使用机器学习的音频重建方法和设备与流程
本公开涉及一种音频重建方法和设备,更具体地,涉及一种通过使用机器学习来重建从比特流获得的解码参数或音频信号来提供改进的声音质量的音频重建方法和设备。
背景技术:
已经开发了能够传输、再现和存储高质量音频内容的音频编解码器技术,并且当前的超高音质技术使得能够传输、再现和存储具有24比特/192khz分辨率的音频。24比特/192khz分辨率意味着以192khz采样原始音频,并且可以使用24比特以2^24种状态来表示采样信号。
然而,可能需要高带宽数据传输来传输高质量的音频内容。另外,高质量的音频内容具有较高的服务价格,并且需要高质量的音频编解码器,因此可能引起版权问题。此外,最近已经开始要提供高质量的音频服务,但是可能不存在以高质量记录的音频。因此,越来越需要用于将低质量音频重建为高质量的技术。为了将低质量的音频重建为高质量,可以使用人工智能(ai)。
ai系统是能够实现人类级别智能的计算机系统,并且是指与现有的基于规则的智能系统不同,机器可以自主地学习、判定和变得更加智能的系统。可以与ai系统的迭代成比例地提高识别率并且可以更准确地理解用户偏好,因此,现有的基于规则的智能系统正逐渐被基于深度学习的ai系统所取代。
ai技术包括机器学习(或深度学习)和使用机器学习的元素技术。机器学习是指用于对输入数据的特性进行自动分类/学习的算法技术,元素技术是指通过使用诸如深度学习之类的机器学习算法来模仿人脑功能(例如,识别和判定)的技术,包括语言理解、视觉理解、推理/预测、知识表示和操作控制等技术领域。
可应用ai技术的各个领域的示例如下所述。语言理解是指识别和应用/处理人类语言/字符的技术,包括自然语言处理、机器翻译、对话系统、查询和响应、语音识别/合成等。视觉理解是指像人类视觉一样识别和处理对象的技术,包括对象识别、对象跟踪、图像搜索、人类识别、场景理解、空间理解、图像增强等。推理/预测是指一种用于确定信息并在逻辑上进行推理和预测的技术,包括基于知识/概率的推理、优化预测、基于偏好的计划、推荐等。知识表示是指一种将人类经验信息自动处理为知识数据的技术,包括知识构造(数据生成/数据分类)、知识管理(数据利用)等。操作控制是指用于控制车辆的自主驾驶和机器人的运动的技术,并且包括运动控制(例如,导航、避免碰撞和驾驶控制)、操纵控制(例如,动作控制)等。
根据本公开,通过使用原始音频和音频编解码器的各种解码参数执行机器学习来获得重建的解码参数。根据本公开,可以使用重建的解码参数来重建更高质量的音频。
技术实现要素:
问题的解决方案
提供了一种通过使用机器学习来重建从比特流获得的解码参数或音频信号的方法和设备。
根据本公开的一方面,一种音频重建方法,所述方法包括:通过解码比特流获得当前帧的多个解码参数;基于所述多个解码参数中包括的第一参数,确定包括在所述多个解码参数中并与所述第一参数相关联的第二参数的特性;通过将机器学习模型应用于所述多个解码参数中的至少一个解码参数、第二参数和第二参数的特性来获得重建的第二参数;以及基于所述重建的第二参数解码音频信号。
解码所述音频信号可以包括:通过基于所述第二参数的特性对所述重建的第二参数进行校正,获得校正后的第二参数;以及基于所述校正后的第二参数解码所述音频信号。
确定所述第二参数的特性可以包括:基于所述第一参数确定所述第二参数的范围,以及其中,获得所述校正后的第二参数包括:当所述重建的第二参数不在所述范围内时,获得所述范围内的最接近所述重建的第二参数的值作为所述校正后的第二参数。
确定所述第二参数的特性可以包括:通过使用基于所述第一参数和所述第二参数中的至少一个预训练的机器学习模型来确定所述第二参数的特性。
获得所述重建的第二参数可以包括:基于所述第二参数的特性确定所述第二参数的多个候选;以及基于所述机器学习模型,选择所述第二参数的多个候选中的一个候选。
获得所述重建的第二参数可以包括:进一步基于前一帧的多个解码参数中的至少一个解码参数,获得所述当前帧的所述重建的第二参数。
所述机器学习模型可以是通过机器学习原始音频信号和所述多个解码参数中的至少一个解码参数来生成的。
根据本公开的另一方面,一种音频重建方法,所述方法包括:通过解码比特流获得当前帧的多个解码参数;基于所述多个解码参数解码音频信号;基于解码的音频信号和所述多个解码参数中的至少一个解码参数,从多个机器学习模型中选择一个机器学习模型;以及通过使用所选择的机器学习模型来重建所述解码的音频信号。
所述机器学习模型可以是通过机器学习所述解码的音频信号和原始音频信号来生成的
选择所述机器学习模型可以包括:基于所述多个解码参数中的至少一个解码参数,确定带宽扩展的起始频率;以及基于所述起始频率和所述解码的音频信号的频率,选择所述解码的音频信号的机器学习模型。
选择所述机器学习模型可以包括:基于所述多个解码参数中的至少一个解码参数,获得当前帧的增益;获取所述当前帧和与所述当前帧相邻的帧的增益的平均值;当所述当前帧的增益与所述增益的平均值之间的差大于阈值时,选择用于瞬态信号的机器学习模型;当所述当前帧的增益与所述增益的平均值之间的差小于所述阈值时,确定所述多个解码参数中包括的窗口类型是否指示为短;当所述窗口类型指示为短时,选择用于所述瞬态信号的所述机器学习模型;以及当所述窗口类型不指示为短时,选择用于稳态信号的机器学习模型。
根据本公开的另一方面,一种音频重建设备,所述设备包括:存储器,所述存储器存储接收到的比特流;以及至少一个处理器,所述至少一个处理器被配置为通过解码所述比特流来获得当前帧的多个解码参数,基于所述多个解码参数中包括的第一参数来确定包括在所述多个解码参数中并与所述第一参数相关联的第二参数的特性,通过将机器学习模型应用于所述多个解码参数中的至少一个解码参数、所述第二参数和所述第二参数的特性来获得重建的第二参数,并基于所述重建的第二参数来解码音频信号。
所述至少一个处理器可以进一步被配置为通过基于所述第二参数的特性校正所述重建的第二参数来获得校正后的第二参数,并基于所述校正后的第二参数解码音频信号。
所述至少一个处理器可以进一步被配置为通过使用基于所述第一参数和所述第二参数中的至少一个而预训练的机器学习模型来确定所述第二参数的特性。
所述至少一个处理器可以进一步被配置为通过基于所述第二参数的特性确定所述第二参数的多个候选并基于所述机器学习模型选择所述第二参数的所述多个候选中的一个候选来获得所述重建的第二参数。
所述至少一个处理器可以进一步被配置为进一步基于前一帧的多个解码参数中的至少一个解码参数来获得所述当前帧的所述重建的第二参数。
所述机器学习模型可以是通过机器学习原始音频信号和所述多个解码参数中的至少一个解码参数来生成的。
根据本公开的另一方面,一种音频重建设备,所述设备包括:存储器,所述存储器存储接收到的比特流;以及至少一个处理器,所述至少一个处理器被配置为通过解码所述比特流来获得当前帧的多个解码参数,基于所述多个解码参数解码音频信号,基于解码的音频信号和所述多个解码参数中的至少一个解码参数从多个机器学习模型中选择一个机器学习模型,以及通过使用所选择的机器学习模型来重建所述解码的音频信号。
根据本发明的另一个方面,一种在其上记录了用于执行上述方法的计算机程序的计算机可读记录媒体。
附图说明
图1是根据实施例的音频重建设备的框图。
图2是根据实施例的音频重建设备的框图。
图3是根据实施例的音频重建方法的流程图。
图4是用于描述根据实施例的机器学习的框图。
图5示出了根据实施例的解码参数的特性的预测。
图6示出了根据实施例的解码参数的特性的预测。
图7是根据实施例的音频重建方法的流程图。
图8示出了根据实施例的解码参数。
图9示出了根据实施例的解码参数的改变。
图10示出了根据实施例的在比特数增加的情况下解码参数的改变。
图11示出了根据实施例的解码参数的改变。
图12是根据实施例的音频重建设备的框图。
图13是根据实施例的音频重建方法的流程图。
图14是根据实施例的音频重建方法的流程图。
图15是根据实施例的音频重建方法的流程图。
具体实施方式
通过参考下面的详细描述和附图,可以更容易地理解本公开的一个或更多个实施例及其实现方法。然而,本公开可以以许多不同的形式来体现,并且不应被解释为限于这里阐述的实施例;相反,提供这些实施例是为了使本公开透彻和完整,并将本公开的概念充分传达给本领域的普通技术人员。
现在将在详细描述本公开之前简要描述本说明书中使用的术语。
