电子装置及其语音指令识别方法与流程
本发明是有关于一种语音识别方法,且特别是有关于一种电子装置及其语音指令识别方法。
背景技术:
随着科技的进展,为了增进电子产品使用上的便利,越来越多的产品支持了语音控制。不过,大部分产品的语音控制功能需要连网才能有识别能力(如googlehome/语音助理;applehomepad/siri;amazonalexa等…)。因为,这些产品需要利用网络链接至远端的服务器,以让所述服务器来对这些产品所接收到的声音进行复杂的语音识别操作。
技术实现要素:
本发明提供一种电子装置及其语音指令识别方法,可在不连网的情况下,识别到所接收到的用户语音,并且对此用户语音独立地执行语音指令识别操作,以确认用户语音所欲执行的电子装置的目标指令,进而执行所述目标指令。
本发明的一实施例提供一种电子装置,其包括麦克风阵列、语音指令管理电路单元、存储单元与处理器。所述麦克风阵列获得多个声音信号。所述语音指令管理电路单元对所述多个声音信号执行一语音纯化操作,以获得纯化后声音信号,并且从纯化后声音信号中识别一目标语音信号,其中所述语音指令管理电路单元经由一复合式语音识别模型来计算对应所述目标语音信号的一复合式语音特征数据,其中所述语音指令管理电路单元比对复合式语音特征数据与语音特征数据库中的多笔参考语音特征数据,以判断所述目标语音信号所映射的目标指令。所述处理器执行所述目标指令。
本发明的一实施例提供一种语音指令识别方法,适用于具有麦克风阵列的电子装置。所述方法包括经由所述麦克风阵列获得多个声音信号;对所述多个声音信号执行一语音纯化操作,以获得纯化后声音信号,并且从纯化后声音信号中识别一目标语音信号;经由一复合式语音识别模型来计算对应所述目标语音信号的一复合式语音特征数据;比对复合式语音特征数据与语音特征数据库中的多笔参考语音特征数据,以判断所述目标语音信号所映射的目标指令;以及执行所述目标指令。
基于上述,本发明的实施例所提供的电子装置及适用于所述电子装置的语音识别方法,可在不需要连接网络的情况下,独立利用较少的运算资源来判断语音指令的存在而触发后续的语音纯化操作,藉由语音纯化操作强化语音指令(对应目标指令的语音)的清晰程度,并且藉由复合式语音识别模型与动态时间规整来较准确地判定用户所说的语音指令是映射至电子装置的目标指令,进而使电子装置可有效率地被用户的语音所控制。
为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图式作详细说明如下。
附图说明
图1是依照本发明的一实施例所绘示的电子装置的方块示意图。
图2是依照本发明的一实施例所绘示的电子装置的使用情境图。
图3a是依照本发明的一实施例所绘示的语音指令识别方法的流程图。
图3b是依照本发明的一实施例所绘示的语音指令识别方法的语音触发检测阶段的流程图。
图3c是依照本发明的一实施例所绘示的语音指令识别方法的语音纯化阶段的流程图。
图4a至4c是依照本发明的一实施例所绘示的声源定向操作的示意图。
图4d是依照本发明的一实施例所绘示的噪音压抑操作的示意图。
图5a至5b是依照本发明的一实施例所绘示的语音指令识别方法的语音指令映射阶段的流程示意图。
图6是依照本发明的一实施例所绘示的分群及权重分配的示意图。
图7a是依照本发明的一实施例所绘示的用以计算特征数据之间的距离的矩阵的示意图。
图7b是依照本发明的一实施例所绘示的经由动态时间规整比对参考语音特征数据的流程图。
具体实施方式
图2是依照本发明的一实施例所绘示的电子装置的使用情境图。请参照图2,本发明的一实施例提供一种电子装置10,可藉由所具有的麦克风阵列(例如包含多个麦克风110(1)~110(8))持续地接收电子装置10周遭的声音,所述声音包括任何环境音(如,家电31所发出的声音sd2或家电32所发出的声音sd3)与用户20的语音sd1(所述语音sd1可视为发自对应用户20的声源sr1)。并且,识别所接收的声音中是否具有符合电子装置10的其中一个指令。若符合,则电子装置10可对应地执行所符合的指令。以下会再藉由多个图式来说明所述电子装置10所使用的语音指令识别方法的细节。
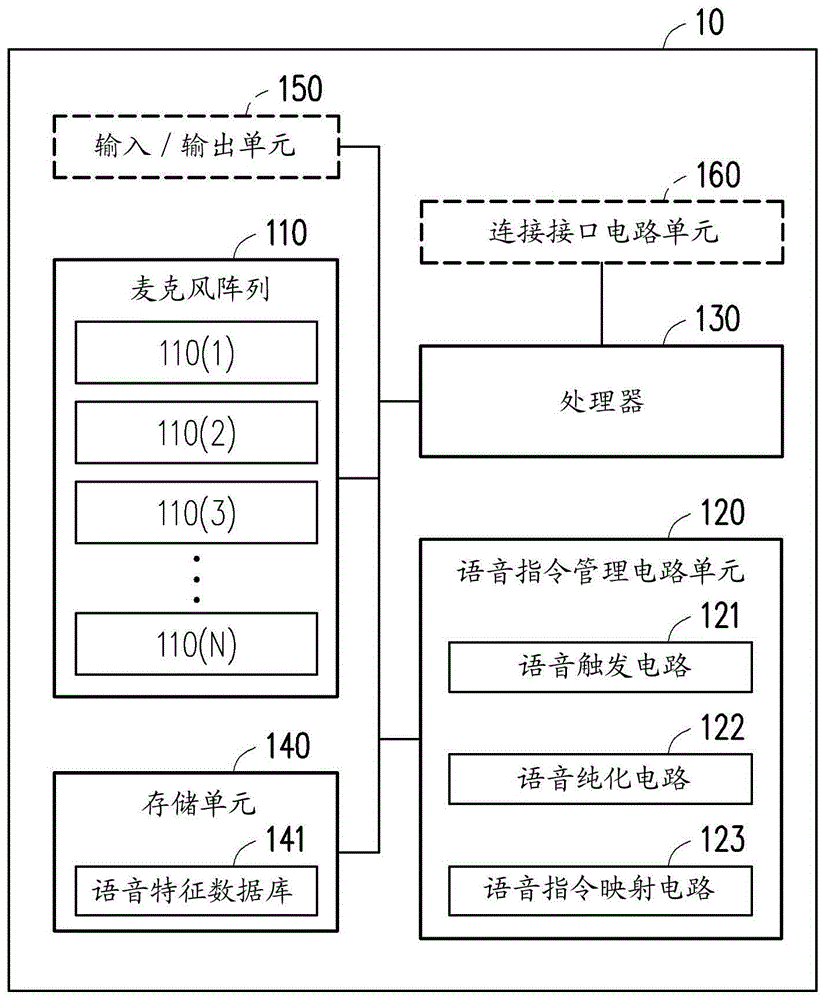
图1是依照本发明的一实施例所绘示的电子装置的方块示意图。请参照图1,在本实施例中,电子装置10包括麦克风阵列110、语音指令管理电路单元120、处理器130、存储单元140。在另一实施例中,所述电子装置10更包括输入/输出单元150与连接接口电路单元160。所述处理器130耦接至所述麦克风阵列110、所述语音指令管理电路单元120与所述存储单元140。
所述麦克风阵列110包括多个麦克风110(1)~110(n),n为所述多个麦克风的总数量。在本实施例中,n被预设为8,但本发明不限于所述多个麦克风的总数量n。例如,在其他实施例中,n可为大于8或小于8的正整数。n的较佳者为偶数,于另一实施例中n亦可为4。如图2所绘示,麦克风阵列110的8个麦克风110(1)~110(8)均匀地环状排列在电子装置10的上方,但本发明不限于此。例如,在其他实施例,麦克风阵列110的所述多个麦克风可适应电子装置的形状来被配置于电子装置的表面,以使所述麦克风阵列110可接收到来自电子装置10附近的任意方位的用户所发出的语音。所述麦克风阵列110中的每个麦克风用以接收(聆听)声音,并且可以将所接收到的声音转为声音信号。所述声音信号可被传送至语音指令管理电路单元120做进一步的处理。本发明并不限定于所述麦克风的其他细节。
