一种用于分布式无线声传感器网络的语音增强系统的制作方法
本发明涉及语音信号处理技术领域,尤其涉及一种用于分布式无线声传感器网络的语音增强系统。
背景技术:
在实际应用中,音频处理设备接收的音频信号经常受到各种噪声的干扰。干扰噪声会使设备性能下降,严重情况下,设备甚至无法正常工作。为了克服噪声的影响,人们提出了语音增强技术。由于基于单个麦克风的语音增强方法性能有限,可以利用空间信息的麦克风阵列语音增强方法获得重视。但是麦克风阵列也暴露了需要知道阵列几何信息,要有固定且规则的阵列结构等一些局限性。随着无线传感器技术的飞速发展,无线声传感器网络(wasn)的应用越来越广泛,如在会议室利用智能手机或笔记本电脑通过wifi(或蓝牙)和音频接口构建出一个wasn。当wasn没有数据融合中心时,可以利用声传感器的无线通信功能进行数据传输实现语音增强。
现有技术中:zeng等在文献[1]研究了分布式语音增强gossip算法的使用,提出一种分布式延迟求和波束形成语音增强技术。该波束形成是在任意连接的wasn下,通过每个麦克风与其相邻的麦克风通信达到估计期望信号的目的。此技术通过异步更新数据和分布式求平均两种方法同时更新每个麦克风的数据,从而提高wasn分布式语音增强的性能。但是该方案的缺陷是由于只注重了分布式算法的实现,致使最终的结果虽然达到了全局最优解,但是该算法中的噪声功率谱密度(npsd)估计利用的是频域已有算法,保证性能的前提下估计成本较高,当噪声环境恶劣时,估计准确率降低。npsd的估计误差越大使输出结果的性能下降越多。
现有技术中:sherson等在文献[2]提出了一种分布式最小方差算法,该算法不需要每个节点分享原始数据,在循环和非循环网络中都可以计算出最优波束形成的输出结果。npsd由时变噪声场的协方差矩阵的低秩结构估计得到。该算法数据整体传输数量要比集中式算法少。在循环网络的任意拓扑结构下该算法的性能促进了最佳声学波束形成的使用。但是该方法的缺陷是:在快速变化的噪声场中,需要按块计算波束形成输出。在非循环网络中,分布式最小方差算法传输数据量相对较高。
现有技术中:xiao等在文献[3]为了使npsd估计更加精确从而提高现有波束形成最小方差无失真响应(mvdr)算法的鲁棒性,在阵列信号波束形成模型中提出了基于估计对角加载的mvdr算法。建立了基于用拉格朗日乘子求对角线加载补偿值的mvdr优化模型,并在矩阵理论的基础上推导出对角线加载补偿值的区间。通过实验方法也确定了区间中的最优对角加载值,并在稳定性和抑制干扰加性噪声方面有了一定提高。该算法是在均匀线性阵列模型中研究的mvdr波束形成,应用在分布式算法中不具有低复杂度特性。
技术实现要素:
根据现有技术存在的问题,本发明公开了一种用于分布式无线声传感器网络的语音增强系统,具体包括:
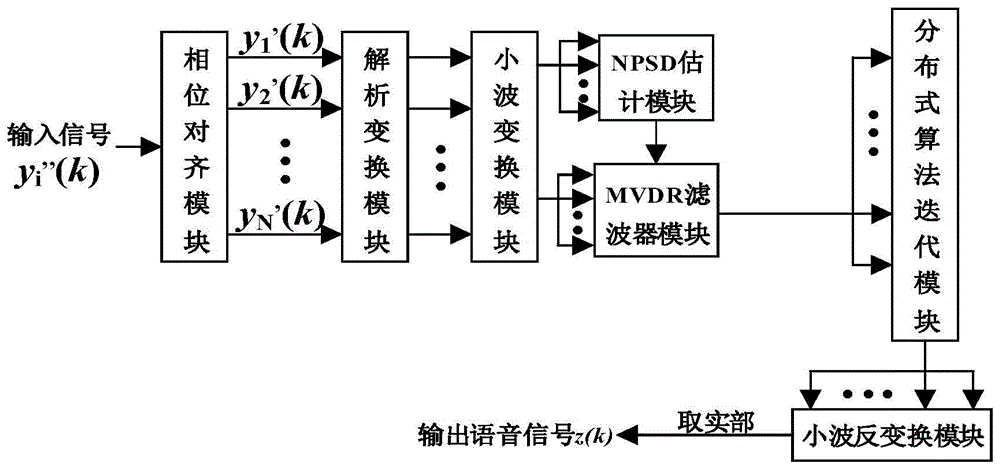
相位对齐模块、将先后接收到的语音信号yi”(k)进行相位平移形成同一时刻语音信号yi'(k);
接收所述相位对齐模块传送的语音信号yi'(k)对该信号进行分帧加窗处理得到信号yi(k)的解析变换模块,所述解析变换模块对每一帧信号yi(k)进行解析变换、输出信号yi;
接收解析变换模块输出的信号yi的小波变换模块,所述小波变换模块采用四层小波分解方式对信号yi进行滤波和降采样处理得到解析的离散小波域信号y;
接收所述小波变换模块输出的含有四层分解的信号y的npsd估计模块,所述npsd估计模块利用每一层数据中的阈值对语音信号的噪声功率谱密度分别进行估计、输出每一层的噪声功率谱密度;
接收所述npsd估计模块传送的噪声功率谱密度信息、以及小波变换模块传送的离散小波域信号y的mvdr滤波器模块,所述mvdr滤波器模块根据接收到的数据信息构建mvdr准则下的滤波器系数w、将该滤波器系数w与离散小波域信号y组合成滤波信号why;