尽管在考虑到根据本公开获得的功能的同时,从当前广泛使用的通用术语中尽可能多地选择了本文中使用的术语,但是基于本领域普通技术、习俗、新技术的兴起中的一种的目的,这些术语可以由其他术语代替。在特定情况下,可以使用由申请人任意选择的术语,并且在这种情况下,可以在本公开的相关部分中描述这些术语的含义。因此,应当注意,本文中使用的术语是基于其实际含义和本说明书的全部内容来解释的,而不是仅基于术语的名称来解释的。
如本文中所使用的,单数形式的“一个”、“一种”和“该”也旨在包括复数形式,除非上下文另外明确指出。另外,除非上下文另外明确指出,否则复数形式也旨在包括单数形式。
将理解的是,当在本文中使用时,术语“包括”、“包括……”、“包含”和/或“包含……”指定存在所述元件,但是不排除一个或更多个其他元件的存在或增加。
如本文所使用的,术语“单元”表示软件或硬件元件并且执行特定功能。但是,“单元”不限于软件或硬件。该“单元”可以形成为位于可寻址存储介质中,或者可以形成为操作一个或更多个处理器。因此,例如,“单元”可以包括元件(例如,软件元件、面向对象的软件元件、类元件和任务元件)、过程、功能、属性、程序、子例程、程序代码段、驱动程序、固件、微代码、电路、数据、数据库、数据结构、表格、数组或变量。由元件和“单元”提供的功能可以被组合为较少数量的元件和“单元”,或者可以被划分为额外的元件和“单元”。
根据本公开的实施例,“单元”可以被实现为处理器和存储器。术语“处理器”应该广义地解释为涵盖通用处理器、中央处理器(cpu)、微处理器、数字信号处理器(dsp)、控制器、微控制器、状态机等。在某些情况下,“处理器”可以指代专用集成电路(asic)、可编程逻辑器件(pld)、现场可编程门阵列(fpga)等。术语“处理器”可以指处理设备的组合,例如dsp和微处理器的组合、多个微处理器的组合、一个或更多个微处理器与dsp内核结合的组合,或任何其他此类配置的组合。
术语“存储器”应该被广义地解释为涵盖能够存储电子信息的任何电子组件。术语存储器可以指各种类型的处理器可读介质,例如随机存取存储器(ram)、只读存储器(rom)、非易失性随机存取存储器(nvram)、可编程只读存储器(prom)、可擦除可编程只读存储器(eprom)、电可擦除prom(eeprom)、闪存、磁或光数据存储以及寄存器。当处理器可以从存储器读取信息和/或在存储器上记录信息时,存储器被称为与处理器电子通信。与处理器集成的存储器与处理器进行电子通信。
在下文中,将通过参考附图解释本公开的实施例来详细描述本公开。在附图中,为了解释清楚,未示出与本公开的实施例无关的部分。
高质量音频内容需要高昂的服务价格和高质量音频编解码器,因此可能引起版权问题。此外,最近已经开始高质量音频服务,然而可能不存在以高质量记录的音频。因此,越来越需要用于将以低质量编码的音频重建为高质量的技术。可用于将以低质量编码的音频重建为高质量的方法之一是使用机器学习的方法。现在将参考图1至图15描述通过使用编解码器的解码参数和机器学习来改进解码音频的质量的方法。
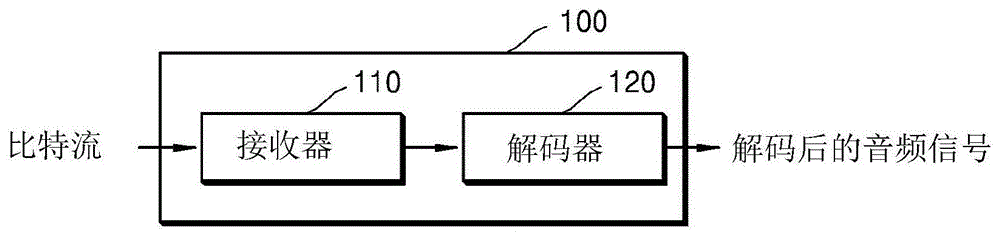
图1是根据实施例的音频重建设备100的框图。
音频重建设备100可以包括接收器110和解码器120。接收器110可以接收比特流。解码器120可以输出基于接收到的比特流而解码的音频信号。现在将参考图2详细描述音频重建设备100。
图2是根据实施例的音频重建设备100的框图。
音频重建设备100可以包括编解码器信息提取器210和至少一个解码器。编解码器信息提取器210可以等同地对应于图1的接收器110。至少一个解码器可以包括第一解码器221、第二解码器222和第n解码器223中的至少一个。第一解码器221、第二解码器222和第n解码器223中的至少一个可以等同地对应于图1的解码器120。
编解码器信息提取器210可以接收比特流。比特流可以由编码设备生成。编码设备可以将原始音频编码并压缩到比特流中。编解码器信息提取器210可以通过有线或无线通信从编码设备或存储介质接收比特流。编解码器信息提取器210可以将比特流存储在存储器中。编解码器信息提取器210可以从比特流中提取各种类型的信息。各种类型的信息可以包括编解码器信息。编解码器信息可以包括关于用于编码原始音频的技术的信息。用于编码原始音频的技术可以包括例如mpeglayer-3(mp3)、高级音频编码(aac)或高效aac(he-aac)技术。编解码器信息提取器210可以基于编解码器信息从至少一个解码器中选择解码器。
至少一个解码器可以包括第一解码器221、第二解码器222和第n解码器223。由编解码器信息提取器210从至少一个解码器中选择的解码器可以基于比特流解码音频信号。为了便于说明,现在将描述第n解码器223。第一解码器221和第二解码器222可以具有与第n解码器223类似的结构。
第n解码器223可以包括音频信号解码器230。音频信号解码器230可以包括无损解码器231、逆量化器232、立体声信号重建器233以及逆转换器234。
无损解码器231可以接收比特流。无损解码器231可以解码比特流并输出至少一个解码参数。无损解码器231可以在不丢失信息的情况下解码比特流。逆量化器232可以从无损解码器231接收至少一个解码参数。逆量化器232可以对至少一个解码参数进行逆量化。逆量化的解码参数可以是单声道信号。立体声信号重建器233可以基于逆量化的解码参数来重建立体声信号。逆转换器234可以转换频域的立体声信号并且输出时域的解码的音频信号。
解码参数可以包括频谱仓(spectralbin)、尺度因子增益、全局增益、频谱数据和窗口类型中的至少一种。解码参数可以是由诸如mp3、aac或he-aac编解码器之类的编解码器使用的参数。然而,解码参数不限于特定的编解码器,并且由不同名称调用的解码参数可以执行类似的功能。可以以帧为单位发送解码参数。帧是在时域中由原始音频信号划分的单位。
频谱仓可以对应于取决于频域中的频率的信号幅度。
尺度因子增益和全局增益是用于缩放频谱仓的值。对于帧中包括的多个频带,尺度因子可以具有不同的值。
对于帧中的所有频带,全局增益可以具有相同的值。音频重建设备100可以通过将频谱仓乘以尺度因子增益和全局增益来获得频域的音频信号。
频谱数据是指示频谱仓的特性的信息。频谱数据可以指示频谱仓的符号。频谱数据可以指示频谱仓的值是否为0。
窗口类型可以指示原始音频信号的特性。窗口类型可以对应于用于将时域的原始音频信号转换为频域的时间段。当原始音频信号是很少变化的稳态信号时,窗口类型可能指示“长”。当原始音频信号是变化很大的瞬态信号时,窗口类型可能指示“短”。
第n解码器223可以包括参数特性确定器240和参数重建器250中的至少一个。参数特性确定器240可以接收至少一个解码参数并确定至少一个解码参数的特性。参数特性确定器240可以使用机器学习来确定至少一个解码参数的特性。参数特性确定器240可以使用包括在至少一个解码参数中的第一解码参数,来确定包括在至少一个解码参数中的第二解码参数的特性。参数特性确定器240可以将至少一个解码参数和解码参数的特性输出到参数重建器250。下面将参考图4至图6详细描述参数特性确定器240。
根据本公开的实施例,参数重建器250可以从无损解码器231接收该至少一个解码参数。参数重建器250可以重建该至少一个解码参数。参数重建器250可以使用机器学习模型来重建该至少一个解码参数。音频信号解码器230可基于重建的至少一个解码参数来输出接近原始音频的解码音频信号。
根据本公开的另一实施例,参数重建器250可以从参数特性确定器240接收至少一个解码参数和解码参数的特性。参数重建器250可以通过将机器学习模型应用于至少一个解码参数和解码参数的特性来输出重建的参数。参数重建器250可以通过将机器学习模型应用于至少一个解码参数来输出重建的参数。参数重建器250可以基于参数特性来校正重建的参数。参数重建器250可以输出校正后的参数。音频信号解码器230可基于校正后的参数输出接近原始音频的解码的音频信号。
参数重建器250可以将重建的至少一个解码参数和校正后的参数中的至少一者输出到参数特性确定器240或参数重建器250。参数特性确定器240和参数重建器250中的至少一个可以接收前一帧的至少一个解码参数和校正后的参数中的至少一者。参数特性确定器240可以基于前一帧的至少一个解码参数和校正后的参数中的至少一者来输出当前帧的参数特性。参数重建器250可以基于前一帧的至少一个解码参数和校正后的参数中的至少一者来获得当前帧的重建的参数。
现在将参考图3至图11详细描述参数特性确定器240和参数重建器250。
图3是根据实施例的音频重建方法的流程图。
