一种语音识别方法、装置和计算机可读存储介质与流程
本发明涉及移动通信技术领域,尤其涉及一种语音识别方法、装置和计算机可读存储介质。
背景技术:
语音识别的最终目标是把输入的语音序列转换为正确的汉字序列。在大词汇量连续语音识别中,由于各种因素的影响,解码输出的识别假设中经常存在错误,阻碍了语音识别系统的应用。
对于识别结果的纠错方法通常是基于某些转换规则的,如在某些条件下将某些词语修正为其他词语,这类方法的难点在于如何提取或学习到有效并且鲁棒的转换规则,而不会在修正某些词语的同时又引入了新的错误。
相关技术中提出了提高语音识别准确性的方法,但是也存在一定的局限性:
1)应用过程需要积累一定量的用户语料并提供用户文档,在当前很多应用中不具备该条件;
2)按类别对加权因子进行调整的方式相对较粗,不能更有针对性的调整某些易错易混词;
3)未给出对于词组语言模型概率调整的方法。
技术实现要素:
有鉴于此,本发明实施例期望提供一种语音识别方法、装置和计算机可读存储介质。
为达到上述目的,本发明实施例的技术方案是这样实现的:
本发明实施例提供了一种语音识别方法,该方法包括:
统计识别结果中每个词语发生每种类型识别错误的次数;
基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;
基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。
其中,所述识别错误的类型包括:
替代型错误、删除型错误和插入型错误。
其中,所述统计识别结果中每个词语发生每种类型识别错误的次数,包括:
确定发生删除型错误,则在标注文本中该错误位置对应词语的删除型错误次数d加1;在标注文本中与该词语构成的n元词组的d也加1;
确定发生插入型错误,则在识别文本中该错误位置对应词语的插入型错误次数i加1;在识别文本中与该词语构成的n元词组的i也加1;
确定发生替代型错误,则在标注文本中该错误位置对应词语的被其他词语替代次数s_pas加1,在标注文本中与该词语构成的n元词组的s_pas也加1;在识别文本中该错误位置对应词语替代目标词语的次数s_act加1,在识别文本中与该词语构成的n元词组的s_act也加1。
其中,所述语言模型加权因子表示为:
r=(s_pas+d)/(s_act+i);
其中,所述r表示语言模型加权因子,所述d表示在识别结果中出现删除型错误的次数,所述i表示插入型错误的次数,所述s_act表示替代目标词语的次数,所述s_pas表示被其他词语替代的次数。
其中,所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,包括:
确定所述r的值大于1时,则升高所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率;
确定所述r的值小于1时,则降低所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率。
其中,所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,为:
基于如下公式对所述词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;其中,所述p为该词语原始的语言模型概率或为该词语构成的n元词组的原始的语言模型概率,所述log(p*r)为调整后的该词语或该词语构成的n元词组的语言模型概率:
log(p*r)=log(p)+log(r)=log(p)+log(s_pas+d)-log(s_act+i)。
可选的,该方法还包括:
确定所述每个词语发生每种类型识别错误的次数大于预设阈值时,则对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;
确定所述每个词语发生每种类型识别错误的次数小于预设阈值时,省略语言模型概率调整过程。
本发明实施例还提供了一种语音识别装置,该装置包括:
统计模块,用于统计识别结果中每个词语发生每种类型识别错误的次数;
确定模块,用于基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;
调整模块,用于基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。
本发明实施例还提供了一种语音识别装置,该装置包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,
