用于声音场景分类的基于分段的特征提取的制作方法
本发明涉及音频处理,尤其涉及从音频信号中提取特征,例如,这些特征可以在采用声音场景分类的应用场景中使用。
背景技术:
声音场景分类(asc)是指一种技术,通过这种技术,仅根据在这些环境中记录的声音来识别环境的类型,例如,汽车、办公室、街道、餐馆等。尤其是,每个环境的特点是在该环境中发生或由环境本身产生的声音事件。
环境识别的主要方法是将具有环境特征的声学指纹与语义标签联系起来。为此,可以首先基于具有已知类型(标签)的声音场景的训练集导出特征向量。然后,所述特征向量可用于为与所述特征向量相关联的各个类型训练统计模型(s模型)。这种经过训练的s模型本质上包含属于同一类型(类)的环境声学景观的属性。在该学习阶段(训练)之后,其他尚未标记的声音记录与最匹配其各自特征向量的类型相关联。
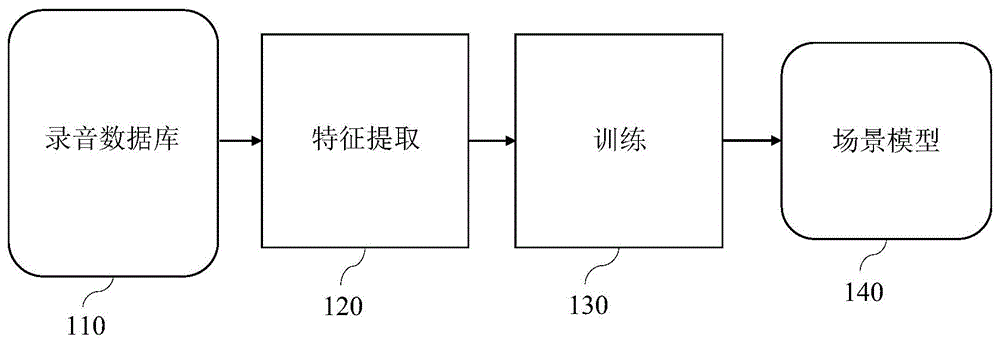
如图1和图2中的示例所示,一般而言,asc过程可分为训练阶段和分类阶段。图1举例说明了训练阶段的各个阶段。音频记录数据库110存储各种音频信号的记录,对应于具有相应场景标签的已知场景。对于已知录音,可以执行特征提取120。然后将获得的特征向量和已知场景的相应标签提供给训练130。训练的结果是基于来自数据库110的已知音频记录的场景模型140。反过来,分类230的结果包括:基于训练130的结果的已知场景模型240,通过从未知音频记录210中特征提取220进行场景识别250。
在图1所示的示例中,训练阶段涉及通过合适的分类器,例如支持向量机(supportvectormachine,简称svm)、高斯混合模型(gaussian-mixture-model,简称gmm)、神经网络等估计场景模型。这些分类器之一用于训练阶段130。训练阶段基于特征提取阶段120的输入,使用从音频记录数据库110已知记录中提取的音频特征,生成学习到的场景模型140。
图2示例性地描述了一个分类阶段。在该示例中,输入音频记录210以进行分类。在与训练阶段的阶段120相对应的阶段220中,从输入音频记录210中确定特征向量。根据场景模型240执行实际分类230,所述场景模型240对应于在阶段140中导出的场景模型。然后,分类器230为输入的音频记录210输出音频场景250的识别的类型。
换言之,在图2所示的分类阶段中,现在在阶段220中基于已知(即,习得的)场景模型240从未知音频样本210中提取相同的特征。如场景模型240所示,这两个基本输入用于根据训练后的声音场景对声音场景250进行分类230。
asc的一个重要部分是从音频信号中定义和提取那些被认为是特定环境的音频特征的特征。为此,asc系统一直在开发各种音频特征类型,主要借鉴了那些通常用于语音分析和听觉研究的特征。例如,这些类型根据以下一项或多项:
–基于时间和频率的低级特征,例如音频信号的过零率或频谱质心,
–频带能量特征,测量音频信号不同子带内的能量数量,
–听觉滤波器组,其中滤波器组用于模拟人类听觉系统用于分析音频帧的响应,
–倒谱特征,基于mfccs系数(mel-frequencycepstral,简称mfccs),用于捕捉声音的频谱包络。
–多声道录音的空间特征,如:音频间时间或电平差,
–基于基频估计的语音特征,
–基于自回归模型的线性预测系数
–无监督学习特征,其中对音频信号的基本属性进行自适应编码,即根据一定的准则进行迭代学习特征,
–矩阵分解法,将声信号的谱图描述为基本函数的线性组合,
–从音频信号的恒定q变换的图像中提取的图像处理特征,
–基于事件的直方图进行事件检测,例如在音频信号中检测到狗吠,汽车经过,枪击,玻璃制动器等事件。通常,事件是音频信号中与其余信号能量不同的任何部分(例如rms)。
几种asc方法是已知的。例如,在2013年“j.南,z.亨和k.李写的基于事件检测的稀疏特征学习和选择性最大池化的声音场景分类、2013年声音场景和事件的检测和分类的ieeeaasp挑战”中提出的方法将稀疏特征学习方法应用于asc。该方法基于稀疏的限制玻尔兹曼机(boltzmann)机,并提出了一种合并特征的新方案。考虑到声音场景数据中音频事件发生的不规则性,该方案首先检测音频事件,然后仅对检测到的事件执行合并。通过阈值化局部隐藏单元的平均特征激活来检测事件。在此上下文中使用的目标特征是mfccs。
由cotton,courtenayv等于2011年ieee国际会议语音和信号处理(icassp)发表的文件《基于瞬态事件的声迹分类》。2011年,ieee提出一种基于声迹分析的视频分类方法。作者研究了一种关注与声音事件相对应的音频瞬态的方法。由此产生的事件相关特征有望比传统的基于帧的统计更好地反映音轨的“前景”并捕捉其短期的时间结构。通过跟踪输入信号的幅度短时傅立叶变换(stft)表示的每个通道的时间演变,并通过将这些值与基于其本地(时间)平均值的阈值进行比较,来检测事件。
已经存在各种事件识别技术,并且可以将其整合到asc方案中以提高声音分类器的性能。虽然在强约束的分类场景中,确定某些事件确实有助于描述一般环境,但这些方法在真实环境中仍存在一些缺点,例如:
1.声音事件需要手动定义和选择。
2.真实环境中的大量声音事件,使得定义、选择和识别(分类)所有事件变得不现实。
3.在特定的声学环境中,有些声音事件必然出现,而有些声音事件在不同的声学环境中也能听到。
因此,基于音频事件检测(aed)的技术不能直接应用于受到软约束的asc问题,因为表征特定环境的声音事件集通常不受限制并且极难推广。
技术实现要素:
鉴于上述问题,本发明不识别特定事件,而是识别通用事件类型。本发明基于一项观察,即在声音场景不同的情况下,根据三个事件类型(短事件、长事件和背景)提取的特征可提供不同的统计。
因此,本发明的技术可以改进特征提取阶段,从而改进声音场景分类。
根据本发明的一个实施例,提供了一种用于音频样本块的声音场景分类的装置。所述装置包括:处理电路,用于在所述时域中将所述块分割为帧;对于所述块的多个帧中的每个帧,计算所述帧与所述块的前一帧之间的变化量;将所述帧分配给短事件帧集合、长事件帧集合和背景帧集合其中之一;根据所述短事件帧集合、所述长事件帧集合和所述背景帧集合计算出的特征确定特征向量。前一帧是该帧的上一帧,这提高了所述方法的可靠可以性。在一个实施例中,将所述帧分配至所述短事件帧集合、所述长事件帧集合或所述背景帧集合其中之一是基于多个(例如,两个)变化量,每个变化量衡量帧相对于前一帧的变化(例如,在所述帧之前的第一n帧可用于估计所述变化量n≥2)。两个帧之间的变化量可以根据两个帧的频谱表示来计算。在一个实施例中,所述多个帧包括所述块的所有帧,除了所述块的第一(即最早)帧(所述块的第一帧缺少所述块的前一帧)。