在操作310中,音频重建设备100可以通过对比特流进行解码来获得当前帧的多个解码参数。在操作320中,音频重建设备100可以确定第二参数的特性。在操作330中,音频重建设备100可以通过使用机器学习模型来获得重建的第二参数。在操作340中,音频重建设备100可以基于重建的第二参数来解码音频信号。
音频重建设备100可以通过对比特流进行解码来获得当前帧的多个解码参数(操作310)。无损解码器231可以通过对比特流进行解码来获得多个解码参数。无损解码器231可以将解码参数输出到逆量化器232、参数特性确定器240或参数重建器250。音频重建设备100可以通过分析解码参数来确定将解码参数输出到何处。根据本公开的实施例,音频重建设备100可以基于预定规则来确定将解码参数输出到何处。然而,本公开不限于此,并且比特流可以包括关于解码参数需要输出到何处的信息。音频重建设备100可以基于包括在比特流中的信息来确定将解码参数输出到何处。
当可以在不对多个解码参数中的至少一个解码参数进行修改的情况下确保高音质时,音频重建设备100可以不对至少一个解码参数进行修改。无损解码器231可以将至少一个解码参数输出到逆量化器232。至少一个解码参数未通过参数特性确定器240或参数重建器250,因此可以不被修改。音频重建设备100对于某些解码参数不使用参数特性确定器240和参数重建器250,因此可以有效地使用计算资源。
根据本公开的实施例,音频重建设备100可以确定对至少一个解码参数进行修改。无损解码器231可以将至少一个解码参数输出到参数重建器250。音频重建设备100可以通过使用机器学习模型基于解码参数来获得重建的解码参数。音频重建设备100可以基于重建的解码参数来解码音频信号。音频重建设备100可以基于重建的解码参数来提供具有改进的质量的音频信号。下面将参考图4详细描述机器学习模型。
根据本公开的另一实施例,音频重建设备100可以确定对多个解码参数进行修改。无损解码器231可以将多个解码参数输出到参数特性确定器240。
参数特性确定器240可以基于多个解码参数中包括的第一参数来确定包括在多个解码参数中的第二参数的特性(操作320)。第二参数可以与第一参数相关联。第一参数可以直接或间接表示第二参数的特性。例如,第一参数可以包括第二参数的尺度因子增益、全局增益、频谱数据和窗口类型中的至少一个。
第一参数可以是与第二参数相邻的参数。第一参数可以是包括在与第二参数相同的频带或帧中的参数。第一参数可以是包括在与包括第二参数的频带或帧相邻的频带或帧中的参数。
尽管为了便于说明在此将第一参数和第二参数描述为不同的参数,但是第一参数可以与第二参数相同。即,参数特性确定器240可以基于第二参数来确定第二参数的特性。
参数重建器250可以通过将机器学习模型应用于多个解码参数中的至少一个、第二参数和第二参数的特性来获得重建的第二参数(操作330)。音频重建设备100可以基于重建的第二参数来解码音频信号(操作340)。基于通过应用机器学习模型而重建的第二参数的解码音频信号可以提供优异的质量。现在将参考图4详细描述机器学习模型。
图4是用于描述根据实施例的机器学习的框图。
数据学习器410和数据应用器420可以在不同时间运行。例如,数据学习器410可以比数据应用器420更早地运行。参数特性确定器240和参数重建器250可以包括数据学习器410和数据应用器420中的至少一个。
参考图4,根据实施例的数据学习器410可以包括数据获取器411、预处理器412和机器学习器413。数据学习器410接收输入数据431并输出机器学习模型432的过程可以称为训练过程。
数据获取器411可以接收输入数据431。输入数据431可以包括原始音频信号和解码参数中的至少一者。原始音频信号可以是高质量记录的音频信号。原始音频信号可以在频域或时域中表示。解码参数可以对应于对原始音频信号进行编码的结果。对原始音频信号进行编码时,某些信息可能会丢失。即,与原始音频信号相比,基于多个解码参数解码的音频信号可能具有较低的质量。
预处理器412可以预处理输入数据431以用于学习。预处理器412可以以使得下面将要描述的机器学习器413可以使用输入数据431的方式将输入数据431处理为预设格式。当原始音频信号和多个解码参数具有不同格式时,原始音频信号或多个解码参数可以被转换为另一个的格式。例如,当原始音频信号和多个解码参数与不同的编解码器相关时,可以修改原始音频信号的编解码器信息和多个解码参数以实现它们之间的兼容性。当原始音频信号和多个解码参数在不同的域中表示时,可以将它们修改为在相同的域中表示。
预处理器412可以从输入数据431中选择学习所需的数据。所选择的数据可以被提供给机器学习器413。预处理器412可以根据预设标准从预处理数据中选择学习所需的数据。预处理器412可以根据预设标准通过下面将要描述的机器学习器413的学习来选择数据。因为大量的输入数据需要较长的数据处理时间,所以当选择输入数据431的一部分时,可以提高数据处理的效率。
机器学习器413可以基于所选择的输入数据来输出机器学习模型432。所选择的输入数据可以包括多个解码参数和原始音频信号中的至少一者。机器学习模型432可以包括用于从多个解码参数中重建至少一个参数的标准。机器学习器413可以学习以最小化原始音频信号和基于重建的解码参数所解码的音频信号之间的差异。机器学习器413可以学习用于选择输入数据431的一部分以从多个解码参数中重建至少一个参数的标准。
机器学习器413可以通过使用输入数据431来学习机器学习模型432。在这种情况下,机器学习模型432可以是预训练的模型。例如,机器学习模型432可以是通过接收默认训练数据(例如,至少一个解码参数)而被预先训练的模型。默认训练数据可以是用于构建预训练模型的初始数据。
例如,可以考虑机器学习模型432的应用领域、学习目的或设备的计算性能来选择机器学习模型432。机器学习模型432可以是例如基于神经网络的模型。例如,机器学习模型432可以使用深度神经网络(dnn)模型、递归神经网络(rnn)模型或双向递归深度神经网络(brdnn)模型,但不限于此。
根据各个实施例,当存在多个预构建的机器学习模型时,机器学习器413可以将与输入数据431或默认训练数据高度相关的机器学习模型确定为要被训练的机器学习模型。在这种情况下,可以根据数据类型对输入数据431或默认训练数据进行预分类,并且可以根据数据类型对机器学习模型进行预构建。例如,可以根据各种标准(例如,生成数据的区域、生成数据的时间、数据大小、数据类型、数据生成器、数据中的对象类型和数据格式)对输入数据431或默认训练数据进行预分类。
机器学习器413可以通过使用例如学习算法(例如误差反向传播或梯度下降)来训练机器学习模型432。
机器学习器413可以使用输入数据431作为输入值通过例如监督学习来训练机器学习模型432。机器学习器413可以通过例如用于通过自主学习做出决定所需的数据类型来寻找做出决定的标准的无监督学习来训练机器学习模型432。机器学习器413可以通过例如使用关于通过学习做出的决定的结果是否正确的反馈进行强化学习来训练机器学习模型432。
机器学习器413可以通过使用等式1和等式2来执行机器学习。
[等式1]
[等式2]
y=softmax(evidencei)
在等式1和等式2中,x表示用于机器学习模型的所选输入数据,y表示每个候选的概率,i表示候选的索引,j表示用于机器学习模型的所选输入数据的索引,w表示输入数据的权重矩阵,b表示偏转参数。
机器学习器413可以通过使用任意权重w和任意偏转参数b来获得预测数据。预测数据可以是重建的解码参数。机器学习器413可以计算成本y。成本可以是实际数据与预测数据之间的差异。例如,成本可以是与原始音频信号有关的数据和与重建的解码参数有关的数据之间的差异。机器学习器413可以更新权重w和偏转参数b以最小化成本。
机器学习器413可以获得与最小成本相对应的权重和偏转参数。机器学习器413可以在矩阵中表示与最小成本相对应的权重和偏转参数。机器学习器413可以通过使用与最小成本相对应的权重和偏转参数中的至少一个来获得机器学习模型432。机器学习模型432可以对应于权重矩阵和偏转参数矩阵。
当训练机器学习模型432时,机器学习器413可以存储训练后的机器学习模型432。在这种情况下,机器学习器413可以将训练后的机器学习模型432存储在数据学习器410的存储器中。机器学习器413可以将训练后的机器学习模型432存储将在下面描述的数据应用器420的存储器中。可选地,机器学习器413可以将训练后的机器学习模型432存储在连接到有线或无线网络的电子设备或服务器的存储器中。
