多智能设备同时存在时处理语音指令的方法和系统与流程
本申请涉及语音识别
技术领域:
,特别涉及多智能设备同时存在时处理语音指令的方法和系统。
背景技术:
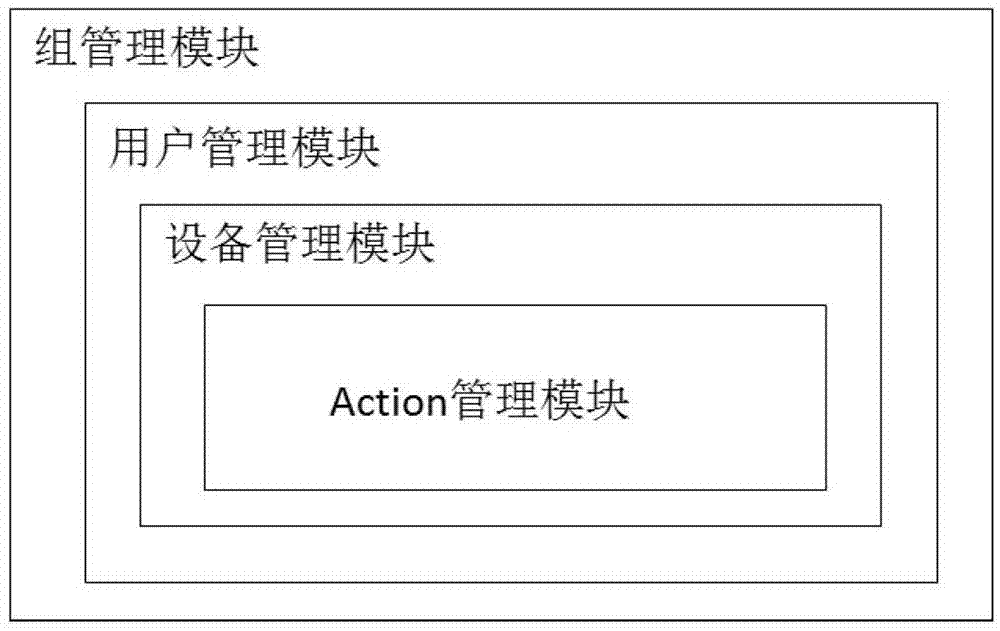
:随着语音识别和自然语言处理技术的发展,智能设备可以方便地实现语音识别与控制。机器学习技术可以通过收集大量用户数据,不断学习训练出符合用户行为习惯的模型,从而快速预测出匹配输入数据的结果。目前,智能设备收到语音指令时,只针对本智能设备进行单独处理。当多个智能设备同时存在时,如果用户发出一条语音指令,每个接收到该语音指令的智能设备均会处理该语音指令,这时,不需要执行该语音命令的智能设备也会对该语音指令进行处理,这不仅造成了不必要的操作或误操作,也对实际需要操作的设备造成了干扰,使用户无法对智能设备实现精确的操作。技术实现要素:本申请提供了一种多智能设备同时存在时处理语音指令的方法和系统,以提高设备操作的精确性与便捷性,并改善用户的操作体验。本申请公开了一种多智能设备同时存在时处理语音指令的方法,包括:创建组,向所述组中加入智能设备;从所述组内的智能设备接收语音指令;以组为级别处理所述语音指令,根据所述组内的智能设备支持的规则筛选出执行所述语音指令的智能设备。较佳的,所述向所述组中加入智能设备包括:通过用户账号获取登陆所述用户账号的在线设备列表;从所述在线设备列表中选择智能设备加入到所述组中。较佳的,从所述组内的智能设备接收语音指令包括:当智能设备采集到的语音指令的音频强度低于设定的阈值时,所述智能设备丢弃所述语音指令;当智能设备采集到的语音指令音频强度高于设定的阈值时,服务器从该智能设备接收语音指令、当前上下文、时间、地点、用户信息。较佳的,所述以组为级别处理所述语音指令包括:通过智能设备注册账号的声纹,服务器通过所述语音指令的声纹识别用户身份,并根据所述地点信息确定组,以组为级别处理所述语音指令。较佳的,该方法还包括:通过大数据采集训练机器学习模型,对于当前语音指令,筛选出能够执行所述语音指令的智能设备。较佳的,该方法还包括:当执行语音指令的智能设备不符合用户预期时,用户通过语音唤起纠错模式,并将纠错后的结果返回给服务器,用于机器学习模型的自我增强。较佳的,所述筛选出能够执行所述语音指令的智能设备包括:判断组是否支持所述语音指令,如果不支持,则向用户返回不支持响应;如果支持,则筛选出所有支持所述语音指令的智能设备,并对筛选出的智能设备的优先级进行排序,选取优先级最高的智能设备作为执行设备。较佳的,该方法还包括:基于大数据训练得出的机器学习模型,进一步根据时间、用户年龄、功能性词汇从筛选出的智能设备中选择执行设备。较佳的,该方法还包括:当接收语音指令的智能设备中,一个或多个智能设备的功能叠加能完成所述语音指令时,选择所述一个或多个智能设备同时执行完成所述功能。较佳的,该方法还包括:当多个智能设备可供选择时,提供用户选择界面。较佳的,该方法还包括:当一个语音指令有多个内容需要显示时,不同内容分别在不同设备上显示。较佳的,该方法还包括:当一条语音指令只执行一次时,智能设备间内部通信保证只执行一次。本申请还公开了一种多智能设备同时存在时处理语音指令的系统,所述系统包括:组管理模块、接收模块和推理模块,其中:所述组管理模块,用于创建组,向所述组中加入智能设备;所述接收模块,用于从所述组内的智能设备接收语音指令;所述推理模块,用于以组为级别处理所述语音指令,根据所述组内的智能设备支持的规则筛选出执行所述语音指令的智能设备。较佳的,所述组管理模块中包含:账号管理模块、设备管理模块、规则管理模块,其中:所述账号管理模块,用于管理登陆的账号,邀请加入的账号,以及基于组创建的用户;所述设备管理模块,用于管理账号下关联的设备,维护在线可用设备列表;所述规则管理模块,用于维护规则列表,并进行规则优先级管理。较佳的,所述接收模块,用于从智能设备接收语音指令、当前上下文、时间、地点、用户信息。