其中,所述处理器用于运行所述计算机程序时,执行上述方法的步骤。
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
本发明实施例提供的语音识别方法、装置和计算机可读存储介质,统计识别结果中每个词语发生每种类型识别错误的次数;基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。本发明实施例基于所述每个词语发生每种类型识别错误的次数确定语言模型加权因子,可以更针对易混易错词语进行语言模型概率的调整,而不会影响其他词语,也不需要提供用户文档;此外,除对单个词语的语言模型概率进行调整外,还对该词语构成的n元词组进行调整,进而可再次应用于本领域的语音识别,提升语音识别的准确率。
附图说明
图1为本发明实施例所述语音识别方法流程示意图;
图2为本发明实施例所述语音识别装置结构示意图一;
图3为本发明实施例所述语音识别装置结构示意图二;
图4为本发明实施例所述语音识别装置结构示意图三。
具体实施方式
下面结合附图和实施例对本发明进行描述。
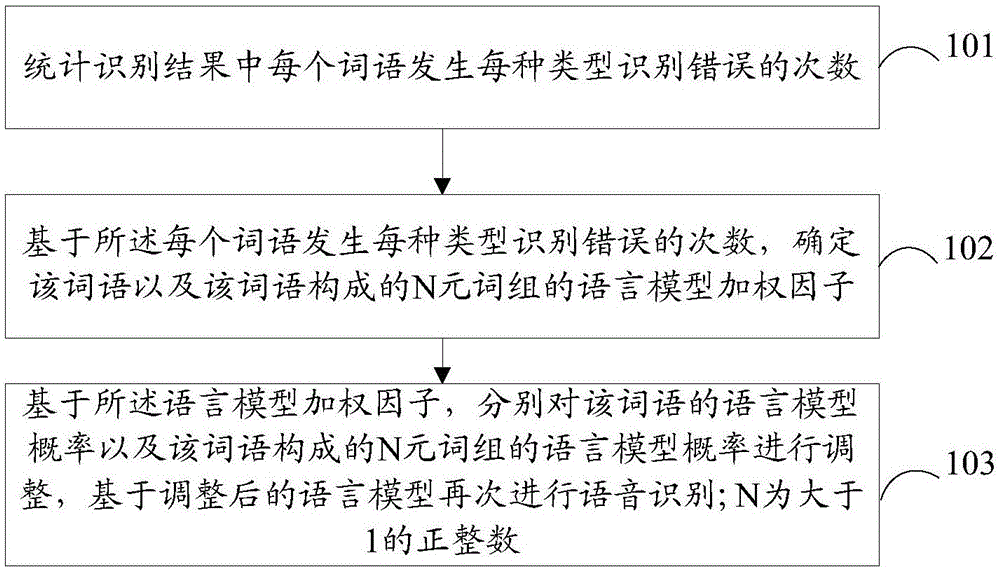
本发明实施例提供了一种语音识别方法,如图1所示,该方法包括:
步骤101:统计识别结果中每个词语发生每种类型识别错误的次数;
步骤102:基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;
步骤103:基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。
本发明实施例中,所述n可选2和3,即:对词语构成的二元词组和三元词组的语言模型概率进行调整,当然也可包括更高元的词组,只是对应的数据较少,精度提高不多。
本发明实施例基于所述每个词语发生每种类型识别错误的次数确定语言模型加权因子,可以更针对易混易错词语进行语言模型概率的调整,而不会影响其他词语,也不需要提供用户文档;此外,除对单个词语的语言模型概率进行调整外,还对该词语构成的n元词组进行调整,进而可再次应用于本领域的语音识别,提升语音识别的准确率。
本发明实施例中,所述识别错误的类型可包括:
替代型错误、删除型错误和插入型错误。
本发明实施例中,所述统计识别结果中每个词语发生每种类型识别错误的次数,可包括:
确定发生删除型错误,则在标注文本中该错误位置对应词语的删除型错误次数d加1;在标注文本中与该词语构成的n元词组的d也加1;
确定发生插入型错误,则在识别文本中该错误位置对应词语的插入型错误次数i加1;在识别文本中与该词语构成的n元词组的i也加1;
确定发生替代型错误,则在标注文本中该错误位置对应词语的被其他词语替代次数s_pas加1,在标注文本中与该词语构成的n元词组的s_pas也加1;在识别文本中该错误位置对应词语替代目标词语的次数s_act加1,在识别文本中与该词语构成的n元词组的s_act也加1。
这里,所述标注文本为待识别语音对应的真实文本,识别文本为经过语音识别系统转换后得到的文本,通常存在识别错误的内容。
本发明实施例中,所述语言模型加权因子表示为:
r=(s_pas+d)/(s_act+i);
其中,所述r表示语言模型加权因子,所述d表示在识别结果中出现删除型错误的次数,所述i表示插入型错误的次数,所述s_act表示替代目标词语的次数,所述s_pas表示被其他词语替代的次数。
本发明实施例中,所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,包括:
确定所述r的值大于1时,则升高所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率;
确定所述r的值小于1时,则降低所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率。
本发明实施例中,所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,为:
基于如下公式对所述词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;其中,所述p为该词语原始的语言模型概率或为该词语构成的n元词组的原始的语言模型概率,所述log(p*r)为调整后的该词语或该词语构成的n元词组的语言模型概率:
log(p*r)=log(p)+log(r)=log(p)+log(s_pas+d)-log(s_act+i)。
一个实施例中,该方法还包括:
确定所述每个词语发生每种类型识别错误的次数大于预设阈值时,则对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;
确定所述每个词语发生每种类型识别错误的次数小于预设阈值时,省略语言模型概率调整过程。
为了实现上述方法,本发明实施例还提供了一种语音识别装置,如图2所示,该装置包括:
统计模块201,用于统计识别结果中每个词语发生每种类型识别错误的次数;
确定模块202,用于基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;
调整模块203,用于基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。
本发明实施例中,所述n可选2和3,即:对词语构成的二元词组和三元词组的语言模型概率进行调整,当然也可包括更高元的词组,只是对应的数据较少,精度提高不多。
本发明实施例基于所述每个词语发生每种类型识别错误的次数确定语言模型加权因子,可以更针对易混易错词语进行语言模型概率的调整,而不会影响其他词语,也不需要提供用户文档;此外,除对单个词语的语言模型概率进行调整外,还对该词语构成的n元词组进行调整,进而可再次应用于本领域的语音识别,提升语音识别的准确率。
本发明实施例中,所述识别错误的类型可包括:
替代型错误、删除型错误和插入型错误。
本发明实施例中,所述统计模块201统计识别结果中每个词语发生每种类型识别错误的次数,可包括:
确定发生删除型错误,则在标注文本中该错误位置对应词语的删除型错误次数d加1;在标注文本中与该词语构成的n元词组的d也加1;
确定发生插入型错误,则在识别文本中该错误位置对应词语的插入型错误次数i加1;在识别文本中与该词语构成的n元词组的i也加1;
确定发生替代型错误,则在标注文本中该错误位置对应词语的被其他词语替代次数s_pas加1,在标注文本中与该词语构成的n元词组的s_pas也加1;在识别文本中该错误位置对应词语替代目标词语的次数s_act加1,在识别文本中与该词语构成的n元词组的s_act也加1。
这里,所述标注文本为待识别语音对应的真实文本,识别文本为经过语音识别系统转换后得到的文本,通常存在识别错误的内容。
本发明实施例中,所述语言模型加权因子表示为:
r=(s_pas+d)/(s_act+i);
其中,所述r表示语言模型加权因子,所述d表示在识别结果中出现删除型错误的次数,所述i表示插入型错误的次数,所述s_act表示替代目标词语的次数,所述s_pas表示被其他词语替代的次数。
本发明实施例中,所述调整模块203基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,包括:
确定所述r的值大于1时,则升高所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率;
确定所述r的值小于1时,则降低所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率。
本发明实施例中,所述所述调整模块203基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,为:
基于如下公式对所述词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;其中,所述p为该词语原始的语言模型概率或为该词语构成的n元词组的原始的语言模型概率,所述log(p*r)为调整后的该词语或该词语构成的n元词组的语言模型概率:
log(p*r)=log(p)+log(r)=log(p)+log(s_pas+d)-log(s_act+i)。
一个实施例中,如图3所示,该装置还包括:
判断模块204,用于确定所述每个词语发生每种类型识别错误的次数大于预设阈值时,则对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;
确定所述每个词语发生每种类型识别错误的次数小于预设阈值时,省略语言模型概率调整过程。
本发明实施例还提供了一种语音识别装置,该装置包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,
其中,所述处理器用于运行所述计算机程序时,执行:
统计识别结果中每个词语发生每种类型识别错误的次数;
基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;
基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。
其中,所述识别错误的类型包括:
替代型错误、删除型错误和插入型错误。
所述统计识别结果中每个词语发生每种类型识别错误的次数时,所述处理器还用于运行所述计算机程序时,执行:
确定发生删除型错误,则在标注文本中该错误位置对应词语的删除型错误次数d加1;在标注文本中与该词语构成的n元词组的d也加1;
确定发生插入型错误,则在识别文本中该错误位置对应词语的插入型错误次数i加1;在识别文本中与该词语构成的n元词组的i也加1;
确定发生替代型错误,则在标注文本中该错误位置对应词语的被其他词语替代次数s_pas加1,在标注文本中与该词语构成的n元词组的s_pas也加1;在识别文本中该错误位置对应词语替代目标词语的次数s_act加1,在识别文本中与该词语构成的n元词组的s_act也加1。
其中,所述语言模型加权因子表示为:
r=(s_pas+d)/(s_act+i);
其中,所述r表示语言模型加权因子,所述d表示在识别结果中出现删除型错误的次数,所述i表示插入型错误的次数,所述s_act表示替代目标词语的次数,所述s_pas表示被其他词语替代的次数。
所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整时,所述处理器还用于运行所述计算机程序时,执行:
确定所述r的值大于1时,则升高所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率;
确定所述r的值小于1时,则降低所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率。
所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整时,所述处理器还用于运行所述计算机程序时,执行:
基于如下公式对所述词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;其中,所述p为该词语原始的语言模型概率或为该词语构成的n元词组的原始的语言模型概率,所述log(p*r)为调整后的该词语或该词语构成的n元词组的语言模型概率:
log(p*r)=log(p)+log(r)=log(p)+log(s_pas+d)-log(s_act+i)。
所述处理器还用于运行所述计算机程序时,执行:
确定所述每个词语发生每种类型识别错误的次数大于预设阈值时,则对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;
确定所述每个词语发生每种类型识别错误的次数小于预设阈值时,省略语言模型概率调整过程。
需要说明的是:上述实施例提供的装置在进行语音识别时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将设备的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的装置与相应方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
在示例性实施例中,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质可以是fram、rom、prom、eprom、eeprom、flashmemory、磁表面存储器、光盘、或cd-rom等存储器;也可以是包括上述存储器之一或任意组合的各种设备,如移动电话、计算机、平板设备、个人数字助理等。
本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时,执行:
统计识别结果中每个词语发生每种类型识别错误的次数;
基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;
基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整,基于调整后的语言模型再次进行语音识别;所述n为大于1的正整数。
其中,所述识别错误的类型包括:
替代型错误、删除型错误和插入型错误。