在这种情况下,存储有训练后的机器学习模型432的存储器还可以存储例如与电子设备的至少一个其他元件有关的命令或数据。存储器可以存储软件和/或程序。程序可以包括例如内核、中间件、应用编程接口(api)和/或应用程序(或“应用”)。
模型评估器(未示出)可以将评估数据输入到机器学习模型432,并且当使用评估数据而输出的结果不满足特定标准时,请求机器学习器413重新学习。在这种情况下,评估数据可以是用于评估机器学习模型432的预设数据。
例如,当与基于评估数据训练的机器学习模型432的结果中的不准确结果相对应的评估数据的条数或比例超过预设阈值时,模型评估器可以评估不满足特定标准。例如,当将特定标准定义为2%的比率,并且当训练后的机器学习模型432关于总共1000条评估数据中的超过20条评估数据输出错误结果时,模型评估器可以评估训练后的机器学习模型432是不合适的。
当存在多个训练后的机器学习模型时,模型评估器可以评估每个训练后的机器学习模型是否满足特定标准并将满足特定标准的模型确定为最终机器学习模型。在这种情况下,当多个机器学习模型满足特定标准时,模型评估器可以将任何机器学习模型或按评估分数的顺序预设的一定数量的机器学习模型确定为最终机器学习模型432。
数据学习器410中的数据获取器411、预处理器412、机器学习器413和模型评估器中的至少一者可以以至少一个硬件芯片的形式制造并被安装在电子设备中。例如,数据获取器411、预处理器412、机器学习器413和模型评估器中的至少一者可以以用于ai的专用硬件芯片的形式或作为通用处理器(例如,中央处理单元(cpu)或应用处理器)或专用图形处理器(例如,图形处理单元(gpu))的一部分来制造,并被安装在各种电子设备中。
数据获取器411、预处理器412、机器学习器413和模型评估器可以被安装在一个电子设备中,或者被分别安装在不同的电子设备中。例如,数据获取器411、预处理器412、机器学习器413和模型评估器中的一些可以被包括在电子设备中,而其他的可以被包括在服务器中。
数据获取器411、预处理器412、机器学习器413和模型评估器中的至少一者可以被实现为软件模块。当数据获取器411、预处理器412、机器学习器413和模型评估器中的至少一者被实现为软件模块(或包括指令的程序模块)时,该软件模块可以存储在非暂时性计算机可读介质中。在这种情况下,至少一个软件模块可以由操作系统(os)或特定应用提供。可选地,至少一个软件模块中的一些可以由os提供,而其他的可以由特定应用提供。
参考图4,根据实施例的数据应用器420可以包括数据获取器421、预处理器422和结果提供器423。数据应用器420接收输入数据441和机器学习模型432并输出输出数据442的过程可以被称为测试过程。
数据获取器421可以获取输入数据441。输入数据441可以包括用于解码音频信号的至少一个解码参数。预处理器422可以预处理输入数据441以使其可用。预处理器422可以以使得将在下面描述的结果提供器423可以使用输入数据441的方式将输入数据441处理为预设格式。
预处理器422可以从预处理的输入数据中选择要由结果提供器423使用的数据。预处理器422可以从预处理的输入数据中选择用于改进音频信号的质量的至少一个解码参数。所选择的数据可以被提供给结果提供器423。预处理器422可以根据用于改进音频信号的质量的预设标准来选择预处理的输入数据的一部分或全部。预处理器422可以根据通过机器学习器413的学习而预设的标准来选择数据。
结果提供器423可以通过将预处理器422选择的数据应用于机器学习模型432来输出输出数据442。输出数据442可以是用于提供改进的声音质量的重建的解码参数。音频重建设备100可以基于重建的解码参数来输出接近于原始音频信号的解码的音频信号。
结果提供器423可以将输出数据442提供给预处理器422。预处理器422可以对输出数据442进行预处理,并将其提供给结果提供器423。例如,输出数据442可以是前一帧的重建的解码参数。结果提供器423可将前一帧的输出数据442提供给预处理器422。预处理器422可将当前帧的选定解码参数和前一帧的重建的解码参数提供给结果提供器423。结果提供器423可以不仅通过反映当前帧的重建的解码参数而且还反映关于前一帧的信息来生成当前帧的输出数据442。当前帧的输出数据442可以包括当前帧的重建的解码参数和校正后的解码参数中的至少一项。音频重建设备100可以基于当前帧的输出数据442来提供更高质量的音频。
模型更新器(未示出)可以基于对结果提供器423提供的输出数据442的评估来控制机器学习模型432的更新。例如,模型更新器可以通过将结果提供器423所提供的输出数据442提供给机器学习器413,来请求机器学习器413更新机器学习模型432。
数据应用器420中的数据获取器421、预处理器422、结果提供器423和模型更新器中的至少一个可以以至少一个硬件芯片的形式制造并被安装在电子设备中。例如,数据获取器421、预处理器422、结果提供器423和模型更新器中的至少一个可以以用于ai的专用硬件芯片的形式或作为通用处理器(例如,cpu或应用处理器)或专用图形处理器(例如,gpu)的一部分来制造,并被安装在各种电子设备中。
数据获取器421、预处理器422、结果提供器423和模型更新器可以被安装在一个电子设备中,或者被分别安装在不同的电子设备中。例如,数据获取器421、预处理器422、结果提供器423和模型更新器中的一些可以被包括在电子设备中,而其他的可以被包括在服务器中。
数据获取器421、预处理器422、结果提供器423和模型更新器中的至少一个可以被实现为软件模块。当数据获取器421、预处理器422、结果提供器423和模型更新器中的至少一个被实现为软件模块(或包括指令的程序模块)时,该软件模块可以存储在非暂时性计算机可读介质中。在这种情况下,os或某个应用可以提供至少一个软件模块。可选地,至少一个软件模块中的一些可以由os提供,而其他的可以由特定应用提供。
现在将参考图5至图11详细描述图1的音频重建设备100的操作以及图4的数据学习器410和数据应用器420。
图5示出了根据实施例的解码参数的特性的预测。
参数特性确定器240可以确定解码参数的特性。音频重建设备100不需要处理不满足解码参数的特性的参数,因此可以减少计算量。与输入的解码参数相比,音频重建设备100可以防止输出质量较差的重建的解码参数。
曲线图510示出了取决于帧中的频率的信号幅度。音频重建设备100基于比特流获得的多个解码参数可以包括取决于频率的信号幅度。例如,信号幅度可以对应于频谱仓。
多个解码参数可以包括第一参数和第二参数。参数特性确定器240可以基于第一参数来确定第二参数的特性。第一参数可以是与第二参数相邻的参数。音频重建设备100可以基于第一参数的趋势来确定第二参数的特性。第二参数的特性可以包括第二参数的范围。
根据本公开的实施例,第二参数可以是在频率f3处的信号幅度513。第一参数可以包括对应于频率f1、f2、f4和f5的信号幅度511、512、514和515。音频重建设备100可以确定与第一参数相对应的信号幅度511、512、514和515处于上升趋势。因此,音频重建设备100可以确定与第二参数相对应的信号幅度513的范围在信号幅度512和514之间。
图2的参数特性确定器240可以包括图4的数据学习器410。机器学习模型432可以由数据学习器410预先训练。
例如,参数特性确定器240的数据学习器410可以接收对应于原始音频信号的信息。对应于原始音频信号的信息可以是原始音频信号本身,也可以是通过对原始音频信号进行高质量编码而获得的信息。参数特性确定器240的数据学习器410可以接收解码参数。参数特性确定器240的数据学习器410接收的参数可以对应于至少一帧。参数特性确定器240的数据学习器410可以基于数据获取器411、预处理器412和机器学习器413的操作来输出机器学习模型432。数据学习器410的机器学习模型432可以是用于基于第一参数来确定第二参数的特性的机器学习模型。例如,机器学习模型432可以被指定为针对至少一个第一参数中的每一个的权重。
参数特性确定器240可以包括图4的数据应用器420。参数特性确定器240可以基于第一参数和第二参数中的至少一个来确定第二参数的特性。参数特性确定器240可以使用预训练的机器学习模型来确定第二参数的特性。
