一种自学习语音识别系统的构建装置和构建方法与流程
本发明涉及声音识别技术领域,尤其涉及一种自学习语音识别系统的构建装置和构建方法。
背景技术:
随着计算机应用技术的快速发展,语音或者其他类型声音识别技术的应用越来越广泛,对声音识别的需求也越来越多。目前的超高清智能电视,智能音箱在待机的期间,仍然需要保留语音唤醒功能,因此语音识别系统仍然需要工作,即电源模块,adc(analog-to-digitalconverter,模数转换器),cpu(centralprocessingunit,中央处理器)都还在工作模式,使得待机过程中消耗大量能源。
技术实现要素:
针对现有技术中存在的上述问题,现提供一种旨在降低待机过程中的能源消耗的自学习语音识别系统的构建装置。
具体技术方案如下:
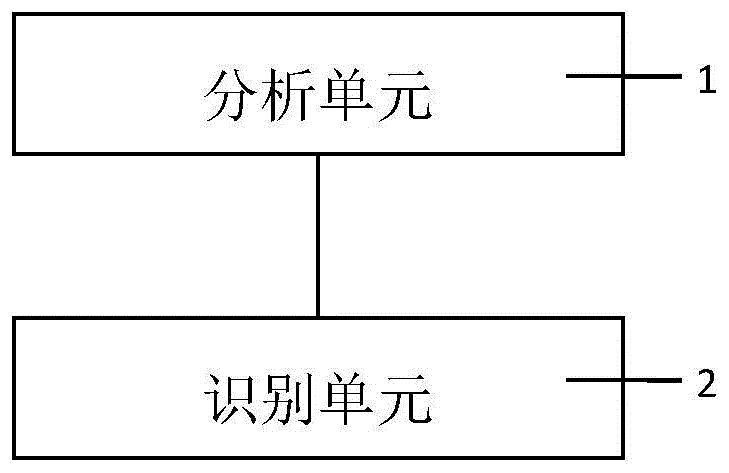
一种自学习语音识别系统的构建装置,应用于语音识别系统中,语音识别系统包括麦克风和应用有构建装置的语音识别模块,麦克风和语音识别模块连接,其中,构建装置包括:
分析单元,用于将麦克风的输出信号进行分析以得到多个信号参数;
识别单元,与分析单元连接,根据信号参数判断输出信号是否为预设的激活语音。
优选的,自学习语音识别系统的构建装置,其中,输出信号为波形信号。
优选的,自学习语音识别系统的构建装置,其中,分析单元将每个类型的信号参数依次保存到对应的序列中,并将每个序列的信号参数输出到识别单元中。
优选的,自学习语音识别系统的构建装置,其中,
识别单元为神经网络,神经网路包括:
第一计算单元,用于根据多个序列的信号参数输出第一输出参数;
第二计算单元,用于根据多个序列的信号参数输出第二输出参数;
第三计算单元,用于根据对应序列的信号参数输出第三输出参数;
第四计算单元,用于根据对应序列的信号参数输出第四输出参数;
隐层,包括多个第一节点,每个第一节点均与第一计算单元、第二计算单元、第三计算单元和第四计算单元连接,每个第一节点设置一个激活语音的一个特征信息,第一节点接收并判断第一输出参数、第二输出参数、第三输出参数和第四输出参数是否符合对应的特征信息,并将判断结果输出;
输出层,包括多个第二节点,每个第二节点与每个第一节点连接,每个第二节点设置对应的一个激活语音,根据判断结果判断输出信号是否符合激活语音。
优选的,自学习语音识别系统的构建装置,其中,信号参数的类型包括波谷、波峰、以及相邻的波谷和波峰之间的间隔时间。
优选的,自学习语音识别系统的构建装置,其中,第一输出参数为包络值;和/或
第二输出参数为相邻的波谷和波峰组成的波沿的数量;和/或
第三输出参数为相邻的两个波谷的差;和/或
第四输出参数为相邻的两个波峰的差。
优选的,自学习语音识别系统的构建装置,其中,
第一计算单元通过波谷、波峰和间隔时间进行计算得到包络值;和/或
第二计算单元通过波谷和波峰进行计算得到相邻的波谷和波峰组成的波沿的数量;和/或
第三计算单元通过波谷进行计算得到相邻的两个波谷的差;和/或
第四计算单元通过波峰进行计算得到相邻的两个波峰的差。
还包括一种自学习语音识别系统的构建方法,应用于语音识别系统中,语音识别系统包括麦克风和应用有构建装置的语音识别模块,麦克风和语音识别模块连接,其中,构建方法包括以下步骤:
步骤s1,将麦克风的输出信号进行分析以得到多个信号参数;
步骤s2,根据信号参数判断输出信号是否为预设的激活语音。
优选的,自学习语音识别系统的构建装置,其中,
步骤s2中,提供一神经网络,通过神经网络判断输出信号是否为预设的激活语音。
优选的,自学习语音识别系统的构建装置,其中,神经网路包括:
第一计算单元,用于根据波谷、波峰和间隔时间输出包络值;
第二计算单元,用于根据波谷和波峰输出相邻的波谷和波峰组成的波沿的数量;
第三计算单元,用于根据波谷输出相邻的两个波谷的差;
第四计算单元,用于根据波峰输出相邻的两个波峰的差;
隐层,包括多个第一节点,每个第一节点均与第一计算单元、第二计算单元、第三计算单元和第四计算单元连接,每个第一节点设置一个激活语音的一个特征信息,第一节点接收并判断包络值、波沿的数量、相邻的两个波谷的差和相邻的两个波峰的差是否符合对应的特征信息,并将判断结果输出;