所述处理电路还用于确定所述短事件帧的集合,包括:对多个相应帧计算的所述变化量值进行高通滤波;根据第一预定阈值检测所述高通滤波后的变化量中的峰值;将检测到所述峰值的帧分配至所述短事件帧集合。
所述处理电路还用于确定长事件帧集合,包括:对所述变化量值进行低通滤波;根据第二预定阈值检测所述低通滤波后的变化量中的峰值;将检测到所述峰值的帧分配至所述长事件帧集合。
根据本发明的一个实施例,所述处理电路用于根据检测到的所述峰值的峰值高度ph、所述峰值高度与所述峰值之前的低通滤波变化量中的第一峰谷的第一差值g1、和/或所述峰值高度与所述峰值之后的第二峰谷的第二差值g2,和阈值t,通过添加变化量长事件区域对应的低通滤波变化量中检测到的峰值附近的帧来扩展所述长事件帧集合变化量
包括处理电路的装置用于根据所述长事件峰值的峰值高度及g1和g2的最小值来更新所述阈值t,如下:
t=ph-min(g1,g2)。
所述装置从所述长事件峰值沿先前帧的方向和/或沿后续帧的方向,在帧基础上通过添加对应帧至所述长事件帧集合对所述长事件区域进行扩展,直至所述帧的所述变化量低于所述阈值t;如果所述帧同时为长事件帧和短事件帧,则将所述帧从所述长事件区域对应的长事件帧集合中删除。
根据本发明的一个实施例,所述处理电路用于将所述背景帧集合确定为既非短事件帧也非长事件帧的帧。
根据本发明的一个实施例,所述处理电路使用复域差值作为所述变化量。
根据本发明的一个实施例,所述处理电路根据事件相关特征中的至少一项计算所述特征,包括事件分数、事件计数、活动级别和事件统计。
根据本发明的一个实施例,所述处理电路根据与帧相关的特征中的至少一项计算所述特征,包括频谱系数、功率、功率谱峰值和谐波性。
根据本发明的一个实施例,所述块的帧是重叠的。
根据本发明的一个实施例,所述处理电路通过将所述帧乘以窗函数和傅里叶变换来变换所述帧。
根据本发明的一个实施例,所述处理电路基于所述特征向量对所述声音场景进行分类,所述特征向量包括从每个所述短事件帧集合、每个所述长事件帧集合和每个所述背景帧集合提取的所述帧相关特征和所述事件相关特征,以及从所述块的所有帧提取的特征。
根据本发明的一个实施例,提供了一种音频样本块的声音场景分类方法,将所述块在时域中分割为帧;对于所述块的多个帧中的每个帧,计算所述帧与所述块的前一帧之间的变化量;根据所述各自计算出的变化量,将所述帧分配至短事件帧集合、长事件帧集合或背景帧集合其中之一;根据所述短事件帧集合、所述长事件帧集合和所述背景帧集合计算出的特征确定特征向量。
根据本发明的一个实施例,提供了一种计算机可读介质,用于存储指令,当其在处理器上执行时,使得处理器执行上述方法。
附图说明
下文将参考以下附图详细描述示例实施例:
图1为通过基于从录音数据库中提取特征的训练来建立声音场景模型一个示例的示意图。
图2为基于训练的场景模型通过从实际音频记录中提取特征进行场景识别一个示例的示意图。
图3为根据事件相关特征对音频记录进行分段的四个级别的过程一个示例的分层示意图。
图4为通过使用分段分割方法结合帧相关lld和事件相关lld来构建联合特征向量一个示例的示意图。
图5是将帧分段分割为三个事件层以及确定特征向量一个示例的流程图,所述特征向量包括基于短事件、长事件和背景计算的事件相关特征和帧相关特征。
图6是用于将音频分割为三个事件层的装置一个示例的示意图,通过使用复域差值作为变化量来举例说明。
图7比较了七个样本声音场景基于事件和帧的声音场景分类的性能。
具体实施方式
本发明涉及通用音频信号处理领域。特别地,本发明涉及用于声音场景识别、声音场景分类(asc)等声音场景分析应用的基于机器学习的方法(包括深度学习方法)。本发明可以应用于智能电话/平板电脑或智能可穿戴设备的环境感知服务中,基于对场景的声音特征的深入分析,能够对其环境进行评估。
更具体地,本发明涉及音频信号的特征提取,所述特征表征特定环境。提取的特征可用来将不同环境的录音文件分类。改进特征提取方法可以提高声音场景分类的准确性或鲁棒性。
本发明描述了一种用于提取音频特征的技术(例如,用于asc)。所述技术包括将音频信号分割为三种类型的分段(在本文中也称为事件类型):长音频事件、短音频事件和背景。这种分段可进一步分析每种类型的分段的贡献。场景识别可以基于低级的音频特征,这些音频特征按照每个事件类型聚合(例如,通过特征平均值)。或者另外,场景识别可以基于新特征,称为事件相关特征,并且基于对某种类型(一个分段)的事件的评估,例如通过统计(例如,在预定时间内特定类型的事件的数量、特定类型的事件数量之间的比率、特定事件的帧的数量等)。因此,所述技术可以根据高级(语义)语义和场景的特定属性(如活动、亮度、谐波性等)改进不同声音场景的区分。
所提出的将声音场景分割为三种类型的分段的方法,目的是将所分析的声音场景分割为与事件类相对应的三个基本“层”。这些分类是通过检测和区分短事件和长事件发现的,而信号的其余部分则归为背景类。将场景分割为三个事件类型可以通过新特征提供额外的信息,这些新特征可以进一步分类。
这种与短、长事件有关的声音特征是显着的声音特征。在目前的技术中,这些声音特征用于提供可靠的和改进的声音场景分类,因为它们包含关于录音内(全部或部分)声音事件的动态和持续时间的重要信息。
因此,基于通过将音频输入信号分成这三个帧集合并且通过在每个帧选择上分别提取与期望的描述符所确定的特征,本发明提出的特征定义和提取使得声音场景的识别和分类更加有效,而不是在所有帧上不加区分地提取。这种方案允许进一步定义新特征,所述新特征可以添加至扩展特征向量中。图1中的特征提取120、对应的图2中的220分别基于用于训练130和分类230的改进的特征向量来提取特征。这样对学习到的场景模型140进行了改进,使得场景识别250更加准确。
特别地,在本发明中,例如在声音场景分类器中提供并使用了改进类型的特征定义和提取。这些特征是从对待分类的输入音频信号进行的分段过程中提取的音频部分提取的。
在一个实施例中,提供了一种处理电路,用于将音频信号块分割为帧。