较佳的,所述推理模块通过所述语音指令的声纹识别用户身份,并根据所述地点信息确定组,以组为级别处理所述语音指令,其中,用户通过智能设备注册账号的声纹。较佳的,所述推理模块,还用于通过大数据训练机器学习模型,对当前语音指令筛选出执行的设备列表。较佳的,所述系统还包括纠错模块,其中:所述纠错模块,用于提供用户修正执行语音指令的窗口,并反馈回服务器,用于机器学习模型的自我增强。较佳的,所述筛选模块还用于:判断组是否支持所述语音指令,如果不支持,则向用户返回不支持响应;如果支持,则筛选出所有支持所述语音指令的智能设备,并对筛选出的智能设备的优先级进行排序,选取优先级最高的智能设备作为执行设备。较佳的,所述筛选模块还用于:基于大数据训练得出的机器学习模型,进一步根据时间、用户年龄、功能性词汇从筛选出的智能设备中选择执行设备;当接收语音指令的智能设备中,一个或多个智能设备的功能叠加能完成所述语音指令时,选择所述一个或多个智能设备同时执行完成所述功能;当多个智能设备可供选择时,提供用户选择界面;当一个语音指令有多个内容需要显示时,不同内容分别在不同设备上显示;当一条语音指令只执行一次时,智能设备间内部通信保证只执行一次。由上述技术方案可见,本发明提供的多智能设备同时存在时处理语音指令的方法和系统,在服务器端以group为单位处理语音指令,通过对group中多个设备的语音命令的规则(actionrule)进行分析,筛选出可执行命令的备选设备列表,并且通过大数据训练出的机器学习模型,智能地推测出应该执行语音命令的一个或多个设备,并提供纠错功能,纠错后的结果反馈回机器学习模型再训练,得出更符合每个用户行为习惯的系统。本发明让用户无需关闭其他设备的麦克风,即可实现同一时间操作一个或多个的设备,有效避免语音命令造成的错乱,提高了语音操作的便捷性和稳定性,并且通过机器学习模型推荐执行的设备,为用户提供更便捷、更精确的操作体验。附图说明图1为本申请组管理模块的组成结构示意图;图2为本申请创建group并添加设备的流程示意图;图3为本申请创建的group的效果图;图4为本申请中语音数据所包含的内容示意图;图5为本申请推理模块推荐最适合处理语音指令的设备的逻辑示意图;图6为本申请纠错模块的纠错逻辑示意图;图7为本申请场景一的示意图;图8为本申请场景二的示意图;图9为本申请场景三的示意图;图10为本申请场景四的示意图;图11为本申请场景五的示意图;图12为本申请场景六的示意图图13为本申请场景七的示意图;图14为本申请场景八的示意图;图15为本申请场景九的示意图;图16为本申请场景十的示意图。具体实施方式为使本申请的目的、技术方案及优点更加清楚明白,以下参照附图并举实施例,对本申请作进一步详细说明。本发明公开了一种多智能设备同时存在时处理语音指令的方法和设备,包含如下关键步骤:1.通过用户账号获取登陆该账号下的在线设备列表,创建group,选择列表中的设备加入到该group。需要加入不同账号的设备时,通过账号邀请,经过对方确认授权后,获取对方的在线设备列表,并从中添加所需设备到group中。用户可以基于group创建子账号,以方便其他用户使用该系统,从而满足不同用户的定制化需求。创建group与加入group的账号默认可用,创建group的账号为主账号(primaryaccount),拥有对group修改、删除等操作权限。较佳的,每个账号均可通过智能设备注册自己的声纹(voiceprint),用于语音处理时进行身份自动识别。当有新的设备登陆或离线时,实时更新group中的列表信息。为每个设备的规则(action)定义不同的优先级(priority),当有多个设备同时支持一条语音指令时,根据设备的优先级选择适合执行的设备。如对于指令“播放音乐”,当智能音箱与智能手机同时可用时,优先选择智能音箱进行播放。2.