一种语音年龄识别方法及系统与流程
本发明涉及一种语音年龄识别方法及系统,属于说话人识别技术领域。
背景技术:
随着人工智能研究热的兴起,大量的人机交互产品需要对说话人本身进行区分,尤其在在线教育行业,准确并实时确定上课人本身对做好智能交互、跟踪学习进度、提升学习效率有很大的帮助。
目前,在少儿英语语音识别垂直领域,由于在声学模型训练中存在数据干扰,而绝大部分数据干扰来源于成人口语,在少儿英语识别过程中很明显识别率会下降。为了提升识别率,只能对训练数据进行清洗,目前根据业务需求清洗的办法就是通过大量人工过滤成人语音,选取小孩语音,导致数据标注的效率低,也会增加人工成本。
技术实现要素:
本发明的目的在于,提供一种语音年龄识别方法及系统,可以至少解决上述技术问题之一。
为解决上述技术问题,本发明采用如下的技术方案:
一种语音年龄识别方法,包括:采集待识别语音数据;对所述待识别语音数据进行预处理,得到第一预处理数据;对所述第一预处理数据进行特征提取,得到第一特征参数;对所述第一特征参数进行降维与聚合,得到第二特征参数;根据预先存储的svm模型以及所述第二特征参数识别出所述待识别语音数据所属的年龄段。
前述的语音年龄识别方法中,所述方法还包括:输入语音训练数据;对所述语音训练数据进行预处理,得到第二预处理数据;对所述第二预处理数据进行特征提取,得到第三特征参数;对所述第三特征参数进行降维与聚合,得到第四特征参数;根据svm算法、所述第四特征参数以及第一年龄标注结果进行训练,生成所述svm模型,其中,所述第一年龄标注结果是对所述语音训练数据进行年龄标注得到的;存储所述svm模型。
前述的语音年龄识别方法中,在生成所述svm模型之后,所述方法还包括:输入语音测试数据;对所述语音测试数据进行预处理,得到第三预处理数据;对所述第三预处理数据进行特征提取,得到第五特征参数;对所述第五特征参数进行降维与聚合,得到第六特征参数;根据所述svm模型以及所述第六特征参数识别出所述语音测试数据所属的年龄段,得到识别结果;将所述识别结果与第二年龄标注结果进行比对,得到识别率,其中,所述第二年龄标注结果是对所述语音测试数据进行年龄标注得到的。
前述的语音年龄识别方法中,所述预处理包括分帧、加窗和预加重;和/或所述特征提取包括时域特征参数提取和频域特征参数提取,其中,时域特征参数包括短时过零率、短时能量谱和基音周期,频域特征参数包括lpcc、δlpcc、mfcc和δmfcc;和/或所述降维为采用pca算法进行数据降维,所述聚合为采用k-means算法进行数据聚合。
前述的语音年龄识别方法中,在对所述待识别语音数据进行预处理之前,所述方法还包括:对所述待识别语音数据进行循环缓存;按一定时间间隔读取缓存的所述待识别语音数据。
一种语音年龄识别系统,包括:音频采集模块,用于采集待识别语音数据;预处理模块,用于对所述待识别语音数据进行预处理,得到第一预处理数据;特征提取模块,用于对所述第一预处理数据进行特征提取,得到第一特征参数;降维聚合模块,用于对所述第一特征参数进行降维与聚合,得到第二特征参数;svm识别模块,用于根据预先存储的svm模型以及所述第二特征参数识别出所述待识别语音数据所属的年龄段。
前述的语音年龄识别系统中,所述系统还包括:语音输入模块,用于输入语音训练数据;所述预处理模块,还用于对所述语音训练数据进行预处理,得到第二预处理数据;所述特征提取模块,还用于对所述第二预处理数据进行特征提取,得到第三特征参数;所述降维聚合模块,还用于对所述第三特征参数进行降维与聚合,得到第四特征参数;svm模型训练模块,用于根据svm算法、所述第四特征参数以及第一年龄标注结果进行训练,生成所述svm模型,其中,所述第一年龄标注结果是对所述语音训练数据进行年龄标注得到的;存储模块,用于存储所述svm模型。
