一种面向瞬态噪声抑制的实时语音增强方法与流程
本发明涉及语音增强技术领域,特别是涉及一种面向瞬态噪声抑制的实时语音增强方法。
背景技术:
语音增强算法研究一直是语音领域的热门方向,早期的单通道语音增强算法主要研究如何从含噪语音中有效估计噪声谱,从而对其进行抑制。近年来,随着深度学习的概念的提出,以及在语音识别领域的成功应用,使得基于监督学习的语音增强算法开始体现价值。dnn网络,cnn网络,lstm网络,gan网络等都被用来实现语音增强。这些监督学习模型在充分训练的情况下,体现了比传统增强方法优越的性能。
但是,由于存在数据标注和采集上的困难,以及模型复杂度高等问题,目前基于监督学习算法的语音增强实际应用较少。经典算法的应用依然比较广泛。谱减法是最早出现的降噪算法,其一般需要先对带噪语音进行语音端点的检测,在不含语音的静音段使用噪声估计算法得到噪声的功率谱然后进行谱减处理。但是如果对噪声功率谱欠估计,则有可能引入新的音乐噪声,而过估计则会造成语音有效信息的丢失,引起失真。而维纳滤波方法增强后的残留噪声类似于高斯白噪声,对人的听感而言要优于谱减法,但是增强后的语音失真问题仍然存在。上世纪八十年代,ephraim等人根据贝叶斯准则推导出了最小均方误差(minimummeansquareerror,mmse)估计器公式,此算法具有最优幅度谱估计,因为尽可能的保证了语音不失真。后来,根据频谱幅度的对数值是和耳朵对声音的响度感知成正比这一特点,他们再次提出了基于对数幅度谱估(log-spectralamplitude,lsa)的mmse方法。此外,chen和loizou又提出了最小控制的迭代平均的(minimacontrolledrecursiveaveraging,mcra)噪声估计算法和基于最优化修正对数谱幅度估计(optimal-modifiedlog-spectralamplitude,om-lsa)的估计器。这些算法主要研究加性背景噪声,并基于噪声和纯净语音间的复杂的统计特性进行设计,通常需要假设噪声信号是相对平稳的或变化很缓慢。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供了一种面向瞬态噪声抑制的实时语音增强方法,该方法采用分位噪声估计法来获得稳态噪声谱,基于信号重心检测瞬态噪声,并根据是否存在瞬态噪声来修正稳态噪声谱;并结合语音特征和谐波分析来估计语音存在概率;最后,在语音概率估计的基础上,计算信号增益并作用于含噪语音,能够更好地实现语音增强。
技术方案:为实现上述目的,本发明采用如下技术方案:
一种面向瞬态噪声抑制的实时语音增强方法,其特征在于,包括以下步骤:
步骤1)、对含噪语音进行分帧和加窗预处理,求出幅度谱;
步骤2)、采用分位噪声估计法获得稳态噪声谱;
步骤3)、采用基于信号重心检测法来获得瞬态噪声,并根据是否存在瞬态噪声来修正稳态噪声谱;
步骤4)、采用基于语音特征的方法估计语音存在概率一;
步骤5)、采用谐波分析的方法估计语音存在概率二;
步骤6)、综合步骤5)和步骤6)获得的两个语音存在概率,计算增益,并进行语音增强。
作为优选,所述的步骤2)中分位噪声估计方法的步骤包括
步骤2.1)、根据幅度谱上各频点的分位数,引入最大抑制值,计算噪声信号抑制因子;
步骤2.2)、根据幅度谱上各频点的分位数噪声幅度值、各频点的语音信号的幅值和噪声信号抑制因子,引入权衡因子,更新分位数噪声幅值,估计得到分位数噪声;
步骤2.3)、估计的噪声和实际频谱幅度的差异性参数,更新分位数。
具体地,所述步骤2.1)中、计算噪声信号抑制因子λ
式中,分位数υ(k)代表着k频点噪声的概率,α代表最大抑制值;
步骤2.2)、更新分位数噪声幅值
