语音交互系统和方法、程序、学习模型生成装置和方法与流程
本发明涉及语音交互系统、语音交互方法、程序、学习模型生成装置以及学习模型生成方法,并且尤其涉及用于通过使用语音与用户进行会话的语音交互系统、语音交互方法、程序、学习模型生成装置和学习模型生成方法。
背景技术:
使用户能够享受与语音交互机器人(语音交互系统)的日常会话的技术正变得普及。根据此技术的语音交互机器人分析用户发出的语音的语音信息,并根据分析结果进行响应。这里,语音交互机器人使用学习模型确定响应。
关于上述技术,日本未经审查的专利申请公开no.2005-352154公开一种情绪状态反应操作装置,其根据用户发出的语音评估用户的情绪状态并执行适当的相应操作。根据日本未经审查的专利申请公开no.2005-352154的情绪状态反应操作装置包括:音素特征量提取装置,用于提取与语音信息的音素频谱相关的特征量;状态确定装置,用于输入音素特征量并基于预先准备的状态确定表确定语音信息的情绪状态;以及相应动作选择装置,用于输入情绪状态并基于预先准备的相应动作选择表确定相应的动作过程。根据日本未经审查的专利申请公开no.2005-352154的情绪状态反应运动装置还包括情绪状态学习表和情绪状态学习装置。情绪状态学习装置基于情绪状态学习表使用预定机器学习模型获取音素特征量和情绪状态之间的关系,并将学习结果存储在状态确定表中。状态确定装置基于状态确定表根据机器学习模型确定情绪状态。
技术实现要素:
取决于用户的状态(用户的差异、用户的情绪等),机器学习模型可能不适合。在这种情况下,例如,可能发生诸如用户话语和装置话语之间的重叠的响应错误、或者用户话语和装置话语之间的时间段长的长沉默。为了解决此问题,根据日本未经审查的专利申请公开no.2005-352154的技术使用一个机器学习模型确定相应的动作过程。因此,利用根据日本未经审查的专利申请公开no.2005-352154的技术,难以适当地处理有效防止由不适当的学习模型引起的响应错误的情况。
本公开涉及能够适当地处理情况使得有效地防止发生响应错误的语音交互系统、语音交互方法、程序、学习模型生成装置和学习模型生成方法。
根据本公开的语音交互系统是通过使用语音与用户进行会话的语音交互系统,包括:话语获取单元,所述话语获取单元被配置成获取用户给出的用户话语;特征提取单元,所述特征提取单元被配置成至少提取所获取的用户话语的特征;响应确定单元,所述响应确定单元被配置成使用通过机器学习预先生成的多个学习模型中的任何一个根据所提取的特征来确定响应;响应执行单元,所述响应执行单元被配置成进行控制以便于执行所确定的响应;用户状态检测单元,所述用户状态检测单元被配置成检测用户状态,其是用户的状态;以及学习模型选择单元,所述学习模型选择单元被配置成根据检测到的用户状态从多个学习模型中选择学习模型,其中响应确定单元使用由学习模型选择单元选择的学习模型来确定响应。
此外,根据本公开的语音交互方法是由语音交互系统执行的语音交互方法,该语音交互系统通过使用语音与用户进行会话,该语音交互方法包括:获取用户给出的用户话语;至少提取所获取的用户话语的特征;使用通过机器学习预先生成的多个学习模型中的任何一个根据所提取的特征来确定响应;进行控制以便于执行确定的响应;检测用户状态,该用户状态是用户的状态;根据检测到的用户状态从多个学习模型中选择学习模型,其中使用所选择的学习模型来确定响应。
此外,根据本公开的程序是用于执行由语音交互系统执行的语音交互方法的程序,该语音交互系统通过使用语音与用户进行会话,该程序使计算机执行以下步骤:获取用户给出的用户话语;至少提取所获取的用户话语的特征;使用通过机器学习预先生成的多个学习模型中的任何一个根据所提取的特征来确定响应;进行控制以便于执行所确定的响应;检测用户状态,该用户状态是用户的状态;根据检测到的用户状态从多个学习模型中选择学习模型;以及使用所选择的学习模型来确定响应。
用于生成响应错误的原因通常是不适合的学习模型。当学习模型不适合时,本公开的上述配置使其能够根据用户状态将学习模型切换到适合的学习模型。因此,本公开能够适当地处理情况,以便有效地防止发生响应错误。
此外,优选地,用户状态检测单元将用户在会话中的积极性的程度检测为用户状态,并且学习模型选择单元选择与用户的积极性的程度相对应的学习模型。
本公开的上述配置使其能够使用适合于用户在会话中的积极性的程度的学习模型进行会话,从而根据进行会话的用户的积极性而执行响应。
此外,优选地,用户状态检测单元相对于语音交互系统已经输出语音作为响应的时间与用户在预定时段内已经发出语音的时间的总和检测用户在预定时间段内给出的语音量或者用户已经发出语音的时间百分比,并且学习模型选择单元选择对应用户给出的语音量或用户已经发出语音的时间的百分比的学习模型。
本公开的上述配置使其能够更准确地确定用户的积极性的程度。
此外,优选地,用户状态检测单元检测关于用户的识别信息作为用户状态,并且学习模型选择单元选择与关于用户的识别信息相对应的学习模型。
本公开的上述配置使其能够使用适合于用户的学习模型进行会话,从而根据进行会话的用户而执行响应。
此外,优选地,用户状态检测单元将用户的情绪检测为用户状态,并且学习模型选择单元选择与用户的情绪相对应的学习模型。
本公开的上述配置使其能够使用适合于用户在会话中的情绪的程度的学习模型进行会话,从而根据进行会话的用户的情绪而做出响应。
此外,优选地,用户状态检测单元将用户的健康状况检测为用户状态,并且学习模型选择单元选择与用户的健康状况相对应的学习模型。
本公开的上述配置使其能够使用适合于用户的健康状况的程度的学习模型进行会话,从而根据进行会话的用户的健康状况而执行响应。
此外,优选地,用户状态检测单元将用户的唤醒状态的程度检测为用户状态,并且学习模型选择单元选择与用户的唤醒状态的程度相对应的学习模型。
本公开的上述配置使其能够使用适合于用户的唤醒状态的程度的学习模型进行会话,从而根据进行会话的用户的唤醒状态而做出响应。
此外,根据本公开的学习模型生成装置是学习模型生成装置,该学习模型生成装置被配置成生成在通过使用语音与用户进行会话的语音交互系统中使用的学习模型,该装置包括:话语获取单元,所述话语获取单元被配置成通过与期望用户进行会话来获取用户话语,该用户话语是由一个或多个期望用户给出的话语;特征提取单元,所述特征提取单元被配置成提取至少指示所获取的用户话语的特征的特征向量;样本数据生成单元,所述样本数据生成单元被配置成生成样本数据,在所述样本数据中,指示对用户话语的响应的正确标签和特征向量彼此相关联;用户状态获取单元,所述用户状态获取单元被配置成获取用户状态,该用户状态是当用户已经发出话语时的期望用户的状态,以将所获取的用户状态与对应于用户话语的样本数据相关联;样本数据分类单元,所述样本数据分类单元被配置成针对用户状态中的每一个用户状态对样本数据进行分类;以及学习模型生成单元,所述学习模型生成单元被配置成针对每条分类的样本数据通过机器学习生成多个学习模型。