前述的语音年龄识别系统中,所述系统还包括:所述语音输入模块,还用于在生成所述svm模型之后,输入语音测试数据;所述预处理模块,还用于对所述语音测试数据进行预处理,得到第三预处理数据;所述特征提取模块,还用于对所述第三预处理数据进行特征提取,得到第五特征参数;所述降维聚合模块,还用于对所述第五特征参数进行降维与聚合,得到第六特征参数;所述svm识别模块,还用于根据所述svm模型以及所述第六特征参数识别出所述语音测试数据所属的年龄段,得到识别结果;比对模块,用于将所述识别结果与第二年龄标注结果进行比对,得到识别率,其中,所述第二年龄标注结果是对所述语音测试数据进行年龄标注得到的。
前述的语音年龄识别系统中,所述预处理包括分帧、加窗和预加重;和/或所述特征提取包括时域特征参数提取和频域特征参数提取,其中,时域特征参数包括短时过零率、短时能量谱和基音周期,频域特征参数包括lpcc、δlpcc、mfcc和δmfcc;和/或所述降维为采用pca算法进行数据降维,所述聚合为采用k-means算法进行数据聚合。
前述的语音年龄识别系统中,所述系统还包括:缓存模块,用于在对所述待识别语音数据进行预处理之前,对所述待识别语音数据进行循环缓存;读取模块,用于按一定时间间隔读取缓存的所述待识别语音数据。
与现有技术相比,本发明所述语音年龄识别方法及系统用计算机代替人工,很好的过滤非小孩语音,加快语音标注的速度,提升全人工标注的效率,提高语音识别率,同时能够降低人工成本。
附图说明
图1至6为本发明实施例一提供的方法的流程图;
图7至10为本发明实施例二提供的系统的结构示意图;
图11为本发明实施例一和二的原理框图。
下面结合附图和具体实施方式对本发明作进一步的说明。
具体实施方式
本发明实施例一:
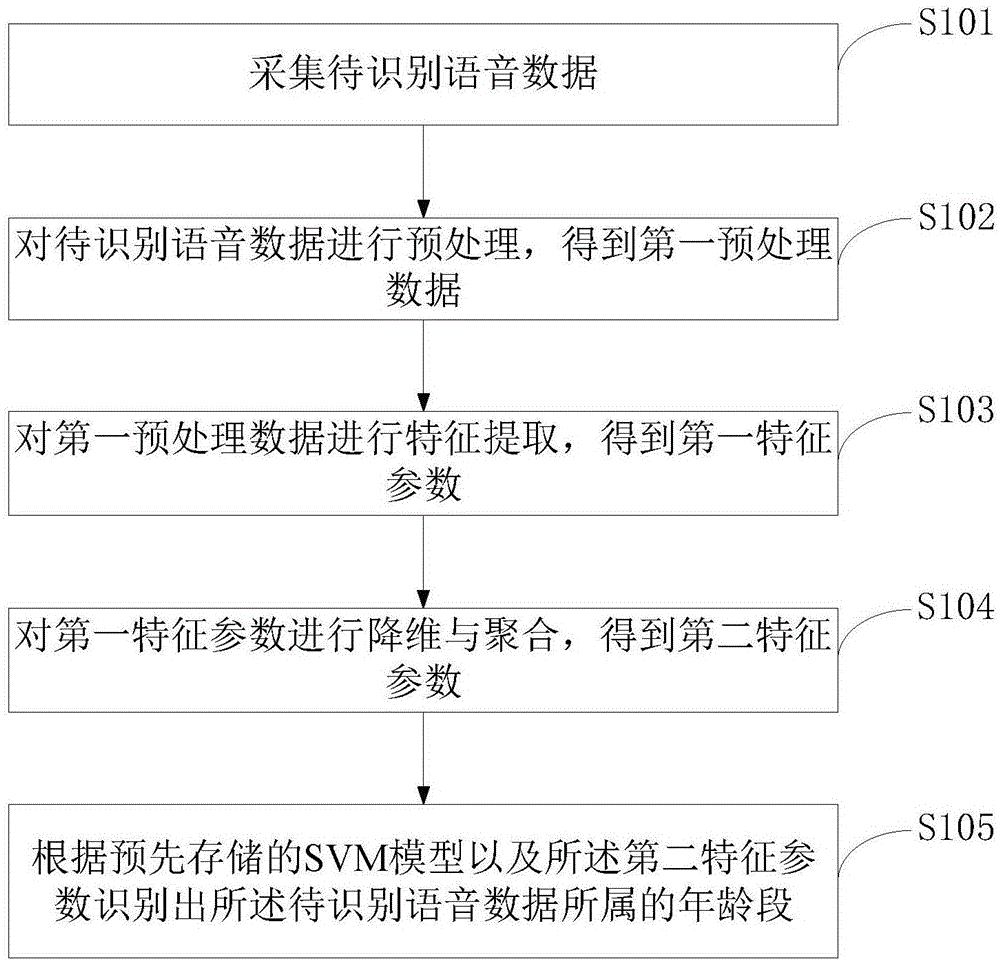
一种语音年龄识别方法,如图1所示,主要包括以下步骤:
步骤s101,采集待识别语音数据;
本实施例中,实际学生上课过程应用中,随着课程进行学生根据老师提问回答相应的问题,此时由在线教育客户端的音频采集模块不断采集待识别语音数据(pcm数据),并将pcm数据传送给sar(speechagerecognition)模块。
步骤s102,对待识别语音数据进行预处理,得到第一预处理数据;
在步骤s102中,如图2所示,sar模块接收到pcm数据后,判断是否第一次启用sar模块,若是则先加载svm模型,再对待识别语音数据进行预处理;若否则直接对待识别语音数据进行预处理。预处理包括分帧、加窗和预加重。分帧是将语音信号依据短时平稳性进行截断,帧长一般采用20ms,帧移一般采用10ms;加窗一般采用汉明窗或者汉宁窗,因为主瓣宽度对应频率分辨力,主瓣宽度越宽,其对应的频率分辨力越低,因此在选择窗函数时尽可能将能量集中于主瓣,或者最大旁瓣高度的相对幅度尽可能小,而汉明窗在幅频特性中旁瓣衰减较大,且可以减小吉布斯效应,所以语音信号的加窗处理一般选择汉明窗;由于语音信号易受声门激励和口鼻辐射的影响,在800hz以上的频率成份会出现6db/倍频程的衰减,因此需要通过预加重的方法来提升高频部分能量,借机弥补高频损失,一般采用一阶高通滤波器1-0.9375z-1来实现预加重。另外,预处理还可以包括抗混叠滤波。
