一种基于条件随机场的中国民歌地域分类方法与流程
本发明属于机器学习与数据挖掘领域,具体涉及一种基于条件随机场的中国民歌地域分类方法。
背景技术:
在多媒体技术高速发展的当下,音乐已从以往的唱片、磁带等形式演变为数字化音乐,庞大的数字音乐数据需要更高效的管理。在此背景下,音乐信息检索和音乐分类识别具有重要的学术意义和广泛的应用场景,引起了学术界和工业界的极大关注。音乐分类技术的发展有助于对不同类别音乐进行智能管理,并且帮助用户在感兴趣的类别中实现音乐高速检索。随着音乐数据的海量增长,如何在进一步提高音乐的分类精度和效率显得尤为重要。
随着中国文化的传播和发展,具有显著地域风格的中国民歌开始被更多的人接触与喜欢,因此对中国民歌基于地域风格分类的研究就尤为重要了。然而,民歌一般是即兴编作、口头传唱,缺少严格的创作规则,且各个地域民歌风格的类别较为模糊,直接单独使用帧特征不能很好的表征地域风格类别,因此相关的研究成果较少。
技术实现要素:
本发明的目的是解决以往民歌地域风格分类算法中存在的特征序列时序缺失问题,提出了一种基于条件随机场的中国民歌地域分类方法,该方法在建立特征序列时序关系的同时,解决了以往研究计算标注序列的准确度“瓶颈”问题,使民歌地域风格分类性能进一步提升。
为达到上述目的,本发明采用如下的技术方案来实现:
一种基于条件随机场的中国民歌地域分类方法,首先对音乐的音频特征进行提取,然后基于条件随机场建立音频特征时序模型,同时结合受限玻尔兹曼机计算其标注序列,使用拟牛顿算法和k次对比散度方法对参数进行学习,最后进行中国民歌的地域分类的实现,具体包括以下步骤:
1)音乐的音频特征提取:包括音频特征的挑选,音乐片段的分帧,音乐音频特征的提取,具体包括以下步骤,
1-1)音频特征的挑选:从音频信号不同变化域的角度进行分析,选择时域特征、频域特征和倒谱域特征作为表征音乐音色与旋律的音频特征;
1-2)音乐片段的分帧:考虑到音乐音频的短时平稳性,将音乐音频m采样成连续的短时段,m={m1,m2,...,mi,...,mn},其中mi称为“帧”,n表示序列长;
1-3)音乐音频特征的提取:以帧为单位,对音乐音频片段m提取1-1)中的相关特征v={v1,v2,...,vi,...,vn},其中vi∈rd表示第i帧的含有d维数据的特征向量;
2)建立音频特征时序模型:考虑各帧音频特征之间的时序关系,通过条件随机场对具有不同地域风格的民歌进行建模;
3)计算音频预测标注序列:基于条件随机场模型的音频预测标注序列计算过程,包括音乐高级特征的学习,标注序列的确定,具体包括以下步骤,
3-1)音乐高级特征的学习:将提取的特征序列v作为受限玻尔兹曼机的输入,采用k次对比散度方法进行网络学习,将隐藏层计算得到的抽象特征作为音乐高级特征,表示为x={x1,x2,...,xi,...,xn},其中xi∈rd表示第i帧的含有d维数据的音乐高级特征向量;
3-2)标注序列的确定:将音乐高级特征向量x作为条件随机场观测序列的观测值,采用受限玻尔兹曼机计算特征函数,进而得到条件随机场标注序列y={y1,y2,...,yi,...,yn},yi表示第i帧高级特征xi对应的地域类别标注;