此外,根据本公开的学习模型生成方法是用于生成在通过使用语音与用户进行会话的语音交互系统中使用的学习模型的学习模型生成方法,该方法包括:通过与期望用户进行会话,获取用户话语,该用户话语是由一个或多个期望用户给出的话语;提取特征向量,该特征向量至少指示所获取的用户话语的特征;生成样本数据,在所述样本数据中,指示对用户话语的响应的正确标签和特征向量彼此相关联;获取用户状态,该用户状态是在用户已经发出话语时的期望用户的状态以将所获取的用户状态与对应于用户话语的样本数据相关联;针对用户状态中的每一个用户状态对样本数据进行分类;以及针对每条分类的样本数据通过机器学习生成多个学习模型。
本公开能够针对每个用户状态对样本数据进行分类并通过机器学习生成多个学习模型,从而生成对应于用户状态的多个学习模型。因此,语音交互系统能够根据用户状态选择学习模型。
根据本公开,能够提供能够适当地处理情况使得有效地防止发生响应错误的语音交互系统、语音交互方法、程序、学习模型生成装置和学习模型生成方法。
从以下给出的详细描述和仅通过图示给出的附图中将更全面地理解本公开的上述和其他目的、特征和优点,并且因此不应视为限制本公开。
附图说明
图1是示出根据第一实施例的语音交互系统的硬件结构的图;
图2是示出根据第一实施例的语音交互系统的配置的框图;
图3是示出根据第一实施例的特征提取单元生成的特征向量的示例的图;
图4是用于描述根据第一实施例的生成学习模型的方法的概要的图;
图5是用于描述根据第一实施例的生成学习模型的方法的概要的图;
图6是用于描述根据第一实施例的生成学习模型的方法的概要的图;
图7是示出由根据第一实施例的语音交互系统执行的语音交互方法的流程图;
图8是示出由根据第一实施例的语音交互系统执行的语音交互方法的流程图;
图9是示出在用户状态是关于用户的识别信息的情况下的处理的图;
图10是示出其中用户状态是用户在会话中的积极性的程度的情况下的处理的图;
图11是图示用于确定积极性的程度的表的图;
图12是示出在用户状态是用户的情绪的情况下的处理的图;
图13是示出在用户状态是用户的健康状况的情况下的处理的图;
图14是示出在用户状态是用户的唤醒状态的程度的情况下的处理的图;
图15是示出根据第二实施例的语音交互系统的配置的框图;
图16是示出根据第二实施例的学习模型生成装置的配置的图;以及
图17是示出由根据第二实施例的学习模型生成装置执行的学习模型生成方法的流程图。
具体实施方式
(第一实施例)
在下文中,参考附图解释根据本公开的实施例。注意,贯穿整个附图,相同的符号被指配给相同的部件,并且根据需要省略重复的解释。
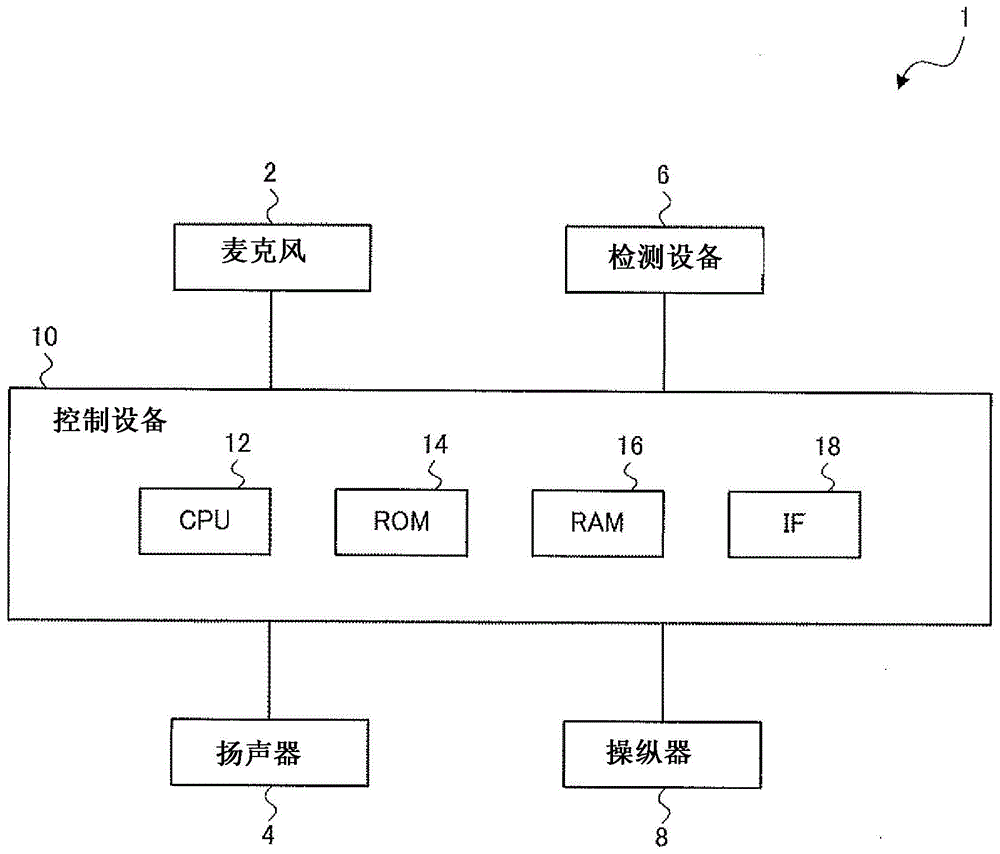
图1是示出根据第一实施例的语音交互系统1的硬件配置的图。语音交互系统1通过使用语音与用户进行会话。具体地,语音交互系统1通过根据用户给出的话语(即,根据用户话语)为用户执行诸如语音的响应来与用户执行会话。语音交互系统1能够被安装在例如生活支持机器人和小型机器人、云系统、智能电话等机器人中。在以下描述中给出语音交互系统1被安装在机器人中的示例。
语音交互系统1包括收集周围声音的麦克风2、产生语音的扬声器4、用于检测用户状态的检测设备6、操作机器人的颈部等的操纵器8、以及控制设备10。该控制设备10具有例如作为计算机的功能。控制设备10无线地或通过电线连接到麦克风2、扬声器4、检测设备6和操纵器8。检测设备6包括例如相机和生物传感器中的至少一个。生物识别传感器例如是血压计、温度计或脉搏计。
控制设备10包括cpu(中央处理单元)12、rom(只读存储器)14、ram(随机存取存储器)16和接口(if)单元18作为主要硬件组件。cpu12、rom14、ram16和接口单元18通过数据总线等彼此连接。
cpu12具有作为执行控制过程、运算过程等的运算单元的功能。rom14具有存储由cpu12执行的控制程序、算术程序等的功能。ram16具有临时存储处理数据等的功能。接口单元18无线地或通过电线向/从外部输入/输出信号。此外,接口单元18接受用户输入数据的操作,并为用户显示信息。
控制设备10分析由麦克风2收集到的用户话语,根据用户话语确定对用户的响应,并执行它。这里,在此实施例中,“响应”包括“沉默”、“点头”和“说话”。“沉默”是语音交互系统1什么都不做的动作。“点头”是垂直摆动机器人颈部的动作。“说话”是语音交互系统1输出语音的动作。当确定的响应是“点头”时,控制设备10控制操纵器8以操作机器人的颈部。当确定的响应是“说话”时,控制设备10通过扬声器4输出与生成的响应相对应的语音(系统话语)。
图2是示出根据第一实施例的语音交互系统1的配置的框图。根据第一实施例的语音交互系统1包括话语获取单元102、特征提取单元104、所选模型存储单元108、响应数据库110(响应db)、响应确定单元120、响应执行单元130、以及响应历史存储单元132。根据第一实施例的语音交互系统1还包括用户状态检测单元140、学习模型选择单元150和学习模型数据库160(学习模型db)。
图2中所示的每个组件能够由麦克风2、扬声器4、操纵器8和控制设备10中的至少一个实现。此外,例如,通过使cpu12执行存储在rom14中的程序,能够实现至少一个组件。此外,必要的程序可以存储在任意非易失性记录介质中,并且可以根据需要安装。请注意,每个组件的实现不仅限于软件实现。也就是说,每个组件可以由诸如一些种类的电路元件的硬件实现。此外,图2中所示的所有组件不必包括在一个设备中,而是图2中所示的一个或多个组件可以包括在与其他组件物理分离的设备中。例如,学习模型数据库160可以包括在服务器中,并且除了学习模型数据库160之外的组件可以包括在能够与服务器通信的语音交互机器人等中。这也适用于稍后将描述的其他实施例。
话语获取单元102可以包括麦克风2。话语获取单元102获取用户话语(以及语音交互系统1的话语)。具体地,话语获取单元102收集用户话语(和语音交互系统1的话语)并将其转换为数字信号。然后,话语获取单元102将用户话语的话语数据(用户语音数据)输出到特征提取单元104。
