一种语音对抗样本生成方法与流程
本发明属于深度学习安全领域中的对抗样本生成算法,特别是一种语音对抗样本生成方法。
背景技术:
近年来,随着深度神经网络的发展,深度学习已经逐渐应用到各个领域,尤其在计算机视觉、语音识别、自然语言处理等方面已经达到甚至超过人类的能力。与此同时,深度学习带来的安全问题也越来越受到人们的关注。其中,对抗样本的生成方法逐渐成为深度学习技术安全领域中的热点问题。对抗样本是指在深度神经网络模型可以做出正确判断的原始数据上,增加人类感官难以分辨的微小扰动后,深度神经网络模型会做出错误判断的样本。语音识别技术得到了重大的突破。深度神经网络以其深层次和非线性的网络结构,在语音信息特征提取和语音声学建模等方面表现突出。2009年,hinton采用深度置信网络(dbn)来代替gmm,首次提出dbn-hmm模型,该模型在timit数据集上,实现了23.3%的词错误率。2013年,随着循环神经网络(rnn)的发展,大量的研究将rnn应用到语音识别系统中,其中包括百度团队提出的deepspeech语音识别系统等。目前绝大部分语音识别系统均采用深度神经网络技术。然而由于深度神经网络的高度复杂性,其在数学上并没有得到严格的解释。此外一般来说深度神经网络系统往往需要大量的数据进行训练、测试和验证,因此其在算法、训练集、测试集和验证集等多个方面都容易受到外界的攻击。2014年christianszegedy等人提出深度神经网络易受外界攻击的特性,并首次提出对抗样本的概念。对抗样本是指在深度神经网络模型可以做出正确判断的源数据上,增加一些人类感官难以分辨的微小改变后,深度神经网络模型会做出错误判断的样本。
自从christianszegedy等人提出深度神经网络易受外界攻击的特性后,众多学者对神经网络的攻击产生浓厚的兴趣,大量的对抗样本生成方法被人们提出。目前主流的对抗样本生成方法如下所述:
l-bfgs:由christianszegedy最初提出,采用纯粹的数学上的方法,求解让深度神经网络做出误判断的方程。但由于问题的复杂度太高,随后他们将问题进行简化,寻找最小的函数损失项,将问题转化为凸优化问题。该算法可适用于任何网络结构和模型,但是该算法的本质是基于牛顿迭代法进行优化的求解方法,求解过程中需要大量的线性迭代,计算量过于庞大。
fgsm:由“gans之父”goodfellow提出,目前为对抗样本在图像处理领域应用最为广泛的算法之一。goodfellow指出深度神经网络模型产生对抗样本的一个重要原因是其结构在高维上的线性性质,因此让输入朝着类别置信度低的方向移动,神经网络模型就会产生错位的分类。同时他指出若误差的变化方向与损失函数的梯度方向一致,则该误差将会对分类造成最大的影响。但是在非线性程度较高的语音识别系统中,该算法生成对抗样本的成功率较低。
deepfool:基于迭代方法的白盒攻击,goodfellow证实通过fgsm算法是一种有效的对抗样本生成方法,然而并未指出当误差为多大时,fgsm算法才会生效。deepfool算法通过对分类的边缘区增加一个极小误差作为开始,在每次迭代中,不断修改误差的大小和方向,直到图像被推入分类的另一侧,即分类器做出错误的判断。实验证明,在相同的攻击效果下,相对于fgsm算法,deepfool算法生成的对抗样本误差更小,并且由于误差系数迭代更新,解决了fgsm中根据经验人工选取误差系数的问题。但是deepfool算法的前提仍是攻击的系统模型具有一定的线性性质,因此在非线性程度较高的语音识别系统中表现不佳。