音频信号块可以是例如具有预定长度(例如由用户设置)的音频信号的一部分,或者可以是待分类的整个音频信号。其中包括时间域中的音频样本,例如,以一定采样间隔(秒)获取的音频信号样本。所述样本可以形成模拟值或数字值的序列。采样率、数字化/量化类型和步长的具体值对本发明不重要,可以设置为任何值。帧的大小小于块的大小。例如,对应于音频块的音频信号部分的典型长度可以为5~30s,并分为1024个音频样本,在这种情况下,帧的长度约为5~30ms。通常,帧是k个样本的序列,即数字值,其中k为大于1且小于所述块中的样本数量的整数。
所述处理电路进一步将样本帧变换成频谱系数的相应帧。可以对所述块的每个帧执行所述变换。然而,本发明并不限于此,通常,一些帧可以在分析中省略。需要注意的是,在将已经变换的帧作为输入提供给处理电路的情况下,可以省略块分段和变换步骤。例如,可从存储器中读出变换后的帧。例如,如果使用预处理的变换帧来压缩音频信号并且音频信号已经以压缩形式存储,则这种方法可以是有益的。
然后,所述处理电路为所述帧计算所述频谱系数帧与其至少一个先前相邻帧之间的变化量。所述变化量是通过将当前帧的音频频谱与至少一个前一帧的音频频谱进行比较来衡量块内的音频内容的变化程度。需要注意的是,变化量可以扩展到多个先前帧。例如,这种变化量可以是当前帧的频谱与m个先前帧的加权频谱之间的差值,m为大于1的整数。所述权重可随着加权帧与当前帧之间的距离的增大而降低。这种变化量可以更好地在帧的基础上捕获音频块内音频信号的自相似性。然而,当前帧频谱与其前一帧频谱之间的简单差值(或其绝对值)可提供良好的结果。在这种情况下,帧的频谱可以由应用于帧的频谱系数的度量表示,以得到单个值,例如平均值、方差、加权平均值等。另一方面,还可以计算两个帧(当前和紧挨着的前一帧)的相应频谱系数之间的差值并求和或取平均值,或者可以计算两个帧的频谱之间的相关性。换言之,本发明不限于任何特定的变化量。
此外,所述处理电路将所述帧分配至短事件帧集合、长事件帧集合和背景帧集合其中之一,根据所述短事件帧集合、所述长事件帧集合和所述背景帧集合计算出的特征确定特征向量。
可以对音频信号块的每一帧执行上述分配至短事件帧、长事件帧或背景其中之一。这样将整个音频块细分为三个分段或层,之后一些特征可以聚合成为特征向量的一部分。然而,本发明并不限于对每一帧执行分配。由于各种原因(例如,降低复杂度或其他原因),仅可以将帧的子集分配给上述三个分类之一。此外,帧分类的方法可以扩展到包括三个以上分类(分段)的事件。
换言之,本发明通过应用长事件和短事件函数对音频信号进行分段来定义和提取特征(限定在特征向量中),通过这些分段提供音频信号的三个部分,即长事件、短事件和背景分段。按照帧级别提取的低级特征,通过统计函数(例如,平均值计算)对每个获得的分段进行聚合。此外,还定义和实现了分段过程所启用的新特征(事件相关特征)。这两种类型的特征的组合有助于更好地区分声音场景类型。
这里的“短事件”是指发生在大约一帧时间内的事件,如枪声、关门声或手指啪啪声等。然而,需要注意的是,本发明并不限于此,还可以在预定数目的帧中检测到短事件。
这里所说的“长事件”是指比短事件长的事件,即,不属于短事件,例如,汽车和/或火车通过的声音、电话铃响、狗吠等。这些类型的事件由音频信号和/或其频谱在一定时期内的变化量确定。
术语“背景”是指音频信号,不包括短或长事件。然而,本发明不限于这种背景的定义。背景帧可以定义为那些音频变化到前一帧的帧数低于一定阈值的帧。如果超过三个类型,背景帧也可以定义为不属于任何其他类型的帧。
在一个实施例中,分段过程根据声音场景内检测到的音频事件的属性将输入帧标记为三个不同层,即短声音事件、长声音事件和背景声音事件。
这种音频特征提取方法特别适用于asc,可以应用在各种不同的应用中。例如,音频信号的编码器和解码器可以利用音频场景分类来对某些场景进行不同的压缩。
本发明还可以应用于基于电话的asc,其中电话识别其所处的环境,并基于所述位置设置不同的振铃模式,例如振铃音量(静音或响亮)、特定振铃声音等。例如,在响亮或事件丰富的环境中,振铃音可以比在无声或事件差的环境中设置得更响。
本发明的还可以应用于智能耳机,例如当用户在公园跑步时,它可以识别声环境(如街道)并自动打开耳机模式。
此外,本发明还可应用于智能手机/平板电脑或智能可穿戴设备的环境感知服务。通过深入分析场景的声音,它有助于使设备了解其环境。
而且,asc可以用于可以的基于上下文的语音识别和语音控制,例如智能助手服务。另一个用例可以是对某些场景的识别,这些场景自动控制,例如,触发警报或监控/监视摄像机。
一般而言,声音场景分类(asc)的过程可以分为训练和分类阶段,如图1和图2所示。
图1说明了训练阶段,其中学习了场景模型。使用音频记录数据库,从音频记录样本中提取一组已知特征(特征向量)。所述特征可以包括基于上述短事件、长事件和/或背景帧计算的特征。然后,特征向量与分类的已知期望结果一起作为输入,以改进或估计分类器的参数,即训练分类器。例如,分类器可以是支持向量机(supportvectormachine,svm)、高斯混合模型(gaussian-mixturemodel,gmm)、神经网络等。
图2说明了分类阶段,其中提取了相同的特征向量,但是现在从未知(尚未分类)的音频记录样本中提取了相同的特征向量。将特征向量输入到如图1所示训练的分类器,即实现通过对具有已知分类结果的音频记录样本进行训练而得到的模型。然后,分类器识别(分类)输入声音场景,即,将输入声音场景指定为类。例如,音频场景(例如,上述提到的音频块)可以归类为火车站、商场、高速公路等。基于上述短事件/长事件/背景细分的asc的一个好处是,不需要检测特定环境特有的特定事件。这为所述方法提供了更容易的扩展性,可应用于新的环境。一方面,基于仅在相同类型的帧上计算的度量而计算出的特征向量的分类,可以表征不同的事件,从而将这种表征映射到不同的相应环境/声音场景上。另一方面,长事件、短事件和背景的帧分类是基于一般事件特征,如事件持续时间和强度,而不是基于对某些环境(如火车站的车轮断裂声、海上的水声等)中预期的特定音频声音的识别。
图3为本文公开的技术一个示例的俯视图。所述技术分为四个级别:
级别1:在第一级别上,示出了一种设备的一般表示,该设备使用上述方法通过基于分段的特征提取320从音频记录310(输入)确定特征向量330(输出)。
级别2:在第二级别上,将基于分段的特征提取进一步细分为两个函数块,其中,通过音频波形340的变换,首先将传入的音频记录拆分为合适的基于帧的表现形式。接下来是将基于帧的音频信号分割(360)为三个基本分段(对应于事件类型),即短事件、长事件和背景事件层。本发明的核心是利用三个不同分段(事件层)来检测典型特征以区分不同类型的声音场景。