特征提取单元104至少提取用户话语的特征。具体地,特征提取单元104针对用户话语分析非语言信息,该非语言信息不同于指示用户话语的特定语义内容的语言信息。此外,特征提取单元104生成将在后面描述的特征向量作为非语言信息分析结果,该非语言信息分析结果是分析非语言信息的结果。然后,特征提取单元104将非语言信息分析结果(特征向量)输出到响应确定单元120。特征提取单元104可以提取除了用户话语之外的用户特征并生成特征向量。
注意,非语言信息是与要处理的用户话语的语言信息(字符串)不同的信息,并且包括关于用户话语的韵律信息和响应历史信息中的至少一个。韵律信息是指示用户话语的语音波形的特征的信息,诸如基频、声压、频率的变化等、变化带、最大幅度、平均幅度等。此外,响应历史信息是指示由响应确定单元120确定(生成)并由响应执行单元130执行的响应的过去历史的信息。当由响应执行单元130执行响应时响应历史存储单元132存储(更新)此响应历史信息。
具体地,特征提取单元104通过对由话语获取单元102获取的用户语音数据执行语音分析等基于语音波形分析韵律信息。然后,特征提取单元104计算指示对韵律信息进行指示的特征量的值。注意,特征提取单元104可以针对用户语音数据计算通过例如以32毫秒的间隔划分用户语音数据而获得的每个帧的基频等。此外,特征提取单元104从响应历史存储单元132提取响应历史信息,并计算指示响应历史的特征的特征量。
注意,因为使用用户话语的语言信息的语法分析使用模式识别等,所以通常需要很长时间来进行此分析。与此相反,用于对非语言信息量的分析(即,对韵律信息的分析和对响应历史信息的分析)的数据小于语法分析的数据量,并且其计算技术是比语法分析简单。因此,对非语言信息的分析所需的时间可能比语法分析所需的时间短得多。
所选模型存储单元108存储由学习模型选择单元150选择的学习模型,稍后将对其进行描述。这里,在本实施例中,学习模型选择单元150通过稍后描述的方法从存储在学习模型数据库160中的多个学习模型中选择适当的学习模型。当学习模型选择单元150还没有选择学习模型时,诸如在语音交互开始之前,所选模型存储单元108可以存储一个指定的学习模型。
响应数据库110存储语音交互系统1做出响应所必需的数据。例如,响应数据库110预先存储当响应是“说话”时指示系统话语的多个系统语音数据片段。
响应确定单元120根据非语言信息分析结果(特征向量)确定要执行哪个响应。这里,在此实施例中,响应确定单元120使用预先通过机器学习(诸如监督学习)生成的多个学习模型中的一个根据提取的特征(特征向量)确定响应。稍后将描述其细节。
在此实施例中,响应确定单元120确定“沉默”、“点头”和“说话”中的一个作为响应。响应确定单元120将指示所确定的响应的数据(响应数据)输出到响应执行单元130。当响应确定单元120确定“说话”作为响应时,其可以从被存储在响应数据库110中的多个系统话语中顺序地或随机地选择系统话语(系统语音数据)。响应确定单元120将所选择的系统语音数据输出到响应执行单元130。
响应执行单元130执行用于执行由响应确定单元120确定的响应的控制。具体地,当从响应确定单元120输出的响应数据指示“沉默(沉默响应)”时,响应执行单元130控制扬声器4和操纵器8使得它们不进行操作。当从响应确定单元120输出的响应数据指示“点头(点头响应)”时,响应执行单元130控制操纵器8以操作机器人的颈部。当从响应确定单元120输出的响应数据指示“说话(话语响应)”时,响应执行单元130控制扬声器4以输出指示由响应确定单元120选择的系统语音数据的语音。
响应历史存储单元132存储用于识别由响应执行单元130执行的响应的数据作为响应历史信息。此外,当响应历史存储单元132包括与会话相关的时间作为响应历史信息时,响应历史存储单元132可以测量在其期间发生会话的时间段并将测量的时间存储为响应历史信息。
图3是图示根据第一实施例的特征提取单元104生成的特征向量的示例的图。注意,图3中所示的特征向量仅是示例。也就是说,其他各种特征向量能够被用作特征向量。让vi表示第i个用户话语的特征向量,特征向量的n个分量被表达为“vi=(vi1,vi2,...,vim-1),vim,vi(m+1),...,vin)”。注意,i、n和m中的每一个都是整数(n>m)。此外,vi1至vi(m-1)对应于与关于第i个用户话语的信息有关的韵律信息的分析结果。此外,vim至vin对应于响应历史信息的分析结果。注意,vim至vin可以是存储在响应历史存储单元132中的信息本身。也就是说,对于响应历史信息,特征提取单元104可以仅从响应历史存储单元132中提取响应历史,并且可以不执行任何具体分析。
在图3所示的示例中,vi1表示第i个用户话语的短语的末尾(以下称为“短语末尾”)处(在用户话语结束之前的t1毫秒(t毫秒)和用户话语结束之间的时段)在t1毫秒内的基频f0(f0t1)的参数。此外,vi7表示第i个用户话语的长度l1[秒](用户话语长度)。注意,可以通过使用sptk(语音信号处理工具包)的swipe(锯齿波形激励音高估计)的逻辑来为每个帧计算基频f0。
此外,vim表示一种紧接前述的响应。紧接前述的响应的类型是由响应执行单元130执行的紧接前述的响应的类型(恰好在第i个用户话语之前)(并且是“沉默”、“点头”和“说话”之一)。注意,对于不是诸如vim的数值的分量的每个分量值(特征量),为每种类型指配数值。例如,对于vim,分量值“1”指示“沉默”,分量值“2”指示“点头”,并且分量值“3”指示“说话”。
用户状态检测单元140(图2)确定已经给出话语的用户的状态(用户状态)。稍后将描述其细节。用户状态检测单元140将检测到的用户状态输出到学习模型选择单元150。虽然用户状态是例如关于用户的识别信息、用户在会话中的积极性、用户的情绪、用户的健康状况或用户的唤醒状态,但是其不限于此。虽然用户的情绪是例如用户的喜悦、愤怒、悲伤、愉悦或惊喜,但是其不限于此。此外,虽然用户的健康状况是例如用户的脉搏、体温、血压等,但是其不限于此。用户状态检测单元140使用通过相机捕获的用户的图像,通过生物传感器检测到的用户的脉搏、体温或血压,或者麦克风2收集的用户的语音来检测前述用户状态。
学习模型选择单元150根据用户状态检测单元140检测到的用户状态从存储在学习模型数据库160中的多个学习模型中选择学习模型。稍后将描述其细节。学习模型数据库160存储通过机器学习预先生成的多个学习模型。稍后将描述生成多个学习模型的方法的具体示例。