jsma:之前的攻击都是通过对所有的输入数据增加扰动来实现,jsma可以实现只改变个别输入值,从而达到较好的攻击效果,其原理为在深度神经网络的前向传播的过程中,计算模型的前向导数,根据前向导数来输入图像中每个像素的重要程度。重要程度越高表示该像素的改变对整幅图像的影响最大。最后根据重要程度进行排序,选出对图像影响较大的一些点进行fgsm攻击,就能实现利用较少的像素点实现对抗攻击。实验表明jsma可以只修改4.02%的输入数据,而可以达到97%攻击成功率。jsma相对于fgsm算法,扰动的大小控制较弱,但整体失真的控制较好。然而在语音识别系统中,个别输入值的剧烈变化会产生短暂的刺耳的噪声,使得语音对抗样本与真实样本易于分辨。
houdini:nips2017最佳论文中提出的一种用于欺骗基于梯度的机器学习算法的方法。该算法通过深度神经网络的可微损失函数的梯度信息来生成对抗样本的扰动值。该算法提出一个恒定可微的损失函数,解决了组合不可分解的问题,除了在图像分类领域以外,在语音识别、姿态评估、语音分割、黑盒攻击等领域都取得了良好的攻击效果。其中在语音识别领域,houdini算法在最大误差不超过输入1%的前提下,语音对抗样本可实现66.5%的词错误率,然而在很多情况下,1%的误差仍然可以使人们正确区分语音对抗样本与真实样本。
遗传算法:针对语音识别系统的有目标攻击方法,该算法分两个阶段进行攻击,第一阶段通过遗传算法,对候选样本总体进行迭代,直到一个合适的样本产生。第二阶段采用梯度估计的方法,当对抗样本接近给定标签值时,允许设置更微小的扰动。该方法可实现在进行5000次迭代之后,对抗样本与真实样本的相关系数可达到0.894,词错误率可达到87.4%,然而该算法生成的语音对抗样本中包含大量噪声,易被人们辨别。
技术实现要素:
本发明针对基于循环神经网络模型结构的deepspeech语音识别系统进行研究,提出一种有目标的语音对抗样本生成算法,该算法解决了对抗样本易被人类辨别的问题,可在人类无法正确辨别生成的对抗样本与真实样本的情况下,实现对抗样本可被deepspeech语音识别系统识别为任意的给定短语。
本发明是通过下述技术方案来实现的。
一种语音对抗样本生成方法,包括以下步骤:
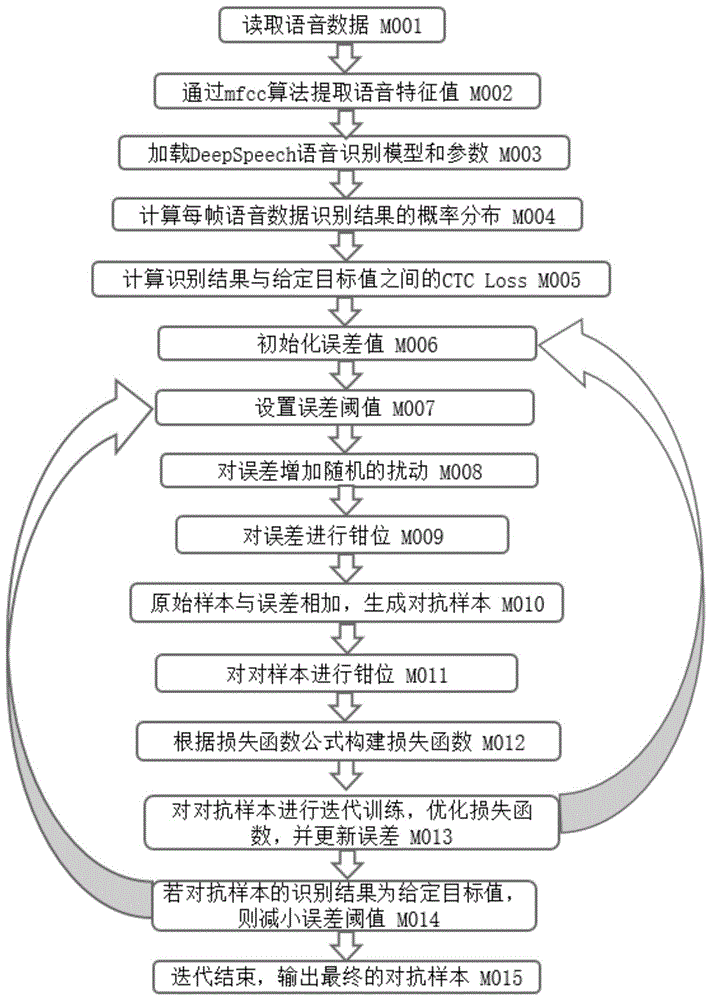
步骤1,读取输入的语音数据,并对输入的语音数据进行预处理操作,提取输入语音数据的语音特征值;
步骤2,加载deepspeech语音识别系统的深度神经网络模型和参数,同时将提取的语音特征值输入到deepspeech语音系统中,计算每帧输入语音数据识别结果的概率分布,并根据该概率分布计算识别结果与给定目标值之间的ctcloss;
步骤3,初始化误差值和误差阈值,并对误差值以及生成的对抗样本进行钳位操作;
步骤4,构建语音对抗样本生成算法的损失函数,并采用神经网络训练中的优化器进行多次迭代,以此来减小该损失函数,并对误差值进行更新;
步骤5,在迭代过程中,若生成的对抗样本的识别结果为给定的目标值,则减小误差阈值进行阈值误差更新,继续进行迭代,直至迭代结束;迭代结束后,输出最终的对抗样本结果。
步骤1中,读取语音数据的方式采用scipy库中的scipy.io.wavfile模块,在python以数组的形式表示;提取输入语音数据的语音特征值采用mfcc算法,通过调用deepspeech语音识别系统的mfcc模块实现。
步骤2中,计算输入语音数据的识别结果与给定目标值之间的ctcloss采用tensorflow平台中的tensorflow.nn.ctc_loss()函数;其中设置该函数中的标签序列时,根据给定目标值中的字母在26个字母中的位置,将字母字符转换为数字,计数从1开始,即字母‘a’对应1,字母‘z’对应26。
