应当处理用户刚才所说的话对应的指令。关于所述代表用户关注度的增益音源的实施例,其原理可体现在下述的正交增益音源和音量增益音源。
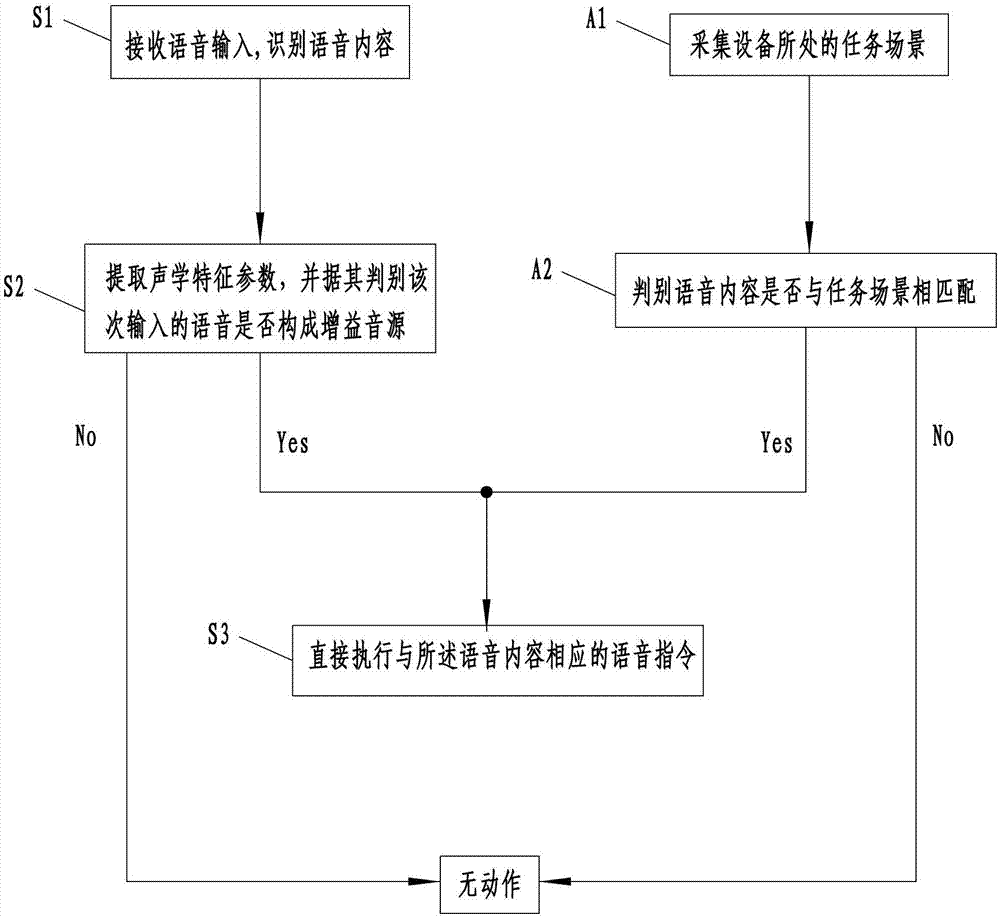
接下来请参照图2,其示出了实施例二中语音交互方法的流程图,实施例二相对于实施例一的区别在于,
在执行步骤s1的同时还执行了步骤a1:采集设备所处的任务场景;
在执行步骤s1与步骤a1之后,执行步骤s3之前,还执行以下步骤:
步骤a2:判别所述语音内容是否与上述任务场景相匹配;
若步骤s2与步骤a2的判别结果均为肯定,则执行步骤s3。
通过增加了步骤a1和a2,增加了基于设备所处的任务场景作为是否执行语音命令的判别条件之一。当增益音源判别和场景匹配均满足条件时,意味着用户是在合适的任务场景下对设备说了合适的语音指令,这样相对于实施例一,优化了系统处理和分析的流程,去除了不必要的冗余处理步骤,使得系统能够更加高效的运行。
接下来请参照图3,其示出了实施例三中语音交互方法的流程图,实施例二相对于实施例一的区别在于,实施例二的增益音源判别和场景匹配判别是并列进行的,而本实施例中,首先进行场景匹配的判别,只有当场景增益音源判别的结果为相匹配,才进行增益音源的判别。这样一来,使场景匹配判别优先于增益音源判别,简化了系统判别的流程,进一步优化系统流程。
即为:所述步骤a2在步骤s2之前执行,若步骤a2的判别结果为肯定,则执行步骤s2。
然而,本实施例中,将场景匹配判别的优先级优先于增益音源判别,这主要考虑到场景匹配判别的实际匹配度较高,其他实施例中,也可以将其反之而行,使增益音源判别优先于场景匹配判别。
上述实施例供了这样一种交互方式,该交互方式免去了现有技术的唤醒步骤,采用一段式的交互方式。它主要基于设备所处的任务场景作为是否执行的条件之一,此外还需考虑到语音输入的音源需要构成增益音源,当两者均满足条件时,意味着用户是在该特定的场景下对设备说话,设备便直接执行用户语音输入的内容,用户无需多说一次唤醒词。
具体的,对于所述步骤s2中如何判别输入的语音是否构成代表用户对设备关注度提升的增益音源,其包括如下步骤:
步骤s21:构件音源的特征参数库,该特征参数库包含了预设的能构成增益音源的声学特征参数的有效范围;
步骤s22:提取语音输入中的人声片段,并从中提取其声学特征参数;
步骤s23:比对提取出的声学特征参数是否在上述特征参数库的有效范围内,若在范围内,则判定为该次输入的语音构成增益音源,否则,判别为不构成。
优选的,即便在多人或嘈杂的环境,当用户希望对设备下达语音指令时,其对设备的关注度自然会提高,这可体现在他对设备说话的音量和角度上。具体方案中,所述增益音源包含音量增益音源和/或正交增益音源;当所述增益音源为正交增益音源时,对应的声学特征参数为音源相对于设备的语音输入装置的输入角度;当所述增益音源为音量增益音源时,对应的声学特征参数为音源的音量。本实施例中,增益音源的判别优选的为需要满足输入角度和音量两个方面,但其他实施例中,只满足一个方面即可。
优选的,设备的语音输入装置为麦克风;在所述设备上设有多个麦克风,以组成麦克风阵列,当麦克风阵列接收语音输入时,通过对语音进行取样、处理、计算等过程,获取输入音源相对于设备的语音输入装置麦克风阵列的输入角度。
此外,对于所述步骤a1中采集任务场景的方法,其具体包括如下步骤:
步骤a11:对设备所需处理的任务分配对应的场景标识符,构建场景标识库;
步骤a12:当设备启动某一任务时,输出对应该任务的场景标识符;
步骤a13:识别所述场景标识符。
而对于所述步骤a2中如何判别语音是否与场景相匹配,由如下步骤来实现:
步骤a21:构建语音指令集,该语音指令集为对应各任务场景下的可用的语音指令的集合;
步骤a22:将语音输入转化为设备可读形式的语音内容,并将该可读形式的语音内容转化与上述语音指令格式相同的假拟语音指令;
步骤a23:提取步骤a1中识别出的任务场景下的所有可用的语音指令,采用步骤a22中得到的假拟语音指令与上述可用的语音指令逐一比对;