处理器130为具备运算能力的硬件(例如芯片组、处理器等),用以管理电子装置10的整体运作,即,所述处理器130可控制每个功能的运作。在本实施例中,处理器130,例如是一核心或多核心的中央处理单元(centralprocessingunit,cpu)、微处理器(micro-processor)、或是其他可程序化的处理单元(programmableprocessor)、数字信号处理器(digitalsignalprocessor,dsp)、可程序化控制器、特殊应用集成电路(applicationspecificintegratedcircuits,asic)、可程序化逻辑装置(programmablelogicdevice,pld)或其他类似装置。
存储单元140可经由处理器130或语音指令管理电路单元120的指示来暂存数据,所述数据包括用以管理电子装置10的数据、用以执行语音识别操作的暂存数据或是其他类型的数据,本发明不限于此。除此之外,存储单元140还可以经由处理器130或语音指令管理电路单元120的指示来记录一些需要长时间存储的数据,例如,对应语音指令识别操作的语音特征数据库141或电子装置10的固件或是软件。值得一提的是,在另一实施例中,存储单元140也可以包含于处理器130中。存储单元140可以是任何型态的硬盘机(harddiskdrive,hdd)或非挥发性存储器存储装置(如,固态硬盘)。
如上述,在一实施例中,电子装置10包括输入/输出单元150,其可用以接收用户的输出操作,以触发电子装置10的一或多项功能。此外,输入/输出单元150也可用以输出信息。在本实施例中,输入/输出单元150可具有多个实体按钮与显示面板。在另一实施例中,输入/输出单元150可为触控屏幕。
此外,在一实施例中,处理器130可藉由连接接口电路单元160与其他电子装置连接,以与其他电子装置的处理器沟通,获得相关于其他电子装置的多个指令的信息。藉此,处理器130可以根据判断用户的语音是否符合其他电子装置的所述多个指令,以对其他电子装置的处理器下达指令,进而操控其他电子装置。连接接口电路单元160例如是兼容于串行高级技术附件(serialadvancedtechnologyattachment,sata)标准、并行高级技术附件(paralleladvancedtechnologyattachment,pata)标准、电气和电子工程师协会(instituteofelectricalandelectronicengineers,ieee)1394标准、高速周边零件连接接口(peripheralcomponentinterconnectexpress,pciexpress)标准、通用串行总线(universalserialbus,usb)标准、整合式驱动电子接口(integrateddeviceelectronics,ide)标准或其他适合的标准。
在本实施例中,所述语音指令管理电路单元120包括语音触发电路121、语音纯化电路122与语音指令映射电路123。所述语音指令管理电路单元120用以根据麦克风阵列110所接收的声音来执行语音指令识别操作。所述语音触发电路121、语音纯化电路122与语音指令映射电路123可用以执行语音指令识别操作的不同阶段。所述语音触发电路121、语音纯化电路122与语音指令映射电路123所执行的操作亦可表示为所述语音指令管理电路单元120的整体运作。
所述语音触发电路121用以选择麦克风阵列110的一个检测麦克风,根据对所述检测麦克风所产生的声音信号来执行语音触发检测操作(语音指令识别操作中的语音触发检测阶段),进而根据语音触发检测操作的结果来判断是否触发后续的处理程序(如,语音指令识别操作中的语音纯化阶段、语音指令识别阶段与语音指令执行阶段)。如此一来,可避免同时对多个麦克风的多个声音信号来执行多个语音触发检测操作,进而可节省语音指令管理电路单元120所耗费的运算资源。所述语音触发电路121可以根据所述多个麦克风所产生的多个声音信号,选择在所述多个声音信号中声强最大的声音信号所属的麦克风作为所述检测麦克风。此外,所述检测麦克风也可为用户或厂商所默认的麦克风。
语音纯化电路122用以在语音指令识别操作中的语音纯化阶段中执行语音纯化操作。在所述语音纯化操作中,语音纯化电路122可以识别对应用户语音的声源sr1相对于电子装置10的方向并且藉此强化用户语音的声强,同时降低其他方向的声音的声强。此外,在所述语音纯化操作中,语音纯化电路122更可进一步地根据持续更新的噪音信息来压抑多个声音信号中的噪音。如此一来,语音纯化电路122可从多个声音信号中获取出对应用户语音的目标语音信号。
语音指令映射电路123用以在语音指令识别操作中的语音指令映射阶段中执行语音指令映射操作。在所述语音指令映射操作中,语音指令映射电路123可根据目标语音信号来获得对应的复合式语音特征数据,并且比对所述复合式语音特征数据与所述语音特征数据库141中的多笔参考语音特征数据,以找出所述目标语音信号所映射的目标指令。语音指令映射电路123可传送所述目标指令至处理器130,以指示处理器130执行对应所述目标指令的功能。应注意的是,在一实施例中,语音指令映射电路123更可包含存储电路,以使所述语音特征数据库141可被存储至语音指令映射电路123的存储电路中。
以下会藉由图3a至3c来进一步说明本发明的一实施例所提供的语音指令识别方法的细节与所述电子装置10的各部件的运作。
图3a是依照本发明的一实施例所绘示的语音指令识别方法的流程图。请参照图1、2与图3a,在步骤s31中,经由麦克风阵列110获得多个声音信号(n预设为8)。具体来说,经由麦克风阵列110的多个麦克风110(1)~110(8),获得分别对应所述麦克风阵列的多个麦克风110(1)~110(8)的多个声音信号。所述多个声音信号被传送至语音指令管理电路单元120。在本实施中,假设麦克风110(1)被设定为检测麦克风(亦称,第一麦克风)。语音指令管理电路单元120会持续地分析麦克风110(1)所产生的声音信号(亦称,第一声音信号)(即,对第一声音信号执行语音触发检测操作)。