所述统计识别结果中每个词语发生每种类型识别错误的次数时,所述计算机程序被处理器运行时,还执行:
确定发生删除型错误,则在标注文本中该错误位置对应词语的删除型错误次数d加1;在标注文本中与该词语构成的n元词组的d也加1;
确定发生插入型错误,则在识别文本中该错误位置对应词语的插入型错误次数i加1;在识别文本中与该词语构成的n元词组的i也加1;
确定发生替代型错误,则在标注文本中该错误位置对应词语的被其他词语替代次数s_pas加1,在标注文本中与该词语构成的n元词组的s_pas也加1;在识别文本中该错误位置对应词语替代目标词语的次数s_act加1,在识别文本中与该词语构成的n元词组的s_act也加1。
其中,所述语言模型加权因子表示为:
r=(s_pas+d)/(s_act+i);
其中,所述r表示语言模型加权因子,所述d表示在识别结果中出现删除型错误的次数,所述i表示插入型错误的次数,所述s_act表示替代目标词语的次数,所述s_pas表示被其他词语替代的次数。
所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整时,所述计算机程序被处理器运行时,还执行:
确定所述r的值大于1时,则升高所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率;
确定所述r的值小于1时,则降低所述该词语的语言模型概率或该词语构成的n元词组的语言模型概率。
所述基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整时,所述计算机程序被处理器运行时,还执行:
基于如下公式对所述词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;其中,所述p为该词语原始的语言模型概率或为该词语构成的n元词组的原始的语言模型概率,所述log(p*r)为调整后的该词语或该词语构成的n元词组的语言模型概率:
log(p*r)=log(p)+log(r)=log(p)+log(s_pas+d)-log(s_act+i)。
所述计算机程序被处理器运行时,还执行:
确定所述每个词语发生每种类型识别错误的次数大于预设阈值时,则对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行调整;
确定所述每个词语发生每种类型识别错误的次数小于预设阈值时,省略语言模型概率调整过程。
下面结合场景实施例对本发明进行描述。
可知汉语中存在许多同音、近音词,语音识别系统需要结合上下文来判断当前发音究竟对应的是哪个词。语言模型为识别系统提供上下文约束和句法规则,如果语言模型不恰当,即使声学模型能识别出正确的发音,识别结果也可能不正确,比如huafei这个音,在电信领域对应着话费,在其他领域可能表示化肥。因此针对不同领域的语音识别,我们需要对语言模型做出调整,以使词语以及n元文法的分布概率符合该领域的特点。通常语言模型自适应的方法如上面提到的那样采用插值的方式对通用语言模型进行调整。该方法对所有词语设定相同的插值比例,比如插值比例设为0.6,则每个词语最终的概率等于通用模型概率*0.4+领域模型概率*0.6。这样做对于领域相关程度较弱的词语,如“你”“我”这种通用词语,也做出了和领域相关程度较强词语相同的调整比例,显然不够合理。
本发明实施例提出一种改进语言模型的语音识别方法及对应的装置。所述方法可包括:统计识别结果中每个词语发生每种类型识别错误的次数;
基于所述每个词语发生每种类型识别错误的次数,确定该词语以及该词语构成的n元词组的语言模型加权因子;基于所述语言模型加权因子,分别对该词语的语言模型概率以及该词语构成的n元词组的语言模型概率进行增大或变小的调整。该方法可通过如下装置实现,如图4所示,该装置包括:声学模型训练单元401、语言模型训练单元402、识别单元403以及纠错调整单元404,其中识别单元403利用声学模型训练单元401中的声学模型和语言模型训练单元402中的语言模型进行识别、将语音识别成文本;纠错调整单元404通过识别结果的错误统计调整语言模型,调整之后识别单元403利用调整后的语言模型再次进行识别。
上文提到识别结果中的错误类型分为替代型错误(substitution)、删除型错误(deletion)和插入型错误(insert):
如果发生插入型错误,则该词语在语言模型中的出现概率应该降低,识别文本中与该词语相邻的词语和该词语所构成的bi-gram(二元)和tri-gram(三元)等词组的出现概率也要降低;