4)音乐地域分类的实现:根据得到的不同地域风格对应的模型,对歌曲的地域类别进行识别。
本发明进一步的改进在于,所述步骤1-1)中挑选的音频特征包括短时平均过零率(zcr)、频谱质心(sc)、频谱流量(sf)、频谱衰减截止频率(srp)、chroma特征、线性预测倒谱系数(lpcc)和梅尔频率倒谱系数(mfcc),共7种,86维。
本发明进一步的改进在于,所述步骤2)具体操作为:将训练集中一类地域类型民歌中的每首民歌的高级特征序列作为条件随机场的观测序列,采用条件随机场的参数化形式对每一类地域类型的民歌建立模型,同时采用参数求解方法计算代表每一类地域类型民歌的条件随机场模型参数;具体步骤如下:
(i)将训练集中一类地域风格的民歌样本集中任意一首民歌的音频帧特征序列作为条件随机场的观测序列,采用条件随机场模型对每一类地域类型的民歌样本集拟合的概率形式,即
其中,z(x(t))是归一化因子,fk(x(t),y(t))是对所有时刻特征函数
(ii)采用拟牛顿方法中的bfgs算法计算代表每一类地域类型民歌的条件随机场模型参数wk,根据最大似然函数估计法则,参数求解是对数据集满足条件随机场的概率密度函数取对数得到对数似然函数l(w),将l(w)作为优化的目标函数进行不断迭代更新,使得所有歌曲的对数似然函数值达到最大,从而得到模型参数的最优解w*。
本发明进一步的改进在于,所述步骤3-1)采用受限玻尔兹曼机对民歌的音频特征进行建模,通过非线性空间变换将原始输入的特征进行映射,将隐藏层学习到的高级特征序列作为观测序列,有利于增大原始音频特征帧与帧之间的差异性;其中,受限玻尔兹曼机参数的估计根据最大对数似然函数估计法则计算:首先,采用k次对比散度算法预训练网络参数;然后,经k次对比散度算法计算后的参数再次做为网络的初始值,采用反向传播算法微调网络参数;最后,得到网络的最优参数。
本发明进一步的改进在于,所述步骤3-2)具体计算过程如下:首先在受限玻尔兹曼机的隐藏层后添加softmax层,softmax层中每个单元代表了一种地域风格类别的民歌,使其具有判别机制;然后对每个时刻的高级特征进行标注状态判断,状态特征函数的对应维度置1,最终得到歌曲的标注序列;具体步骤如下:
(i)对数据集中的所有音频帧特征建立受限玻尔兹曼机判别模型,即在受限玻尔兹曼机的隐藏层后添加softmax层,softmax层中每个单元代表了一种地域风格类别的民歌,使得受限玻尔兹曼机具有判别机制;
(ii)计算标注序列中任意时刻的地域类别标注的状态时,由公式(2)对该时刻学习到的抽象特征进行标注的状态判断,即状态特征函数sl对应的维度置1;
式中:
(iii)最后得到数据集中第t首歌曲的标注序列。
本发明进一步的改进在于,所述步骤4)具体计算过程如下:首先将歌曲得到的高级特征作为条件随机场的观测序列分别带入到训练好的条件随机场中,然后通过前向-后向算法分别计算预测标注序列由每一个条件随机场产生的后验概率,最后选择后验概率值最大的条件随机场代表的类别作为测试歌曲地域风格类别的预测标准;具体步骤如下:
(i)将每一首测试歌曲得到的高级特征作为条件随机场的观测序列分别带入到已训练好的条件随机场中,通过前向-后向算法分别计算在给定观测序列时,标注序列由每一个条件随机场产生的后验概率;其中,给定的观测序列指由受限玻尔兹曼机计算的观测序列在条件随机场中的预测标注序列;
(ii)选择后验概率值最大的条件随机场代表的类别作为测试歌曲地域风格类别的预测标准,即满足公式(3):
式中:
本发明具有如下有益的技术效果:
本发明提供的一种基于条件随机场的中国民歌地域分类方法,首先对音乐的音频特征进行提取,然后提出采用条件随机场对民歌的帧特征进行建模,其中结合受限玻尔兹曼机计算其标注序列,使用拟牛顿算法和k次对比散度方法对参数进行学习,最后进行音乐地域分类的实现。相较于传统的民歌地域分类方法,该方法采用条件随机场建立帧特征序列之间的时序关系,同时采用受限玻尔兹曼机解决了以往研究计算标注序列的准确度“瓶颈”问题,使民歌地域风格分类性能进一步提升。通过理论分析和实验分析,都证实了本发明在提高中国民歌地域分类问题上的正确率和精确率。
附图说明
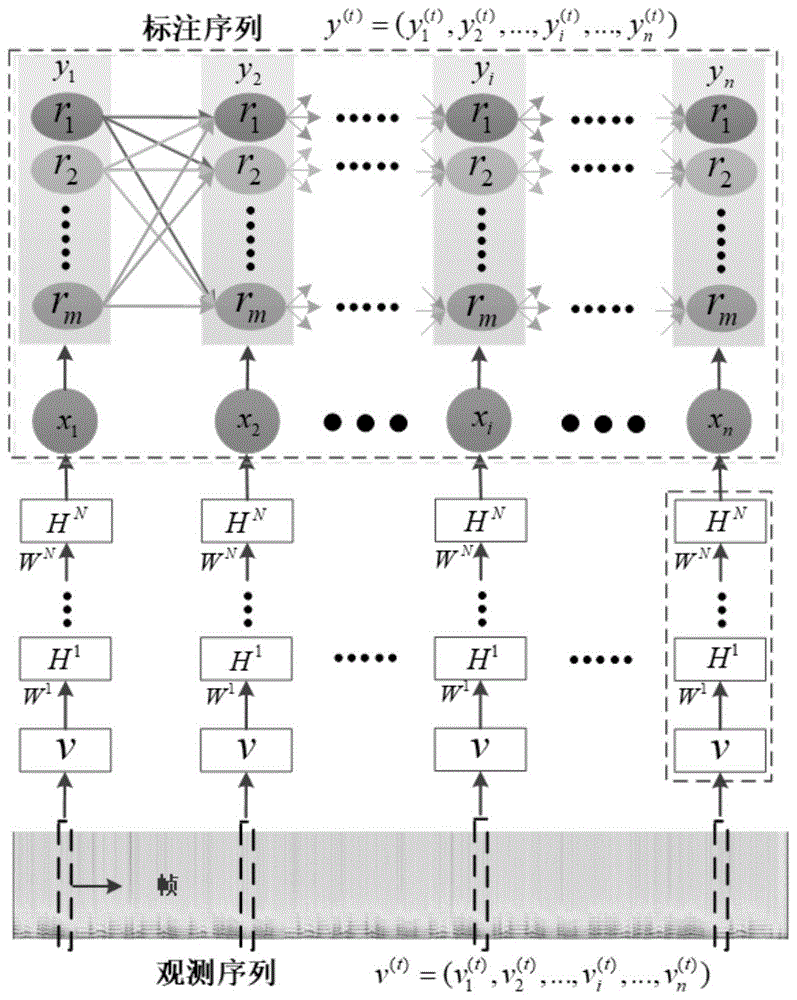
图1为本发明提出的基于条件随机场的地域分类整体模型图。
具体实施方式
下面结合附图对本发明做进一步详细描述。
参照图1,本发明提供的一种基于条件随机场的中国民歌地域分类方法,首先对音乐的音频特征进行提取,然后基于条件随机场建立音频特征时序模型,同时结合受限玻尔兹曼机计算其标注序列,使用拟牛顿算法和k次对比散度方法对参数进行学习,最后进行中国民歌的地域分类的实现,具体包括以下步骤:
1)音乐的音频特征提取:包括音频特征的挑选,音乐片段的分帧,音乐音频特征的提取,具体包括以下步骤:
step1音频特征的挑选:从音频信号不同变化域的角度进行分析,选择时域特征、频域特征和倒谱域特征作为表征音乐音色与旋律的音频特征,具体挑选的特征参照表1;
表1:本发明中挑选的用于表征音乐音色与旋律的音频特征。
其中,挑选的7种音频特征都有助于音乐表示,zcr可以很好表征音乐音色,用于音频信号的端点检测、音高的检测和音调的分割;sc映了音频信号频率的分布;sf反映了相邻两帧的能量频谱的改变量;srp反映能量频谱,是对频谱包络的度量;chroma特征考虑了音乐中和声的存在,减小了噪声和非音调声音的干扰,具有较强的旋律区分与降低误判的能力;lpcc是模拟人发声的模型,mfcc是结合人耳听觉机理而计算的声学特征,可以很好地反映不同地域风格的民歌音色上的差异。
step2音乐片段的分帧:考虑到音乐音频的短时平稳性,将音乐音频m采样成连续的短时段m={m1,m2,…,mi,…,mn},其中mi称为“帧”,n表示序列长;
step3音乐音频特征的提取:以帧为单位,对音乐音频片段m提取相关特征,v={v1,v2,…,vi,…,vn}其中vi∈rd表示第i帧的含有d维数据的特征向量。
2)建立音频特征时序模型:考虑各帧音频特征之间的时序关系,通过条件随机场对具有不同地域风格的民歌进行建模。关键步骤描述如下:
(i)将训练集中一类地域风格的民歌样本集中任意一首民歌的音频帧特征序列作为条件随机场的观测序列,采用条件随机场模型对每一类地域类型的民歌样本集拟合的概率形式,即