输出层,包括多个第二节点,每个第二节点与每个第一节点连接,每个第二节点设置对应的激活语音,根据判断结果判断输出信号是否符合激活语音;
步骤s2包括以下步骤:
步骤s21,通过波谷、波峰和间隔时间进行计算得到包络值;和
通过波谷和波峰进行计算得到相邻的波谷和波峰组成的波沿的数量;和
通过波谷进行计算得到相邻的两个波谷的差;和
通过波峰进行计算得到相邻的两个波峰的差;
步骤s22,每个第一节点接收并将判断包络值、波沿的数量、相邻的两个波谷的差和相邻的两个波峰的差是否符合特征信息,并将判断结果输出;
步骤s23,每个第二节点根据判断结果判断输出信号是否符合激活语音,并输出判断结果。
上述技术方案具有如下优点或有益效果:通过激活语音进行唤醒工作,从而实现在待机过程中的电源模块、adc和cpu进行睡眠,以降低待机过程中的能源消耗。
附图说明
参考所附附图,以更加充分的描述本发明的实施例。然而,所附附图仅用于说明和阐述,并不构成对本发明范围的限制。
图1为本发明自学习语音识别系统的构建装置实施例的结构示意图;
图2为本发明自学习语音识别系统的构建装置实施例的神经网络的结构示意图;
图3为本发明自学习语音识别系统的构建方法实施例的流程图;
图4为本发明自学习语音识别系统的构建方法实施例步骤s2的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
本发明包括一种自学习语音识别系统的构建装置,应用于语音识别系统中,语音识别系统包括麦克风和应用有构建装置的语音识别模块,麦克风和语音识别模块连接,如图1所示,构建装置包括:
分析单元,用于将麦克风的输出信号进行分析以得到多个信号参数;
识别单元,与分析单元连接,根据信号参数判断输出信号是否为预设的激活语音。
在上述实施例中,通过识别单元识别分析单元中的信号参数是否为预设的激活语音,通过激活语音进行唤醒工作,从而实现在待机过程中的电源模块、adc和cpu进行睡眠,以降低待机过程中的能源消耗。
其中,预设的激活语音可以为预设数量,其中预设数量可以2个、3个、4个,由于预设的激活语音是根据隐层中的第一节点获得的,因此预设的激活语音不要太多,以降低能源消耗。
进一步地,在上述实施例中,输出信号为波形信号。从而可以在波形信号中获取多个信号参数,例如,上述信号参数的类型可以包括波谷、波峰、以及相邻的波谷和波峰之间的间隔时间。
进一步地,在上述实施例中,分析单元可以将每个类型的信号参数依次保存到对应的序列中,并将每个序列的信号参数输出到识别单元中。
例如,波谷所在的序列可以为{drop1,drop2,……dropn},其中,drop用于表示波谷;
波峰所在的序列可以为{rise1,rise2,……risen},其中,rise用于表示波峰;
间隔时间所在的序列可以为{t1,t2,……tn},其中,t用于表示间隔时间。
进一步地,在上述实施例中,识别单元可以为神经网络,如图2所示,神经网路包括:
第一计算单元10,用于根据多个序列的信号参数输出第一输出参数;
第二计算单元20,用于根据多个序列的信号参数输出第二输出参数;
第三计算单元30,用于根据对应序列的信号参数输出第三输出参数;
第四计算单元40,用于根据对应序列的信号参数输出第四输出参数;
隐层,包括多个第一节点50,每个第一节点50均与第一计算单元10、第二计算单元20、第三计算单元30和第四计算单元40连接,每个第一节点50设置一个激活语音的一个特征信息,第一节点50接收并判断第一输出参数、第二输出参数、第三输出参数和第四输出参数是否符合对应的特征信息,并将判断结果输出;
输出层,包括多个第二节点60,每个第二节点60与每个第一节点50连接,每个第二节点60设置对应的一个激活语音,根据判断结果判断输出信号是否符合激活语音。
其中,上述隐层的数量可以根据用户的需求进行自设定。
在上述神经网络中,每一个节点都可以为滤波器。
进一步地,作为优选的实施方式,第一输出参数为包络值;
第二输出参数为相邻的波谷和波峰组成的波沿的数量;
第三输出参数为相邻的两个波谷的差;
第四输出参数为相邻的两个波峰的差。并且第一计算单元10通过波谷、波峰和间隔时间进行计算得到包络值;
第二计算单元20通过波谷和波峰进行计算得到相邻的波谷和波峰组成的波沿的数量;
第三计算单元30通过波谷进行计算得到相邻的两个波谷的差;