作为本实施例的一种可选实施方式,如图3所示,在对待识别语音数据进行预处理之前,还包括:
步骤s106,对待识别语音数据进行循环缓存;
步骤s107,按一定时间间隔读取缓存的待识别语音数据。
在本可选实施方式中,为了在实际应用中避免因为断点检测引起的识别错误,在sar模块接收到pcm数据时候要对数据进行循环缓存,不断往循环缓存区写数据,但是读取数据采用10s间隔读取,每10秒判断一次年龄。
步骤s103,对第一预处理数据进行特征提取,得到第一特征参数;
在步骤s103中,sar模块对第一预处理数据进行特征提取,得到第一特征参数。如图4所示,特征提取包括时域特征参数提取和频域特征参数提取,其中,时域特征参数包括短时过零率、短时能量谱和基音周期,频域特征参数包括lpcc、δlpcc、mfcc和δmfcc。基于对发生机理和听觉特性的深刻研究,旨在增加特征参数的多样性,多次实验对于语音信号中年龄相关特征参数的提取和组合,多种特征参数涵盖的年龄信息对应的识别率,确定了时域和频域,发声和听觉,静态和动态相结合的多特征年龄识别方法。对常用的时域和频域,发声和听觉,静态和动态等特征矢量逐个进行试验,时域特征采用基因周期和过零率,频域用短时能量谱,发声机理的特征参数用lpcc,听觉特性的参数用mfcc,为了能提现声纹信息动态变化过程最后对lpcc和mfcc都做了一阶差分,最终选择lpcc以及一阶差分(n*24),mfcc以及一阶差分(n*24),基音周期(n*1),短时能量谱(n*1),短时平均过零率(n*1),按列进行组合,其中,n表示语音信号帧数。
步骤s104,对第一特征参数进行降维与聚合,得到第二特征参数;
在步骤s104中,sar模块对第一特征参数进行降维与聚合,得到第二特征参数。如图4所示,降维为采用pca算法进行数据降维,聚合为采用k-means算法进行数据聚合。其中lpcc及一阶差分(n*24)和mfcc及一阶差分(n*24)由pca算法分别选择8维主成分作为代替,且二者进行组合最终成了16维的特征向量,再加上基音周期,短时能量谱和短时过零率总共19维,形成n*19矩阵。为了提高svm训练效率,对每个长短不一的语料帧数做了k-means聚类,最后每个语料将有12*19矩阵来表征所有特征信息。
步骤s105,根据预先存储的svm模型以及第二特征参数识别出待识别语音数据所属的年龄段。
作为本实施例的一种可选实施方式,在步骤s105之前,如图5所示,还包括:
步骤s201,输入语音训练数据;
步骤s201中,通过语音输入模块输入语音训练数据,语音输入模块可以是麦克风等音频采集模块,也可以是数据传输接口,将大量语音训练数据传输到sar模块;
步骤s202,对语音训练数据进行预处理,得到第二预处理数据;
步骤s203,对第二预处理数据进行特征提取,得到第三特征参数;
步骤s204,对第三特征参数进行降维与聚合,得到第四特征参数;
步骤s205,根据svm算法、第四特征参数以及第一年龄标注结果进行训练,生成svm模型,其中,第一年龄标注结果是对语音训练数据进行年龄标注得到的;
步骤s206,存储svm模型。
对于上述步骤s202至s206中,sar模块对语音训练数据依次进行预处理、特征提取、降维与聚合,然后进行svm训练,得到svm模型,并进行存储,待后续需要时再读取svm模型。
上述步骤s202至s204中的预处理、特征提取、降维与聚合这些数据操作分别与步骤s102至s104中的预处理、特征提取、降维与聚合这些数据操作是相同的,此处不再赘述。