用户发出一条语音指令时,采集到语音指令的设备对其音频强度进行判断,当某设备采集到的语音指令的音频强度低于设定的阈值时,该设备丢弃该语音指令不做处理;当某设备采集到的语音指令音频强度高于设定的阈值时,该设备将采集到语音指令、当前上下文(context)、时间、地点、用户等等发送给服务器端,用于服务器选择执行指令的设备。也就是说,对同一语音指令,有的设备将不做处理,而有的设备将向服务器端上报。声音的强弱通过音频强度来判断,声音的强弱反应用户与设备之间的距离,可以用于服务器端选择合适的设备。3.在服务器端,通过声纹识别用户身份。根据设备上传数据中的地点(position)信息确定group,以group级别处理语音指令,并根据group中设备列表支持的规则(action)进行判断,筛选出能够执行命令的候选设备。4.通过大数据采集训练机器学习模型,对于一条语音指令,推断出能够执行该语音指令的设备。机器学习模型因子包括但不限于:时间、地点、账号属性(年龄、性别、爱好等等)、设备属性、规则、规则优先级、音频强弱、音频内容等等。5.当执行语音指令的设备不符合用户预期时,提供纠错方法,用户通过语音唤起纠错模式,并将纠错后的结果返回给服务器,用于机器学习模型的自我增强。本申请多智能设备同时存在时处理语音指令的系统主要包含以下模块:1.组管理模块:服务器端支持组管理功能,支持多个账号用户数据管理。每个设备以登录的账号+设备唯一标识符(mac,但不限于mac)为唯一标识。服务器端列出在线的设备,用户可以方便地创建和配置组(group),将合适的设备添加到组中。在同一组中,所有设备支持的规则(action)合并,以group级别管理。组管理模块的组成结构示意图如图1所示,还包括账号管理模块、设备管理模块、action管理模块。其中:账号管理模块主要管理登陆的账号,邀请加入的账号,以及基于组(group)创建的用户。基于组(group)创建的用户可通过注册声纹智能识别用户。设备管理模块主要管理账号下关联的设备,维护在线可用设备列表。当有新设备加入时,更新列表信息,将新设备加入在线可用设备列表中;当有设备离线时,将对应的设备从在线可用设备列表中删除。action管理模块主要维护action列表,并进行action优先级管理。相同账号的设备、不同账号的设备均可加入同一group,添加流程如图2所示,包括:登陆账号后,可以获取本账号下的在线设备列表,并创建group,从本账号下的在线设备列表中选择设备加入group;也可以向其他账号发出邀请,获取其他账号下的在线设备列表,并从中选择设备加入group。向group中加入在线设备后,得到该group的可用设备列表以及可用actions。按照图2所示流程创建group并向group中添加在线设备后,将得到如图3所示的效果图:图3所示group中包含2个账号:accounta和accountb,其中:accounta下有两个设备device1和device2;accountb下有设备device3;device1、device2和device3均可以执行action1、action2和action3。2.数据发送模块:当用户发出语音指令时,收到语音数据的音频强度高于阈值的设备将数据发送给服务端。语音数据包括声音的内容、音频强弱、地点、时间、用户信息以及设备当前的上下文环境(context)等等,如图4所示。声音的强弱通过音频文件的音阶高低来判断,声音的强弱反应用户与设备之间的距离,可以用于服务器端选择合适的设备。3.推理模块:服务器端接收到各个设备的语音指令时,从可用设备中选取当前语境支持该语音指令的设备,当所有在线设备筛选完成时,获得可处理该语音指令的设备列表,再用机器学习模型通过包括但不限于用户、用户第三方数据行为分析、时间、地点、command类型、设备优先级、action优先级等因子,推理出最适合处理该语音指令的一个或者多个设备。图5为本申请推理模块推荐最适合处理语音指令的设备的逻辑示意图。4.