第四计算单元40通过波峰进行计算得到相邻的两个波峰的差。
其中,需要说明的是,上述相邻的两个波谷的差为波谷序列中的前一个波谷减去后一个波谷的差;上述相邻的两个波峰的差为波峰序列中的前一个波峰减去后一个波峰的差。
进一步地,神经网络可以设定多个预设的激活语音进行训练,将上述预设的激活语音对应的输出信号中的信号参数输入到神经网络中,神经网络中的第一计算单元10根据波谷、波峰和间隔时间进行计算得到包络值,第二计算单元20根据波谷和波峰进行计算得到相邻的波谷和波峰组成的波沿的数量,第三计算单元30根据波谷进行计算得到相邻的两个波谷的差,第四计算单元40根据波峰进行计算得到相邻的两个波峰的差,隐层中的每个第一节点50接收并将判断包络值、波沿的数量、相邻的两个波谷的差和相邻的两个波峰的差是否符合特征信息,并将判断结果输出,输出层中的每个第二节点60根据判断结果判断输出信号是否符合激活语音,并输出判断结果当输出信号为对应的激活语音时,重复输入预设的激活语音对应的输出信号中的信号参数进行训练;当输出信号不为对应的激活语音时,调整判断结果对应的第一节点50的权值,继续输入该输出信号中的信号参数进行训练,直至输出层判断该输出信号为对应的激活语音时,输入其他预设的激活语音对应的输出信号中的信号参数进行训练,从而实现预测得到输出信号对应的激活语音。
可以通过逻辑值来表示判断结果,例如,预设的激活语音在对应的第二节点60中的逻辑值为1010101010,在神经网络中输入上述预设的激活语音对应的输出信号中的信号参数,隐层中的每个第一节点50接收并将判断输出参数是否符合特征信息,当输出参数符合特征信息时,输出判断结果对应的逻辑值为1;当输出参数不符合特征信息时,输出判断结果对应的逻辑值为0;输出层的第二节点60根据接收到的判断结果判断输出信号是否符合预设的激活语音,当判断结果为对应的逻辑值1010101010时,第二节点60输出判断结果对应的逻辑值为1,以表示输出信号符合上述预设的激活语音;当判断结果不为对应的逻辑值1010101010时,第二节点60输出判断结果对应的逻辑值为0,以表示输出信号不符合上述预设的激活语音。
还包括一种自学习语音识别系统的构建方法,应用于语音识别系统中,语音识别系统包括麦克风和应用有构建装置的语音识别模块,麦克风和语音识别模块连接,如图4所示,构建方法包括以下步骤:
步骤s1,将麦克风的输出信号进行分析以得到多个信号参数;
步骤s2,根据信号参数判断输出信号是否为预设的激活语音。
在上述实施例中,通过分析信号参数是否为预设的激活语音,通过激活语音进行唤醒工作,从而实现在待机过程中的电源模块、adc和cpu进行睡眠,以降低待机过程中的能源消耗。
进一步地,在上述实施例中,步骤s2中,提供一神经网络,通过神经网络判断输出信号是否为预设的激活语音。
神经网路包括:
第一计算单元10,用于根据波谷、波峰和间隔时间输出包络值;
第二计算单元20,用于根据波谷和波峰输出相邻的波谷和波峰组成的波沿的数量;
第三计算单元30,用于根据波谷输出相邻的两个波谷的差;
第四计算单元40,用于根据波峰输出相邻的两个波峰的差;
隐层,包括多个第一节点50,每个第一节点50均与第一计算单元10、第二计算单元20、第三计算单元30和第四计算单元40连接,每个第一节点50设置一个激活语音的一个特征信息,第一节点50接收并判断包络值、波沿的数量、相邻的两个波谷的差和相邻的两个波峰的差是否符合对应的特征信息,并将判断结果输出;
输出层,包括多个第二节点60,每个第二节点60与每个第一节点50连接,每个第二节点60设置对应的激活语音,根据判断结果判断输出信号是否符合激活语音;
步骤s2包括以下步骤:
步骤s21,通过波谷、波峰和间隔时间进行计算得到包络值;和
通过波谷和波峰进行计算得到相邻的波谷和波峰组成的波沿的数量;和
通过波谷进行计算得到相邻的两个波谷的差;和
通过波峰进行计算得到相邻的两个波峰的差;
步骤s22,每个第一节点50接收并将判断包络值、波沿的数量、相邻的两个波谷的差和相邻的两个波峰的差是否符合特征信息,并将判断结果输出;
步骤s23,每个第二节点60根据判断结果判断输出信号是否符合激活语音,并输出判断结果。
以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!