在本可选实施方式中,第一年龄标注结果就是给每个语音训练数据加一个年龄段标签,在训练时读取该年龄段标签。由于本方法集中应用于青少儿在线英语教育,其核心目的是在上课过程中实时识别出回答问题者是上课小孩本人还是家长,因此可以采用分三段的方法对语音训练数据进行标注(此三段的划分是充分依赖51talk客户),例如,规定年龄10岁以下为标签0,10至15岁为标签1,大于15岁为标签2。
在本可选实施方式中,参考模板的训练方法有多种,大体可以分为三大类,第一类是单纯的模型匹配法,包括矢量量化(vq)、动态时间规整(dtw)等;第二类是概率统计方法,包括高斯混合模型(gmm)、隐马尔科夫模型(hmm)等;第三类是辨别器分类方法,如支持向量机(svm)、人工神经网络(ann)和深度神经网络(dnn)等以及多种组合方法。本发明针对计算复杂度和实时性方面的多次实验最终选择svm作为分类算法。svm法即支持向量机(supportvectormachine)法,该方法是建立在统计学习理论基础上的机器学习方法。svm的目的在于寻找一个超平面h(d),该超平面可以将训练集中的数据分开,且与类域边界的沿垂直于该超平面方向的距离最大,故svm法亦被称为最大边缘(maximummargin)算法。svm方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题。svm方法巧妙地应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,在几乎不增加计算复杂度的前提下,还可以获得良好的分类效果。选择不同的核函数,可以生成不同的svm,常用的核函数有以下4种:
(1)线性核函数k(x,y)=x·y;
(2)多项式核函数k(x,y)=[(x·y)+1]^d;
(3)径向基函数k(x,y)=exp(-|x-y|^2/d^2);
(4)二层神经网络核函数k(x,y)=tanh(a(x·y)+b)。
本实施例使用多项式核函数生成svm算法。
在本可选实施方式中,预处理、特征提取、降维与聚合的具体处理方法与前述步骤s102至s104所述的方法相同,此处不再赘述。
作为本实施例的一种可选实施方式,如图6所示,在生成svm模型之后,还包括:
步骤s301,输入语音测试数据;
步骤s302,对语音测试数据进行预处理,得到第三预处理数据;
步骤s303,对第三预处理数据进行特征提取,得到第五特征参数;
步骤s304,对第五特征参数进行降维与聚合,得到第六特征参数;
步骤s305,根据svm模型以及第六特征参数识别出语音测试数据所属的年龄段,得到识别结果;
步骤s306,将识别结果与第二年龄标注结果进行比对,得到识别率,其中,第二年龄标注结果是对语音测试数据进行年龄标注得到的。
在本可选实施方式中,第二年龄标注结果就是给每个语音测试数据加一个年龄段标签,在计算识别率时读取该年龄段标签。对语音测试数据的年龄分段方法与对语音训练数据的年龄分段方法相同,此处不再赘述。
本实施例基于svm的语音年龄识别,当前根据数据处理需要只识别小孩和成人两种情况,使用的特征参数包括lpcc,mfcc,zcr(短时过零率),pitch(基音周期),ses(短时能量谱),经过调试运行正常。其中svm采用libsvm库,需要在官网下载并安装。目前标注数据总共883条,除去300个训练样本,测试样本为583个,除去mos分低于3分的26组,最终有效测试数据557。将混合后的特征参数给svm分类器进行识别,根据置信度不同可以得到不同的分类结果,目前提供置信度是0.6和0.8两种,识别结果见表1。其中小于10岁202条,10至15岁49条,大于15岁285条。从识别率来看,置信度为0.6时小孩的识别更准确,当置信度为0.8时成人识别更准确。