其中,z(x(t))是归一化因子,fk(x(t),y(t))是对所有时刻特征函数
(ii)采用拟牛顿方法中的bfgs算法计算代表每一类地域类型民歌的条件随机场模型参数wk,根据最大似然函数估计法则,参数求解是对数据集满足条件随机场的概率密度函数取对数得到对数似然函数l(w),将l(w)作为优化的目标函数进行不断迭代更新,使得所有歌曲的对数似然函数值达到最大,从而得到模型参数的最优解w*。
3)计算音频预测标注序列:基于条件随机场模型的音频预测标注序列计算过程,包括音乐高级特征的学习,标注序列的确定,具体包括以下步骤:
step1音乐高级特征的学习:参照图1的虚线框表示受限玻尔兹曼机结构,包含一个可见层v和若干个隐藏层hn。将提取的特征序列v作为受限玻尔兹曼机的输入,采用k次对比散度方法进行网络学习,将隐藏层计算得到的抽象特征作为音乐高级特征,表示为x={x1,x2,...,xi,...,xn},其中xi∈rd表示第i帧的含有d维数据的音乐高级特征向量;
step2标注序列的确定:将音乐高级特征向量x作为条件随机场观测序列的观测值,采用受限玻尔兹曼机计算特征函数,进而得到条件随机场标注序列y={y1,y2,...,yi,...,yn},yi表示第i帧高级特征xi对应的地域类别标注。关键步骤描述如下:
(i)对数据集中的所有音频帧特征建立受限玻尔兹曼机判别模型,即在受限玻尔兹曼机的隐藏层后添加softmax层,softmax层中每个单元代表了一种地域风格类别的民歌,使得受限玻尔兹曼机具有判别机制;
(ii)计算标注序列中任意时刻的地域类别标注的状态时,由公式(2)对该时刻学习到的抽象特征进行标注的状态判断,即状态特征函数sl对应的维度置1;
式中:
(iii)最后得到数据集中第t首歌曲的标注序列。
4)音乐地域分类的实现:根据得到的不同地域风格对应的模型,对歌曲的地域类别进行识别。具体计算过程如下:首先将歌曲得到的高级特征作为条件随机场的观测序列分别带入到训练好的条件随机场中,然后通过前向-后向算法分别计算预测标注序列由每一个条件随机场产生的后验概率,最后选择后验概率值最大的条件随机场代表的类别作为测试歌曲地域风格类别的预测标准。具体步骤如下:
(i)将每一首测试歌曲得到的高级特征作为条件随机场的观测序列分别带入到已训练好的条件随机场中,通过前向-后向算法分别计算在给定观测序列时,标注序列由每一个条件随机场产生的后验概率;其中,给定的观测序列指由受限玻尔兹曼机计算的观测序列在条件随机场中的预测标注序列;
(ii)选择后验概率值最大的条件随机场代表的类别作为测试歌曲地域风格类别的预测标准,即满足公式(3):
式中:
参照表2,从对陕西民歌、江苏民歌和湖南民歌分类的混淆矩阵实验结果可以看出,本发明提供的一种基于条件随机场的中国民歌地域分类方法取得了比较好的分类结果。
表2:本发明提出的分类方法准确率的比较,采用分类混淆矩阵进行评价。
参照表3,本发明采用条件随机场对音乐的时序结构进行编码的中国民歌地域分类准确率高于优于已有民歌分类方法。
表3:中不同民歌地域风格分类算法的准确率对比。
- 还没有人留言评论。精彩留言会获得点赞!