步骤a24:若假拟语音指令覆盖了某一该任务场景下可用的语音指令,则结束比对,并判别为语音内容与任务场景相匹配,否则,判别为不匹配。
例如,当设备处于多媒体播放的任务场景,且用户说出“下一首”时,语音控制系统判断用户在该任务场景下说出了合适正确匹配的语音指令,便直接执行“下一首”的命令。
以下请参照图4-5,本发明的另一方面还提供了一种语音控制系统,其中图4示出了实施例四中的语音控制系统,其包括:语音输入设备、微处理器。
所述微处理器内置有增益音源判别单元、指令执行单元以及内容识别单元;所述内容识别单元连接语音输入设备以识别语音输入的内容;
所述增益音源判别单元连接语音输入设备,并能提取语音输入的声学特征参数,以判别输入的语音是否构成增益音源;
所述指令执行单元分别连接到内容识别单元以及增益音源判别单元,当增益音源判别单元的判别结果为肯定时,所述指令执行单元执行对应所述语音内容应的语音指令。
通过以上结构,构建了一种基于实施例一的音交互方法的语音控制系统,为其提供了硬件依托。通过在设备上装载本系统,使得用户对设备的语音交互更加智能化,高效化。
优选的,图5示出的实施例五中,语音控制系统还包括存储装置,所述存储装置储存有特征参数库,所述特征参数库包含了预设的能构成增益音源的声学特征参数的有效范围。
所述增益音源判别单元连接所述特征参数库,并比对所述提取出的声学特征参数是否在上述特征参数库的有效范围内。
具体的,所述增益音源包含音量增益音源和/或正交增益音源;当所述增益音源为正交增益音源时,对应的声学特征参数为音源相对于设备的语音输入装置的输入角度;当所述增益音源为音量增益音源时,对应的声学特征参数为音源的音量。
优选的,所述语音输入设备为多个麦克风,并组成麦克风阵列。当麦克风阵列接收语音输入时,通过对语音进行取样、处理、计算等过程,获取输入音源相对于设备的语音输入装置麦克风阵列的输入角度,并将其输出至所述增益音源判别单元。
进一步的,所述增益音源判别单元还包括音量检测单元,以检测语音输入的音量大小。
最后,请参照图6,其示出了实施例六中的语音控制系统,实施例六的系统对应于实施例二或实施例三的语音交互方法。该实施例相较于实施例五,所述微处理器还内置有场景匹配单元,该场景匹配单元连接内容识别单元,以判别语音内容是否与设备所处的任务场景相匹配。
此外,所述指令执行单元还连接到所述场景匹配单元,当场景匹配单元及增益音源判别单元的判别结果均为肯定时,所述指令执行单元执行对应所述语音内容应的语音指令。
本实施例中,所述存储装置储存有场景标识库、语音指令集、以及实施例五中所述的特征参数库。所述场景标识库包含了与设备所需处理的任务分配对应的场景标识符;所述语音指令集为对应各场景标识符的可用的语音指令的集合。
具体结构中,微处理器还包括任务处理单元,用于处理设备的各项任务,其连接到所述存储装置的场景标识库和场景匹配单元。在设备启动某一任务时,所述任务处理单元向场景匹配单元输出对应该任务的场景标识符。
所述场景匹配单元连接所述存储装置的语音指令集,在场景匹配单元接收所述场景标识符后,所述场景匹配单元依据该场景标识符提取对应该任务场景下的所有可用的语音指令。此外,所述内容识别单元将语音输入转化为与上述语音指令格式相同的假拟语音指令,并将其输出至场景匹配单元,场景匹配单元将所述假拟语音指令与上述可用的语音指令逐一比对,以判别语音内容是否与设备所处的任务场景相匹配。
这样,通过场景标识库、语音指令集、任务处理单元、内容识别单元的配合,使得场景匹配单元可判别语音输入的内容是否与设备所处的任务场景相匹配。再结合增益音源判别单元,使得指令执行单元根据场景匹配单元和增益音源判别单元的判别结果,选择是否执行用户命令。
以上所述仅为本发明的优选实施例,并非因此限制其专利范围,凡是利用本发明说明书及附图内容所作的等效结构变换,直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!