一种语音信号的端点识别方法和装置与流程
本发明涉及信号处理技术领域,尤其是一种语音信号的端点识别方法和装置。
背景技术:
语音交流是人类之间最常见也是最重要的一种信息交换方式,随着数字通信技术的发展,人和人之间通过数字通信系统而不是面对面进行语音沟通正在成为一种普遍的生活方式。语音信号在数字通信系统的传输过程中,包含了大量被嵌入语音中的停顿,例如,当一个人在说话而另一个人在聆听时,有效话音段时间大约占整个通话期间的50%左右。如果能正确的找出有效语音话音段,使得在对话语音的语音编码系统中可以使用非连续发送(dtx)或者在语音编码中减低噪声和静音段的比特率来增加编码的效率,可以显著提升传输效率。
目前现有技术中,一般抽取语音信号时-频域的特征参数,然后对其进行分类判断以完成语音信号端点检测的任务。语音信号的时域特征参数包括短时平均能量、短时平均幅度和短时平均过零率,而其时-频域特征参数包括倒谱系数、周期率测度和分形维数等;语音信号的端点判断方式由原来的单门限和双门限发展到基于模糊逻辑和模式分类的判断。
技术实现要素:
本发明实施例旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明实施例的一个目的是提供一种语音信号的端点识别方法和装置。
本发明所采用的技术方案是:
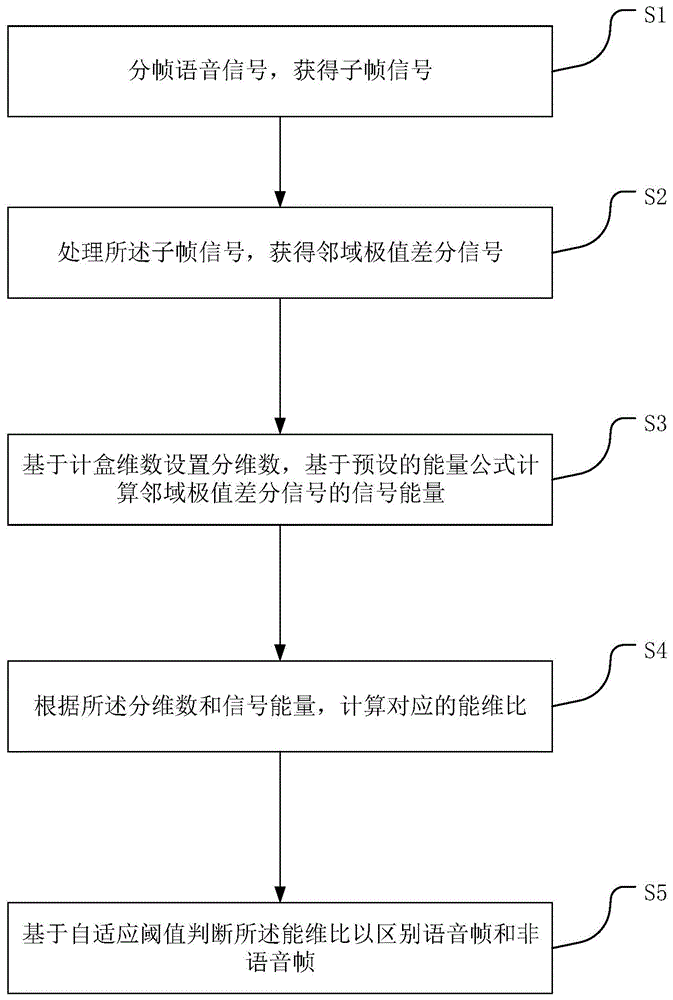
第一方面,本发明实施例提供一种语音信号的端点识别方法,包括:分帧语音信号,获得子帧信号;处理所述子帧信号,获得邻域极值差分信号;基于计盒维数设置分维数,基于预设的能量公式计算邻域极值差分信号的信号能量;根据所述分维数和信号能量,计算对应的能维比;基于自适应阈值判断所述能维比以区别语音帧和非语音帧。
优选地,还包括:根据预设帧阈值判断所述非语音帧以重新确定其是否属于语音帧。
优选地,所述获得邻域极值差分信号包括:根据临域尺寸确定待处理信号点的邻域,根据加权值和临域计算临域值;等值扩展所述待处理信号点,得到待处理信号点的基准值;所述临域值与所述基准值的差值的最大值的集合为邻域极值差分信号。
优选地,设置分维数d包括:最小二乘拟合logn(s)和log(1/s)得到分维数
优选地,所述基于自适应阈值检测子帧信号包括:
初始阈值为
后续第i帧的判断阈值
基于θi+1=λθ×θi+(1-λθ)×θi+1对阈值进行平滑处理,其中,θi表示判断阈值,λ为滤波系数,edri表示得分值,当edri>θi时,对应的帧为语音帧,否则为非语音帧。
第二方面,本发明实施例提供一种语音信号的端点识别装置,包括:分配模块,用于分帧语音信号,获得子帧信号;邻域处理模块,用于处理所述子帧信号,获得邻域极值差分信号;预处理模块,用于基于计盒维数设置分维数,基于预设的能量公式计算邻域极值差分信号的信号能量;能维比模块,用于根据所述分维数和信号能量,计算对应的能维比;判断模块,用于基于自适应阈值判断所述能维比以区别语音帧和非语音帧。
优选地,还包括:误判防止模块,用于根据预设帧阈值判断所述非语音帧以重新确定其是否属于语音帧。