级别3:在第三级别上,音频波形由块划分器341变换为块部分,每个帧都由成帧器342分割为重叠的帧表示。例如,音频信号的块通过具有块持续时间的窗函数(例如矩形窗口)进行分段行。然而,本发明不限于此示例。音频记录的块也可以是重叠的。另一方面,帧可以是不重叠的。帧级别的重叠更利于待计算的变化量。
例如,音频波形可以是已经采样和数字化的音频信号,即,音频样本的序列。然而,本发明并不限于此,实施例的装置还可以包括数字化单元(采样和模数变换)。本发明还可以在模拟信号上工作,但是模拟信号不如数字信号操作实用。
在将变换后的音频分割为三种类型的层之后,提取(361)每层基于低级描述符(lld)的低级特征,并且计算(362)与事件相关的特征。
级别4:在第四级别上,聚合器363对每层(事件类型)提取的基于帧的lld350进行统计聚合。通过将特征合并(364)到特征向量330中作为输出,将聚合的特征与计算的事件相关特征362组合。
这种方法的一个优点是提供了关于短事件和/或长事件发生的补充信息。该信息可结合层特征用作其它输入特征,以便根据其短声音、长声音和背景声指纹对声音场景进行分类。
该方法的另一个优点是,基于三层的分段引入了新颖的特征,可以将其添加到先前提取的lld中。这样,可以得到扩展的最终特征向量(联合特征向量jointfeaturevector),对音频场景进行分类。
图4示出了联合特征提取器400的一个可能实施例。音频记录410等输入信号被块划分器420划分为相等长度的一组不重叠的音频块,例如,块长度约为几十秒。结果是一些长度为30秒的非重叠音频块。在图4的例子中,采样频率fs等于16khz,即每秒16000个采样。
根据所述技术的另一实施例,所述音频记录可以划分为非等长音频块。例如,如果所述音频记录包含具有相应不同时长(至少是预先大致已知)的不同音频场景,则可以应用所述方法。
根据该技术的一个实施例,使用如汉恩窗的窗函数来执行音频信号的帧和/或块分段。其他窗函数也可以使用,包括汉明、受限高斯、韦尔奇、正弦等适用的函数执行窗口。
然后,每个音频块由成帧器430分为等长的n重叠帧。例如,帧块可以由几百个样本组成。例如,一个音频块的典型长度为5~30秒,分为1024个音频样本长度的帧,该帧的长度约为64ms。如下所述,基于帧的定义音频将在处理链的其他步骤中使用。
一个音频块的重叠帧集合是低级描述符(lld)提取器450和划分分割器440的输入。
所述低级描述符提取器450从每个帧中提取一个或多个典型lld。d.鲍奇西、d.甘诺利斯、d.史托威尔和m.d.庞普利在《声音场景分类:根据声音产生的环境对它们进行分类》,2015年ieee信号处理杂志,第32卷第3,第16~34段中提供了(但不限于)可能的lld,例如:
–频谱峰值频率和/或频谱峰值,
–哈马伯格指数(0.2khz~2.5khz频带最大能量之间的差值)。
–阿尔法比(在低频范围(例如0.5-1khz)和高频范围(1-5khz)之间计算的能量比)
–谐波性度量(例如谐波功率与总功率之比或频谱不是谐波的高频率等)
–频谱平坦度
–功率
–频谱距心
等。
换言之,对于每一帧,确定(计算)一个或多个上述lld。
划分分割器440通过从一个音频块的输入帧中计算短事件和长事件检测函数的函数值来执行短事件和长事件的检测,下文将进一步详细描述。因此,根据这些输入帧对短事件,长事件和背景的隶属关系为其分配一个类型。划分分割器分别产生与短事件、长事件和背景相关的帧索引。分割器440还可以输出一个或多个与事件相关的特征,例如属于短事件层的帧的数目、属于长事件层的帧的数目、与背景层相关的帧的数目或短事件的数目和/或长期事件的数目。
将每个帧分配至短事件,长事件和背景三层其中之一的优点是,除了已知的基于帧的、不区分不同事件类型的帧的lld之外,还可以获得每层聚合的帧相关特征和事件相关特征。例如,与帧相关的特征频谱平坦度可以计算为与某一分段(层)相关的块中所有帧的频谱平坦度的中值,例如与长事件相关。本发明并不限制特征向量仅包括用于单个层的帧相关特征。特征向量还可以包括对所有层的帧计算的帧相关特征。此外,可以提供组合特征,例如对单个层的帧计算的帧相关特征与对所有层的帧计算的帧相关特征之间的比例或差异。另一种可能性是引入特征,所述特征是对各个不同层计算的帧相关特征的加权平均值。
聚合器460执行帧相关特征的计算。例如,聚合器460在其输入上获得分配至各个层的帧的索引,并且实现对一个或多个各种聚合器的计算,例如,如上所述的平均值、中值、标准偏差、最小值、最大值、范围等。该聚合的结果是基于单个音频块的帧或更多此类特征的帧的相关帧特征。此外,所述聚合还可以提供额外特征的聚合,例如帧数量中的长事件长度的聚合函数的最小值、最大值、平均值或其他特征。可以对其他层的特征进行相应的聚合。
由聚合器460确定的帧相关特征和/或由划分分割器440确定的事件相关特征和/或由聚合器460在整个块上计算的特征,然后组合成音频块的特征向量470。
该扩展的特征向量470在训练和分类阶段的特征提取阶段120和220中使用,以便分别提供改进的场景模型140,以基于(训练的)场景模型240识别场景250。
图5为音频块分段方法的流程图,其中包括根据短事件、长事件和背景将音频块的帧分组至三个事件类型中。
由块划分器420输出的音频块在前述步骤中被分割为一组等长的n重叠帧,例如,由成帧器430执行。或者,可以对音频块进行分割,使得相应帧不重叠。
分段过程的第一步包括(步骤510)每个帧的变换,以获得帧的频谱系数,分别对应于频谱图。完成帧分割,。例如先将所述块样本乘以窗函数,例如汉恩窗函数,以得到帧,然后对得到的所述帧进行离散傅里叶变换(discretefouriertransform,简称dft)。使用除矩形窗口以外的窗口进行窗口处理可确保通过变换得到的频谱受到限制。
也可以使用其他窗函数,包括适合执行上述窗口的汉明函数、受限高斯函数、韦尔奇函数、正弦函数等。
为了量化音频块内的音频变化,然后根据帧频谱计算帧(步骤520)的变换量cm(对应于变化量函数),当前帧n与其至少一个先前的相邻帧n′之间的具有n′<n,且n表示帧索引。需要注意的是,帧索引n对应于离散时间tn,与帧索引意思相同,即,n≡tn具有1≤n≤n的变化量函数值cm(n)还可以用作输入到聚合器460的低级描述符lld。