表1语音年龄识别不同置信度识别结果统计表
下面给出测试代码:
1.triandata.m语音数据训练集合测试集合准备;
2.children_feature.m遍历所有小孩文件夹下语音数据并做特征提取;
3.adults_feature.m遍历所有成人文件夹下语音数据并做特征提取;
4.svm_train.m整合特征训练集并训练模型保存于svmmodel.mat;
5.svm_train_predict_test.m测试基于svm的语音信号年龄识别。
由于目前对于少儿英语语音识别而言,语音年龄识别模块是为了数据标注和数据筛选开发的,在51talk客户端实际集成过程中要把matlab代码转成c代码编译成各个平台对应的库,如在ios平台根据ios版本编译成阿arm64和armv7两种静态库进行调用,对于pc平台直接提供lib库和头文件,对于android平台提供动态库和jni调用接口。
本实施例所述语音年龄识别方法基于语音特征参数的模式分类,即通过训练,能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。
本发明实施例二:
一种语音年龄识别系统,如图7所示,主要包括:音频采集模块401,用于采集待识别语音数据;预处理模块402,用于对待识别语音数据进行预处理,得到第一预处理数据;特征提取模块403,用于对第一预处理数据进行特征提取,得到第一特征参数;降维聚合模块404,用于对第一特征参数进行降维与聚合,得到第二特征参数;svm识别模块405,用于根据svm模型以及第二特征参数识别出待识别语音数据所属的年龄段。
本实施例中,实际学生上课过程应用中,随着课程进行学生根据老师提问回答相应的问题,此时由在线教育客户端的音频采集模块不断采集待识别语音数据(pcm数据),并将pcm数据传送给sar(speechagerecognition)模块。
本实施例中,如图2所示,sar模块接收到pcm数据后,判断是否第一次启用sar模块,若是则先加载svm模型,再对待识别语音数据进行预处理;若否则直接对待识别语音数据进行预处理。预处理包括分帧、加窗和预加重。分帧是将语音信号依据短时平稳性进行截断,帧长一般采用20ms,帧移一般采用10ms;加窗一般采用汉明窗或者汉宁窗,因为主瓣宽度对应频率分辨力,主瓣宽度越宽,其对应的频率分辨力越低,因此在选择窗函数时尽可能将能量集中于主瓣,或者最大旁瓣高度的相对幅度尽可能小,而汉明窗在幅频特性中旁瓣衰减较大,且可以减小吉布斯效应,所以语音信号的加窗处理一般选择汉明窗;由于语音信号易受声门激励和口鼻辐射的影响,在800hz以上的频率成份会出现6db/倍频程的衰减,因此需要通过预加重的方法来提升高频部分能量,借机弥补高频损失,一般采用一阶高通滤波器1-0.9375z-1来实现预加重。另外,预处理还可以包括抗混叠滤波。
作为本实施例的一种可选实施方式,如图8所示,系统还包括:缓存模块411,用于在对待识别语音数据进行预处理之前,对待识别语音数据进行循环缓存;读取模块412,用于按一定时间间隔读取缓存的待识别语音数据。
在本可选实施方式中,为了在实际应用中避免因为断点检测引起的识别错误,在sar模块接收到pcm数据时候要对数据进行循环缓存,不断往循环缓存区写数据,但是读取数据采用10s间隔读取,每10秒判断一次年龄。