步骤3进一步包括子步骤:
3.1初始化误差值;
3.2设置误差阈值;
3.3对误差增加随机的扰动,深度神经网络训练过程的技巧,增加一个较小的扰动可以加速损失函数的收敛,同时可增加模型的泛化能力;
3.4根据误差阈值对误差进行钳位操作,钳位操作采用的是tensorflow中的clip_by_value函数,该函数使小于误差阈值下限的值等于误差阈值下限,大于误差阈值上限的等于误差阈值上限,其目的是防止产生过大的误差;
3.5将误差值与原始样本相加生成对抗样本;
3.6对生成的对抗样本进行钳位操作,同样采用tensorflow中的clip_by_value函数,防止数据溢出。
步骤4进一步包括子步骤:
4.1构建损失函数时,在ctcloss损失函数的基础上,增加对误差的无穷范数,用公式表达如下:
其中ε为误差,f为ctc损失函数,x+ε为对抗样本,t为常数;
若所有的误差值均小于t时,减小t的值,当存在误差值大于t时,保持t的值不变;不断重复此过程,直至最后收敛,(εi-t)+的函数表达式为:max(εi-t,0),c为ctc损失函数权重系数;
4.2优化方法采用adam算法,具体实现采用tensorflow平台中的tensorflow.train.adamoptimizer()函数。
步骤5中,更新误差阈值的方法为在原阈值的基础上乘以固定系数。
本发明由于采取以上技术方案,其具有以下有益效果:
本发明提出通过构建基于ctcloss的损失函数,并采用深度神经网络训练中的优化算法,在规定的误差范围内对误差值进行调整,不断降低此损失函数,而此损失函数越低,代表对抗样本在语音识别系统的识别结果与我们给定的目标短句越接近,即对抗样本在语音识别系统为给定的目标短句得概率越大。同时若找到合适的误差值,使得语音对抗样本的识别结果为给定的目标短句,则缩小规定的误差范围,在更小的范围内寻找合适的误差值。同时,由于损失函数在本论文对抗样本生成算法中有着至关重要的作用,因此损失函数的选择对算法的性能有着重要的影响。
本发明采用神经网络训练的方法,通过多次迭代不断调整对抗样本与原始样本之间的误差值,减小语音识别系统识别结果与给定目标值的ctcloss,从而生成对抗样本。同时,为了得到更小的误差值,在ctcloss的基础上增加对误差的无穷范数的约束。经实验验证,本算法生成的对抗样本可在deepspeech语音识别系统的识别结果为给定的任意短句(识别速度上限为每秒50个字符),与其他语音对抗样本生成算法相比,在对抗样本识别结果与真实标签词错误率相同的情况下,本算法生成的对抗样本与原始样本的相似度更高。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,并不构成对本发明的不当限定,在附图中:
图1为整体算法流程图;
图2为本发明算法与houdini算法对比;
图3为本发明算法与遗传算法对比。
具体实施方式
下面将结合附图以及具体实施例来详细说明本发明,在此本发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
本算法整体实现流程如图1所示,包括以下步骤:
1)读取输入的语音数据,并对输入的语音数据进行预处理操作,提取输入语音数据的语音特征值。其中输入的语音数据格式为.wav,采样频率为16khz,数值精度为16比特有符号数,即语音数据的值为[-215,215-1],读取方式采用scipy库中的scipy.io.wavfile模块,在python以数组的形式表示,提取输入语音数据的语音特征值采用mfcc算法,通过调用deepspeech语音识别系统的mfcc模块实现。