式中,d(k,l)代表第l帧第k频点处的分位数噪声幅度值,β为一个权衡因子,|x(k,l)|为第l帧第k频点处的语音信号x(k,l)的幅值;
此时,估计得到的分位数噪声表示为nυ(k,l)=ed(k,l)(11)
步骤2.3)、更新分位数
式中,ω表示估计的噪声和实际频谱幅度的差异性参数,更新后的分位数用于返回步骤2.1)进行下一帧的噪声信号抑制因子计算。
作为优选,所述步骤3)中稳态噪声谱修正方法的步骤包括
步骤3.1)、通过线性预测模拟估计出当前信号,计算当前信号的预白化信号;
步骤3.2)、根据预白化信号,求解幅度谱的各帧的预白化信号的重心;
步骤3.3)、根据预白化信号和各帧的预白化信号的重心,设置最短时间长度的约束条件,判断是否存在瞬态噪声;
步骤3.4)、根据是否存在瞬态噪声,修正稳态噪声谱。
具体地,所述步骤3)中稳态噪声谱修正方法的步骤包括
步骤3.1)、预白化信号
通过线性预测模拟估计出当前信号,计算公式如下:
式中,x(n,l)表示当前帧的含噪语音信号,x′(n,l)表示预白化语音信号,ap为ar()因子,n代表时刻值,p代表阶数;
步骤3.2)、求解重心
第l帧的预白化信号的重心表示为
式中,w(n)为汉宁窗函数,c(l)为当前帧的重心索引点,n代表帧长;
步骤3.3)、估计最短时间长度b(l),使之满足下列条件
式中,e代表能量比例,能量集中在某处频带的瞬态噪声,b(l)往往会很小;当帧长n为256点时,b(l)小于75则认为存在瞬态噪声;
步骤3.4)、修正噪声谱
若存在瞬态噪声,则当前帧的估计噪声na(k,l)可表示为
na(k,l)=nυ(k,l)+κ|x(k,l)|(16)
κ为衰减因子。
作为优选,所述步骤4)中基于语音特征估计语音存在概率一的步骤包括
步骤4.1)、根据各帧信号的能量与噪声功率的比值计算后验信噪比、先验信噪比和似然比,计算似然比均值特征;
步骤4.2)、根据各频点的语音信号的幅值,计算频谱平坦度特征;
步骤4.3)、根据各频点的语音信号的幅值、当前帧的估计噪声,计算频谱差异度;
步骤4.4)、联合似然比均值特征、频谱平坦度特征和频谱差异度三个特征,计算语音先验概率、和平滑后的语音先验概率,将语音似然比和平滑后的语音先验概率进行综合,获得更新后的语音先验概率。
具体地,所述基于语音特征估计语音存在概率一的步骤为
步骤4.1)、计算似然比均值特征为
其中,似然比δ(k,l)定义为
此处,δl(k)为后验信噪比,表示观测到第l帧信号的能量与噪声功率的比值,
先验信噪比ρl(k)为:
ρl(k)=rddρl-1(k)+(1-rdd)max(δl(k)-1,0)(12)
式中,rdd为时间平滑参数;
步骤4.2)、计算频谱平坦度特征为
步骤4.3)、计算频谱差异度为
式中,var和cov分别表示方差函数和协方差函数;
步骤4.4)、三特征联合的语音先验概率为
其中,γq是一个平滑因子;
平滑后的语音先验概率
将语音似然比δ(k,l)和语音先验概率
qf为获得更新概率。
作为优选,所述步骤5)中的基于谐波分析的语音概率二的计算步骤为
步骤5.1)根据基音周期对应的频点、谐波参数,通过短时傅里叶变换后的窗函数来构造出激励谱;
步骤5.2)、根据语音信号、激励谱,计算拟合系数;
步骤5.3)、根据语音信号、、拟合系数,计算信号拟合误差;
步骤5.4)、使用误差最小的拟合系数和激励谱拟合出符合当前帧的谐波;
步骤5.5)、结合当前帧的谐波、似然比,获得基于谐波的语音存在概率。
具体地,所述步骤5)中的基于谐波分析的语音概率二的计算步骤为
步骤5.1)通过短时傅里叶变换后的窗函数来构造出激励谱,公式为:
式中,
步骤5.2)、计算拟合系数
步骤5.3)、计算信号拟合误差为:
式中,ai和bi代表谐波频带的区间且ai=(i-0.5)tk,bi=(i+0.5)tk;
步骤5.4)、使用误差最小的ηi(l)和激励谱χ(k,l)拟合出符合当前帧的谐波,公式表示为:
步骤5.5)、结合似然比,基于谐波的语音存在概率为:
其中,
作为优选,所述步骤6)中的综合两个语音概率计算增益,并进行语音增强的步骤为
步骤6.1)、基于步骤4)和步骤5)中获得的两个语音存在概率,计算得到最终的语音存在概率;
步骤6.2)、根据最终的语音存在概率、各频点的语音信号的幅值,计算当前帧的估计的噪声谱;
步骤6.3)、与上一帧噪声谱进行平滑,得到平滑后的当前帧的估计的噪声谱,根据估计的噪声重新求出经过调整的后验信噪比和先验信噪比;
步骤6.4)、根据经过调整的后验信噪比和先验信噪比计算增益函数,结合增益函数、调整前的后验信噪比和先验信噪比,获得增强后的信号。
其中,
所述步骤6.1)、基于计算的两个语音存在概率,最终的语音存在概率为:
p(k,l)=τpf(k,l)+(1-τ)pm(k,l)(23)
其中,τ为加权因子;
步骤6.2)、计算估计的噪声谱:
步骤6.3)、与上一帧噪声谱进行平滑,可得
式中,tn为语音存在可能性阈值;噪声平滑系数ξn相对于语音平滑系数ξx较小;
根据估计的噪声重新求出后验信噪比
步骤6.4)、增强后的信号
其中,
式中,gmin(k,l)取值为0.1,代表着抑制噪声的最大系数。
有益效果:由于采用了上述技术方案,本发明具有以下优点:
(1)、本发明采用了分位噪声估计法获得稳态噪声谱,可以有效的结合噪声的频带分布特性,准确的估计噪声的功率谱密度;
(2)、本发明在稳态噪声估计的基础上,采用信号重心检测来估计瞬态噪声,从而有针对性对瞬态噪声进行有效抑制;
(3)、本发明结合语音特征和谐波分析对语音概率进行估计,既提高了每个频带的语音存在概率估计准确度,又根据基音周期模拟的语音谐波作为语音谐波频段的包络,在语音谐波段内进行噪声抑制的时候,通过增强模拟出来的波形进行衰减,防止削弱语音重要的组成成分;
(4)、本发明在语音概率估计的基础上,计算信号增益并作用于含噪语音,从而实现语音增强,在综合语音增强性能和实时性指标方面,本发明提出的方法明显优于其它经典的语音增强方法。
附图说明
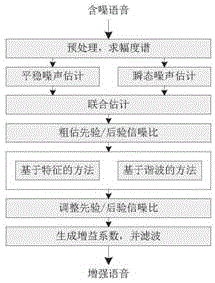
图1为本发明的语音增强原理框架图;
图2是本发明方法对瞬态噪声的抑制效果图;
具体实施方式
下面结合附图对本发明作更进一步的说明。
如图1所示,一种面向瞬态噪声抑制的实时语音增强方法,包括以下步骤:
步骤1)、对含噪语音进行分帧和加窗预处理,求出幅度谱;
步骤2)、采用分位噪声估计法获得稳态噪声谱;
步骤3)、采用基于信号重心检测法来获得瞬态噪声,并根据是否存在瞬态噪声来修正稳态噪声谱;
步骤4)、采用基于语音特征的方法估计语音存在概率一;
步骤5)、采用谐波分析的方法估计语音存在概率二;
步骤6)、综合步骤5)和步骤6)获得的两个语音存在概率,计算增益,并进行语音增强。
本发明中优选步骤2)中的分位噪声估计方法,包括以下步骤:
步骤2.1)、计算噪声信号抑制因子λ
式中,分位数υ(k)代表着k频点噪声的概率,α代表最大抑制值,取值为40。
步骤2.2)、更新分位数噪声幅值
式中,d(k,l)代表第l帧第k频点处的分位数噪声幅度值。β为一个权衡因子,取值为0.25。|x(k,l)|为第l帧第k频点处语音信号x(k,l)的幅值。
此时,估计得到的分位数噪声可表示为nυ(k,l)=ed(k,l)(18)
步骤2.3)、更新分位数
式中,ω表示估计的噪声和实际频谱幅度的差异性参数,取值为0.01。