例如,参数特性确定器240的数据应用器420可以接收包括在当前帧的多个解码参数中的第一参数和第二参数中的至少一个。参数特性确定器240的数据应用器420可以从参数特性确定器240的数据学习器410接收机器学习模型432。参数特性确定器240的数据应用器420可以基于数据获取器421、预处理器422和结果提供器423的操作,来确定第二参数的特性。例如,参数特性确定器240的数据应用器420可以通过将机器学习模型432至少应用于第一参数和第二参数中的至少一个来确定第二参数的特性。
根据本公开的另一实施例,音频重建设备100可以通过重建比特流中不包括的第二参数来提供高比特率音频。第二参数可以是频率f0处的信号幅度。比特流可以不包含有关频率f0处的信号幅度的信息。音频重建设备100可以基于第一参数来估计频率f0处的信号特性。第一参数可以包括与频率f1、f2、f3、f4和f5相对应的信号幅度511、512、513、514和515。音频重建设备100可以确定与第一参数相对应的信号幅度511、512、513、514和515处于上升趋势。因此,音频重建设备100可以确定与第二参数相对应的信号幅度的范围在信号幅度514与515之间。音频重建设备100可以包括图4的数据学习器410和数据应用器420中的至少一个。上面提供了对数据学习器410或数据应用器420的操作的详细描述,因此这里将不再重复。
参考曲线图520,第二参数可以是在频率f3处的信号幅度523。第一参数可以包括对应于频率f1、f2、f4和f5的信号幅度521、522、524和525。音频重建设备100可以确定与第一参数相对应的信号幅度521、522、524和525处于先升后降的趋势中。因为对应于频率f4的信号幅度524大于对应于频率f2的信号幅度522,所以音频重建设备100可以确定对应于第二参数的信号幅度523的范围大于或等于信号幅度524。
参考曲线图530,第二参数可以是在频率f3处的信号幅度533。第一参数可以包括对应于频率f1、f2、f4和f5的信号幅度531、532、534和535。音频重建设备100可以确定与第一参数相对应的信号幅度531、532、534和535处于先降后升的趋势。因为对应于频率f4的信号幅度534小于对应于频率f2的信号幅度532,所以音频重建设备100可以确定对应于第二参数的信号幅度533的范围小于或等于信号幅度534。
参考曲线图540,第二参数可以是在频率f3处的信号幅度543。第一参数可以包括与频率f1、f2、f4和f5相对应的信号幅度541、542、544和545。音频重建设备100可以确定与第一参数相对应的信号幅度541、542、544和545处于下降趋势。音频重建设备100可以确定与第二参数相对应的信号幅度543的范围在信号幅度542与544之间。
图6示出了根据实施例的解码参数的特性的预测。
音频重建设备100可以使用多个帧来确定帧中的解码参数的特性。音频重建设备100可以使用该帧的先前帧来确定该帧中的解码参数的特性。例如,音频重建设备100可以使用包括在帧n-2、帧n-1610、帧n620或帧n+1630中的至少一个解码参数,来确定包括在帧n+1630中的至少一个解码参数的特性。
音频重建设备100可以从比特流获得解码参数。音频重建设备100可以基于多个帧中的解码参数来获得曲线图640、650和660。曲线图640示出了频域中的帧n-1610中的解码参数。曲线图640中所示的解码参数可以表示取决于频率的信号幅度。曲线图650示出了在频域中取决于帧n620中的频率的信号幅度。曲线图660示出了在频域中取决于帧n+1630中的频率的信号幅度。音频重建设备100可以基于包括在曲线图640、650和660中的至少一个信号幅度来确定包括在曲线图660中的信号幅度的特性。
根据本公开的实施例,音频重建设备100可以基于包括在曲线图640、650和660中的至少一个信号幅度来确定包括在曲线图660中的信号幅度662的特性。音频重建设备100可以检查曲线图640的信号幅度641、642和643的趋势。音频重建设备100可以检查曲线图650的信号幅度651、652和653的趋势。趋势可以上升然后在f3附近下降。音频重建设备100可以基于曲线图640和650来确定曲线图660的趋势。音频重建设备100可以确定信号幅度662大于或等于信号幅度661和信号幅度663。
根据本公开的另一实施例,音频重建设备100可以基于包括在曲线图640、650和660中的至少一个信号幅度来确定在曲线图660中的f0处的信号幅度的特性。音频重建设备100可以检查曲线图640中的信号幅度的趋势。音频重建设备100可以检查曲线图650中的信号幅度的趋势。趋势可以在f0附近下降。音频重建设备100可以基于曲线图640和650来确定曲线图660的趋势。音频重建设备100可以确定在f0处的信号幅度小于或等于在f4处的信号幅度并且大于或等于在f5处的信号幅度。音频重建设备100可以包括图4的数据学习器410和数据应用器420中的至少一个。上面提供了对数据学习器410或数据应用器420的操作的详细描述,因此这里将不再重复。
根据本公开的实施例,音频重建设备100可以使用一个帧的先前帧来确定该帧中包括的解码参数的特性。音频重建设备100可以基于先前帧中的取决于特定频率的信号来确定当前帧中的取决于特定频率的信号的特性。音频重建设备100可以基于例如先前帧中的取决于特定频率的信号的分布范围、平均值、中值、最小值、最大值、偏差或符号,来确定当前帧中的取决于特定频率的解码参数的特性。
例如,音频重建设备100可以基于包括在曲线图640和650中的至少一个信号幅度来确定包括在曲线图660中的信号幅度662的特性。音频重建设备100可以基于曲线图640中的频率f3处的信号幅度642和曲线图650中的频率f3处的信号幅度652,来确定曲线图660中的频率f3处的信号幅度662的特性。信号幅度662的特性可以是基于例如信号幅度642和652的分布范围、平均值、中值、最小值、最大值、偏差或符号。
根据本公开的实施例,音频重建设备100可以从比特流获得解码参数。解码参数可以包括第二参数。可以基于不是解码参数的预定参数来确定第二参数的特性。
例如,量化步长可以不包括在解码参数中。第二参数可以对应于取决于帧中的频率的信号幅度。信号幅度可以对应于频谱仓。音频重建设备100可以基于量化步长来确定频谱仓的范围。量化步长是确定为频谱仓的信号幅度的范围。量化步长可以随频率而不同。量化步长在可听见频率区域中可能很密集。量化步长在除可听见频率区域以外的区域中可能很稀疏。因此,当已知对应于频谱仓的频率时,可以确定量化步长。频谱仓的范围可以基于量化步长来确定。
根据本公开的另一实施例,音频重建设备100可以从比特流获得解码参数。解码参数可以包括第一参数和第二参数。可以基于第一参数来确定第二参数的特性。第二参数的特性可以包括第二参数的范围。
例如,第一参数可以包括尺度因子和掩蔽阈值。可以基于尺度因子和掩蔽阈值来确定量化步长。如上所述,尺度因子是用于缩放频谱仓的值。对于帧中包括的多个频带,尺度因子可以具有不同的值。当存在被称为掩蔽器的噪声时,掩蔽阈值是使当前信号可听见的当前信号的最小幅度。掩蔽阈值可以因频率和掩蔽器类型而异。当掩蔽器在频率上接近当前信号时,可以增加掩蔽阈值。
例如,当前信号可以出现在f0处,而掩蔽器信号可以出现在接近f0的f1处。可以基于f1的掩蔽器确定在f0处的掩蔽阈值。当f0的当前信号的幅度小于掩蔽阈值时,当前信号可能是听不到的声音。因此,音频重建设备100在编码或解码过程中可以忽略f0的当前信号。否则,当f0的当前信号的幅度大于掩蔽阈值时,当前信号可能是可听见的声音。因此,音频重建设备100在编码或解码过程中不可以忽略f0的当前信号。
音频重建设备100可以将尺度因子和掩蔽阈值中的量化步长设置为较小的值。音频重建设备100可以基于量化步长来确定频谱仓的范围。
图7是根据实施例的音频重建方法的流程图。
在操作710中,音频重建设备100可以通过对比特流进行解码来获得用于解码音频信号的当前帧的多个解码参数。在操作720中,音频重建设备100可以基于包括在多个解码参数中的第一参数来确定包括在多个解码参数中的第二参数的特性。在操作730中,音频重建设备100可以通过使用机器学习模型基于多个解码参数中的至少一个来获得重建的第二参数。在操作740中,音频重建设备100可以通过基于第二参数的特性校正第二参数来获得校正后的第二参数。在操作750中,音频重建设备100可以基于校正后的第二参数来解码音频信号。
操作710和操作750可以由音频信号解码器230执行。操作720可以由参数特性确定器240执行。操作730和操作740可以由参数重建器250执行。