生成响应错误的原因通常是不适合的学习模型。例如,某个用户的适合的学习模型可能不适合另一个用户。即使对于相同的用户,由于用户的情绪等的变化,适合的学习模型也可能变得不适合。学习模型不适合意味着对用户话语的响应的准确性低。换句话说,学习模型不适合意味着会话的节奏和韵律不好。因为会话的合适节奏和韵律可以取决于用户而变化,所以适合于一个用户的学习模型可能不适合于另一个用户。此外,即使对于相同的用户,会话的合适的节奏和韵律也可以取决于他/她的情绪等的变化而变化,并且之前适合的学习模型可能不再适合。当对学习模型的响应的准确性低时,当应对某些用户话语执行“沉默响应”时机器人执行“话语响应”,或者当应对某些用户话语执行“话语响应”时机器人执行“沉默响应”。
另一方面,在此实施例中,能够根据用户状态将学习模型切换为适合的模型。因此,根据此实施例的语音交互系统1能够适当地处理情况以有效地防止发生响应错误。也就是说,根据此实施例的语音交互系统1使能够改善响应精度。
接下来,将描述生成学习模型的方法的概要。
图4至图6是用于描述根据第一实施例的生成学习模型的方法的概要的图。首先,获取用于生成学习模型的样本数据。如图4中所示,收集样本数据(训练数据),其中通过用户a和机器人之间的会话,诸如机器人(语音交互系统1)响应于用户话语,将特征向量和正确标签彼此相关联。此时,操作员以机器人对用户a的话语执行适合的响应的方式操作机器人(语音交互系统1)。
在图4中所示的示例中,正确标签“a”对应于“沉默响应”。正确标签“b”对应于“点头响应”。正确标签“c”对应于“话语响应”。操作员操作机器人,使得在用户a的话语期间执行沉默响应。此时,操作员不必做任何事情。另外,操作员操作机器人,使得在用户a的话语中的逗号级的中断处执行点头响应。此时,机器人通过操作员的操作点头。此外,操作员操作机器人,使得在用户a的话语的句号级别中断处执行话语响应。此时,机器人通过操作员的操作说话。
在图4中的示例中,操作员确定它处于用户a的话语中间,因为用户a的话语“毕竟”和“我自己收听”之间没有中断,并且然后操作机器人以执行沉默响应。当用户a的话语“我自己收听”结束时,确定存在句号级别中断,并且操作员操作机器人以执行话语响应。此时,机器人输出话语“真的吗?”。
此外,检测用户a的用户状态。用户状态可以由例如操作员确定,或者可以由诸如用户状态检测单元140的前述功能自动检测。因此,用户状态#1至#n之一与样本数据相关联。符号n是等于或大于2的整数,指示用户状态的数量。此n可以对应于学习模型的数量。
图5是图示样本数据的示例的图,该样本数据是从图4的示例获取的一对特征向量和正确标签。因为用户话语“毕竟”的长度是0.5秒,“0.5”被输入到特征向量的分量(图3中的vi7)。此外,因为对用户话语“毕竟”的响应是“沉默响应”,所以正确的标签“a”与用户话语的“毕竟”的特征向量相关联。
此外,因为用户话语“我自己收听”的长度是1.5秒,所以“1.5”被输入到特征向量的分量(图3中的vi7)。此外,因为对用户语音“我自己收听”的响应是“话语响应”,所以正确的标签“c”与用户话语“我自己收听”的特征向量相关联。此外,在一系列用户话语“毕竟我自己收听”中,用户状态(例如,关于用户的识别信息)是“用户状态#1”(例如,“用户a”)。因此,用户状态#1与对应于用户话语“毕竟我自己收听”的样本数据组相关联。
图6是图示从分类的样本数据组生成学习模型的模式的图。对于用户状态#1至#n中的每一个,以上述方式收集的样本数据组被分类为n个组。通过诸如监督学习的机器学习从用户状态#1的样本数据组(例如,对应于“用户a”的用户话语的样本数据组)生成学习模型#1。同样地,通过机器学习从用户状态#n的样本数据组(例如,对应于“用户n”的用户语音的样本数据组)生成学习模型#n。因为学习模型#1至#n的正确标签“a”、“b”和“c”的边界彼此不同,即使当将相同的特征向量输入到每个学习模型#1至#n中的每一个,要输出的响应可能不同。由此生成的多个学习模型被存储在学习模型数据库160中。用于生成学习模型的机器学习方法可以是例如随机森林、支持向量机(svm)或深度学习。
取决于用户状态定义学习模型的正确标签“a”、“b”和“c”的边界。例如,当用户状态是“积极性”时,因为学习模型对应于积极性程度大的用户状态,所以可以减少选择“说话”的概率并且“沉默”被选择的概率可能会增加。也就是说,会话中的积极性的程度很大意味着用户倾向于主动说话。在这种情况下,语音交互系统1被调整为不太频繁地说话,以便防止语音交互系统1的语音与用户的语音重叠。另一方面,当会话中的积极性的程度较小时,这意味着用户倾向于不会非常主动地说话。在这种情况下,语音交互系统1被调整为更频繁地说话以便抑制长时间的沉默。
此外,学习模型对应于由前述用户状态检测单元140检测到的用户状态。例如,当用户状态检测单元140检测到“积极性的程度”作为用户状态时,为每种积极性的程度提供多个学习模型。此外,当用户状态检测单元140检测到“关于用户的标识信息”作为用户状态时,为关于用户(用户a、用户b、……、用户n等等)的多条识别信息中的每一条提供多个学习模型。
图7和8是示出由根据第一实施例的语音交互系统1执行的语音交互方法的流程图。首先,话语获取单元102获取如上所述的用户话语(步骤s102)。如上所述,特征提取单元104分析关于所获取的用户话语的非语言信息(韵律信息和响应历史信息),并提取用户话语的特征(特征向量)(步骤s104)。
接下来,响应确定单元120使用当前学习模型(存储在所选模型存储单元108中的学习模型)根据提取的特征向量确定对用户话语的响应(步骤s110)。响应执行单元130执行在如上所述的s110中确定的响应(步骤s120)。
图8是示出s110的处理的流程图。响应确定单元120将提取的特征向量输入到学习模型(步骤s112)。响应确定单元120确定学习模型的输出(步骤s114)。
当输出是“沉默响应”(s114中的“沉默”)时,响应确定单元120确定执行沉默响应(步骤s116a)。也就是说,响应确定单元120确定不对与此特征向量对应的用户话语做任何事情。当输出是“点头响应”(s114中的“点头”)时,响应确定单元120确定执行点头响应(步骤s116b)。也就是说,响应确定单元120确定以机器人的颈部对于与此特征向量对应的用户话语垂直摆动的方式操作操纵器8。当输出是“话语响应”(s114中的“说话”)时,响应确定单元120确定执行话语响应(步骤s116c)。也就是说,响应确定单元120确定操作扬声器4以输出与此特征向量对应的用户话语的系统话语。