本发明中优选步骤3)中的稳态噪声谱修正方法包括以下步骤:
步骤3.1)、预白化信号
通过线性预测模拟估计出当前信号,计算公式如下:
式中,x′(n,l)表示预白化语音信号,ap为ar()因子,n代表时刻值,p代表阶数。
步骤3.2)、求解重心
第l帧的预白化信号的重心表示为
式中,w(n)为汉宁窗函数,c(l)为当前帧的重心索引点。n代表帧长。
步骤3.3)、估计最短时间长度b(l),使之满足下列条件
式中,e代表能量比例,取值为90。能量集中在某处频带的瞬态噪声,b(l)往往会很小。当帧长n为256点时,b(l)小于75则认为存在瞬态噪声。
步骤3.4)、修正噪声谱
若存在瞬态噪声,则当前帧的估计噪声na(k,l)可表示为
na(k,l)=nυ(k,l)+κ|x(k,l)|(23)
κ为衰减因子,取值为0.4。
具体地,步骤4)中获得基于语音特征估计语音存在概率一的步骤为
步骤4.1)、计算似然比均值特征为
其中,似然比δ(k,l)定义为
此处,δl(k)为后验信噪比,表示观测到第l帧信号的能量与噪声功率的比值,
先验信噪比ρl(k)为:
ρl(k)=rddρl-1(k)+(1-rdd)max(δl(k)-1,0)(12)
式中,rdd为时间平滑参数,取值为0.98。
步骤4.2)、计算频谱平坦度特征为
步骤4.3)、计算频谱差异度为
式中,var和cov分别表示方差函数和协方差函数。
步骤4.4)、三特征联合的语音先验概率为
其中,γq是一个平滑因子;
平滑后的语音先验概率
将语音似然比δ(k,l)和语音先验概率
本发明中步骤5)获得基于谐波分析的语音概率2的计算步骤为
步骤5.1)、通过短时傅里叶变换后的窗函数来构造出激励谱,公式为:
式中,
步骤5.2)、计算拟合系数
步骤5.3)、计算信号拟合误差为:
式中,ai和bi代表谐波频带的区间且ai=(i-0.5)tk,bi=(i+0.5)tk。
步骤5.4)、使用误差最小的ηi(l)和激励谱χ(k,l)拟合出符合当前帧的谐波,公式表示为:
步骤5.5)、结合似然比,基于谐波的语音存在概率为:
其中,
本发明步骤6)中综合两个语音概率计算增益,并进行语音增强的步骤为
步骤6.1)、基于计算的两个语音存在概率,最终的语音存在概率为:
p(k,l)=τpf(k,l)+(1-τ)pm(k,l)(23)
其中,τ为加权因子,取值为0.3。
步骤6.2)、计算估计的噪声谱:
步骤6.3)、与上一帧噪声谱进行平滑,可得
式中,tn为语音存在可能性阈值,取值为0.3。噪声平滑系数ξn(取值0.9)相对于语音平滑系数ξx(取值0.99)要小一些。
根据估计的噪声重新求出后验信噪比
步骤6.4)、增强后的信号
其中,
式中,gmin(k,l)取值为0.1,代表着抑制噪声的最大系数。
如图2所示,是本发明方法的瞬态噪声抑制效果。本发明方法消除频域上的噪声成分最多,其抑制效果明显高于不带谐波估计的算法。从性能指标看,改进算法的分段信噪比从-5.35提高到-2.91,pesq从1.55提升到1.73,综合性能指标从1.61提升到1.95,stoi从0.6163提升到0.6382。
表1为本发明方法和最优化修正对数谱幅度估计方法的语音增强效果。本发明方法的mos和stoi得分较好,两种算法的pesq相当。在低信噪比时,本发明方法的pesq性能较好。说明,本发明方法的语音增强效果更好,语音质量更好。此外,在配置为intel17-7700cpu和8g内存电脑下,本发明方法和最优化修正对数谱幅度估计方法处理1秒语音的运行时间分别为45ms和1.4s。本发明方法可以显著降低运行时间。
表1
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!