如果发生删除型错误,则该词语在语言模型中的出现概率应该升高,在标注文本中与该词语相邻的词语和该词语所构成的bi-gram和tri-gram等词组的出现概率也要升高;
如果发生替代型错误,则标注文本中被替代的词语、以及它和它相邻词语构成的bi-gram和tri-gram等词组的出现概率要升高,识别文本中替代目标词语的词、以及它和它相邻词语构成的bi-gram和tri-gram等词组的出现概率要降低。
这里,需要说明的是,bi-gram和tri-gram等词组的构成需要根据不同错误类型选择是标注文本中的词组还是识别文本中的词组。
综上,语言模型中概率需要升高的词语及词组包括:标注文本中发生删除型错误的词语及其与相邻词语构成的bi-gram、tri-gram词组;标注文本中被替代的词语及其与相邻词语构成的bi-gram、tri-gram词组。语言模型中概率需要降低的词语及词组包括:识别文本中发生插入型错误的词语及其与相邻词语构成的bi-gram、tri-gram词组;识别文本中替代目标词语的词语及其与相邻词语构成的bi-gram、tri-gram词组。
这里,可用d表示在识别结果中出现删除型错误的次数,i表示插入型错误的次数,s_act表示替代目标词语的次数,s_pas表示被其他词语替代的次数。对每个词语及词组来说,统计其在识别结果中出现以上四种情况的次数,计算语言模型加权因子r=(s_pas+d)/(s_act+i)。
可见,当该词语被其他词语替代的次数以及发生删除型错误的次数总和大于该词语替代其他词语以及发生插入型错误的总和时,r大于1,则该词语在语言模型中的出现概率升高;反之r小于1,该词语在语言模型中的出现概率降低。通常情况下,语言模型的结果会以对数形式存在,如词语w的出现概率为p,则语言模型保留的是log(p),log以10为底。因此引入加权因子r之后,词语w在语言模型中的出现概率的对数log(p)变为:
log(p*r)=log(p)+log(r)=log(p)+log(s_pas+d)-log(s_act+i)(1)
考虑到几种错误的次数可能为0,因此可采用常用的平滑方式进行平滑,比如每种错误类型均加1等。此外,为了增加加权因子的置信度,可以对次数设定阈值,若发生错误的次数和小于该阈值,则不对该词语的出现概率进行调整,只有达到阈值时才会对其进行调整。
实施例一
具体实施时,将标注文本与识别文本对齐,遍历这些结果中的替代型错误s、删除型错误d和插入型错误i。
步骤一:统计识别结果中每个词语发生每种类型识别错误的次数;
1)如果检索到d错误,则在标注文本中该错误位置对应词语的删除型错误次数d加1;在标注文本中与该词语构成的bi-gram、tri-gram的d也加1;
2)如果检索到i错误,则在识别文本中该错误位置对应词语的插入型错误次数i加1;在识别文本中与该词语构成的bi-gram、tri-gram的i也加1;
3)如果检索到s错误,则在标注文本中该错误位置对应词语的被其他词语替代次数s_pas加1,在标注文本中与该词语构成的bi-gram、tri-gram的s_pas也加1;在识别文本中该错误位置对应词语替代目标词语的次数s_act加1,在识别文本中与该词语构成的bi-gram、tri-gram的s_act也加1。
步骤二:计算每个词语及相应词组的概率加权因子r;
步骤三:利用r调整语言模型的概率,利用该语言模型再次进行解码将语音识别成文本;
例如:
标注文本:确认成功之后就是下个月生效;
识别文本:现任成功之后就是下个月生效;
上述示例是电信领域的一个识别实例,“确认”被识别成了“现任”,属于替代型错误。“现任”在电信领域不常见,利用本提案中调整语言模型的方法,“确认”的语言模型概率会提升,“现任”的语言模型概率会降低;对于二元词组,“确认成功”的语言模型概率也会提升,“现任成功”的语言模概率会降低;三元词组“确认成功之后”的语言模型概率会提升,“现任成功之后”的语言模型概率会降低。利用该方法调整之后的语言模型更适应电信领域的语音识别的应用,提升语音识别的识别率。
本发明实施例基于所述每个词语发生每种类型识别错误的次数确定语言模型加权因子,可以更针对易混易错词语进行语言模型概率的调整,而不会影响其他词语,也不需要提供用户文档;此外,除对单个词语的语言模型概率进行调整外,还对该词语构成的n元词组进行调整,进而可再次应用于本领域的语音识别,提升语音识别的准确率。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!