一种多模态远程语音感知方法及装置与流程
本发明涉及多模态联合的传感器采集和语音增强领域,尤其涉及一种基于矩形麦克风面阵和摄像头联合采集的多模态远程语音感知方法及装置。
背景技术:
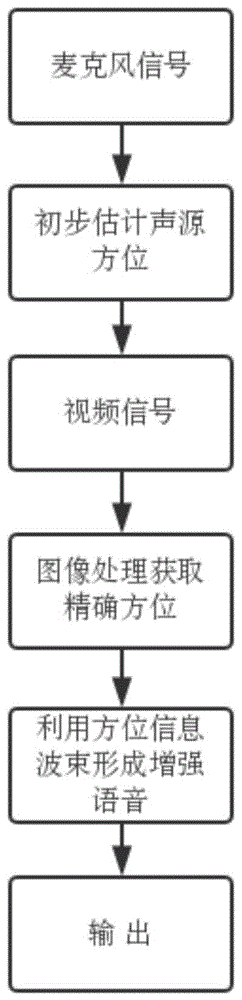
:近年来远程视频监控技术在人们生活中有着越来越广泛的应用。街道上的闯红灯照相仪、办公室里的监控摄像头以及各种红外探测仪和热成像技术等,尤其是在远程监控应用方面,只需要一个摄像头,人们就可以随时随地在手机等智能设备上查看远程监控画面,给人们生活带来了极大的便利。利用麦克风处理音频信号已经在手机和个人电脑领域有了一定的应用。在这些应用实例中,一般采用的是单个或者两个麦克风组成的系统。近年来,在国外,亚马逊、微软、谷歌等公司已经发布了基于麦克风阵列技术的产品。国内,讯飞、云知声、声智科技等公司也提出了成熟的麦克风硬件方案。这些产品的拾音和作用距离在10m以内,主要面向的是近场语音应用场景。然而,传统的近场语音应用已经渐渐无法满足人们的需求。当场景切换到室外、机器人、车载或者监控领域时,需要更为复杂的语音控制智能设备,因此,麦克风阵列技术成为了远场语音感知的核心。但是远程视频只能对图像进行处理而无法感知声音,这俨然已不能满足人们的需求。同时,传统的语音感知技术,在近距离时,其语音识别的识别率已达到身份识别的水准,但是在远距离情况下,其效果大幅度下降,原因是接收的语音信号的信噪比低,存在干扰信号。目前已有的远程语音定位技术存在的问题如下:(1)压缩传感技术用于方位估计可以提高方位精度,但是需要高信噪比;(2)卷积波束形成方法用于小传感器阵列,在提高方位估计精度的同时也需要较高的信噪比;(3)大尺度麦克风阵列可以同时满足高信噪比和窄波束,但在工程使用上非常麻烦,一方面占有较大的空间位置,另一方面,多通道数据处理需要强大功能的信号处理机。为了解决远程语音定位不够精准的问题,研究人员提出了利用图像高分辨能力的方法提高定位精度,获取声源有效位置,再结合麦克风阵列,利用波束形成算法增强语音、消除噪声,提高语音的质量。技术实现要素:针对现有技术存在的问题,本发明提供一种多模态远程语音感知方法及装置,利用矩形麦克风阵列和摄像头联合的检测方式,搭建采集处理系统,同时利用波束形成、自适应背景建模及前景提取、音视频联合的方法,获取远程语音信号并进行语音增强,最终实现音视频联合对远程语音信号的感知。本发明的目的是通过以下技术方案来实现的:一种多模态远程语音感知方法,包括以下步骤:步骤1:利用矩形麦克风阵列和摄像头,采集语音和视频信号;步骤2:对目标语音信号利用波束形成进行初步到达角估计,以获得粗略的声源方位;步骤3:根据粗略的声源方位,驾驶摄像头正对声源方向;步骤4:基于初始数据建立背景模型,进行前景提取和背景模型自适应更新;步骤5:将前景空间位置映射到高精度角度方位,将这个高精度方位参数传输给波束形成模块,波束形成在这个方位的输出就是增强的语音信号。进一步的,所述步骤2具体包括以下子步骤:步骤2.1,对语音信号分帧,记阵列采集到的第l帧(l=1,...,l)信号为x(l)=[x1(l),x2(l),...,xm(l),...,xm(l)],其中,m表示麦克风数目,每个麦克风作为一个通道,xm(l)=[xm(0,l),xm(1,l),...,xm(n,l)...,xm(n-1,l)]t表示第m个通道上采集的第l帧信号;对每帧信号应用窗函数后进行短时傅立叶变换,对第m个通道第l帧的时域信号进行傅里叶变换后的频域表示:其中,n表示时间的索引,