返回参考根据本公开的实施例的图3,参数重建器250的数据学习器410和数据应用器420可以接收第二参数的特性作为输入。即,参数重建器250可以基于第二参数的特性来执行机器学习。参数重建器250的数据学习器410可以通过反映第二参数的特性来输出机器学习模型432。参数重建器250的数据应用器420可以通过反映第二参数的特性来输出输出数据442。
参考根据本公开的另一实施例的图7,参数重建器250的数据学习器410和数据应用器420可以不接收第二参数的特性作为输入。即,参数重建器250可以仅基于解码参数而不基于第二参数的特性来执行机器学习。参数重建器250的数据学习器410可以在不反映第二参数的特性的情况下输出机器学习模型432。参数重建器250的数据应用器420可以在不反映第二参数的特性的情况下输出输出数据442。
输出数据442可以是重建的第二参数。参数重建器250可以确定重建的第二参数是否满足第二参数的特性。当重建的第二参数满足第二参数的特性时,参数重建器250可以将重建的参数输出到音频信号解码器230。当重建的第二参数不满足第二参数的特性时,参数重建器250可以通过基于第二参数的特性校正重建的第二参数来获得校正后的第二参数。参数重建器250可以将校正后的参数输出到音频信号解码器230。
例如,第二参数的特性可以包括第二参数的范围。音频重建设备100可以基于第一参数来确定第二参数的范围。当重建的第二参数不在第二参数的范围内时,音频重建设备100可获得范围内与重建的第二参数最接近的值作为校正后的第二参数。现在将参考图8提供其详细描述。
图8示出了根据实施例的解码参数。
曲线图800在频域中示出了取决于原始音频信号的频率的信号幅度。曲线图800可以对应于原始音频信号的帧。原始音频信号由具有连续波形的曲线805表示。原始音频信号可以在频率f1、f2、f3和f4处采样。原始音频信号在频率f1、f2、f3和f4处的大小可以由点801、802、803和804表示。原始音频信号可以被编码。音频重建设备100可以通过对编码后的原始音频信号进行解码来生成解码参数。
曲线图810示出了取决于频率的信号幅度。在曲线图810中示出的虚线815可以对应于原始音频信号。曲线图810中所示的点811、812、813和814可以对应于解码参数。解码参数可以从音频重建设备100的无损解码器231输出。原始音频信号和解码参数中的至少一个可以被缩放并显示在曲线图810中。
如曲线图810所示,虚线815可以与点811、812、813和814不同。虚线815与点811、812、813和814之间的差异可能是由于对原始音频信号进行编码和解码时造成的错误而导致的。
音频重建设备100可以确定与点811、812、813和814相对应的解码参数的特性。音频重建设备100可以使用机器学习模型来确定解码参数的特性。上面关于图5和图6提供了确定解码参数的特性的详细描述,在此不再赘述。解码参数可以是频谱仓。解码参数的特性可以包括频谱仓的范围。
在曲线图830中示出了由音频重建设备100确定的频谱仓的范围。即,箭头835表示点831对应于频谱仓的可用范围。箭头836表示点832对应于频谱仓的可用范围。箭头837表示点833对应于频谱仓的可用范围。箭头838表示点834对应于频谱仓的可用范围。
音频重建设备100可以确定在f2和f3之间的f0处的信号特性。音频重建设备100可以在f0处不接收解码参数。音频重建设备100可以基于与f0有关的解码参数来确定在f0处的解码参数的特性。
例如,音频重建设备100可以不接收关于在f0处的频谱仓的幅度的信息。音频重建设备100可以通过使用与f0相邻的频率的频谱仓和与当前帧相邻的帧的频谱仓来确定在f0处的信号幅度的范围。上面关于图5和图6提供了其详细描述,在此不再赘述。
音频重建设备100可以重建解码参数。音频重建设备100可以使用机器学习模型。为了重建解码参数,音频重建设备100可以将至少一个解码参数和解码参数的特性应用于机器学习模型。
在曲线图850中示出了由音频重建设备100重建的解码参数。点851、852、853、854和855代表重建的解码参数。与重建之前的解码参数相比,重建的解码参数可能具有更大的误差。例如,尽管在曲线图830中对应于频谱仓的点834靠近原始音频信号,但是在曲线图850中对应于频谱仓的点854可以远离由虚线860表示的原始音频信号。
音频重建设备100可以校正解码参数。音频重建设备100可以确定解码参数是否在解码参数的可用范围内。当解码参数不在解码参数的可用范围内时,音频重建设备100可以校正解码参数。校正后的解码参数可以在解码参数的可用范围内。
例如,曲线图870示出了校正后的频谱仓。对应于频谱仓的点871、872、873和875可以在频谱仓的可用范围内。然而,对应于频谱仓的点874可以不在频谱仓的可用范围878内。当重建的频谱仓不在频谱仓的可用范围878内时,音频重建设备100可以获得范围878的最接近重建的频谱仓的值作为校正后的频谱仓。当与重建的频谱仓相对应的点874的值大于范围878的最大值时,音频重建设备100可以获得范围878的最大值作为与校正后的频谱仓相对应的点880。即,音频重建设备100可以将与重建的频谱仓相对应的点874校正为点880。点880可以与校正后的频谱仓相对应。
音频重建设备100可以基于校正后的解码参数来解码音频信号。利用在频率f0处对应于重建频谱仓的点875,可以改进音频信号的采样率。利用在频率f4处对应于重建频谱仓的点880,可以精确地表示音频信号的幅度。因为校正后的解码参数接近频域的原始音频信号,所以解码后的音频信号可以接近原始音频信号。
图9示出了根据实施例的解码参数的改变。
曲线图910对应于图8的曲线图810。曲线图910示出了取决于频率的信号幅度。曲线图910中示出的虚线915可以对应于原始音频信号。曲线图910中所示的点911、912、913和914可以对应于解码参数。原始音频信号和解码参数中的至少一个可以被缩放并在图形910中示出。
音频重建设备100可以确定与点911、912、913和914相对应的解码参数的特性。音频重建设备100可以使用机器学习模型来确定解码参数的特性。上面关于图5和图6提供了确定解码参数的特性的详细描述,在此不再赘述。解码参数可以是频谱仓。解码参数的特性可以包括频谱仓的范围。在曲线图930中示出了由音频重建设备100确定的频谱仓的范围。
音频重建设备100可以确定用于微调每个频谱仓的候选。音频重建设备100可以通过使用多个比特来表示频谱仓。音频重建设备100可以与用于表示频谱仓的比特数成比例地精细地表示频谱仓。音频重建设备100可以增加用于表示频谱仓的比特数,以微调频谱仓。现在将参考图10描述增加用于表示频谱仓的比特数的情况。
图10示出了根据实施例的在比特数增加的情况下解码参数的变化。
参考曲线图1000,音频重建设备100可以使用两比特来表示量化的解码参数。在这种情况下,音频重建设备100可以通过使用“00”、“01”、“10”和“11”来表示量化的解码参数。即,音频重建设备100可以表示解码参数的四个幅度。音频重建设备100可以将解码参数的最小值分配给“00”。音频重建设备100可以将解码参数的最大值分配给“11”。
由音频重建设备100接收的解码参数的幅度可以对应于点1020。解码参数的幅度可以是“01”。然而,在被量化之前的解码参数的实际幅度可以对应于星形1011、1012或1013。当解码参数的实际幅度对应于星形1011时,误差范围可以对应于箭头1031。当解码参数的实际幅度对应于星形1012,误差范围可以对应于箭头1032。当解码参数的实际幅度对应于星形1013时,误差范围可以对应于箭头1033。
参考曲线图1050,音频重建设备100可以使用三比特来表示量化的解码参数。在这种情况下,音频重建设备100可以通过使用“000”、“001”、“010”、“011”、“100”、“101”、“110”和“111”来表示量化的解码参数。即,音频重建设备100可以表示解码参数的八个幅度。音频重建设备100可以将解码参数的最小值分配给“000”。音频重建设备100可以将解码参数的最大值分配给“111”。
音频重建设备100接收的解码参数的幅度可以对应于点1071、1072和1073。解码参数的幅度可以是“001”、“010”和“011”。解码参数的实际幅度可以对应于星形1061、1062和1063。当解码参数的实际幅度对应于星形1061时,误差范围可以对应于箭头1081。当解码参数的实际幅度对应于对于星形1062,误差范围可以对应于箭头1082。当解码参数的实际幅度对应于星形1063时,误差范围可以对应于箭头1083。