根据本发明的一实施例,所述变化量cm是复域差值cdd,在这种情况下,需要通过帧n之前的两个帧来确定帧n的cdd。
根据为具有1≤n≤n的n帧计算变化量cm(n),将第n帧分配至与短事件帧集合、长事件帧集合和背景集合三个集合其中之一。将一个帧分配至三个集合其中之一要经过多个阶段。
接下来,短事件帧集合通过变化量值的高通滤波(步骤530)确定,由变化量函数cm(n)表示。滤波的结果为短事件函数sef(n)。与cm(n)类似,所述sef(n)还可以用作低级描述符lld并输入到所述聚合器460中。
在使用复域差值cdd作为变化量的情况下,可以通过从函数cdd(n)中减去应用于cdd(n)的(因果)中值滤波器(medfil{n})的结果来实现高通滤波。由于中值滤波器是低通滤波器,因此从cdd中减去cdd的低通滤波器部分后,高通部分仍然存在。类似的滤波可以应用于其他变化量。该方法提供了一种简单有效的高通滤波实现方法。需要注意的是,可以使用其它低通滤波器来代替中值滤波器。
通过根据第一预定阈值(步骤532)检测短事件函数sef(n)中的峰值,并将与检测到的峰值对应的帧添加到短事件帧集合中,从而确定短事件帧集合。换句话说,如果sef(i)超过第一预定阈值,则可以为帧i检测峰值。可以通过存储这些与短事件类型相关帧的索引来实现将帧添加到短事件帧的集合中。
根据本发明的一个实施例,如果变化量函数cm(n)基于复域差值函数cdd(n),则在高通滤波cdd(n)内检测峰值。应注意,本发明并不局限于此类测定。也可以在所述cdd和/或cm任何使用中直接检测所述峰值。然而,高通滤波可以更好地区分短事件的高频变化特征。
接下来,长事件帧集由步骤540中的变化量函数cm(n)的低通滤波确定,并将长事件函数lef(n)作为输出。与所述sef(n)类似,所述lef(n)还可以用作低级描述符lld并用作所述聚合器460的输入。
在使用复域差值cdd作为变化量的情况下,低通滤波可包括从函数cdd(n)中减去相应的短事件函数sef(n)。这意味着从表示cdd的帧集合中有选择地删除短事件帧集合。然后,通过应用中值滤波器(medfil{n})以及随后的移动平均滤波器(movavgfil{m}),对该操作的结果进行进一步滤波,从而得到长事件函数lef(n)。该滤波过程仅仅为一个示例。本发明不限于此。通常,低通滤波可以通过任何其它方式执行。例如,可以仅通过cm减去sef得到lef,甚至作为用于获得所述sef的中值滤波cm。
根据第二预定阈值(步骤542),通过检测低通滤波变化量中的峰值来确定长事件帧集合,如长事件函数lef(n)所示,并将检测到的峰值对应的帧添加到长事件帧集合中。峰值检测可以通过检测帧索引等lef(n)中的局部最大值来执行,分别对应lef的本地局部最大值。
由于长事件帧包含有关检测到的事件的持续时间的信息,因此预计会在每个检测到的峰值周围的相邻帧上扩展,因此通过计算长事件区域(步骤544)来补充峰值检测(步骤540)。这一区域内的相应帧也包含在长事件帧集合中。根据检测到的峰值的峰值高度ph、在峰值高度和长事件函数lef(n)内的第一个和第二个峰谷之间(第一个峰谷在峰值之前/第二个峰谷在峰值之后)的第一g1和第二差值g2,和阈值t,在检测到的长事件峰值(对应于长事件帧)附近计算这一区域。
对于已知的峰值高度ph(在步骤542中检测到)及其相邻的两个峰谷,即峰谷差值g1和g2,先根据t=ph-min(g1,g2)更新阈值t。然后,将峰值对应的帧作为中心帧,通过将所述帧添加到所述长事件帧集合中,在所述中心帧的两个方向上的帧n基础上扩展所述区域,直到变化量函数cm(n)低于(或低于-等于)阈值t。最后,从长事件帧集中删除既是长事件帧又是短事件帧的帧,从而形成长事件区域。
确定背景帧集合既不是短事件帧也不是长事件帧(步骤550)。不需要将该步骤作为存储此类帧或其索引的显式步骤来执行,而只需假设与长事件或短事件不相关的索引的帧属于背景层。换言之,背景帧是与短事件帧和长事件帧的集合的并集互补的帧集合。
这样就完成了一个块的帧的分段过程,包括由它们对应的帧索引表示的三个帧集合(短事件、长事件、背景)、变化量函数、cm(n)以及短事件和长事件函数(分别为sef(n)和lef(n)),作为低层描述符lld。
通过执行步骤510到550,根据计算出的音频变化量cm,将音频块的所有n帧分为三个事件类型,可以为三个帧集合中的各个帧和/或一个帧集合中的所有帧计算各个特征(步骤560)。这两种特征确定特征向量,输出该特征向量并将其添加到最终特征向量470中。
如上所述,可以对短事件帧集合、长事件帧集合和背景帧集合其中之一计算特征。换言之,这些计算出的特征是音频块中发生的特定事件(短、长或背景)的特征,定义了新的事件相关特征。所述与事件相关的特征是特征向量的一部分。
可能的事件相关特征包括,例如,事件分数、事件计数、活动级别、事件统计和不规则性。为了便于说明,通过计算在音频块内发生的事件之间的平均间隔(即,对应于时间间隔的平均帧索引间隔)来确定活动水平。基于活动水平(平均),通过计算事件间间隔的标准偏差可以直接获得不规则性。事件相关特征不限于上述列表,还可以进一步扩展,具体取决于具体应用场景。
除了上述事件相关的特征外,通过基于帧的频谱、首先为短事件帧集合、长事件帧集合和背景帧集合中的至少一个集合中的每一帧计算对应于一个低级描述符(low-leveldescriptor,lld)的至少一个低级特征,来确定帧相关的特征。所述lld特征包括,例如,频谱峰值、频谱峰值频率、哈马伯格指数、阿尔法比、谐波性、频谱平坦度功率、频谱距心等。然后,将三个事件层集合中一个集合的所有帧计算的lld特征聚合在一起。这些聚合特征是指与帧相关的特征,因为它们是基于三个帧类型中的一个帧类型的所有帧得到的。可以通过以下聚合器执行lld特征聚合,例如平均值、中值、标准偏差、最小值、最大值等。
在步骤560中计算的这些与事件和帧相关的特征被合并,确定特征向量,并作为输出。只要提供(输出)待包含在特征向量中的特征,例如,通过提供存储这些特征的存储器中的地址或输出这些特征的值以供进一步使用(训练、分类、显示),不需要单独执行合并这个步骤。
换言之,在步骤570中,提供分段过程的结果和特征计算作为输出,过程结束。输出内容包括特征向量、三个帧索引集合(短事件、长事件、背景)和/或作为新lld提供给聚合器460的函数cm(n)、sef(n)和lef(n)。