优选地,所述获得邻域极值差分信号包括:根据临域尺寸确定待处理信号点的邻域,根据加权值和临域计算临域值;等值扩展所述待处理信号点,得到待处理信号点的基准值;所述临域值与所述基准值的差值的最大值的集合为邻域极值差分信号。
优选地,设置分维数d包括:最小二乘拟合logn(s)和log(1/s)得到分维数
优选地,所述基于自适应阈值检测子帧信号包括:
初始阈值为
后续第i帧的判断阈值
基于θi+1=λθ×θi+(1-λθ)×θi+1对阈值进行平滑处理,其中,θi表示判断阈值,λ为滤波系数,edri表示得分值,当edri>θi时,对应的帧为语音帧,否则为非语音帧。
本发明实施例的有益效果是:
本发明实施例通过分帧语音信号,获得子帧信号;处理子帧信号,获得邻域极值差分信号;基于计盒维数设置分维数,基于预设的能量公式计算邻域极值差分信号的信号能量;根据分维数和信号能量,计算对应的能维比;基于自适应阈值判断能维比以区别语音帧和非语音帧,能够为后续的编码提供指示,提高传输效率。
附图说明
图1是语音信号的端点识别方法的一种实施例的流程图;
图2是语音信号的端点识别装置的一种实施例的连接图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
分形是混沌信号描述的其中一个方法,语音实质上属于混沌的自然现象,其能对信号的精细度与规则性进行度量,对信噪比相对较低的环境具有适用性,同时分形维数受信号能量强度与信噪比的干扰偏低,其阈值的稳定性较高。在语音中的有话区间能量是向上凸起的,而分形维数相反,在有话区间是向下凹陷。这表明,有话区间能量的数值大,而分形维数值小;在噪声区间能量的数值小,而分形维数数值大,所以把能量值除以分形维数值,则可以更突出有话区间的数值,噪声区间的数值变得更小,拉开了有话区间和噪声区间的数值差距,更容易检测出语音的端点。
实施例1。
本实施例提供如图1所示的语音信号的端点识别方法,包括:
s1、分帧语音信号,获得子帧信号;
s2、处理所述子帧信号,获得邻域极值差分信号;
s3、基于计盒维数设置分维数,基于预设的能量公式计算邻域极值差分信号的信号能量;
s4、根据所述分维数和信号能量,计算对应的能维比;
s5、基于自适应阈值判断所述能维比以区别语音帧和非语音帧。
其中,具体的语音信号的端点识别流程包括:
第一步,执行分帧:
设置分帧的规格,具体可以是帧长20ms,帧移为0.5倍数的帧长。
第二步,邻域差分计算:
含噪语音信号可以表示为fn(x),一般而言其邻近信号之间具有较高的关联度。设fn(x)在信号点n0处(n个信号点范围内,即邻域尺寸)的邻域信号
设置一个n邻域差分加权模块,集合
在本实施例中,取帧长franlen=160,邻域范围n取81样点,则对应样点的下标m=(n-1)/2=40。对于每帧信号,取第franlen/4+1样点到3franlen/4样点范围内,对应的邻域极值差分信号f(x),其长度为franlen/4。
第三步,设置分维数:
分维的定义有多种,如相似性维数、容量维数、haudorff维数、信息维数、计盒维数等。本实施例利用计盒维数的定义求取分维数d。
设有集合a,用一个网状栅格将其覆盖,网格边长维s,n(s)为网格中含有集合a任意一部分的网格数,则计盒维数为:
本实施例采用最小二乘拟合logn(s)~log(1/s)直线,求出此直线的斜率即为计盒维数d。具体实现过程为:
移位操作,将最小值点移动到坐标0点,fshift(x)=f(x)-fmin。
通过一维线性插值将信号fshift(x)扩展长度为cellmax+1,得到插值后的信号finterp(x),其中cellmax为网格的最大边长,可以取2的偶数次幂次(1,2,4,8...),取大于数据长度的偶数。
按比例缩放信号finterp(x),使其最大值为cellmax,即将原始语音信号归一化到单位正方形区域,得到归一化信号fnormal(x),
将正方形区域划分为边长为s的网格,计算出logn(s),logn(1/s)。
改变s的大小,计算相应的logn(s),logn(1/s)。
令xi=log(1/si),yi=logn(si),i=1,2,...,m,利用(xi,yi)最小二乘拟合直线y=kx+b,k为计盒维数d,其中
第四步,计算邻域极值差分信号的信号能量:
计算邻域极值差分信号f(x)的能量,能量公式:
第五步,计算能维比:
按照上述步骤得到的能量的计算值和分维数就能估计出邻域极值差分信号f(x)的能维比
第六步,自适应阈值判断:
装置采用动态自适应阈值法检测语音段,默认开始的前10帧为静音段,初始阈值为:
后续第i帧的阈值:
本方法采用θi+1=λθ×θi+(1-λθ)×θi+1对阈值进行平滑。设t0和t1分别表示非语音和语音,λ为滤波系数,θi表示判断阈值,edri表示得分值,那么当edri>θi时,其对应的帧为语音帧,否则为非语音帧。判断公式为:t0:edri≤θi,t1:edri>θi。
第七步,延迟保护
基于语音相关性的基础,把输入的带噪语音分为三种状态,即语音状态、噪声状态及语音和噪声之间的转换状态,并为语音状态转换为噪声状态以及噪声状态转换为语音状态分别设置了不同的延迟保护长度,其目的在于保持一次语音的连续性,防止出现由于误判帧属于非语音帧,导致信息得不到合理的编码,出现不清晰的情况。
如果当前帧的初步判断结果在保护长度之内,则判定当前帧为转换状态,而初步判断结果作为累计值保存起来;如果当前帧的初步判断结果超出了保护长度的范围,则判定当前帧为新的语音状态或噪声状态。即根据预设帧阈值判断所述非语音帧以重新确定其是否属于语音帧;例如,连续10帧判断属于语音帧,然后出现5帧判断属于非语音帧,而预设帧阈值为1帧,则后续的5帧非语音帧中,第一帧属于保护长度的范围,则重新确定该非语音帧为语音帧。
实施例2。
本实施例提供如图2所示的一种语音信号的端点识别装置,包括:
分配模块1,用于分帧语音信号,获得子帧信号;
邻域处理模块2,用于处理所述子帧信号,获得邻域极值差分信号;
预处理模块3,用于基于计盒维数设置分维数,基于预设的能量公式计算邻域极值差分信号的信号能量;
能维比模块4,用于根据所述分维数和信号能量,计算对应的能维比;
判断模块5,用于基于自适应阈值判断所述能维比以区别语音帧和非语音帧。
误判防止模块,用于根据预设帧阈值判断所述非语音帧以重新确定其是否属于语音帧。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!