接下来,如上所述,用户状态检测单元140检测用户状态(步骤s130)。学习模型选择单元150选择与通过s130的处理检测到的用户状态相对应的学习模型(步骤s140)。更具体地,在当前学习模型与对应于检测到的用户状态的学习模型不同时,学习模型选择单元150将当前学习模型切换到与检测到的用户状态对应的学习模型。另一方面,在当前学习模型是与检测到的用户状态对应的学习模型时,学习模型选择单元150不改变学习模型。如上所述,根据第一实施例的学习模型选择单元150被配置成根据用户状态选择新学习模型,从而能够选择能够进一步改善响应的精度的学习模型。
在下文中,将解释用户状态的具体示例。第一示例是在用户状态是关于用户的标识信息的情况下的示例。第二示例是在用户状态是用户在会话中的积极性的程度的情况下的示例。第三示例是用户状态是用户的情绪的程度的情况下的示例。第四示例是在用户状态是用户的健康状况的程度的情况下的示例。第五示例是用户状态是用户的唤醒状态的程度的示例。
(用户状态的第一示例)
图9是示出其中用户状态是关于用户的标识信息的情况下的处理的图。图9示出在用户状态是关于用户的识别信息的情况下的s130和s140(图7)的具体处理。用户状态检测单元140从作为相机的检测装置6获取用户的图像(步骤s132a)。“图像”还可以指示对作为信息处理的目标的图像进行指示的图像数据(同样适用于以下描述)。
用户状态检测单元140对图像执行面部识别处理以检测关于用户的识别信息(步骤s134a)。更具体地,例如,用户状态检测单元140从图像确定用户的面部区域,执行面部特征点的检测,并确定诸如眼睛、鼻子、嘴的末端等的面部的特征点位置。然后,用户状态检测单元140使用特征点位置对面部区域的位置和大小进行标准化,并且然后利用预先已经注册的人的图像进行面部匹配处理。因此,用户状态检测单元140获取关于所匹配的人的识别信息。
接下来,学习模型选择单元150选择与检测到的识别信息对应的学习模型(步骤s142a)。假设对于关于用户的多条识别信息中的每一条,预先在学习模型数据库160中存储多个学习模型。例如,当用户状态检测单元140已经检测到关于“用户a”的识别信息时,学习模型选择单元150选择对应于“用户a”的学习模型。
如上所述,根据第一示例的语音交互系统1具有使用适合于用户的学习模型的会话,从而此语音交互系统1能够根据与此语音交互系统1进行会话的用户执行响应。因此,根据第一示例的语音交互系统1能够适当地处理情况,从而有效地防止发生响应错误。此外,发生响应错误意味着当前会话的节奏或韵律不适合用户。根据第一示例的语音交互系统1选择对应于用户的学习模型,从而能够使会话的节奏或韵律适合于此用户。
此外,在第一示例中,当生成学习模型时,关于用户的标识信息作为用户状态被关联。换句话说,为关于用户的多条识别信息中的每一条生成多个学习模型。当生成学习模型时,操作员输入例如关于用户的识别信息,由此样本数据和关于用户的识别信息彼此相关联。因此,针对关于用户的每条识别信息对样本数据进行分类,并且使用已经分类的样本数据通过机器学习生成多条学习数据。因此,例如,生成对应于用户a的学习模型、对应于用户b的学习模型、以及对应于用户c的学习模型。
虽然在前述示例中通过使用图像的面部识别处理来识别用户,但是识别用户的方法不限于此方法。可以通过对用户话语执行说话者识别处理(语音识别处理)来识别发出话语的用户。此外,可以通过输入关于用户的标识信息(id)来识别用户。
(用户状态的第二示例)
图10是示出在用户状态是用户在会话中的积极性的程度的情况下的处理的图。图10示出在用户状态是用户的积极性的程度的情况下的s130和s140(图7)的具体处理。用户状态检测单元140获取过去t分钟期间的用户话语百分比rs(步骤s132b)。符号t表示预定时段。虽然时间t例如是1[分钟],但是不限于此。“过去t分钟”意指从当前时间开始返回t分钟的时间到当前时间的时间段。用户话语百分比rs是用户发出话语的时间tu相对于语音交互系统1输出语音作为响应的时间tr[分钟]和用户在过去的t分钟内发出话语的时间tu[分钟]的总和tu+tr[分钟]的百分比。也就是说,rs[%]=100*tu/(tu+tr)。
用户状态检测单元140检测与用户话语百分比rs对应的积极性的程度(步骤s134b)。更具体地,用户状态检测单元140预先存储图11中所图示的表。用户状态检测单元140使用此表确定用户话语百分比rs对应于哪个积极性阶段。
图11是图示用于确定积极性的程度的表的图。在图11中所图示的表中,积极性的程度和用户话语百分比rs彼此相关联。在图11中所示的示例中,积极性的程度由从#1到#4的四个阶段定义。积极性的程度从#1度增加到#4度。用户状态检测单元140确定所获取的用户话语百分比rs对应于程度#1至#4中的哪一个。例如,当rs是20[%]时,用户状态检测单元140确定积极性的程度是#1。此外,当rs是80[%]时,用户状态检测单元140确定积极性的程度是#4。
接下来,学习模型选择单元150选择与已经检测到的积极性的程度相对应的学习模型(步骤s142b)。假设对于用户的积极性的每个程度,多个学习模型被预先存储在学习模型数据库160中。例如,当用户状态检测单元140已经检测到“积极性的程度#1”时,学习模型选择单元150选择对应于“积极性的程度#1”的学习模型。此外,当用户状态检测单元140已经检测到“积极性的程度#4”时,学习模型选择单元150选择对应于“积极性的程度#4”的学习模型。
虽然在前述描述中根据用户话语百分比确定用户的积极性的程度,但是可以根据用户给出的话语量来确定用户的积极性的程度。更具体地,用户状态检测单元140获取过去t分钟中的用户话语的量[分钟](s132b)。用户状态检测单元140检测与用户话语量对应的积极性的程度(s134b)。在这种情况下,以类似于图11中所图示的表格的方式,用户状态检测单元140可以存储用户话语量和积极性的程度(阶段)彼此相关联的表格。用户状态检测单元140可以使用此表确定用户话语量对应于积极性的哪个阶段。
如上所述,根据第二示例的语音交互系统1具有使用适合于用户在会话中的积极性的程度的学习模型的会话,由此此语音交互系统能够根据进行与此语音交互系统进行会话的用户的积极性执行响应。因此,根据第二示例的语音交互系统1能够适当地处理情况,使得有效地防止发生响应错误。此外,发生响应错误意味着当前会话的节奏或韵律不适合用户的积极性的程度。根据第二示例的语音交互系统1能够通过选择与用户的积极性的程度相对应的学习模型来使得会话的节奏或韵律适合于用户的积极性的程度。此外,用户在会话中的积极性的程度可以根据会话的主题等而变化。根据第二示例的语音交互系统1能够根据积极性的程度的变化来改变学习模型。