当将曲线图1000与曲线图1050进行比较时,曲线图1050中的解码参数的误差小于曲线图1000中的解码参数的误差。如图10所示,可以与音频重建设备100用来表示解码参数的比特数成比例地精确地表示解码参数。
返回参考图9,音频重建设备100可以确定用于微调每个解码参数的候选。参考曲线图950,音频重建设备100可以另外使用一比特来表示解码参数。音频重建设备100可以确定与曲线图930的解码参数931相对应的候选951、952和953。音频重建设备100可以使用解码参数的特性来确定解码参数的候选951、952和953。例如,解码参数的特性可以包括解码参数的范围954。候选951、952和953可以在解码参数的范围954内。
音频重建设备100可以基于机器学习模型来选择解码参数的候选951、952和953中的一个。音频重建设备100可以包括数据学习器410和数据应用器420中的至少一个。音频重建设备100可以通过将当前帧的解码参数和前一帧的解码参数中的至少一个应用于机器学习模型来选择一个解码参数。机器学习模型可以被预先训练。
解码参数可以包括第一参数和第二参数。音频重建设备100可以使用与第二参数相关联的第一参数来选择第二参数的多个候选中的一个。
参考曲线图960,音频重建设备100可以获取选择的解码参数961。音频重建设备100可获取基于选择的解码参数961解码的音频信号。
参考曲线图970,音频重建设备100可以另外使用两比特来表示解码参数。音频重建设备100可以确定与曲线图930的解码参数931相对应的候选971、972、973、974和975。与曲线图950的候选951、952和953相比,候选971、972、973、974和975具有更详细的值。与使用一比特的情况相比,音频重建设备100可以通过使用两比特来重建更准确的解码参数。音频重建设备100可以使用解码参数的特性来确定解码参数的候选971、972、973、974和975。例如,解码参数的特性可以包括解码参数的范围976。候选971、972、973、974和975可以在解码参数的范围976内。
音频重建设备100可基于机器学习模型来选择解码参数的候选971、972、973、974和975中的一个。音频重建设备100可以通过将当前帧的解码参数和先前帧的解码参数中的至少一个应用于机器学习模型来选择一个解码参数。解码参数可以包括第一参数和第二参数。音频重建设备100可以使用与第二参数相关联的第一参数来选择第二参数的多个候选中的一个。
参考曲线图980,音频重建设备100可以获得选择的解码参数981。与曲线图960的所选择的解码参数961相比,选择的解码参数981可以具有更准确的值。与选择的解码参数961相比,所选择的解码参数981可以更接近原始音频信号。音频重建设备100可以获得基于所选择的解码参数981而解码的音频信号。
图11示出了根据实施例的解码参数的改变。
音频重建设备100可以接收比特流。音频重建设备100可以基于比特流获得解码参数。音频重建设备100可以确定解码参数的特性。解码参数的特性可以包括符号。当解码参数的幅度为0时,幅度0可以用作解码参数的特性。
例如,解码参数可以是频谱数据。频谱数据可以指示频谱仓的符号。频谱数据可以指示频谱仓的值是否为0。频谱数据可以被包括在比特流中。音频重建设备100可以基于比特流来生成频谱数据。
解码参数可以包括第一参数和第二参数。音频重建设备100可以基于第一参数来确定第二参数的特性。第一参数可以是频谱数据。第二参数可以是频谱仓。
曲线图1110示出了取决于频率的解码参数的幅度。解码参数可以是频谱仓。解码参数可以具有各种符号。例如,解码参数1111可以具有负号。解码参数1113可以具有正号。音频重建设备100可以将解码参数1111和1113的符号确定为解码参数1111和1113的特性。解码参数1112的幅度可以为0。音频重建设备100可以将0的幅度确定为解码参数1112的特性。
根据本公开的实施例,音频重建设备100可以通过将解码参数应用于机器学习模型来确定重建的解码参数。曲线图1130示出了取决于频率的重建的解码参数的大小。音频重建设备100可以通过重建解码参数1111、1112和1113来获得重建的解码参数1131、1132和1133。然而,重建的解码参数1131和1133可以具有与解码参数1111和1113不同的符号。与解码参数1112不同,重建的解码参数1132可以具有非零值。
音频重建设备100可以基于解码参数的特性,通过校正重建的解码参数来获得校正的解码参数。音频重建设备100可以基于解码参数的符号来校正重建的解码参数。参考曲线图1150,音频重建设备100可以通过校正重建的解码参数1131和1133的符号来获得校正后的解码参数1151和1153。音频重建设备100可以通过将重建的解码参数1132的幅度校正为0来获得校正后的解码参数1152。
根据本公开的另一实施例,音频重建设备100可以通过将机器学习模型应用于解码参数和解码参数的特性来获得重建的解码参数。即,音频重建设备100可以基于曲线图1110所示的解码参数来获得曲线图1150所示的重建的参数。
图12是根据实施例的音频重建设备100的框图。
音频重建设备100可以包括编解码器信息提取器1210、音频信号解码器1220、比特流分析器1230、重建方法选择器1240和至少一个重建器。
编解码器信息提取器1210可以等同地对应于图1的接收器110。编解码器信息提取器1210可以等同地对应于图2的编解码器信息提取器210。编解码器信息提取器1210可以接收比特流并确定用于对比特流进行编码的技术。用于编码原始音频的技术可以包括例如mp3、aac或he-aac技术。
音频信号解码器1220基于比特流解码音频信号。音频信号解码器1220可以等同地对应于图2的音频信号解码器230。音频信号解码器1220可以包括无损解码器、逆量化器、立体声信号重建器和逆转换器。音频信号解码器1220可以基于从编解码器信息提取器1210接收的编解码器信息,输出重建的音频信号。
比特流分析器1230可以基于比特流获得当前帧的解码参数。比特流分析器1230可以基于解码参数来检查重建的音频信号的特性。比特流分析器1230可以将关于信号特性的信息发送到重建方法选择器1240。
例如,解码参数可以包括频谱仓、尺度因子增益、全局增益、窗口类型、缓冲级别、时域噪声整形(tns)信息和感知噪声替代(pns)信息中的至少一个。
频谱仓可以对应于取决于频域中的频率的信号幅度。音频编码设备可以仅针对人类敏感的频率范围发送准确的频谱仓,以减少数据。针对人类听不到的高频或低频区域,音频编码设备可能不会发送任何频谱仓或发送不准确的频谱仓。音频重建设备100可以将带宽扩展技术应用于针对其没有发送频谱仓的区域。比特流分析器1230可以通过分析频谱仓来确定频谱仓被准确地发送的频率区域和频谱仓被不准确地发送的频率区域。比特流分析器1230可以将关于频率的信息发送到重建方法选择器1240。
例如,带宽扩展技术通常可以应用于高频区域。比特流分析器1230可以将频谱仓被不准确地发送的频率区域的最小频率值确定为起始频率。比特流分析器1230可以确定需要从起始频率开始应用带宽扩展技术。比特流分析器1230可以将关于起始频率的信息发送到重建方法选择器1240。
尺度因子增益和全局增益是用于缩放频谱仓的值。比特流分析器1230可以通过分析尺度因子增益和全局增益来获得重建的音频信号的特性。例如,当当前帧的尺度因子增益和全局增益快速变化时,比特流分析器1230可以确定当前帧是瞬态信号。当帧的尺度因子增益和全局增益几乎不变时,比特流分析器1230可以确定帧是稳态信号。比特流分析器1230可以将指示帧是稳态信号还是瞬态信号的信息发送到重建方法选择器1240。
窗口类型可以对应于用于将时域的原始音频信号转换为频域的时间段。当当前帧的窗口类型指示“长”时,比特流分析器1230可以确定当前帧是稳态信号。当当前帧的窗口类型指示“短”时,比特流分析器1230可以确定当前帧是瞬态信号。比特流分析器1230可以将指示帧是稳态信号还是瞬态信号的信息发送到重建方法选择器1240。
缓冲级别是关于在对一个帧进行编码之后剩余的可用比特数的信息。缓冲级别用于通过使用可变比特率(vbr)对数据进行编码。当原始音频的帧是很少变化的稳态信号时,音频编码设备可以通过使用少量比特来对原始音频进行编码。然而,当原始音频的帧是变化很大的瞬态信号时,音频编码设备可以通过使用大量比特来对原始音频进行编码。音频编码设备可以使用在对稳态信号进行编码之后剩余的可用比特来对瞬态信号进行编码。即,当前帧的高缓冲级别意味着当前帧是稳态信号。当前帧的低缓冲级别意味着当前帧是瞬态信号。比特流分析器1230可以将指示帧是稳态信号还是瞬态信号的信息发送到重建方法选择器1240。