纠错模块:当推荐执行语音指令的设备不满足用户使用需求时,用户通过语音唤起纠错模式,系统列出当前所有在线的设备,用户再次选择合适的执行设备,再次选择的结果反馈回服务器,用于机器学习模型的自我增强。本申请纠错模块的纠错逻辑示意图如图6所示。下面通过几个典型的应用场景,对本发明举实施例进行说明。场景一:家庭使用中,往往有多个设备支持语音控制,智能挑选出最适合处理语音指令的设备,可以极大方便用户使用,用户无需去对其他设备的语音输入进行限制,可以省去额外操作,减少不必要的设备处理造成的干扰,将针对性较强的语音指令匹配到合适的设备进行处理。对于一条语音指令,从多个支持该语音的设备中选取一个或多个设备进行处理。对于一条语音指令,不支持该语音指令的设备不做处理。以播放音乐为例,用户首先需要配置一个组,将用户账户下的设备添加到该组中。如图7中所示,组中包括智能电视、智能手机和智能音箱,当用户通过唤醒语音唤醒各个设备时,所有设备准备接收语音指令,当用户发出“播放音乐”指令时,所有设备将收到的指令以及当前上下文信息发送给服务器端进行处理。服务器端将在一定时间内收到指令所在组中进行判断。首先判断组是否支持该指令,如果不支持,则给用户返回“不支持”响应;如果支持,则筛选出所有支持该指令的设备,并将支持指令的优先级进行排序,选取优先级最高的设备作为执行设备,其余设备返回“不响应”回复,如表一所示。表一在选取执行设备时,优先级作为其中一条判断标准。在此基础上,可以另外引入大数据训练得出的机器学习模型,以选取更为合适的执行设备,并且推荐更为合适的内容。如播放音乐时,智能音箱(speaker)作为专业播放设备,用户更愿意选取音箱作为执行备,但是机器模型统计出结果,在凌晨或深夜,用户更愿意使用手机播放音乐,这时选取手机作为执行设备,如表二所示。表二当用户为不同年龄段时,推荐给用户不同的音乐内容,如表三所示。表三并且,机器学习模型可以维护一系列功能性词汇,便于功能性指令的设备选择。如询问菜谱时,选取冰箱作为执行设备,便于用户在厨房进行操作,观看电视节目时选取电视作为执行设备,等等。如表四所示。设备功能智能电视电视智能手机打电话智能手机上网冰箱烹饪微波炉烘焙智能音箱音乐洗衣机清洗……表四场景二:如图8所示,不同的用户,通过声纹识别确定身份,相同的指令返回符合不同用户的内容。例如:请求播放音乐时,针对不同年龄段,推荐不同类型的音乐,年长者推荐经典音乐,小孩推荐儿童歌曲。场景三:如图9所示,根据语音指令的内容选择合适的执行设备。如在用餐时间段,用户想查询某个菜谱,且有冰箱在线时,优先选择冰箱执行指令,提供菜谱信息。场景四:如图10所示,如果用户朝着某个设备发出语音指令,这个设备也支持该指令时,该设备提取的音频强度最强,优先选择该设备进行操作。场景五:如图11所示,当所在区域有更适合执行的设备时,虽然该设备未检测到语音指令,但是通过匹配组中设备列表数据,也可选择该设备为执行设备。场景六:如图12所示,当接收语音的设备无法处理语音指令,但是group中有设备可以处理时,选择可执行处理的设备进行响应。场景七:如图13所示,当接收语音的设备中,一个或多个设备的功能叠加能完成该语音指令时,选择一个或多个设备同时执行完成该功能。如面包烤好后,打电话给妈妈,首先烤箱执行烤面包操作,完成之后使用手机给妈妈打电话。场景八:如图14所示,当多个合适设备可供选择时,提供用户选择界面。如设置闹钟时,提供选择界面,使用户选择可以合适的执行设备。场景九:如图15所示,当一个指令有多个内容需要显示时,不同内容分别在不同设备上显示。如播报天气时,界面在电视上显示,语音播报在音箱上进行。场景十如图16所示,一条指令只运行执行一次时,设备间内部通信保证执行一次。如预订机票时,只预订一张。本发明公开了一种多智能设备处理语音的方法和系统,只需配置好设备的组信息,即可灵活地处理多智能设备同时在线时的语音命令,提高了设备操作的精确性与便捷性,改善了用户的操作体验。以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1