此外,在第二示例中,当生成学习模型时,用户的积极性程度作为用户状态被关联。换句话说,针对积极性的每种程度生成多个学习模型。当生成学习模型时,操作员输入例如用户在会话期间的积极性的程度,由此样本数据和用户积极性程度彼此相关联。此外,同样当生成学习模型时,如图10中所示,可以使用用户话语百分比或用户话语量来确定用户在会话期间的积极性的程度。在这种情况下,操作员可以适当地设置时段t。例如,当会话的主题已经改变时,可以计算用户的积极性的程度。
因此,针对用户的积极性的程度的每种程度对样本数据进行分类,并且使用已经分类的样本数据通过机器学习生成多条学习数据。因此,例如,对应于积极性的程度#1的学习模型、对应于积极性的程度#2的学习模型、对应于积极性的程度#3的学习模型、以及对应积极性的程度#4的学习模型被生成。
如上所述,取决于用户状态定义学习模型的正确标签“a(沉默)”、“b(点头)”和“c(说话)”的边界。当用户状态是“积极性”时,因为学习模型对应于积极性的程度较大的用户状态,可以减少选择“说话”的概率,并且可以增加选择“沉默”的概率。也就是说,学习模型以下述方式被生成,即,在学习模型#4(程度#4)中选择“a(沉默)”的概率变得高于在学习模型(程度#1)中选择“a(沉默)”的概率。因此,在与其积极性的程度较大的用户进行会话期间,可以调整语音交互系统1以不频繁地讲话,以防止话语重叠。此外,在与其积极性的程度较小的用户的会话期间,可以调整语音交互系统1以更加频繁地说话以防止长时间的沉默。
虽然在前述示例中使用用户话语百分比或用户话语量来检测用户在会话中的积极性的程度,但是检测用户的积极性的程度的方法不限于此方法。用户状态检测单元140可以通过获取例如用户的图像来检测积极性的程度。更具体地,用户状态检测单元140可以通过分析用户的表情和用户的面部图像中指示的视线来确定用户的积极性,并且数字化积极性的程度。此外,用户状态检测单元140可以通过获取例如用户话语来检测积极性程度。更具体地,用户状态检测单元140可以分析用户话语的韵律,确定用户的积极性,并且数字化积极性的程度。然而,如上所述,通过使用用户话语百分比或用户话语量确定积极性程度,能够更准确地确定用户的积极性的程度。因此,通过使用用户话语百分比或用户话语量,根据第二示例的语音交互系统1能够更适当地处理情况以防止发生响应错误。
(用户状态的第三示例)
图12是示出在用户状态是用户的情绪的情况下的处理的图。图12示出在用户状态是用户的情绪的程度的情况下的s130和s140(图7)的具体处理。“情绪的程度”例如是“喜悦”的程度。例如,“情绪的程度”可以是愤怒的程度、悲伤的程度或惊讶的程度。
用户状态检测单元140从作为相机的检测装置6获取用户的面部图像(步骤s132c)。用户状态检测单元140分析面部图像并从他/她的表情、视线等中检测用户的情绪(喜悦)的程度(步骤s134c)。例如,用户状态检测单元140可以使用诸如“affdex”或“情绪api”的人工智能来数字化用户的情绪(喜悦)。然后,用户状态检测单元140可以使用指示情绪的数值和情绪的程度彼此相关联的表格来检测情绪的程度,如图11中所图示。
接下来,学习模型选择单元150选择与已经检测到的情绪(喜悦)的程度相对应的学习模型(步骤s142c)。假设对于用户的情绪的每种程度,预先在学习模型数据库160中存储多个学习模型。例如,当用户状态检测单元140检测到“情绪(喜悦)的程度#1”时,学习模型选择单元150选择对应于“情绪(喜悦)的程度#1”的学习模型。此外,当用户状态检测单元140检测到“情绪(喜悦)的程度#4”时,学习模型选择单元150选择对应于“情绪(喜悦)的程度#4”的学习模型。
如上所述,根据第三示例的语音交互系统1具有使用适合于用户在会话中的情绪的程度的学习模型的会话,由此此语音交互系统1能够根据进行与此语音交互系统1的会话的用户的情绪做出响应。因此,根据第三示例的语音交互系统1能够适当地处理情况,从而有效地防止发生响应错误。此外,发生响应错误意味着当前会话的节奏或韵律不适合用户的情绪的程度。根据第三示例的语音交互系统1能够通过选择与用户的情绪的程度相对应的学习模型来使得会话的节奏或韵律适合于用户的情绪的程度。此外,用户在会话中的情绪的程度可以根据会话的主题等而变化。根据第三示例的语音交互系统1能够根据情绪的程度的变化来改变学习模型。
此外,在第三示例中,当生成学习模型时,用户的情绪的程度作为用户状态被关联。换句话说,例如,针对情绪的每种程度生成多个学习模型。当生成学习模型时,操作员输入用户在会话期间的情绪的程度,由此样本数据和用户的情绪的程度彼此相关联。此外,当生成学习模型时,也可以使用用户的面部图像来确定用户在会话期间的情绪的程度。
因此,针对用户的情绪的每种程度对样本数据进行分类,并且使用已经分类的样本数据通过机器学习生成多个学习数据。因此,例如,对应于情绪的程度#1的学习模型、对应于情绪的程度#2的学习模型、对应于情绪的程度#3的学习模型、以及对应于情绪的程度#4的学习模型被生成。
虽然在前述示例中使用用户的面部图像来检测用户的情绪的程度,但是检测用户的情绪的程度的方法不限于此方法。用户状态检测单元140可以通过例如获取用户话语来检测情绪的程度。更具体地,用户状态检测单元140可以通过分析用户话语的韵律并将情绪的程度数字化来确定用户的情绪。
此外,在上述示例中,用户状态检测单元140检测情绪的程度。然而,用户状态检测单元140可以检测情绪的类型,即,喜悦、悲伤、愤怒、惊讶等。更具体地,用户状态检测单元140分别检测指示喜悦、悲伤、愤怒和惊讶的数值。然后,用户状态检测单元140可以检测与这些数值中的最大值对应的情绪(例如,“愤怒”)作为用户的情绪。在这种情况下,为每种类型的情绪提供多个学习模型。然后,学习模型选择单元150可以根据已经检测到的情绪的类型(例如,“愤怒”)来选择学习模型。
此外,用户状态检测单元140可以检测每种类型的情绪的程度。在这种情况下,学习模型数据库160可以存储例如在愤怒的程度是x1并且惊讶的程度是y1的情况下的学习模型、在愤怒的程度是x1并且惊讶的程度是y2的情况下的学习模型、在愤怒的程度是x2并且惊讶的程度是y1的情况下的学习模型、以及在愤怒的程度是x2和惊讶的程度是y2的情况下的学习模型。然后,学习模型选择单元150可以选择与已经检测到的愤怒的程度和惊讶的程度相对应的学习模型。
(用户状态的第四示例)
图13是示出在用户状态是用户的健康状况的情况下的处理的图。图13示出在用户状态是用户的健康状况的程度的情况下的s130和s140(图7)的具体处理。“健康状况的程度”是例如心率的程度。“健康状况的程度”可以替代地是血压的程度、体温的程度等。