tns信息是用于减少预回波的信息。可以基于tns信息找到时域中攻击信号的起始位置。攻击信号表示突然响亮的声音。因为可以基于tns信息找到攻击信号的起始位置,所以比特流分析器1230可以确定在起始位置之前的信号是稳态信号。比特流分析器1230可以确定起始位置之后的信号是瞬态信号。
pns信息是关于在频域中产生孔(hole)的部分的信息。孔是指针对其不发送频谱仓以节省比特流的比特,并且在解码过程中充满了任意噪声的部分。比特流分析器1230可以将关于孔的位置的信息发送到重建方法选择器1240。
重建方法选择器1240可以接收解码的音频信号和解码的参数的特性。重建方法选择器1240可以选择用于重建解码的音频信号的方法。解码的音频信号可以由至少一个重建器中的一个基于重建方法选择器1240的选择来重建。
至少一个重建器可以包括例如第一重建器1250、第二重建器1260和第n重建器。第一重建器1250、第二重建器1260和第n重建器中的至少一个可以使用机器学习模型。机器学习模型可以是通过机器学习原始音频信号、解码的音频信号和解码参数中的至少一个而生成的模型。第一重建器1250、第二重建器1260和第n重建器中的至少一个可包括数据获取器1251、预处理器1252和结果提供器1253。第一重建器1250、第二重建器1260和第n重建器中的至少一个可以包括图4的数据学习器410。第一重建器1250、第二重建器1260和第n重建器中的至少一个可以接收解码的音频信号和解码参数中的至少一个作为输入。
根据本公开的实施例,解码的参数的特性可以包括关于针对其准确地发送频谱仓的频率区域和针对其不准确地发送频谱仓的频率区域的信息。对于当前帧的针对其准确地发送了频谱仓的频率区域,重建方法选择器1240可以基于解码的参数和解码的音频信号中的至少一个来确定重建的解码音频信号。重建方法选择器1240可以确定通过使用第一重建器1250来重建解码的音频信号。第一重建器1250可以通过使用机器学习模型来输出重建的音频信号。
对于当前帧的针对其未准确发送频谱仓的频率区域,重建方法选择器1240可以确定通过使用带宽扩展技术来重建音频信号。带宽扩展技术包括频谱带复制(sbr)。重建方法选择器1240可以确定通过使用第二重建器1260来重建解码的音频信号。第二重建器1260可以通过使用由机器学习模型改进的带宽扩展技术来输出重建的音频信号。
根据本公开的另一实施例,解码的参数的特性可以包括指示一个帧是稳态信号还是瞬态信号的信息。当该帧是稳态信号时,重建方法选择器1240可以将第一重建器1250用于稳态信号。当该帧是瞬态信号时,重建方法选择器1240可以将第二重建器1260用于瞬态信号。第一重建器1250或第二重建器1260可以输出重建的音频信号。
根据本公开的另一个实施例,解码后的参数的特性可以包括关于孔的位置的信息。对于使用不与孔的位置相对应的信号所解码的音频信号,重建方法选择器1240可以基于解码的参数和解码的音频信号确定重建解码的音频信号。重建方法选择器1240可以确定通过使用第一重建器1250来重建解码的音频信号。第一重建器1250可以通过使用机器学习模型来输出重建的音频信号。对于使用与孔的位置相对应的信号所解码的音频信号,重建方法选择器1240可以使用用于与孔的位置相对应的信号的第二重建器1260。第二重建器1260可以通过使用机器学习模型来输出重建的音频信号。
因为可以通过重建方法选择器1240基于音频信号的特性来选择重建解码的音频信号的方法,所以音频重建设备100可以有效地重建音频信号。
图13是根据实施例的音频重建方法的流程图。
在操作1310中,音频重建设备100通过对比特流进行解码来获得当前帧的多个解码参数。在操作1320中,音频重建设备100基于多个解码参数来解码音频信号。在操作1330中,音频重建设备100基于解码的音频信号和多个解码参数中的至少一个,从多个机器学习模型中选择一个机器学习模型。在操作1340中,音频重建设备100通过使用选择的机器学习模型来重建解码的音频信号。
基于图13的音频重建设备100和基于图3的音频重建设备100均可以改进解码的音频信号的质量。基于图13的音频重建设备100更少地依赖于解码参数,因此可以实现更高的通用性。
现在将参考图14和图15详细描述音频重建设备100的操作。
图14是根据实施例的音频重建方法的流程图。
编解码器信息提取器1210可以接收比特流。音频信号解码器1220可以输出基于比特流解码的音频信号。
比特流分析器1230可以基于比特流获得解码参数的特性。例如,比特流分析器1230可以基于多个解码参数中的至少一个来确定带宽扩展的起始频率(操作1410)。
参考曲线图1460,音频编码设备可以针对低于频率f的频率区域准确地发送频谱仓。但是,对于高于频率f且人类听不到的频率区域,音频编码设备可能不会发送频谱仓或较差地发送频谱仓。编解码器信息提取器1210可以基于频谱仓来确定带宽扩展的起始频率f。编解码器信息提取器1210可以将关于带宽扩展的起始频率f的信息输出到重建方法选择器1240。
重建方法选择器1240可以基于起始频率f和解码的音频信号的频率来选择用于解码的音频信号的机器学习模型。重建方法选择器1240可以将解码的音频信号的频率与起始频率f进行比较(操作1420)。重建方法选择器1240可以基于比较来选择重建方法。
当解码的音频信号的频率低于起始频率f时,重建方法选择器1240可以选择某个机器学习模型。可以基于解码的音频信号和原始音频信号来预训练特定的机器学习模型。音频重建设备100可以通过使用机器学习模型来重建解码的音频信号(操作1430)。
当解码的音频信号的频率高于起始频率f时,重建方法选择器1240可以通过使用带宽扩展技术来重建解码的音频信号。例如,重建方法选择器1240可以选择对其应用了带宽扩展技术的机器学习模型。可以使用与带宽扩展技术有关的参数、解码的音频信号和原始音频信号中的至少一个来预训练机器学习模型。音频重建设备100可以通过使用应用了带宽扩展技术的机器学习模型来重建解码的音频信号(操作1440)。
图15是根据实施例的音频重建方法的流程图。
编解码器信息提取器1210可以接收比特流。音频信号解码器1220可以输出基于比特流解码的音频信号。
比特流分析器1230可以基于比特流获得解码参数的特性。例如,比特流分析器1230可以基于多个解码参数中的至少一个来获得当前帧的增益a(操作1510)。比特流分析器1230可以获得当前帧和与当前帧相邻的帧的增益的平均值(操作1520)。
重建方法选择器1240可以将当前帧的增益与增益的平均值之间的差与阈值进行比较(操作1530)。当当前帧的增益与增益的平均值之间的差大于阈值时,重建方法选择器1240可以选择用于瞬态信号的机器学习模型。音频重建设备100可以通过使用用于瞬态信号的机器学习模型来重建解码的音频信号(操作1550)。
当当前帧的增益与增益的平均值之间的差小于阈值时,重建方法选择器1240可以确定包括在多个解码参数中的窗口类型是否指示为短(操作1540)。当窗口类型指示为短时,重建方法选择器1240可以选择用于瞬态信号的机器学习模型(操作1550)。当窗口类型不指示短时,重建方法选择器1240可以选择用于稳态信号的机器学习模型。音频重建设备100可以通过使用用于稳态信号的机器学习模型来重建解码的音频信号(操作1560)。
用于瞬态信号的机器学习模型可以基于被分类为瞬态信号的原始音频信号和解码的音频信号进行机器学习。用于稳态信号的机器学习模型可以基于被分类为稳态信号的原始音频信号和解码的音频信号进行机器学习。因为稳态信号和瞬态信号具有不同的特性,并且音频重建设备100分别地学习稳态信号和瞬态信号,所以可以有效地重建解码的音频信号。
已经参考本公开的各种实施例具体地示出和描述了本公开。本领域普通技术人员将理解的是,在不脱离本公开的范围的情况下,可以在形式和细节上进行各种改变。因此,上述实施例应仅在描述性意义上考虑,而不是出于限制的目的。本公开的范围不是由以上描述限定,而是由所附权利要求限定,并且从权利要求及其等同物限定的范围得出的所有变型将被解释为包括在本公开的范围内。
本公开的上述实施例可以被写为计算机程序,并且可以在通过使用计算机可读记录介质执行程序的通用数字计算机中实现。计算机可读记录介质的示例包括磁性存储介质(例如,rom、软盘和硬盘)和光学记录介质(例如,cd-rom和dvd)。
- 还没有人留言评论。精彩留言会获得点赞!