分布式算法迭代模块,将mvdr滤波器模块输出的滤波信号why处理为求平均值的形式、通过初始状态值根据metropolis权矩阵多次迭代求得初始状态值的平均值得到输出信号z;
小波反变换模块:将分布式算法迭代模块传送的输出信号z进行小波反变换、再取实部得到增强后的时域输出语音信号。
进一步的,所述npsd估计模块对语音信号的每层的噪声功率谱密度进行估计时采用如下方式:
设定每次分解时的阈值,其中阈值表达式如下
其中,j代表小波分解中的第j层,tj是第j层小波系数的阈值,nj是第j层小波系数的个数,σj的表达式如下
其中,median(|dj|)是第j层小波系数的中位数,采用如下公式估计语音信号的每层噪声功率谱密度,当前帧的噪声功率谱密度估计值均由上一帧的噪声功率谱密度估计值和当前帧的阈值更新得到,
其中,l是当前帧数,
由于采用了上述技术方案,本发明提供的一种用于分布式无线声传感器网络的语音增强系统,采用该系统首先将每个节点的输入信号要和距离声源最远的那个节点相位对齐,对齐之后的每一路信号分别进行解析小波变换;然后,在小波域中估计npsd,同时得到mvdr滤波系数;最终通过分布式算法迭代模块得到每个节点麦克风的输出信号,对输出信号进行小波反变换并取实部获得时域信号。该系统的实现是由每个麦克风和其附近麦克风通过交换特定数据,使得所有麦克风的初始状态值经过迭代收敛到全局平均值完成的。其中,在设置迭代次数足够的情况下,每个麦克风的输出信号是相同的,均得到输出信号的方差最小,并达到全局最优解的效果。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明系统的工作原理图;
图2为本发明无线声传感器网络示意图;
图3为本发明四层小波分解图示意图;
图4为本发明分布式语音增强前每个麦克风输入信号的snr示意图;
图5为本发明分布式语音增强前每个麦克风输入信号的pesq示意图;
图6为本发明分布式语音增强后每个麦克风输出信号的snr和pesq示意图;
具体实施方式
为使本发明的技术方案和优点更加清楚,下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚完整的描述:
如图1所示的一种用于分布式无线声传感器网络的语音增强系统,具体包括:相位对齐模块、解析变换模块、小波变换模块、npsd估计模块、mvdr滤波器模块、分布式算法迭代模块和小波反变换模块。
其中实际的无线声传感器网络wasn如图2所示,麦克风和声源的位置随机分布。麦克风之间的通信受到距离的限制,只能和附近的麦克风进行通信。
所述相位对齐模块在无线声传感器网络wasn中,在距声源某个已知距离为l的位置放一个参考麦克风,利用该麦克风接收到的信号能量与其它麦克风接收的信号能量可以估计出其它麦克风到声源的距离li。距离估计公式如下:
其中,e和ei分别是参考信号和其它麦克风信号的能量,ε和εi是背景噪声的能量,能量公式如下:
其中,len是信号的总长度,fs是采样频率,即一秒信号对应的点数。该公式利用语音第一秒大部分是无语音段的特点,估计背景噪声的能量。定义max{li}对应节点为参考输入信号y”a(k),每一路待对齐信号为y”b(k),且y”b(k)循环通过一个单位延迟器的同时,与y”a(k)做互相关运算,表达式如下:
rab(τ)=e[y”a(k)y”b(k-τ)],τ=0,1,...,t(3)
其中,t是平移最大量,可适当选取。当τ的取值使以上两路信号对齐时,互相关函数值最大。令
根据无线声传感器网络连接图可依次将各路信号对齐。由于麦克风与声源的距离不同,导致每个麦克风接收到信号的先后顺序不一致,相位对齐模块的作用是选择一路参考信号,将其他每一路信号的相位进行一定数量的平移,使得所有麦克风接收到的信号相当于是同一时刻接收的。