用户状态检测单元140从作为生物传感器的检测装置6获取用户的生物系统参数(步骤s132d)。生物系统参数例如是心率。用户状态检测单元140从生物系统参数检测用户的健康状况的程度(步骤s134d)。用户状态检测单元140可以通过使用例如其中指示健康状况的数值(心率)和健康状况的程度彼此相关联的表来检测健康状况的程度,如图11中所图示。
接下来,学习模型选择单元150选择与已经检测到的健康状况(心率)的程度相对应的学习模型(步骤s142d)。假设对于用户的健康状况的每种程度,多个学习模型被预先存储在学习模型数据库160中。例如,当用户状态检测单元140检测到“健康状况(心率)的程度#1”时,学习模型选择单元150选择对应于“健康状况(心率)的程度#1”的学习模型。此外,当用户状态检测单元140已经检测到“健康状况(心率)的程度#4”时,学习模型选择单元150选择对应于“健康状况(心率)的程度#4”的学习模型率)。
如上所述,根据第四示例的语音交互系统1使用适合于用户的健康状况的程度的学习模型与用户进行会话,由此,该语音交互系统1能够执行根据进行会话的用户的健康状况而执行反应。因此,根据第四示例的语音交互系统1能够适当地处理情况,以便有效地防止发生响应错误。此外,发生响应错误意味着当前会话的节奏或韵律不适合用户的健康状况的程度。根据第四示例的语音交互系统1选择与用户的健康状况的程度相对应的学习模型,从而能够使会话的节奏或韵律适合于用户的健康状况的程度。此外,用户的心率等可以取决于会话的主题等而变化。根据第四示例的语音交互系统1能够根据诸如心率的健康状况的程度的改变来改变学习模型。
此外,在第四示例中,当生成学习模型时,用户的健康状况的程度作为用户状态被关联。换句话说,针对健康状况的每种程度生成多个学习模型。当生成学习模型时,使用例如生物传感器输入会话期间用户的健康状况的程度,由此样本数据和用户的健康状况的程度彼此相关联。
因此,针对用户的健康状况的每种程度对样本数据进行分类,并且使用已经分类的样本数据通过机器学习生成多个学习数据。因此,例如,对应于健康状况的程度#1的学习模型、对应于健康状况的程度#2的学习模型、对应于健康状况的程度#3的学习模型、以及对应于健康状况的程度#4的学习模型被生成。
虽然在前述示例中使用生物识别传感器检测用户的健康状况的程度,但是检测用户的健康状况的程度的方法不限于此方法。用户状态检测单元140可以通过从作为相机的检测装置6获取例如用户的面部图像来检测用户的健康状况的程度。在这种情况下,用户状态检测单元140可以通过分析面部图像来检测用户的面部颜色(红色、蓝色、白色、黄色或黑色)。然后,用户状态检测单元140可以取决于用户的面部的颜色接近红色、蓝色、白色、黄色和黑色的哪种颜色来检测健康状况。在这种情况下,针对用户的面部的每种颜色存储多个学习模型。
此外,用户状态检测单元140可以从多个生物系统参数(心率、血压和体温)确定用户的健康状况是好还是坏、或者用户的疲劳程度。此外,用户状态检测单元140可以确定心率、血压和体温中的每一个是否在预定的正常范围内,并取决于已经超出正常范围的生物系统参数的数量确定健康状况的程度(健康状况是好还是差)。
(用户状态的第五示例)
图14是示出在用户状态是用户的唤醒状态的程度的情况下的处理的图。图14示出在用户状态是用户的唤醒状态的程度的情况下的s130和s140(图7)的具体处理。
用户状态检测单元140从作为相机或生物传感器的检测装置6获取用户的生物系统参数(步骤s132e)。生物系统参数例如是眨眼、心跳和脑波中的至少一种。可以通过分析从相机获取的用户的面部图像来获取眨眼。可以通过分别使用作为生物传感器的心率计和脑电图仪来获取心跳和脑电波。
用户状态检测单元140从生物系统参数检测用户的唤醒状态的程度(步骤s134e)。用户状态检测单元140根据前述生物系统参数计算例如唤醒程度。用户状态检测单元140可以例如根据眨眼之间的间隔、用户在眨眼期间打开他/她的眼睛的时间、眼睛的打开程度等来计算唤醒程度。然后,用户状态检测单元140可以使用其中唤醒程度和唤醒状态程度彼此相关联的表来检测唤醒状态的程度,如图11中所图示。
接下来,学习模型选择单元150选择与已经检测到的唤醒状态的程度相对应的学习模型(步骤s142e)。假设针对用户的唤醒状态的每种程度,将多个学习模型预先存储在学习模型数据库160中。例如,当用户状态检测单元140已经检测到“唤醒状态的程度#1”时,学习模型选择单元150选择对应于“唤醒状态的程度#1”的学习模型。此外,当用户状态检测单元140已经检测到“唤醒状态的程度#4”时,学习模型选择单元150选择对应于“唤醒状态的程度#4”的学习模型。
如上所述,根据第五示例的语音交互系统1具有使用适合于用户的唤醒状态程度的学习模型的会话,由此上述语音交互系统1能够根据其进行会话的用户的唤醒状态进行响应。因此,根据第五示例的语音交互系统1能够适当地处理情况,以便有效地防止发生响应错误。此外,发生响应错误意味着当前会话的节奏或韵律不适合用户的唤醒状态的程度。根据第五示例的语音交互系统1能够通过选择与用户的唤醒状态的程度相对应的学习模型来使会话的节奏或韵律适合于用户的唤醒状态的程度。此外,用户的唤醒程度可以取决于会话的主题等而变化。根据第五示例的语音交互系统1能够根据唤醒程度的变化来改变学习模型。
此外,在第五示例中,当生成学习模型时,用户的唤醒状态的程度作为用户状态被关联。换句话说,针对唤醒状态的每种程度生成多个学习模型。当生成学习模型时,使用例如相机或生物传感器输入会话期间用户的唤醒状态的程度,由此样本数据和用户的唤醒状态的程度彼此相关联。
因此,针对用户的唤醒状态的每种程度对样本数据进行分类,并且使用已经分类的样本数据通过机器学习生成多个学习数据。因此,例如,对应于唤醒状态的程度#1的学习模型、对应于唤醒状态的程度#2的学习模型、对应于唤醒状态的程度#3的学习模型、以及对应于唤醒状态的程度#4的学习模型被生成。
虽然在前述示例中使用相机或生物传感器检测用户的唤醒状态的程度,但是检测用户的唤醒状态的程度的方法不限于此方法。用户状态检测单元140可以通过获取用户话语来检测唤醒状态的程度。更具体地,用户状态检测单元140可以分析用户话语的韵律,确定用户的唤醒状态,并且数字化唤醒状态的程度。
(第二实施例)
接下来,将解释第二实施例。第二实施例与第一实施例的不同之处在于语音交互系统1生成多个学习模型。因为根据第二实施例的语音交互系统1的硬件配置基本上类似于根据图1中所示的第一实施例的语音交互系统1的硬件配置,所以将省略其描述。