接着,根据分析结果,在步骤s32中,语音指令管理电路单元120用以从所述多个声音信号中的第一声音信号中识别第一触发语音信号。上述步骤s31与s32可表示语音指令识别操作中的语音触发检测阶段。以下利用图3b来说明语音触发检测阶段的细节。
图3b是依照本发明的一实施例所绘示的语音指令识别方法的语音触发检测阶段的流程图。请参照图3b,步骤s32包括步骤s321~s324。
在步骤s321中,根据所述第一声音信号的声强,识别所述第一声音信号中声强大于触发声强门限值的部份第一声音信号。在一实施例中,语音触发电路121只保留在人声频带(如,300赫兹至3400赫兹)的声音信号,以使所述第一声音信号为对应人声频带的声音信号。如此一来,可减少计算量,更可因只针对人声频带而避免其他种类的杂音所造成的影响,另外,亦可检测到缺乏能量、频率较快的清、浊音。
具体来说,语音触发电路121会分析第一声音信号的波形与声强。当第一声音信号的声强大于触发声强门限值时,语音触发电路121,会进一步设定一个起始时间,以累计在起始时间之后,第一声音信号的声强大于触发声强门限值的持续时间。换言之,所述部份第一声音信号为第一声音信号中连续的声强大于触发声强门限值的部份的声音信号。
接着,在步骤s322中,语音触发电路121判断所述部份第一声音信号的持续时间是否小于触发时间门限值。具体来说,本实施例假设用户所发出的对应电子装置的指令的语音的长度会小于触发时间门限值(如,3秒)。基此,反应于所述部份第一声音信号的所述持续时间的长度小于触发时间门限值,语音触发电路121判定所述部份第一声音信号为第一触发语音信号(步骤s323);反应于所述部份第一声音信号的所述持续时间的长度不小于触发时间门限值,语音触发电路121判定所述部份第一声音信号为噪音(步骤s324)。藉此,语音触发电路121可进一步地避免电子装置10周遭的持续性的噪音(如,电器运转声、电器所播放的声音)被作为触发语音信号。
此外,在另一实施例中,语音触发电路121假设用户所发出的对应电子装置的指令的语音的长度会大于临界时间门限值(如,0.5秒或1秒)且小于触发时间门限值(如,3秒)。基此,语音触发电路121会根据判断所述部份第一声音信号的持续时间是否大于临界时间门限值且小于触发时间门限值,以判定所述部份第一声音信号是第一触发语音信号或噪音。藉此,语音触发电路121可进一步地避免电子装置10周遭的短暂且大声的噪音被作为触发语音信号。
若所述部份第一声音信号被判定为噪音,则语音纯化电路122可根据被判定为噪音的所述部份第一声音信号来更新所记录的噪音信息,其中所述噪音信息被用于所述语音纯化操作中的噪音压抑操作中。例如,语音纯化电路122可根据被判定为噪音的所述部份第一声音信号的波形来过滤所述多个声音信号中的噪音。换句话说,在所述语音触发检测阶段中,第一声音信号中被判定的噪音可进一步地被反馈至后续的语音纯化操作,以强化语音纯化电路122压抑噪音的效率。
如上述,在判定所述部份第一声音信号为第一触发语音信号(步骤s323)后,语音触发电路121会指示语音纯化电路122执行后续的语音纯化阶段(即,步骤s33),即,流程会接续至步骤s33。
在步骤s33中,语音纯化电路122对所述多个声音信号执行语音纯化操作,以获得纯化后声音信号,并且从所述纯化后声音信号中识别一目标语音信号。
图3c是依照本发明的一实施例所绘示的语音指令识别方法的语音纯化阶段的流程图。请参照图3c,步骤s33可包括步骤s331~s333。
在步骤s331中,语音纯化电路122根据所述第一触发语音信号,对所述多个声音信号执行声源定向操作,以获得对应所述第一触发语音信号的声源角度。以下藉由图4a至图4c来说明声源定向操作的细节。
图4a至4c是依照本发明的一实施例所绘示的声源定向操作的示意图。请参照图4a,举例来说,假设声源sr1发出声音sd1,并且麦克风阵列110的多个麦克风110(1)~110(8)都会接收到声音sd1。在判定第一触发语音信号后,语音纯化电路122可从第一麦克风110(1)之外的其他麦克风110(2)~110(8)(亦称,第二麦克风)所产生的多个第二声音信号中分别识别其中的第二触发语音信号。也就是说,在判定第一声音信号中的第一触发语音信号的存在之后,语音纯化电路122可从每一个第二声音信号中识别到对应于第一触发语音信号的第二触发语音信号。所述第二触发语音信号的波形与声强会相似或相同于第一触发语音信号。在另一实施例中,所述多个麦克风各自可切割出大于触发声强门限值、大于临界时间门限值、小于触发时间门限值且为人类的声音频率的声音信号,以产生对应的声音信号给语音指令管理电路单元120。
接着,语音纯化电路122识别对应所述第一触发语音信号与所述多个第二触发语音信号的多个起始时间(亦可视为,所述多个第二声音信号的多个起始时间),并且根据所述多个起始时间计算麦克风110(1)~110(8)间的多个时间差。其中,麦克风110(1)~110(8)分别对应不同的角度(亦称,麦克风角度),所述多个时间差的每一个时间差各自对应不同的麦克风角度,并且不同的所述麦克风角度分别对应所述多个麦克风110(1)~110(8)中的不同的麦克风。更详细来说,由于8颗麦克风间彼此之间有非常多的排列组合与对应的多个时间差。为了让延迟时间更显著,得到最大的角度分辨率。在本实施例中,会使用对角关系来计算时间差。即,为了使一个时间差所对应的两个麦克风之间的间距为最大,本实施例是从8个麦克风中设定4个对角麦克风(如,麦克风110(1)与麦克风110(5)为一组对角麦克风;麦克风110(2)与麦克风110(6)为一组对角麦克风;麦克风110(3)与麦克风110(7)为一组对角麦克风;麦克风110(4)与麦克风110(8)为一组对角麦克风)。每个成对的对角麦克风彼此与电子装置10的中心c10的角度差为180度(对角)。此外,本实施例更利用对角麦克风的对称性,来计算时间差与对应的声源角度。经由对角麦克风110(1)、110(5)所获得的时间差td15与td51可被预先设定为对应至为0、180度的角度,并且可藉此来推算出其他对角麦克风的时间差所对应的角度值(如,对应对角麦克风110(3)、110(7)的时间差td37对应至为90度的角度)。一个时间差所对应的角度亦称为所述时间差的对应角度。