2)加载deepspeech语音识别系统的深度神经网络模型和参数,同时将提取的语音特征值输入到deepspeech语音系统中,计算每帧输入语音数据识别结果的概率分布,并根据该概率分布计算识别结果与给定目标值之间的ctcloss。其中计算输入语音数据的识别结果与给定目标值之间的ctcloss采用tensorflow平台中的tensorflow.nn.ctc_loss()函数。其中设置该函数中的标签序列时,根据给定目标值中的字母在26个字母中的位置,将字母字符转换为数字,计数从1开始,即字母‘a’对应1,字母‘z’对应26。
3)初始化误差值和误差阈值,并对误差值以及生成的对抗样本进行钳位操作,包括以下步骤:
1)初始化误差值;
2)设置误差阈值;
3)对误差增加随机的扰动,深度神经网络训练过程的技巧,增加一个较小的扰动可以加速损失函数的收敛,同时可增加模型的泛化能力;
4)根据误差阈值对误差进行钳位操作,钳位操作采用的是tensorflow中的clip_by_value函数,该函数使小于误差阈值下限的值等于误差阈值下限,大于误差阈值上限的等于误差阈值上限,其目的是防止产生过大的误差;
5)将误差值与原始样本相加生成对抗样本;
6)对生成的对抗样本进行钳位操作,同样采用tensorflow中的clip_by_value函数,防止数据溢出。
4)构建语音对抗样本生成算法的损失函数,并采用神经网络训练中的优化器进行多次迭代,以此来减小该损失函数,并对误差值进行更新,包括以下步骤:
1)构建损失函数时,在ctcloss损失函数的基础上,增加对误差的无穷范数,用公式表达如下:
其中ε为误差,f为ctc损失函数,x+ε为对抗样本,t为常数;
若所有的误差值均小于t时,减小t的值,当存在误差值大于t时,保持t的值不变;不断重复此过程,直至最后收敛,,(εi-t)+的函数表达式为:max(εi-t,0),c为ctc损失函数权重系数;
2)优化方法采用adam算法,具体实现采用tensorflow平台中的tensorflow.train.adamoptimizer()函数。
5)在迭代过程中,若生成的对抗样本的识别结果为给定的目标值,则减小误差阈值进行阈值误差更新,减小误差阈值的方法为在原阈值的基础上乘以0.8。继续进行迭代,直至迭代结束。迭代结束后,输出最终的对抗样本结果。
本发明对ctc损失函数的权重进行了分析,当权重系数c越大时,损失函数在目标函数的权重越大,生成的对抗样本的成功率越高,但同时误差也会相对较大。经过实验验证,在损失函数上增加误差的无穷范数约束时,损失函数权重系数c取90,可实现生成对抗样本成功率为100%,且误差值最小。
将本发明算法与其他算法进行对比时,对抗样本与原始样本之间的相似度采用最大误差值和互相关系数作为评价标准,输入语音数据的真实标签值与对抗样本识别值的距离采用词错误率作为评价标准。如图2和图3所示,与houdini算法对比时,在输入语音数据的真实标签值与对抗样本识别值的词错误率相同的情况下,本发明算法生成的语音对抗样本与原始样本的最大误差值更小;与遗传算法算法对比时,在输入语音数据的真实标签值与对抗样本识别值的词错误率相同的情况下,本发明算法生成的语音对抗样本与原始样本的相关系数更高,即在输入语音数据的真实标签值与对抗样本识别值的词错误率相同的情况下,本发明生成的对抗样本与原始样本的相似度更高。
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!