图15是示出根据第二实施例的语音交互系统1的配置的框图。根据第二实施例的语音交互系统1包括话语获取单元102、特征提取单元104、所选模型存储单元108、响应数据库110、响应确定单元120、响应执行单元130和响应历史存储单元132。此外,根据第二实施例的语音交互系统1包括用户状态检测单元140、学习模型选择单元150和学习模型数据库160。语音交互系统1还包括学习模型生成装置200。因为除了学习模型生成装置200之外的组件具有与第一实施例中描述的组件基本类似的功能,所以将省略其描述。
学习模型生成装置200通过稍后描述的方法生成多个学习模型。由学习模型生成装置200生成的多个学习模型存储在学习模型数据库160中。学习模型可以由学习模型生成装置200自动存储,或者由诸如操作员的工作人员手动存储。
学习模型生成装置200不必与其他组件物理地集成。也就是说,其中提供其他组件的装置(诸如机器人)和其中提供学习模型生成装置200的装置(诸如计算机)可以不相同。下面将解释学习模型生成装置200的具体配置。学习模型生成装置200的处理(稍后将说明的图17中所示的处理)对应于图4-图6并且在与用户的会话之前的阶段(图7中所示的处理)执行。
图16是示出根据第二实施例的学习模型生成装置200的配置的图。此外,图17是示出由根据第二实施例的学习模型生成装置200执行的学习模型生成方法的流程图。学习模型生成装置200包括话语获取单元212、特征提取单元214、样本数据生成单元216、用户状态获取单元218、样本数据分类单元220和学习模型生成单元222。模型生成装置200可以独立地具有与图1所示的语音交互系统1的硬件配置基本相似的硬件配置。
话语获取单元212通过与期望用户的会话,以与图7中的s102的处理的方式类似的方式获取用户话语,该用户话语是由一个或多个期望用户给出的话语(步骤s202)。“期望用户”不限于与语音交互系统1进行会话的用户,并且可以是期望的用户。特征提取单元214以与图7中的s104的处理的方式类似的方式提取至少指示所获取的用户话语的特征的特征向量(步骤s204)。
接下来,样本数据生成单元216生成其中指示对用户话语的响应的正确标签和特征向量彼此相关联的样本数据(步骤s206)。更具体地,如上面参考图4所述,样本数据生成单元216将由操作员确定的响应(正确标签)与相应用户话语的特征向量相关联。因此,样本数据生成单元216生成样本数据。只要能够自动确定正确标签,样本数据生成单元216可以从用户话语中自动确定正确标签(响应),并将已经确定的正确标签与用户话语的特征向量相关联。接下来,学习模型生成装置200(或图2中所示的响应执行单元130)以与图7中的s120的处理的方式类似的方式执行响应(步骤s208)。
用户状态获取单元218获取用户状态,该用户状态是用户已经发出话语时的期望用户状态,并且将所获取的用户状态与对应于用户话语的样本数据相关联(步骤s210)。更具体地,用户状态获取单元218可以使用用户的图像、用户话语、生物系统参数等来获取期望用户的用户状态,如参考图9至图14所述。取决于用户状态的类型(第一到第五示例),获取用户状态的方法可以彼此不同。可替选地,用户状态获取单元218可以获取例如由操作员确定的期望用户的用户状态。然后,用户状态获取单元218将所获取的用户状态与对应于由期望用户发出的话语的样本数据相关联。
学习模型生成装置200确定是否结束用户话语的获取(步骤s212)。当应继续对用户话语的获取时(s212中的否),学习模型生成装置200重复s202-s210的处理。另一方面,当因为已经获取足够量的样本数据而结束对用户话语的获取(s212中的是)时,样本数据分类单元220针对每种用户状态对样本数据进行分类,如参考图6所述(步骤s220)。然后,学习模型生成单元222通过例如针对每条分类的样本数据的诸如随机森林或支持向量机的机器学习而生成多个学习模型,如上面参考图6所述(步骤s222)。
如上所述,根据第二实施例的学习模型生成装置200针对每种用户状态对样本数据进行分类,并通过机器学习生成多个学习模型,由此此学习模型生成装置能够生成与用户状态相对应的多个学习模型。因此,语音交互系统1能够根据用户状态选择学习模型,如上所述。
(变型示例)
本公开不限于前述实施例,并且可以在不脱离本公开的精神的情况下适当地改变。例如,在上述流程图中,可以适当地改变多个处理的顺序。此外,在上述流程图中,可以省略多个处理中的一个。例如,可以在s102和s120之间执行图7中的s130的处理。
此外,参考图9至图14描述的用户状态的第一至第五示例可以互相适用。也就是说,用户状态检测单元140可以检测多种类型的用户状态。然后,学习模型选择单元150选择与已经检测到的多种类型的用户状态相对应的学习模型。用户状态检测单元140可以检测例如关于用户的识别信息和用户的积极性的程度。在这种情况下,学习模型数据库160可以存储例如针对用户a的积极性的每种程度和用户b的积极性的每种程度的多个学习模型。当用户状态检测单元140已经检测到“用户a”的“积极性的程度#1”时,学习模型选择单元150可以选择与“用户a”的“积极性的程度#1”对应的学习模型。
虽然在前述实施例中从用户话语的韵律信息等生成特征向量(图3),但是此配置仅是示例。特征向量的分量不限于与韵律相关的分量,并且可以包括从作为相机的检测设备6获取的用户的特征。特征向量的分量可以包括例如用户的视线以及交互机器人和用户之间的距离。
此外,虽然在前述实施例中图示语音交互系统1安装在机器人中的示例,但是此配置仅是示例。语音交互系统1可以安装在诸如智能手机或平板终端的信息终端中。在这种情况下,当执行“点头响应”时,例如,人、动物、机器人等点头的视频图像可以显示在信息终端的显示屏上,而不是操作操纵器8。
在以上示例中,能够使用任何类型的非暂时性计算机可读介质来存储程序并将其提供给计算机。非暂时性计算机可读介质包括任何类型的有形存储介质。非暂时性计算机可读介质的示例包括磁存储介质(诸如软盘、磁带、硬盘驱动器等)、光磁存储介质(例如,磁光盘)、cd-rom、cd-r、cd-r/w和半导体存储器(诸如掩模rom、prom(可编程rom)、eprom(可擦除prom)、闪存rom、ram等)。可以使用任何类型的暂时性计算机可读介质将程序提供给计算机。暂时性计算机可读介质的示例包括电信号、光信号和电磁波。暂时性计算机可读介质能够经由有线通信线路(例如,电线和光纤)或无线通信线路将程序提供给计算机。
从如此描述的公开内容,将会显而易见的是,本公开的实施例可以以多种方式变化。不应将这些变化视为脱离本公开的精神和范围,并且对于本领域的技术人员来说显而易见的是,所有这些变型旨在包括在所附权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!