k表示第k个频率点,bn表示长度为n的汉宁窗;定义m通道的频域信号为x(k,l):x(k,l)=[x1(k,l),x2(k,l),...,xm(k,l)]t,0≤k≤n-1(2.2)步骤2.2,定义信号的空间谱矩阵为sx(k)=e{x(k,l)xh(k,l)},e{·}表示对l帧信号求期望,矩阵元素假定语音信号入射角为θ,对n个频率点的的空间谱估计结果进行加权求和,得到总波束功率p(θ):其中,wds(θ,k)=[w1(θ,k),w2(θ,k),...,wm(θ,k)]t表示相位取齐的第k个频点的权向量,wdsh(θ,k)表示wds(θ,k)的共轭转置;对总波束功率p(θ)进行角度搜索,获得初步估计的粗略声源方位角进一步的,所述步骤3具体包括以下子步骤:步骤3.1,根据步骤2中得到的方向角判断声源的大致方向,驾驶摄像头正对声源方向。进一步的,所述步骤4具体包括以下子步骤:步骤4.1,首先使用初始视频数据建立背景模型,记采集的第p帧图像为ip(x,y),(x,y)是图像矩阵像素坐标;将图像转化成灰度图后对前s帧取平均作为初始背景b0(x,y)。公式如下:完成背景建模后,利用当前帧减去背景模型得到前景target(x,y):d(x,y)=ip(x,y)-b0(x,y)(4.2)ip(x,y)表示当前帧图像,d(x,y)代表前景像点,t是设定的阈值,target(x,y)矩阵中的1表示前景像素。步骤4.2,获得的二值化前景图像存在轮廓不连续、前景不完整等现象,因此,需要对图像进行开-闭运算等后续处理,最终获得完整的前景图像gp(x,y)。在处理视频流时,由于光线等环境变化,需要对背景模型进行更新。更新公式如下:其中,bp(x,y)为加入第p帧图像进行自适应更新后的背景模型,0<α<1为更新因子,根据环境变换而变化。由于目标的水平尺寸相对于到摄像头的距离很小,图像坐标和方向坐标可看作线性关系,进而把前景的位置换算成角度输出给波束形成模块。进一步的,所述步骤5具体包括以下子步骤:步骤5.1,根据图像处理获得的精确角度信息相应目标信号的阵响应矢量为:其中[p1,p2,...,pm]是m个麦克风阵元的二维坐标,是第k个频点对应的波长,fk是第k个频点的频率,c表示平面波在介质中传播的速度;步骤5.2,将线性约束最小方差波束形成转化为解下面的最优化问题:其中,w(k,l)=[w1(k,l),w2(k,l),...,wm(k,l)]t表示第l帧信号的权向量,sx(k,l)表示第l帧信号的空间谱矩阵。根据最速下降自适应算法进行滤波:w(k,l+1)=j(k)[w(k,l)-μx(k,l)y*(k,l)]+f(k)(5.3)其中y(k,l)=wh(k,l)x(k,l)表示波束形成输出信号,y*(k,l)表示y(k,l)的复共轭,μ≥0为收敛步长,初始权向量将各子频带信号拼接成宽带信号:y(l)=[y(0,l),y(1,l),...,y(n-1,l)];步骤5.3:最后对y(l)进行逆离散傅立叶变换(inversediscretefouriertransform,简称idft),得到第l帧的时域输出信号y(l):y(l)=idft[y(l)](5.4)再将l帧语音信号进行拼接,可得时域输出y(t):y(t)=[y(1),y(2),...,y(l),...,y(l)](5.5)y(t)即为增强的语音信号。