举例来说,如图4a所绘示,第一麦克风110(1)所产生的第一声音信号中的第一触发声音信号的起始时间为时间t1;第二麦克风110(2)~110(8)所产生的第二声音信号中的第二触发声音信号的起始时间为时间t2~t8。在本实施例中,语音纯化电路122计算每一对对角麦克风之间的起始时间的时间差。
例如,如图4b所绘示,第二麦克风110(3)与110(7)彼此成对,语音纯化电路122可计算出第二麦克风110(3)与110(7)之间的起始时间的时间差td37为第二麦克风110(3)的起始时间t3减去第二麦克风110(7)的起始时间t7的差值(即,td37=t3-t7)。在本实施例中,8个麦克风110(1)~110(8)共包含了4组对角麦克风,利用上述的方式,如同图4b中的表格所记载,语音纯化电路122可计算出对应四组对角麦克风的8个时间差,即,对应对角麦克风110(1)、110(5)的时间差td15与td51;对应对角麦克风110(2)、110(6)的时间差td26与td62;对应对角麦克风110(3)、110(7)的时间差td37与td73;对应对角麦克风110(4)、110(8)的时间差td48与td84。
接着,语音纯化电路122根据所述多个时间差,计算对应所述多组对角麦克风间的所述多个时间差的多个时间差移动平均。具体来说,在本实施例中,所述时间差td15对应麦克风110(1),并且其对应角度为0度;所述时间差td51对应麦克风110(5),并且其对应角度为180度;所述时间差td26对应麦克风110(2),并且其对应角度为45度;所述时间差td62对应麦克风110(6),并且其对应角度为-135度;所述时间差td37对应麦克风110(3),并且其对应角度为90度;所述时间差td73对应麦克风110(7),并且其对应角度为-90度;所述时间差td48对应麦克风110(4),并且其对应角度为135度;所述时间差td84对应麦克风110(8),并且其对应角度为-45度。
此外,考量到信号量测误差的消除,语音纯化电路122会进一步对所述多个时间差计算移动平均,其中移动平均所使用的参数设定为3。在本实施例中,语音纯化电路122将一个时间差所对应的麦克风为中心,根据移动平均所使用的参数“3”来找出在为中心的麦克风旁的2个麦克风与对应的2个时间差。接着,利用共3个时间差来计算时间差移动平均。
举例来说,对应时间差td15的时间差移动平均m1(亦对应麦克风110(1))会利用包含时间差td15以及前后时间差td26、td84的共3个时间差来进行移动平均。即,对应时间差td15的时间差移动平均m1为-13/3(即,
(td26+td15+td84)/3),并且所述时间差移动平均m1的对应角度相同于时间差td15的对应角度(即,0度)。以此类推,如图4c中的表格所示,语音纯化电路122可计算出其余的时间差移动平均m2~m8与各自的对应角度。
接着,语音纯化电路122根据所述多个时间差移动平均m1~m8的大小来选择多个目标时间差移动平均,其中所述多个目标时间差移动平均的数量小于所述多个时间差移动平均的数量。具体来说,越接近第一触发语音信号的声源sr1的麦克风所对应的时间差移动平均的值会越小,即,在本例子中,对应时间差移动平均m1的麦克风110(1)是在所有麦克风110(1)~110(8)中最接近声源sr1的麦克风。在一实施例中,语音纯化电路122会选择所有为负值的时间差移动平均来做为目标时间差移动平均。
接着,语音纯化电路122根据所述多个目标时间差移动平均与分别对应所述多个目标时间差移动平均的多个对应角度来计算所述声源角度。具体来说,语音纯化电路122先计算所述多个目标时间差移动平均的总和,并且将每个所述多个目标时间差移动平均除以所述多个目标时间差移动平均的总和,来获得多个时间差比率。举例来说,接续上述的例子,为负值的时间差移动平均m1、m8、m2被设定为目标时间差移动平均。所述多个目标时间差移动平均m1、m8、m2的总和为-31/3,并且对应的时间差比率为13/31、9/31与9/31(如,图4c中的表格所示)。
接着,语音纯化电路122将对应所述多个目标时间差移动平均m1、m8、m2的对应角度0度、45度、-45度各自乘以对应所述多个目标时间差移动平均m1、m8、m2的时间差比率,以获得对应所述多个目标时间差移动平均m1、m8、m2的加权后角度0度、(405/31)度与(-405/31)度。最后,语音纯化电路122加总对应所述多个目标时间差移动平均m1、m8、m2的所有加权后角度,以获得加权后角度总和,并且将加权后角度总和作为对应声源sr1的声源角度。
如图4c所绘示,所计算的声源角度为0度,即,声源sr1相对于电子装置的中心点c10的角度为0度,并且其对应麦克风110(1)的对应角度“0度”。例如,假设随着用户的移动,触发语音为语音sd1’,计算出的声源角度从0度转变至-45度(如,箭头a41所示)。在此情境下,移动后的声源sr1’相对于中心点c10的角度为-45度。