本实施例中,如图4所示,特征提取包括时域特征参数提取和频域特征参数提取,其中,时域特征参数包括短时过零率、短时能量谱和基音周期,频域特征参数包括lpcc、δlpcc、mfcc和δmfcc。基于对发生机理和听觉特性的深刻研究,旨在增加特征参数的多样性,多次实验对于语音信号中年龄相关特征参数的提取和组合,多种特征参数涵盖的年龄信息对应的识别率,确定了时域和频域,发声和听觉,静态和动态相结合的多特征年龄识别方法。对常用的时域和频域,发声和听觉,静态和动态等特征矢量逐个进行试验,时域特征采用基因周期和过零率,频域用短时能量谱,发声机理的特征参数用lpcc,听觉特性的参数用mfcc,为了能提现声纹信息动态变化过程最后对lpcc和mfcc都做了一阶差分,最终选择lpcc以及一阶差分(n*24),mfcc以及一阶差分(n*24),基音周期(n*1),短时能量谱(n*1),短时平均过零率(n*1),按列进行组合,其中,n表示语音信号帧数。
如图4所示,降维为采用pca算法进行数据降维,聚合为采用k-means算法进行数据聚合。其中lpcc及一阶差分(n*24)和mfcc及一阶差分(n*24)由pca算法分别选择8维主成分作为代替,且二者进行组合最终成了16维的特征向量,再加上基音周期,短时能量谱和短时过零率总共19维,形成n*19矩阵。为了提高svm训练效率,对每个长短不一的语料帧数做了k-means聚类,最后每个语料将有12*19矩阵来表征所有特征信息。
作为本实施例的一种可选实施方式,如图9所示,系统还包括:语音输入模块406,用于输入语音训练数据;预处理模块402,还用于对语音训练数据进行预处理,得到第二预处理数据;特征提取模块403,还用于对第二预处理数据进行特征提取,得到第三特征参数;降维聚合模块404,还用于对第三特征参数进行降维与聚合,得到第四特征参数;svm模型训练模块407,用于根据svm算法、第四特征参数以及第一年龄标注结果进行训练,生成svm模型,其中,第一年龄标注结果是对语音训练数据进行年龄标注得到的;存储模块408,用于存储svm模型。
在本可选实施方式中,预处理模块402对待识别语音数据和语音测试数据进行预处理的方法是相同的,特征提取模块403对第一预处理数据和第二预处理数据进行特征提取的方法是相同的,降维聚合模块404对第一特征参数和第三特征参数进行降维与聚合的方法是相同的,因此,此处不再赘述。
在本可选实施方式中,第一年龄标注结果就是给每个语音训练数据加一个年龄段标签,在训练时读取该年龄段标签。由于本系统集中应用于青少儿在线英语教育,其核心目的是在上课过程中实时识别出回答问题者是上课小孩本人还是家长,因此可以采用分三段的方法对语音训练数据进行标注(此三段的划分是充分依赖51talk客户),例如,规定年龄10岁以下为标签0,10至15岁为标签1,大于15岁为标签2。
在本可选实施方式中,参考模板的训练方法有多种,大体可以分为三大类,第一类是单纯的模型匹配法,包括矢量量化(vq)、动态时间规整(dtw)等;第二类是概率统计方法,包括高斯混合模型(gmm)、隐马尔科夫模型(hmm)等;第三类是辨别器分类方法,如支持向量机(svm)、人工神经网络(ann)和深度神经网络(dnn)等以及多种组合方法。本发明针对计算复杂度和实时性方面的多次实验最终选择svm作为分类算法。svm法即支持向量机(supportvectormachine)法,该方法是建立在统计学习理论基础上的机器学习方法。