本发明的另一目的是提供一种多模态远程语音感知装置,该装置包括:矩形麦克风阵列,与声源相距8~10m;摄像头,布置于矩形麦克风阵列上端边沿,与麦克风阵列同步转动;下位机,与矩形麦克风阵列连接,用于控制命令接收、信号采集、数据传输;下位机在接收到上位机发送的“开始”控制指令后,通过矩形麦克风阵列进行语音信号采集,并实时上传数据到上位机;下位机在接受到上位机发送的“停止”控制指令后,停止实时上传数据到上位机;上位机,与摄像头连接,接收视频信号和下位机发送的语音信号,对目标语音信号进行初步角度估计,利用这个角度驾驶摄像头转动到正对声源方向。从视频图像提取目标前景,将前景坐标映射到精确方位;将此高精度方位参数传送给波束形成模块,波束形成在该方位输出,获得增强的语音信号。进一步的,所述下位机与上位机的连接及数据传输具体如下:a,确定上位机、下位机、麦克风阵列和摄像头的数据端口和连线接口,建立连接;b,上位机下发控制命令“开始”,开始采集音频和视频数据;c,对矩形麦克风阵列所有通道的采样数据进行并串转换,下位机向上位机发送上行数据包;d,上位机下发控制命令“停止”,下位机停止采集数据,等待上位机重新发送控制命令“开始”;e,采集结束后音频数据自动存储为.dat文件,视频数据存储为.avi文件。相对于现有技术,本发明的有益效果是:(1)本发明使用音视频联合的语音定位方法,加入视频定位人像便于获取精确的声源方位角,避免了传统波束形成中语音方位估计分辨率低,无法清晰辨别多个声源的缺点。(2)本发明使用图像处理返回的角度和麦克风阵列对远程语音信号进行增强,解决了远程语音信号在空间中传播后能量减弱、信噪比太低的问题。(3)本发明利用自适应线性约束最小方差波束形成器抑制非相干噪声和干扰信号,解决了语音信号远距离时噪声干扰严重的问题。(4)基于上述三个特点,本发明可以实现室外远程语音感知的功能,具有较好的实用价值。附图说明图1为本发明多模态远程语音感知方法总体流程图;图2为本发明中初步估计声源方位角流程图;图3为本发明中图像处理输出精确声源方位角流程图;图4为本发明中自适应波束形成增强语音信号流程图;图5为本发明中上位机波束形成初步定位的波束模式图;图6为本发明中视频处理获取高精度语音方位结果图;图7为本发明中语音增强前后信号波形图;图8为本发明中语音增强前后信号时频图。具体实施方式下面结合附图和具体实施方式对本发明作进一步详细描述,本发明的目的和效果将变得更加明显。图1给出了本发明的总体流程图。本发明的多模态远程语音感知方法分成5个步骤,即首先利用矩形麦克风阵列和摄像头采集语音和视频信号;对信号进行初步方位角估计;根据到达角粗略估计结果,配合自适应背景建模检测目标,获得声源的精确方位角;基于图像处理得到的精确方位角,利用线性约束最小方差波束形成和最速下降算法,实现对语音信号的自适应滤波,最终输出增强后的清晰语音信号。本发明的检测方法具体实施方式如下:步骤1:将矩形麦克风阵列与摄像头放置在同一角度,采集音视频信号;步骤2:对目标语音信号进行到达角估计,以获得粗略的声源方位。流程图如图2所示,包含以下子步骤:步骤2.1,对语音信号分帧,记阵列采集到的第l帧(l=1,...,l)信号为x(l)=[x1(l),x2(l),...,xm(l),...,xm(l)],其中,m表示麦克风数目,每个麦克风作为一个通道,xm(l)=[xm(0,l),xm(1,l),...,xm(n,l)...,xm(n-1,l)]t表示第m个通道上采集的第l帧信号;对每帧信号应用窗函数后进行短时傅立叶变换,对第m个通道第l帧的时域信号进行傅里叶变换后的频域表示:其中,n表示时间的索引,k表示第k个频率点,bn表示长度为n的汉宁窗;定义m通道的频域信号为x(k,l):x(k,l)=[x1(k,l),x2(k,l),...,xm(k,l)]t,0≤k≤n-1(2.2)作为优选,具体实施过程中,采样频率为48khz,短时傅里叶变换长度n为512,选择窗函数bn为长度为512的汉宁窗。