接着,在获得声源角度后,在步骤s332,语音纯化电路122根据所述声源角度对所述多个声音信号执行声音聚束操作,以产生聚束后声音信号。具体来说,语音纯化电路122会经由聚束形成(beamforming)技术,读取所述第一触发语音信号与所述多个第二触发语音信号,并且利用所述声源角度来计算对应每个声音信号的转向向量(steervectors),以将对应所述声源角度的声音信号分离出来。如,对一个声音信号,强化此声音信号中于所述声源角度的角度范围内的部份声音信号的声强,并且减弱其他部份的声音信号的声强(或是直接滤除其他部份的声音信号)。如此一来,可将调整声强后的所述多个声音信号集合为聚束后声音信号。上述操作可称为声音聚束操作。
在一实施例中,语音纯化电路122根据所述声源角度,识别每一所述多个声音信号中对应所述声源角度的聚束部份与非聚束部份。所述语音纯化电路122可增加每一所述多个声音信号中的所述聚束部份的声强,减少每一所述多个声音信号中的所述非聚束部份的声强,并且根据所述声源角度与对应所述多个麦克风的多个时间差来将所述多个声音信号中的所述聚束部份相加,以获得聚束后声音信号。在另一实施例中,语音纯化电路122可根据下列步骤来执行声音聚束操作:(1)所述多个声音信号的时域信号经过傅立叶变换转至频域;(2)利用所述声源角度来计算对应每个声音信号的转向向量;(3)利用得到的转向向量来建立波束形成器;(4)将频域的所述多个声音信号输入至波束形成器以相乘叠加,以获得单一声音信号;(5)对所获得的单一的声音信号进行反傅立叶变换,以获得时域的聚束后声音信号。
接着,在步骤s333中,语音纯化电路122对所述聚束后声音信号执行噪音压抑操作,以获得目标语音信号。
图4d是依照本发明的一实施例所绘示的噪音压抑操作的示意图。请参照图4d,图4d上方是一个聚束后声音信号的信号波形图。聚束后声音信号中具有多个噪音区段与非噪音区段410、420、430。所述非噪音区段410、420、430为对应所述声源角度的声音信号。
具体来说,语音纯化电路122根据上述的噪音信息与人声频带,利用两步估测法(two-stepnoisereduction,tsnr)与谐波重建法(harmonicregenerationnoisereduction),经由维纳滤波器(wienerfilter),降低所述聚束后声音信号中的噪音的声强,以获得纯化后声音信号。所述两步估测法可避免运算时所造成的音框延迟;所述谐波重建法,可避免过度压抑噪音而产生声音信号的失真。在本实施例中,维纳滤波器可用于压抑稳态的背景噪音。此外,在本实施例中,语音纯化电路122可进一步利用所述噪音信息来补足维纳滤波器的缺陷。如上述,所述噪音信息为适应性背景噪音信息,即,在语音识别操作中所识别出的暂态噪音的相应信息。语音纯化电路122可相应地利用目前环境中的暂态噪音的噪音信息经由所述两步估测法与所述谐波重建法来压抑声音信息中的暂态噪音。若没有检测到任何语音活动,所识别出的环境噪音可对应地被持续更新,以使适应性背景噪音信息可持续地根据环境噪音的变化而对应地更新。应注意的是,在上述的噪音压抑操作中,语音纯化电路122会根据人声频带(300hz至3400hz),仅保留聚束声音信号中于这频带范围内的声音信号,并且移除这频带范围之外的声音信号。
也就是说,请参照图4d,如箭头a21所示,图4d上方的聚束后声音信号(亦可称,纯化后声音信号),可经由所执行的噪音压抑操作来获得目标语音信号。具体来说,非噪音区段410、420、430中的声音信号的波形经过噪音压抑操作后,会变成更为清晰的声音信号(如,非噪音区段411、421、431),其中的噪声(如,噪音所导致的声音信号的噪声)也会被消除。于一实施例中,语音纯化电路122使用目标声强门限值来从纯化后声音信号中识别目标语音信号。语音纯化电路122可从非噪音区段411、421、431中识别所述目标语音信号。所述目标语音信号的声强大于目标声强门限值。例如,上述非噪音区段411、421、431中的声音信号的声强皆大于目标声强门限值,并且非噪音区段411、421、431中的声音信号皆为合格的目标语音信号。被识别出的目标语音信号会被语音纯化电路122所获取,并且被用于后续的语音指令映射阶段(即,步骤s34~s35)。以下会利用图5a、5b来说明语音指令映射阶段的细节。
图5a至5b是依照本发明的一实施例所绘示的语音指令识别方法的语音指令映射阶段的流程示意图。
请同时参照图3a与5a,在步骤s34中,语音指令映射电路123基于所述目标语音信号,经由复合式语音识别模型来计算对应所述目标语音信号的复合式语音特征数据。详细来说,复合式语音识别模型包括第一复合式语音识别模型511与第二复合式语音识别模型512。
所述第一复合式语音识别模型511包括mfs(mel-scalefrequency)滤波器与imfs(inversemel-scalefrequency)滤波器。其中mfs滤波器根据人耳听觉系统的特性,将频率信号转换为mel刻度,以模拟人耳对声音的感受。所述imfs滤波器主要是补足原始mfs滤波器在频率-声强结构上的不足(imfs滤波器的频率-声强结构相似于mfs滤波器的频率-声强结构的镜像)。所述第一复合式语音识别模型511用来强化语者声纹。
所述第二复合式语音识别模型512包括gfs(gammatone-scalefrequency)滤波器与igfs(inversegammatone-scalefrequency)滤波器。gfs滤波器可将保留语音中的关键的模板特征,并且对其中的噪声加以模糊化。换言之,gfs滤波器会使所获得的语音特征数据具有较高的抗噪性。所述igfs滤波器主要是补足原始gfs滤波器在频率-声强结构上的不足(igfs滤波器的频率-声强结构相似于gfs滤波器的频率-声强结构的镜像)。所述第二复合式语音识别模型512用来强化语音特征。
如此一来,由于复合式语音识别模型同时利用了上述的滤波器,可以同时保留目标语音信号的声纹特征,并且提高目标语音信号的抗噪性。