svm的目的在于寻找一个超平面h(d),该超平面可以将训练集中的数据分开,且与类域边界的沿垂直于该超平面方向的距离最大,故svm法亦被称为最大边缘(maximummargin)算法。svm方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题。svm方法巧妙地应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,在几乎不增加计算复杂度的前提下,还可以获得良好的分类效果。选择不同的核函数,可以生成不同的svm,常用的核函数有以下4种:
(1)线性核函数k(x,y)=x·y;
(2)多项式核函数k(x,y)=[(x·y)+1]^d;
(3)径向基函数k(x,y)=exp(-|x-y|^2/d^2);
(4)二层神经网络核函数k(x,y)=tanh(a(x·y)+b)。
本实施例使用多项式核函数生成svm算法。
作为本实施例的一种可选实施方式,如图10所示,系统还包括:语音输入模块406,还用于在生成svm模型之后,输入语音测试数据;预处理模块402,还用于对语音测试数据进行预处理,得到第三预处理数据;特征提取模块403,还用于对第三预处理数据进行特征提取,得到第五特征参数;降维聚合模块404,还用于对第五特征参数进行降维与聚合,得到第六特征参数;svm识别模块405,还用于根据svm模型以及第六特征参数识别出语音测试数据所属的年龄段,得到识别结果;比对模块409,用于将识别结果与第二年龄标注结果进行比对,得到识别率,其中,第二年龄标注结果是对语音测试数据进行年龄标注得到的。
在本可选实施方式中,第二年龄标注结果就是给每个语音测试数据加一个年龄段标签,在计算识别率时读取该年龄段标签。对语音测试数据的年龄分段方法与对语音训练数据的年龄分段方法相同,此处不再赘述。
本实施例基于svm的语音年龄识别,当前根据数据处理需要只识别小孩和成人两种情况,使用的特征参数包括lpcc,mfcc,zcr(短时过零率),pitch(基音周期),ses(短时能量谱),经过调试运行正常。其中svm采用libsvm库,需要在官网下载并安装。目前标注数据总共883条,除去300个训练样本,测试样本为583个,除去mos分低于3分的26组,最终有效测试数据557。将混合后的特征参数给svm分类器进行识别,根据置信度不同可以得到不同的分类结果,目前提供置信度是0.6和0.8两种,识别结果见表1。其中小于10岁202条,10至15岁49条,大于15岁285条。从识别率来看,置信度为0.6时小孩的识别更准确,当置信度为0.8时成人识别更准确。
本实施例所述语音年龄识别系统基于语音特征参数的模式分类,即通过训练,能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。
本发明实施例的工作原理如图11所示,对输入的语音训练数据依次通过预处理、特征提取等操作,再通过svm训练得到svm模型,并进行保存,为后续的语音识别做准备;对输入的待识别语音数据也依次通过预处理、特征提取等操作,再根据svm模型判决,根据不同的置信度输出所属年龄段。
在本说明书的描述中,术语“一个实施例”、“一些实施例”、“具体实施例”“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的创造性精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!