如上文所述,分段过程(步骤510至570)分别由划分分割器440输出的其它lld与由低级描述符提取器450从原始帧中提取的lld一起使用(即,在成帧器430之后的非层特定帧),作为聚合器460的输入,从而得到与帧相关的特征(块级)。所述聚合器与帧分段中使用的聚合器相同或相似。这些特征与在步骤560中确定的特征向量和在步骤570中输出的特征向量(对应于划分分割器440的输出)组合在一起,形成最终特征向量470。
然后,基于所述特征向量470对所述声音场景进行分类,所述特征向量470包括对短事件帧集合、长事件帧集合和背景帧集合中的每个集合提取的事件相关特征和帧相关特征,以及对所述块的所有帧提取的那些特征。
上述方法通过添加新的事件相关特征来提供改进的特征向量470,同时,除了提取的lld450之外,还提供事件相关低级描述符,所述提取的lld450用于通过聚合(460)计算帧相关特征。这样,特征提取阶段形成了学习阶段(参见图1,阶段120)和分类阶段(参见图2,阶段220)的关键构建块,提升了特征提取阶段。具体地,学习阶段可以提供更准确的场景模型(140),因为特征提取120使用扩大后的特征向量,包括新事件相关特征。分类阶段具有两个优点,因为使用了改进的(经过训练的)场景模型(作为场景模型参考)和改进的特征向量。只有通过将音频块的每个帧分为三个事件类型并将新的lld和与事件相关的特征添加到最终特征向量中,才能实现这些优点。
所述方法步骤510至570对应的指令用于通过从音频样本块中提取特征向量来对声音场景进行分类,包括将所述块分割为帧;将样本帧变换为相应的频谱系数帧;为所述帧计算所述频谱系数帧与其至少一个先前相邻帧之间的变化量;根据各自计算出的变化量,将所述帧分配给短事件帧集合、长事件帧集合和背景帧集合其中之一;根据所述短事件帧集合、所述长事件帧集合和所述背景帧集合计算出的特征,确定并输出所述特征向量。所述指令存储在计算机可读介质上,当其在处理器上执行时,使得处理器执行所述方法的步骤。
图6示出了本发明用于将音频信号分为三个事件类型的一个实施例,如用于变化量的复域差值(cdd)的示例所示。图6的示意图示出了联合特征提取器600,包括处理电路,所述处理电路用于将音频块划分为三个事件层层和执行基于层的特征提取,如下所述。
将对应于成帧器430的输出的一个音频块的重叠帧(n音频样本)的集合输入到窗口和dft单元610中。窗口和dft单元610根据窗函数,例如汉恩窗函数,通过首先将帧乘以分析窗口(窗口)来计算块的每个帧的频谱系数(谱图)。
也可以使用汉明、受限高斯、韦尔奇、正弦等其它适用的窗函数来执行加窗。
然后,对加窗的帧进行离散傅里叶变换(dft),以频谱系数(即帧的频谱)的形式获得每个n帧的频谱表示,这些系数对应于帧的频谱图。需要注意的是,术语频谱系数、频谱图和频谱是同义词。
然后,根据每一帧的谱图计算表示音频变化的变化量cm。在图6的实施例中,变化量基于复域差值(cdd),该复域差值由cdd计算单元620对具有帧索引1≤n≤n的每个帧n计算得出。例如,使用当前帧n和前两个(即,较早的)n-1和n-2帧计算第n帧cd(n)的复域差值,如下:
xt(n,k)=|x(n-1,k)|eψ(n-1,k)+ψ′(n-1,k)(2)
ψ'(n-1,k)=ψ'(n-1,k)-ψ'(n-2,k).(3)
帧索引n频谱图的第k个频谱系数用x(n,k)表示,k的值参考一个音频块的频谱索引(bin)和帧数(音频样本)n。所述cdd622根据等式(1)计算,生成复域差值函数cd(n),所述复域差值函数在音频块上演进了离散帧次数n≡tn,由n帧表示。
根据等式(1),参考目标频谱xt(n,k)计算cdd,ψ′(n,k)=ψ(n,k)-ψ(n-1,k)为第n帧与前n-1帧与频点k的相位差。
变化量cm也可以基于频谱通量、相位导数、相关性等计算。
所述cdd根据等式(1)计算既要考虑起始事件也要考虑偏移事件,即所述事件的相应音频签名会随着增长和衰减而改变。这意味着根据等式(1)计算的cdd同时捕获两种声音动态值,而无需区分它们。
在本发明的另一实施例中,可以扩展cdd时间函数cd(n),计算用于起始事件和偏移事件的单独cdd函数,从而根据起始和偏移声音签名进一步丰富事件相关帧。cdd可以通过以下方式扩展等式(1)来实现。
其中θ表示heavisidetheta函数,θ(y)=1,如果y≥0,则θ(y)=0。
然后等式(1)的cdd函数cd(n)。输入到两个检测单元630和640,以检测cd(n)中的短事件和长事件。两个单元分别通过高通(适用于短事件)和低通(适用于长事件)对cd(n).进行滤波。
在图6的实施例中,相应的滤波单元分别为短事件检测单元630和长事件检测单元640的一部分。
或者,所述滤波可以由外部滤波单元执行。
cdd函数cd(n)(帧索引n对应离散时间索引)可以根据其高通hpf和低通lpf滤波分量再计算,将高频内容和低频部分分离,
cd=hpf{cd}+[cd-hpf{cd}]≡f1+f2(3)
f1和f2指两个中间函数,表示cd(n)的高通滤波分量和低通滤波分量。需要注意的是,术语cd、cd(n)和cdd是同义词,指基于复域差值的变化量cm的一个示例性实现。
在本发明的一种实现方式中,所述变化量cm基于复域差值cdd,在这种情况下,高通滤波在低通滤波之前执行,从cdd中减去cdd(相关的)中值滤波值(medfil{*})
f1≡hpf{cdd}=cdd-medfil{cdd}.(4)
然后,短事件检测单元630基于第一预定阈值通过滤波中间函数f1(参考等式(4))的峰值检出来检测短事件并返回相应帧索引,在帧中检测到峰值。该帧索引用于分别将帧添加到短事件帧集合中,如其各自帧索引631所示。峰值检测到的短事件帧索引集合用于计算短事件帧集合所表示的短事件检测函数sedf632。
在本发明的一种实现方式中,可以在检测到的短事件附件发展短事件区域。这样做的优点是,当检测到紧密间隔的多个短事件峰值时,这些峰值可以合并到短事件簇中。基于检测到的中心帧对应的峰值,可以建立短事件区域。例如,将以下的短事件帧n′添加到该短事件区域,其帧索引n′与中心帧n(对应于时间间隔)之间的差值低于预定阈值。
短事件检测器630的计算输出包括相应的帧索引集合631和检测函数632,以及cdd622,用作长事件检测单元640的输入。长事件检测单元640进行低通滤波和峰值检出,确定长事件帧集合。