请参照图5a,在本实施例中,语音指令映射电路123输入所述目标语音信号至所述复合式语音识别模型中的第一复合式语音识别模型511(步骤s51-1),以获得第一复合式语音特征数据521(如,compoundmelfeatures,cmf)(步骤s52-1),并且输入所述目标语音信号至所述复合式语音识别模型中的第二复合式语音识别模型512(步骤s51-2),以获得第二复合式语音特征数据522(如,compoundgammatonefeatures,cgf)(步骤s52-2)。
语音指令映射电路123对所述第一复合式语音特征数据与所述第二复合式语音特征数据执行特征压缩操作(步骤s53-1、s53-2),以获得压缩后第一复合式语音特征数据531(如,compressedcompoundmelfeatures,ccmf)与压缩后第二复合式语音特征数据532(如,compressedcompoundgammatonefeature,ccgf)。所述压缩后第一复合式语音特征数据与所述压缩后第二复合式语音特征数据为所述复合式语音特征数据。由于经由所述特征压缩操作所获得的复合式语音特征数据的数据量远小于所述第一复合式语音特征数据与所述第二复合式语音特征数据。如此一来,对于复合式语音特征数据的语音映射操作的运算量也会大量减少,进而减少了运算时间。
在本实施例中,处理器130可接收用户的输入操作,以启动电子装置10的训练模式。在此训练模式中,用户可指定要训练的电子装置的目标指令,并且说出对应的语音,以使语音指令管理电路单元120可在获得对应此语音的目标语音信号的复合式语音特征数据后,判定此复合式语音特征数据为对应此目标指令的训练用的复合式语音特征数据,并且将此复合式语音特征数据存储至对应的语音特征数据库,以成为参考语音特征数据。
也就是说,反应于判定所述电子装置10处于对应所述目标指令的所述训练模式,语音指令映射电路123存储所述压缩后第一复合式语音特征数据与所述压缩后第二复合式语音特征数据于所述语音特征数据库(如,分别存储于第一语音特征数据库141-1与第二语音特征数据库141-2)中,以成为参考语音特征数据,并且所存储的所述压缩后第一复合式语音特征数据与所存储的所述压缩后第二复合式语音特征数据被映射至所述目标指令。
相对地,反应于判定所述电子装置10不处于所述训练模式,语音指令映射电路123分别对所述压缩后第一复合式语音特征数据与所述压缩后第二复合式语音特征数据执行语音映射操作s35-1、s35-2,以藉由存储在第一语音特征数据库141-1与第二语音特征数据库141-2的多个参考语音特征数据来判断所述目标语音信号所映射的所述目标指令。应注意的是,本发明并不限定于压缩所述复合式语音特征数据的方式。
请再参照图3a,在获得所述复合式语音特征数据,在步骤s35中,语音指令映射电路123经由动态时间规整(dynamictimewraping,dtw)的方式,比对所述复合式语音特征数据与语音特征数据库141中的多笔参考语音特征数据,以判断所述目标语音信号所映射的目标指令。
具体来说,请参照图5b,以压缩后第一复合式语音特征数据531为例子。首先,语音指令映射电路123会经由所述动态时间规整的方式,将所述复合式语音特征数据来比对所述语音特征数据库中的多笔参考语音特征数据,以从所述多笔参考语音特征数据中识别k个最终最近参考语音特征数据(步骤s54-1)。应注意的是,在步骤s54-1中,会利用所述动态时间规整的方式以及最近邻居法的概念来从第一语音数据库141-1中依照时间顺序找出k个最近参考语音特征数据。在最后的时间点所找出的k个最近参考语音特征数据即为所述k个最终最近参考语音特征数据,其中每个最终最近参考语音特征数据会映射一个指令。所述k为预先设定的正整数。
以下先利用图7a、7b来说明本实施例所使用的动态时间规整的方式的细节。
图7a是依照本发明的一实施例所绘示的用以计算特征数据之间的距离的矩阵的示意图。举例来说,假设目前欲计算语音特征数据s与参考语音特征数据k1之间的距离。此外,语音特征数据s具有3个音框数,如,s=[vf1,vf2,vf3],其中每个vf为对应3个音框的多个特征向量的集合(如,vf1为对应第一个音框的特征向量的集合)。参考语音特征数据k1具有4个音框数,如,k1=[k1f1,k1f2,k1f3,k1f4],其中每个k1f为对应的音框的4个特征向量的集合(如,k1f1为对应参考语音特征数据k1中第一个音框的特征向量的集合)。
请参照图7a,为了计算语音特征数据s与参考语音特征数据k1之间的距离,语音指令映射电路123建立一个距离矩阵m1,所述距离矩阵m1的维度是根据语音特征数据s与参考语音特征数据k1各自的音框数来决定的。以此例,语音特征数据s的音框数为3,参考语音特征数据k1的音框数为4。因此距离矩阵m1为4*3的矩阵。
接着,语音指令映射电路123利用下列公式来计算距离矩阵m1的每个元素的数值。所述元素可代表语音特征数据s与参考语音特征数据k1的对应的音框的多个特征向量之间的距离。假设每个音框有147个特征向量。
图7a中的距离矩阵m1的各元素aij的值等于m1(i,j)。例如,
所述元素a11为语音特征数据s的第一个音框的147个特征向量与参考语音特征数据k1的第一个音框的147个特征向量之间的距离。以此类推,可计算出距离矩阵m1的每个元素的值。矩阵计算的顺序为从左而右,从上而下。即,先计算a11,a12,a13,再计算a21,a22,a23,再计算a31,a32,a33,再计算a41,a42,a43。