解析变换模块是将相位对齐模块输出的各路信号分别进行分帧加窗处理,对每一帧信号进行解析变换。在验证时用的是汉宁窗,帧移为50%,每帧数据长度为k=256点。汉宁窗表达式如下:
ω(k)=0.5-0.5cos(2πk/k),k=0,1,...,k-1(5)
加窗后的信号为
y(k)=y'(k)ω(k)(6)
信号变为解析信号表示为
y=y+jh[y](7)
其中,h[]表示希尔伯特变换。希尔伯特变换系数表如下:
当序列数为偶数时,系数均为0值。且后半部分系数有如下关系:h(128)=0,h(129)=-h(127),...,h(256)=-h(1),即后一半系数关于h(128)奇对称。希尔伯特变换为
其中,h[y(k)]的长度为511点,先取前k=256个数,后256-1个数前位对齐相加,即
使得h[y(k)]的长度变为k个数。然后将h[y(k)]作虚部,y(k)作实部,更新y为解析信号。
小波变换模块采用mallat快速算法的原理,离散小波变换可以看成是由一个滤波器组对信号进行滤波和降采样处理。信号的四层小波分解图如图3所示,这里分别给出了‘sym4’母小波的高通滤波器分解系数和低通滤波器分解系数:
h0=[-0.0322-0.01260.09920.2979-0.80370.49760.0296-0.0758];
g0=[-0.0758-0.02960.49760.80370.2979-0.0992-0.01260.0322]。
令解析变换模块输出的信号y分别与高通滤波器分解系数h0和低通滤波器分解系数g0作卷积运算,结果如下:
得到(k+m-1)个数,其中m=8是滤波器系数的个数。得到的卷积结果取前k个数,后m-1个数前位对齐相加,即
分别得到点数为k的高通滤波系数和低通滤波系数。然后进行降采样运算,在k个数中,以2为步长抽取k/2个数,具体操作如下:
分别得到高频系数hi_d1和低频系数lo_d1。第二层分解时,对低频系数重复上述操作。图4给出了四层小波分解的结构图。本专利在验证时是做了四层分解。将解析信号的离散小波变换表示为y=dw[y+jh[y]]。
npsd估计模块采用了一种新的噪声功率谱密度npsd估计方法,称为阈值法。该方法利用了小波域中提到的阈值,可以避免使用vad(语音活动检测)方式。这里使用自适应的阈值对噪声功率谱密度npsd进行估计,阈值表达式如下
其中,下标j代表小波分解中的第j层,tj是第j层小波系数的阈值。nj是第j层小波系数的个数,σj的表达式如下
其中,median(|dj|)是第j层小波系数的中位数。每一帧用到的npsd估计值均由上一帧的噪声功率谱密度npsd估计值和当前帧的阈值更新得到,那么npsd的估计表达式为
其中,l是当前帧数,
进一步的,为了保证输出信号方差最小的同时没有失真,mvdr滤波器模块要在解析信号的小波域找到一个滤波器系数w,使输出信号z有如下表达式
z=why(16)
其中,[]h表示向量或矩阵的共轭转置。通过mvdr可得滤波器系数w,即
其中,
分布式算法迭代模块的工作原理是:将mvdr滤波器模块输出的滤波信号why处理为求平均值的形式、通过初始状态值根据metropolis权矩阵多次迭代求得初始状态值的平均值得到输出信号。其中在分布式实现该算法时,需要将输出信号z的表达形式写成求平均值的形式,该形式经定义式可变换为
其中,令
观察上式可以得知分布式mvdr的结果只需要每个麦克风获得所有麦克风初始状态值的平均值(
其中,m是metropolis权矩阵,定义如下
式中d代表两个不同麦克风可以互相通信的连接集合,即(i,j)∈d(i,j=1,…,n,i≠j)。di表示第i个麦克风可以与附近麦克风通信的数量。在上述迭代计算使得每个麦克风的输出信号
进一步的,分布式算法迭代模块的输出是解析信号小波域中的解。在小波反变换模块中,我们需要将输入值进行小波反变换,再取实部得到时域输出语音信号。离散小波反变换的具体操作与离散小波变换的做法正好相反,先升采样再进行滤波,最终数据相加实现重构。这里给出了‘sym4’母小波的重构滤波器系数:
h0'=[-0.07580.02960.4976-0.80370.29790.0992-0.0126-0.0322];
g0'=[0.0322-0.0126-0.09920.29790.80370.4976-0.0296-0.0758]。
升采样即先对最后一层的高频系数hi_d4和低频系数lo_d4分别每相邻两个点之间补1个零,具体运算如下:
升采样后的高频系数hi_r4”和低频系数lo_r”分别与重构高通滤波器系数h0’和重构低通滤波器系数g0’做卷积如下;
将两组卷积后的数分别取后m-1个数末位对齐相加如下:
最后将两组数据相加,即
lo_d3=hi_r4(k)+lo_r4(k)(25)
就实现了第四层高频系数hi_d4和低频系数lo_d4的小波重构,重构回第三层的低频系数lo_d3,依次类推,即可实现小波变换重构。
为验证本发明方法的有效性,本专利通过imgae模型模拟了一个5×5×3的封闭式房间,混响时间为0.1秒,声源位置坐标为(2.5米,2.5米,1米),取10个麦克风,麦克风横纵坐标利用均匀分布随机生成且高度也均为1米。麦克风之间的通信距离是在所有通信线路有45条的情况下,选择了最短的19条线路作为通信情况。声源是从timit数据库[https://download.csdn.net/download/sdhyfxh/4086482]随机选取的一个6秒纯净语音信号,采样频率是16khz。在每个麦克风接收到输入语音信号的同时加上一个互不相关的高斯白噪声作为输入噪声信号,致使10个麦克风输入信号的snr值和pesq值如图4、图5所示。可以看出,每个麦克风输入信号的snr值和pesq值各不相同。
采用本方法所提出的分布式mvdr的语音增强方法对每个麦克风输入信号进行降噪,每个麦克风的输出信号均达到全局最优解。消噪后的每个麦克风输出信号的snr值和pesq值如图6所示。可以看出snr值和pesq值相对文献[1]中的方法都有所提高,从而达到了分布式语音增强的效果。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
文件中的字母缩写的含义
mvdr:最小方差无失真响应
pesq:语音质量的感知评估snr:信噪比vad:语音活动检测
npsd:噪声功率谱密度wasn:无线声传感器网络
[1]y.zengandr.c.hendriks,"distributeddelayandsumbeamformerforspeechenhancementviarandomizedgossip,"inieee/acmtransactionsonaudio,speech,andlanguageprocessing,vol.22,no.1,pp.260-273,jan.2014.
[2]t.sherson,w.b.kleijnandr.heusdens,"adistributedalgorithmforrobustlcmvbeamforming,"2016ieeeinternationalconferenceonacoustics,speechandsignalprocessing(icassp),shanghai,2016,pp.101-105.
[3]yutengxiao,jihangyin,honggangqi,hongshengyin,andganghua,“mvdralgorithmbasedonestimateddiagonalloadingforbeamforming,”mathematicalproblemsinengineering,vol.2017,articleid7904356,7pages,2017。
- 还没有人留言评论。精彩留言会获得点赞!