在本发明的一种实现方式中,变化量cm基于复域差值cdd,长事件检测器640通过先从cdd函数622减去短事件检测函数sedf632,使用上述提供的输入进行低通滤波。这意味着从表示cdd的帧集合中选择性地移除短事件帧集合631。然后,长事件检测器640还通过计算中值对中间结果(称为cdd2)进行滤波,中值提供中间长事件检测函数iledf。
iledf≡medfil{cdd2}=medfil{cdd-sedf}.(5)
iledf取决于移动平均滤波器(movavgfil{*}),在本实施例中,所述移动平均滤波器被执行两次,生成长事件检测函数ledf642。
ledf=movavg{movavg{iledf}}.(6)
通过检测长事件检测函数ledf642中的峰值来发现长事件帧索引641,相应索引与长事件区域相关,包含关于每个检测到的长事件的持续时间的信息。
在本发明的一种实现方式中,这通过基于相对于两个相邻峰谷的某一相对峰值高度和第二预定最小阈值首先选取ledf中的峰值来实现。各个峰谷的相对峰值高度早于和晚于ledf中检测到的峰值,通过检测到的峰值ph的高度与两个峰谷的最小值(称为g1和g2)之间的差值来确定。与检测到的峰值相对应的帧(帧索引分别为641),指插入到长事件帧集合中的中心帧。
基于检测到的峰的峰值高度ph、差值g1和g2,,和阈值t确定对应于峰值长事件区域的长事件的持续时间。阈值通过以下等式进行更新:
t=ph-min(g1,g2).(7)
从实际检测到的峰值开始,通过将相应帧添加到长事件帧集合中,将长事件区域从峰值附近沿着先前帧和/或后续帧到峰值的方向进行扩展,直到长事件函数ledf的值低于阈值t。需要注意的是,术语“先前帧”和“后续帧”对应具有帧索引(即,离散时间标签)的帧,这些帧索引早于(即,更小)和晚于(即,大于)帧索引n。换言之,从峰值帧索引开始,将索引较低的帧与阈值t进行比较(帧索引减1,并测试每个帧),如果其ledf值超过门限,则计入长事件区域。
在本发明的一种实现方式中,ledf,对应地,变化量cm分别基于复域差值cdd,所述帧被包括在长事件帧集合中,直到所述复域差值的值低于所述阈值t。
最后,从对应于长事件区域的长事件帧集合641中移除长事件帧和短事件帧。
与短事件和长事件相关的输出帧索引631和641用作背景检测器670的输入,通过从一个块的原始帧集合中移除短事件帧631和长事件帧641的集合,确定背景帧索引680的背景帧集合。因此,背景帧集合是短事件帧集合和长事件帧集合的并集的互补。
然后,使用短事件帧集合、长事件帧集合和背景帧集合作为输入,事件相关特征单元690通过计算每个帧帧集合来确定事件相关特征,例如短事件和长事件的计数。
另一个事件相关的特征可通过计算长事件检测函数中的峰值级别之和来计算长事件得分,其中仅考虑通过高级峰值选取方法选择的峰值。
另一个事件相关的特征可通过计算短事件检测函数中的峰值级别之和来计算短事件得分,其中仅考虑高于最小阈值的峰值。另一个事件相关的特征可包括计算归一化长事件检测函数的方差。另一个事件相关的特征可包括计算归一化长事件检测函数的斜率,例如,通过最小二乘线性拟合。另一个事件相关特征可包括活动级别和不规则性特征,活动级别和不规则性特征通过计算事件之间的间隔的平均值和标准偏差得到。
事件检测步骤提供的信息用于定义中级特征。例如,在图6的实施例中,cdd函数622和两个事件函数632和642可用作其它低级描述符并发送到统计聚合器块650(自定义聚合器)以计算帧相关特征660。
上述用于实现特征提取和/或场景分类的装置包括处理电路,所述处理电路在操作中执行音频块序列的事件相关分割。所述处理电路可以是一个或多个硬件部件,例如处理器或多个处理器、asic或fpga或其任意组合。所述电路可用于通过硬件设计和/或硬件编程和/或软件编程执行上述处理。
因此,所述装置可以是软件和硬件的组合。例如,可以将帧划分为短事件、长事件和背景这三个音频类型作为基于帧的分类单元的主要阶段,执行帧相关和事件相关低描述符的联合分类,例如,或者可以将划分集成到分类单元中。这种处理可以由芯片执行,例如通用处理器、数字信号处理器(dsp)、现场可编程门阵列(fpga)等。然而,本发明不限于在可编程硬件上的实现。它可以在专用集成电路(asic)上实现,也可以通过上述硬件组件的组合实现。
根据本发明的一个实施例,所述算法在编程语言python中实现,但也可以由其他任何高级编程语言实现,包括c、c++、java、c#等。
根据本发明的一个实施例和示例,特征提取算法在python中实现,并且由两组函数组成,这些函数按顺序连续执行。
目前的实现方式已经在一组具有相同长度的音频文件(建议长度在5秒和30秒之间)上测试过,因此它们已经代表了实际的音频块。如图4所示,在整体方法的图形概述中,在这种情况下,实际的实现方式不需要包含第一成帧阶段420。
在本发明的一种实现方式中,可以进一步分两个阶段执行基于三个事件层的特征提取。第一阶段执行基于帧的低级特征提取(使用低级描述符lld)和将音频信号块分割为三个事件层,包括短事件、长事件和背景。该过程的结果可以保存在存储介质上,例如,保存在包含层和lld上的结果信息的磁盘上。在使用python作为实现语言的情况下,这些数据最好以pickle文件的形式存储。
整个程序代码可以划分为两个阶段,并使用复域差值cdd作为变化量来量化音频变化,如下所示:
实现阶段1-程序代码结构大纲
·将音频文件加载到numpy数组(scipy.io,numpy)
·将音频文件/音频文件块分割为帧(使用相同的参数计算谱图)调用例程→extractframes()
·计算每一帧的频谱图(使用python库“librosa”)
·基于频谱图执行帧划分:
调用例程→segmentlayers()(包括子例程的调用)
○计算与当前帧相关的复域差值cdd:
调用子例程→complexdomaindiff()
计算短事件函数
○检测短事件函数中的峰值并返回短事件帧索引:
调用例程→events_peak_picking()(基础模式)
○在短事件索引附近发展短事件区域
○计算长事件函数
○检测长事件函数中的峰值并返回长事件区域:
调用例程→events_peak_picking()(高级模式)
○从长事件区域滤波掉短事件相关帧
○基于其他两个检测到的区域定义背景区域
○将获取的层数据打包成字典返回
·将层信息保存到磁盘(pythonpickle格式)
·基于频谱图计算频谱特征:
调用例程→computespectralfeatures()
·基于帧音频计算时间特征:
调用例程→computetemporalfeatures()
·合并频谱和时间特征相关信息,合并后的层数据lld保存在磁盘(pickle)上
第二个程序脚本集合读取第一个脚本/函数集合生成的文件,根据层划分结果进行数据聚合,并将得到的特征以pickle文件的形式保存(每个输入音频文件保存一个特征)。
实现阶段2-程序代码结构大纲:
·将lld信息加载到字典中
·将层信息加载到字典中
·将事件检测函数从层字典移到lld字典
·基于层数据计算事件相关特征并打包成字典:
调用例程→eventrelatedfeatures()
○统计长事件
○计算long-eventscore(长事件函数中的峰值等级之和,只考虑采用先进的峰值检出方法选取的峰值)
○计算归一化长事件函数的方差
○计算长事件函数的一般斜率(最小二乘线性拟合)
○统计短事件
○计算short-eventscore(短事件函数中的峰值等级之和,只考虑高于最小阈值的峰值)
○计算levelofactivity(事件之间的平均间隔)
○计算irregularity(事件间隔的标准偏差)
○将得到的特征打包成字典返回
·迭代lld:
○根据3层区域,从当前的lld数组中构建3个数组
○基于短事件数组计算统计函数并将其附加到输出字典
○基于计算长事件数组的统计函数并将其附加到同一字典
○基于背景数组计算统计函数并将其附加到同一字典
·将输出字典保存到磁盘(python格式“json”)
根据基于给定特征区分声音场景的能力,对上述技术进行了评价。在测试中,选出了7个示例声音场景,包括“家”、“火车”、“地铁”、“汽车”、“办公室”、“街道”、“商店”。作为表征这些声音场景的特征,选择lld特征:主谱峰频率、频谱差异、阿尔法比、频谱下部分的能量、功率函数的一阶导数和“频谱差异”,如表1第一列所示。此外,每个特征都要根据每个特征的特定聚合器进行统计估计,这里包括根据声音场景帧计算的“最小”、“范围”、“最小”、“最大”、“中等”和“标准偏差”(参见表1第二列)。第三列表示在哪个层进行特征聚合。例如,在第一行中,通过最小聚合函数聚合属于短事件层的帧的频谱峰值的频率,即,在属于短事件层的帧的频谱峰值的频率中找到频谱峰值的最小频率。
在本申请的一个实施例中,基于bathacharyya距离衡量声音场景可区分性的属性,衡量两个分布值p(x)和q(x)之间的距离,如等式(8)所示。
其中,x表示特征集合x中的一个特定特征。
上述样本特征是从目标数据集中提取的,包括7个声音场景的4小时录音。
对于每个特征,通过计算所有可能的类型对的平均batthacharyya距离和最大batthacharyya距离,比较了与不同场景相关的值的分布。然后,利用这些分数来评估特征的属性,以及相对于基于帧的标准方法来执行特征提取的基于层的方法的改进。
表1表示将本发明提出的方法应用于数据集时最明显的结果,该数据集由来自上述7个不同声音场景的4个小时的录音材料组成。归一化每个中级特征的结果值,这样总体分布值具有零均值和单位方差。然后,得到每一类型(音频场景分类)的个体分布,并根据batthacharyya距离比较每对分布值。计算每个中级特征的平均场景间距离,以及最大场景间距离。表1中的结果显示了与特定层(第4列)有关的bathacharyya距离,并将其与计算该块所有帧的统计聚合器(第5列)时得到的距离进行比较。这两种变化量之间的差值也记录在表格的“增量(delta)”列(第6列)。这个实验使用的块大小是30秒。
表1:多个提取特征的基于层和基于帧计算bathacharyya距离的比较
通过考虑各个分布的误差线图,基于帧的方法与基于层的方法之间的差异变得更加明显。
图7a示出了一个特征(主要频谱峰值)的分布,其中最小的特征被聚合器用于在7个不同音频场景中进行基于帧(参见图7a)和基于层(参见图7b)计算。
如上所述,本发明提供了用于实现特征向量提取和/或其在音频场景分类中的应用的方法和装置。所执行的音频场景分类自动提供结果,这些结果可进一步用于控制各种其它技术过程,例如音频编码或解码、音频渲染和/或某些函数或设备的触发。
如图4所示,如上所述,特征向量确定可以实现为装置,例如联合特征提取器400。特别地,特征提取器400可包括用于划分分割器440、低级描述符提取器450和聚合器460的处理电路。特征提取器400输出特征向量470,以供训练阶段130和/或分类阶段230进一步处理。执行每个帧的层划分的划分分割器440可包括其它子单元,包括执行加窗和dft(例如单元610)的变换单元、用于基于帧计算音频变化的变化量单元(例如单元620和622)、短事件单元(例如单元630、631和632)、长事件(例如单元640、641、642)、背景(例如单元670),以及提供部分特征向量的输出单元(例如单元690、660)。
划分分割器440(包括其子单元)、聚合器460和低级描述符提取器450可以是编码器和/或解码器的一部分(单独或组合),以执行根据本发明划分的音频信号的数字处理。编码器和/或解码器还可以在各种设备中实现,例如电视机、机顶盒、个人计算机、平板电脑、智能手机等任意能录制、编码、转码、解码或播放的设备。编码器和/或解码器可以是实现方法步骤的软件或应用程序,并且存储/运行在上述电子设备中的处理器上。
这种装置可以是软件和硬件的组合。例如,特征向量的确定可以由通用处理器、数字信号处理器(dsp)、现场可编程门阵列(fpga)等芯片实现。然而,本发明不限于在可编程硬件上的实现。可以在专用集成电路(asic)上实现,也可以通过上述硬件组件的组合实现。
特征向量确定也可以通过存储在计算机可读介质上的程序指令来实现。程序在执行时,使得计算机执行上述方法的步骤。所述计算机可读介质可以是存储所述程序的任何介质,例如dvd、cd、u盘(闪存)、硬盘、通过网络可用的服务器存储器等。
综上所述,本发明涉及一种用于确定特征向量的装置和方法,所述特征向量通过从音频样本块中提取特征来执行声音场景分类,具体方法是将所述块分割为音频帧并计算每一帧的频谱图。基于频谱图,通过计算音频变化函数来确定块的音频变化,其中音频变化用于根据短事件,长事件和背景将帧分组为事件相关帧的集合。对于每个事件相关帧集合,计算帧相关特征并合并到特征向量中。基于特征向量进行声音场景的分类,特征向量包含与在每个帧集合内发生的音频事件相关的签名以及通过其它低级描述符为音频块的所有帧确定的非事件相关的特征。
- 还没有人留言评论。精彩留言会获得点赞!