图7b是依照本发明的一实施例所绘示的经由动态时间规整比对参考语音特征数据的流程图。请参照图7b,图7b的步骤s71~s80可视为图5b中的步骤s54-1的流程步骤。“h”用以辨别当前与压缩后第一复合式语音特征数据进行比较的第一语音特征数据库141-1的参考语音特征数据,并且所述h的初始为1(表示第“1”个与压缩后第一复合式语音特征数据进行比较的参考语音特征数据,意即上述的第“1”个参考语音特征数据为参考语音特征数据k1,将参考语音特征数据k1与压缩后第一复合式语音特征数据进行比较,第“2”个参考语音特征数据即为参考语音特征数据k2,以此类推)。以压缩后第一复合式语音特征数据为例,所述在步骤s71中,语音指令映射电路123经由动态时间规整来计算压缩后第一复合式语音特征数据与第h个参考语音特征数据的距离矩阵。计算距离矩阵的方法已经说明如上,不赘述于此。在步骤s72中,语音指令映射电路123判断h是否大于k。若不大于k(步骤s72→否),接续至步骤s73,语音指令映射电路123存储对应所述第h个参考语音特征数据的所述距离矩阵,并且设定所述第h个参考语音特征数据为候选参考语音特征数据。接着,在步骤s74中,语音指令映射电路123判断h是否等于k。若不等于k(步骤s74→否),接续至步骤s76,h=h+1,即,语音指令映射电路123将h加上1,选择下一个参考语音特征数据。接着,流程再回到步骤s71。
若在步骤s74中,判定h等于k(步骤s74→是),并且流程接续至步骤s75。此时,语音指令映射电路123可知道目前已经设定的候选参考语音特征数据的总数目等于预先设定的k。在步骤s75中,语音指令映射电路123初始化终止阈值。具体来说,语音指令映射电路123从对应k个候选参考语音特征数据的距离矩阵的多个元素(距离)中找寻最大者(最大距离值),并且将终止阈值的数值设定为所找到的最大距离值。接着,执行步骤s76,h的值又加1。
若在步骤s72中,语音指令映射电路123判定h大于k,接续至步骤s77,语音指令映射电路123判断对应所述第h个参考语音特征数据的所述距离矩阵是否具有大于所述终止阈值的距离值。具体来说,语音指令映射电路123会比较所述第h个参考语音特征数据的所述距离矩阵中的每个元素(距离值)与所述终止阈值。若不大于(步骤s77→否),接续至步骤s78;若大于(步骤s77→是),接续至步骤s80。
在一实施例中,在h大于k后,于执行步骤s77,即,计算所述第h个参考语音特征数据的所述距离矩阵的过程中,语音指令映射电路123会比较距离矩阵的每一个元素(距离值)与终止阈值。当距离矩阵中有一行的距离值皆大于所述终止阈值时,就停止计算距离矩阵的其他距离值,并且接续至步骤s80,可加速寻找k个最终最近参考语音特征数据的运算速度。
在步骤s78中,语音指令映射电路123存储对应所述第h个参考语音特征数据的所述距离矩阵,并且设定所述第h个参考语音特征数据为候选参考语音特征数据。具体来说,语音指令映射电路123设定所述第h个参考语音特征数据为候选参考语音特征数据(候选参考语音特征数据的总数目为k+1),并且从所有的候选参考语音特征数据删除具有终止阈值的候选参考语音特征数据,以保留k个候选参考语音特征数据。
接着,在步骤s79中,语音指令映射电路123更新终止阈值。即,语音指令映射电路123,会找寻当前的k个候选参考语音特征数据的多个距离矩阵的多个距离值中的最大者,并且将此最大者设定为新的终止阈值。
接着,在步骤s80中,语音指令映射电路123判断h是否等于第一语音特征数据库的参考语音特征数据总数目。若是(s80→是),语音指令映射电路123会判定第一语音特征数据库的所有参考语音特征数据皆已经由动态时间规整的方式来与压缩后第一复合式语音特征数据计算出对应的距离矩阵,并且当前的所设定的k个候选参考语音特征数据即为所述k个最终最近参考语音特征数据。接着,语音指令映射电路123执行步骤s55-1;若否(s80→否),流程接续至步骤s76。如此一来,经由图7b所述的流程,语音指令映射电路123可以找到k个最终最近参考语音特征数据。
请再回到图5b,在找出所述k个最终最近参考语音特征数据后,语音指令映射电路123会对k个最终最近参考语音特征数据来进行分群及权重分配(步骤s55-1)。以下利用图6来说明。应注意的是,压缩后第二复合式语音特征数据532的语音映射操作相似于压缩后第一复合式语音特征数据531的语音映射操作,不再赘述于此。
图6是依照本发明的一实施例所绘示的分群及权重分配的示意图。举例来说,如图6中的例子,假设压缩后第一复合式语音特征数据为目标特征值tf,k被设定为6,并且于多个参考语音特征数据db1~db15中,k个最终最近参考语音特征数据为db1~db6,其中最终最近参考语音特征数据db1~db4映射至电子装置10的多个指令中的第一指令,并且最终最近参考语音特征数据db5~db6映射至第二指令。此外,信心阈值被设定为3。
语音指令映射电路123会计算所述复合式语音特征数据分别与所述k个最终最近参考语音特征数据db1~db6之间的k个距离d1~d6,根据k个距离d1~d6的大小来分别赋予所述k个最终最近参考语音特征数据一次序权重值,其中越小的距离对应越大的次序权重值。如表600所示,语音指令映射电路123可依据距离d1~d6,由近至远,来识别对应的接近次序,将所述k个最终最近参考语音特征数据db1~db6依据对应的接近次序来排序,并且根据接近次序赋予对应的次序权重值(即,接近次序越前方,对应的次序权重值越大)。如,根据接近次序为“1、2、3、4、5、6”,将最终最近参考语音特征数据的次序权重值依序设定为“1、0.85、0.8、0.75、0.7、0.65”。