步骤2.2,定义信号的空间谱矩阵为sx(k)=e{x(k,l)xh(k,l)},e{·}表示对l帧信号求期望,矩阵元素假定语音信号入射角为θ,对n个频率点的的空间谱估计结果进行加权求和,得到总波束功率p(θ):其中,wds(θ,k)=[w1(θ,k),w2(θ,k),...,wm(θ,k)]t表示相位取齐的第k个频点的权向量,wdsh(θ,k)表示wds(θ,k)的共轭转置;对总波束功率p(θ)进行角度搜索,获得初步估计的粗略声源方位角在具体实施过程中,根据实际情况,角度θ的搜索范围为:-90°≤θ≤+90°,角度步进为1度。步骤3:利用声源方位初步信息,使得摄像头正对声源方向。步骤4:基于初始数据建立背景模型,进行前景检测和背景模型自适应更新;流程图如图3所示,包含以下子步骤:步骤4.1,首先使用初始视频数据建立背景模型,记采集的第p帧图像为ip(x,y),(x,y)是图像矩阵像素坐标;将图像转化成灰度图后对前s帧取平均作为初始背景b0(x,y)。公式如下:完成背景建模后,利用当前帧减去背景模型得到前景target(x,y):d(x,y)=ip(x,y)-b0(x,y)(4.2)ip(x,y)表示当前帧图像,d(x,y)代表前景像点,t是设定的阈值,target(x,y)矩阵中的1表示前景像素。步骤4.2,获得的二值化前景图像存在轮廓不连续、前景不完整等现象,因此,需要对图像进行开-闭运算等后续处理,最终获得完整的前景图像gp(x,y)。在处理视频流时,由于光线等环境变化,需要对背景模型进行更新。更新公式如下:其中,bp(x,y)为加入第p帧图像进行自适应更新后的背景模型,0<α<1为更新因子,根据环境变换而变化。由于目标的水平尺寸相对于到摄像头的距离很小,图像坐标和方向坐标可看作线性关系,进而把前景图像gp(x,y)的位置换算成角度输出给波束形成模块。实验中的获取的精确角度为+27°。步骤5:将精确角度应用至自适应波束形成算法中,提高语音信号的信噪比。流程图如图4所示,包含以下子步骤:步骤5.1,根据图像处理获得的精确角度信息相应目标信号的阵响应矢量为:其中[p1,p2,...,pm]是m个麦克风阵元的二维坐标,是第k个频点对应的波长,fk是第k个频点的频率,c表示平面波在介质中传播的速度;具体实施过程中,麦克风阵列为2×6的均匀矩阵,麦克风之间的间距均为0.05m,只考虑水平方向角,不考虑俯仰方向角。步骤5.2,将线性约束最小方差波束形成转化为解下面的最优化问题:其中,w(k,l)=[w1(k,l),w2(k,l),...,wm(k,l)]t表示第l帧信号的权向量,sx(k,l)表示第l帧信号的空间谱矩阵。根据最速下降自适应算法进行滤波:w(k,l+1)=j(k)[w(k,l)-μx(k,l)y*(k,l)]+f(k)(5.3)其中y(k,l)=wh(k,l)x(k,l)表示波束形成输出信号,y*(k,l)表示y(k,l)的复共轭,μ≥0为收敛步长,初始权向量具体实施过程中,μ的选择根据不同的语音采集场景进行更改,实验中0.00003≤μ≤0.0001。将各子频带信号拼接成宽带信号:y(l)=[y(0,l),y(1,l),...,y(n-1,l)];步骤5.3:最后对y(l)进行逆离散傅立叶变换(inversediscretefouriertransform,简称idft),得到第l帧的时域输出信号y(l):y(l)=idft[y(l)](5.4)再将l帧语音信号进行拼接,可得时域输出y(t):y(t)=[y(1),y(2),...,y(l),...,y(l)](5.5)y(t)即为增强的语音信号。