接着,语音指令映射电路123根据所述k个最终最近参考语音特征数据的所述次序权重值对所述k个最终最近参考语音特征数据所映射的一或多个指令分别进行权重加总运算,以获得所述一或多个指令各自的总权重值。例如,于一实施例中,依据距离赋予所述k个最终最近参考语音特征数据db1~db6的所述次序权重值分别为1、0.65、0.7、0.85、0.8、0.75。则,对应第一指令的总权重值即为映射至第一指令的最终最近参考语音特征数据db1~db4的次序权重值1、0.65、0.7、0.85的总和(即,3.2);对应第二指令的总权重值即为映射至第二指令的最终最近参考语音特征数据db5~db6的次序权重值0.8、0.75的总和(即,1.55)。
在计算出总权重值后,语音指令映射电路123根据所述一或多个总权重值中的最大总权重值与一信心阈值来判断所述一或多个指令中是否具有映射至所述目标语音信号的所述目标指令(步骤s56-1),其中反应于所述最大总权重值大于所述信心阈值,语音指令映射电路123判定所述一或多个指令中对应所述最大总权重值的指令为所述目标语音信号所映射的所述目标指令,其中反应于所述最大总权重值不大于所述信心阈值,语音指令映射电路123判定所述目标语音信号为噪音。被判定为噪音的目标语音信号也可用来更新噪音信息。
例如,在此例子中,由于最大的总权重值是对应第一指令的总权重值,并且对应第一指令的总权重值大于信心阈值(即,3.2>3)。语音指令映射电路123判定对应第一指令的总权重值具有可信度,并且第一指令即为目标语音信号所映射的目标指令(步骤s57-1)。语音指令映射电路123会输出目标语音信号所映射的目标指令给处理器130(步骤s58-1)。应注意的是,当步骤s57-1与s57-2所判定的目标指令不同时,于步骤s59中,语音指令映射电路123会进一步加总于步骤s55-1、s55-2的相同指令的总权重值,以获得统合的多个指令的总权重值,并且判定具有最大总权重值的指令为目标指令。
接着,请回到图3a,在判定目标语音信号所映射的目标指令后,语音指令映射电路123会告知处理器130,并且在步骤s36中,处理器130执行所述目标指令。所述目标指令的详细的指令叙述内容已经记载于电子装置10的固件中,并且所述处理器130可根据所述目标指令的所述指令叙述内容来执行所述目标指令,本发明并不限定于所述目标指令的详细指令叙述内容。
应注意的是,上述语音识别操作并不会经由网络连线或是其他连线来使用其他电子装置来以执行。换言之,上述语音识别操作皆可经由电子装置10中的语音指令管理电路单元120独立执行完成。也因为没有连线至其他外部装置,用户个人数据的安全性也得以保障。
值得一提的是,在本范例实施例中,语音指令管理电路单元120是以硬件电路实施,但本发明不限于此。语音指令管理电路单元120可以程序代码或软件来实现相同于语音指令管理电路单元120的功能,并且被存储在存储单元140中。例如,语音指令管理电路单元120的功能可实作为以多个程序指令所组成的语音指令管理模块,其包括语音触发模块、语音纯化模块及语音指令映射模块。并且,语音指令管理模块可由处理器130来执行以完成上述语音指令管理电路单元120的功能。换言之,本发明的上述方法可实现在软件或固件中,或者可实现为可存储在记录介质(诸如cdrom、ram、软盘、硬盘或磁光盘)中的软件或计算机代码。另外,当处理器10存取上述的程序代码模块,以实现在上述语音识别方法时,所述电子装置10也转变为特定功能的可处理上述语音识别操作的专用电子装置。
综上所述,本发明的实施例所提供的电子装置及适用于所述电子装置的语音识别方法,可在不需要连接网络的情况下,独立利用较少的运算资源来判断语音指令的存在而触发后续的语音纯化操作,藉由语音纯化操作强化语音指令(对应目标指令的语音)的清晰程度,并且藉由复合式语音识别模型与动态时间规整来较准确地判定用户所说的语音指令是映射至电子装置的目标指令,进而使电子装置可有效率地被用户的语音所控制。此外,由于可不经由连接网络而完成语音指令映射操作,本发明的实施例更可避免用户个人数据经由网络连线而外泄,进而保障了用户个人数据的安全性,并且适用于需要对个人数据保密的特定电子装置(如,个人辅助器具、医疗设备等…)。
虽然本发明已以实施例揭露如上,然其并非用以限定本发明,本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视后附的权利要求所界定者为准。
【符号说明】
10:电子装置
20:用户
31、32:其他电子装置
sd1、sd1’、sd2、sd3:声音
sr1、sr1’:声源
c10:中心点
110:麦克风阵列
110(1)~110(8):麦克风
120:语音指令管理电路单元
121:语音触发电路
122:语音纯化电路
123:语音指令映射电路
130:处理器
140:存储单元
141、141-1、141-2:语音特征数据库
150:输入/输出单元
160:连接接口电路单元
s31、s32、s33、s34、s35、s36:语音识别方法的流程步骤
s321、s322、s323、s324:语音识别方法的步骤s32的流程步骤
s331、s332、s333、s334:语音识别方法的步骤s33的流程步骤
t1~t8:时间
td15、td51、td26、td62、td37、td73、td48、td84:时间差
m1~m8:时间差移动平均
a41、a42:箭头
410、411、420、421、430、431:区域
510、511、512:复合式语音识别模型
521、522、531、532:特征数据
s51-1、s51-2、s52-1、s52-2、s53-1、s53-2、s35-1、s35-2、s54-1、s54-2、s55-1、s55-2、s56-1、s56-2、s57-1、s57-2、s58-1、s58-2、s59:语音指令映射阶段的步骤
db1~db15:参考语音特征数据
600:表格
d1~d6:距离
tf:对应目标语音信号的复合式语音特征数据
- 还没有人留言评论。精彩留言会获得点赞!