所述的多模态远程语音感知装置包括以下四个模块:a,矩形麦克风阵列,与声源相距8~10m;b,摄像头,布置于矩形麦克风阵列上端边沿,与麦克风阵列同步转动;c,下位机,与矩形麦克风阵列连接,用于控制命令接收、信号采集、数据传输;下位机在接收到上位机发送的“开始”控制指令后,通过矩形麦克风阵列进行语音信号采集,并实时上传数据到上位机;下位机在接受到上位机发送的“停止”控制指令后,停止上传数据;d,上位机,与摄像头连接,接收视频信号和下位机发送的语音信号,对目标语音信号进行初步角度估计,利用这个角度驾驶摄像头转动到正对声源方向。从视频图像提取目标前景,将前景坐标映射到精确方位;将此高精度方位参数传送给波束形成模块,波束形成在该方位输出,获得增强的语音信号。检测装置中所述下位机与上位机的连接及数据传输具体如下:a,确定上位机、下位机、麦克风阵列和摄像头的数据端口和连线接口,建立连接;b,上位机下发控制命令“开始”,开始采集音频和视频数据;c,对矩形麦克风阵列所有通道的采样数据进行并串转换,下位机向上位机发送上行数据包;d,上位机下发控制命令“停止”,下位机停止采集数据,等待上位机重新发送控制命令“开始”;e,采集结束后音频数据自动存储为.dat文件,视频数据存储为.avi文件。实施例本实施例将上述检测方法应用于远程语音感知,具体步骤如前所述,此处不再赘述。对目标语音利用波束形成进行初步到达角估计,计算-90°到+90°的总波束功率p(θ),以角度θ为x轴坐标,归一化功率p(θ)为y轴坐标作图,结果如图5所示,目标声源(女声)的粗略方位角干扰声源的估计角为-29°。图像处理的原图如图6中(a)所示,背景差分法处理后结果如图6中(b)所示,可以看出一些噪声以及干扰会影响结果。为消除干扰,采用开-闭运算处理后得到如图6中(c)所示结果,最终声源定位结果如图6中(d)所示。获得的声源精确位置为+27°和-25°,根据波束形成得到的粗略方位角,选择将精确的声源方位角输出给波束形成模块进行波束形成输出。上位机音视频联合算法音频处理结果如图7、图8所示。图7是语音增强前、后的信号波形图,处理后噪声被明显减弱,信噪比增强。图8是语音增强前、后的信号时频图,从时频图中可以看出,经过波束形成后,噪声和能量集中在低频部分的干扰(男声)被抑制,而高频部分的目标声源(女声)被保留并被增强。用信噪比和pesq分数分别评价波束形成在粗略角和精确角的结果,检验多模态联合系统在实际数据处理中的性能。处理结果如表1和表2所示,波束形成在精确方位角的输出信号信噪比增益达到了12.1704db,pesq评分提高了0.655,其性能优于波束形成在粗略方位角输出的结果。表1波束形成信噪比对比粗略角度精确角度信噪比增益(db)10.016812.1704表2pesq评价分数对比单通道信号粗略角度精确角度pesq评价1.64581.94732.3008本发明所述处理方法已在杭州浙江大学玉泉校区永谦广场进行测试,采用2×6的麦克风面阵,声源距离为10米,分为目标声源(27°)和干扰声源(-25°),采样率为48khz,测试结果良好。本发明能够进行远程语音和视频的联合采集,并且上发上位机进行处理和输出。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1