音乐驱动的舞蹈生成方法与流程
本发明涉及跨域序列分析和音视频分析领域,更具体地说,是一种基于音乐驱动的舞蹈动作生成方法。
背景技术:
基于序列分析的深度学习有很多应用,包括语言处理、视频跟踪、跨域分析、基于语义特征的情感分析。跨域序列分析是序列分析的重要分支之一。跨域序列分析是指找出两种不同类型序列之间的对应关系。有很多相关的应用,如不同语言之间的翻译,使用自然语言合成真实的图像。
音视频分析是跨域序列分析的一个特例。与其他学科相比,音视频分析的研究相对较少。主要原因在于对于一般的传统视频来说,音频和视频的相关性不是很强。例如,对于一个特定的视频场景,可能有多个对应的音频序列;对于特定的音频序列,它还可以用作多个视频场景的背景音频。
然而,与一般的音频和视频序列相比,音乐和舞蹈动作之间的相关性相对显著。虽然舞蹈动作与音乐之间没有一一对应关系,但舞蹈动作的节拍与音乐节拍之间的相关性相对较强。这种相对较强的相关性为音乐和视频的跨领域分析提供了可能。例如,可以根据特定的音乐序列来分析舞蹈动作节拍的协调性;或者根据舞蹈动作选择合适的背景音乐。
音乐驱动的舞蹈生成是计算机视觉领域的一个重要研究课题,具有广阔的应用前景。例如,合成的视频可以用于动画生成、编舞、虚拟现实、虚拟角色和游戏。目前已有一些关于舞蹈动作合成的研究。alemi等人使用groovenet来学习低级音频特征和舞蹈动作之间的关系。chan等人提出了一个模型来实现不同人类受试者之间的运动风格迁移。cai等人尝试从噪声中合成人体运动视频。上述尝试的局限性要么是没有发现音乐和视频之间的强相关性,要么只是专注于合成人体动作,而忽略了音乐和视频之间的内在联系。
技术实现要素:
本发明要解决的技术问题在于,针对上述舞蹈合成的方法中,忽略音视频之间的强相关性,只专注于合成人体动作,网络模型简单的问题,提出了一种音乐驱动的舞蹈生成方法。
实现本发明目的的技术解决方案为:一种基于音乐驱动的舞蹈生成方法,包括设计神经网络、训练神经网络和测试神经网络三个过程:
神经网络构建过程包括以下步骤:
1)设计神经网络的主要模块featuremodule和seq2seqmodule;
2)设计神经网络的层数和输入参数。
训练神经网络过程包括以下步骤:
3)对数据集预处理,将其转换成跨域序列分析lstm-sa网络的标准输入即音乐序列和舞蹈序列;
4)初始化神经网络的参数;
5)通过不断迭代前向传播过程、反向传播过程训练神经网络模型;
测试神经网络过程包括以下步骤:
6)输入测试音乐,利用由训练过程得到的神经网络模型预测对应的舞蹈序列;
7)根据预测结果,将其与测试的音乐合成对应的舞蹈序列视频。
上述方法中,所述步骤1)包括以下具体步骤:
11)设计musicfeatureextraction和posefeatureextraction组成featuremodule;
12)设计encoder和decoder模块se2seqmodule,每个encoder和decoder模块里面分别由lstm、dense和attention组成;
上述方法中,所述步骤2)包括以下具体步骤:
21)神经网络模型使用1个featuremodule作为前置网络,1个seq2seqmodule作为主体网络;
22)在seq2seqmodule中,lstm使用了3层,dense网络使用了一层,attention使用了一层;
上述方法中,所述步骤3)包括以下具体步骤:
31)预处理数据集的标签信息,将每段舞蹈序列的标签信息格式化为(n*18*18)写入一个txt文件中。其中n表示舞蹈系列的帧数,(18*18)表示18个关键骨骼点的坐标;
32)预处理输入音乐,重新调整数据集中的输入音乐,统一大小为(n*28)作为跨域序列网络lstm-sa的输入;
上述方法中,所述步骤4)包括以下具体步骤:
41)初始化学习率,迭代次数,batch;
42)采用标准初始化方法初始化权重参数;
上述方法中,所述步骤5)包括以下具体步骤:
51)根据输入的音乐和舞蹈序列信息进行网络的前向传播,计算损失函数大小;
52)如果迭代次数大于最大迭代次数或者损失函数小于误差阈值,结束训练;
53)由计算得到的损失函数值,进行神经网络反向传播计算,更新神经网络各层的权重参数。
54)迭代次数加1,调到步骤51);
上述方法中,所述步骤6)包括以下具体步骤:
61)输入待检测音乐序列,将音乐序列调整为(n*28)的大小。
62)根据训练好的神经网络模型和输入的音乐序列计算得到合成的舞蹈序列。
上述方法中,所述步骤7)包括以下具体步骤:
71)根据合成的舞蹈序列,在空图上标记出关节点的位置坐标;
72)将合成的舞蹈序列与输入的测试音乐相结合,合成结果保存为.mp4的文件;
本发明与现有技术相比,其显著优点在于:1)使用mfcc和openpose进行特征提取,与传统方法相比,不仅效率高,准确率也得到了提高;2)设计的跨域网络模型相比其它深度学习方法中简单的网络模型,模型更复杂,模型体积小,计算速度快。3)预测过程更加简易,可以快速地将音乐与舞蹈序列结合。
附图说明
图1是featuremodule的结构组成。
图2是seq2seqmodule的结构组成。
图3是神经网络模型的组成。
图4是本发明的训练过程。
图5是本发明的预测过程。
图6是本发明的可视化检测结果图。
具体实施方式
下面结合附图对本发明作进一步说明。
本发明公开了一种音乐驱动的舞蹈生成方法,该方法具有多种潜在的应用前景,如虚拟现实、动漫角色和编舞等。对于一首给定的音乐序列,为了产生自然的舞蹈动作,需要满足以下条件:1)舞蹈动作与音乐节拍之间的节奏要和谐;2)产生的舞蹈动作应具有明显的多样性。
本发明提出了一种利用长短时记忆和自我注意机制的序列对序列学习体系结构(lstm-sa)。本发明的音乐驱动舞蹈生成方法包括神经网络模型构建、神经网络训练、测试网络模型三个主要过程。
神经网络构建过程是指选择合适的网络框架,设计合理神经网络层数,在神经网络的每一层使用最优参数,确定合适的损失函数。包括以下具体步骤:
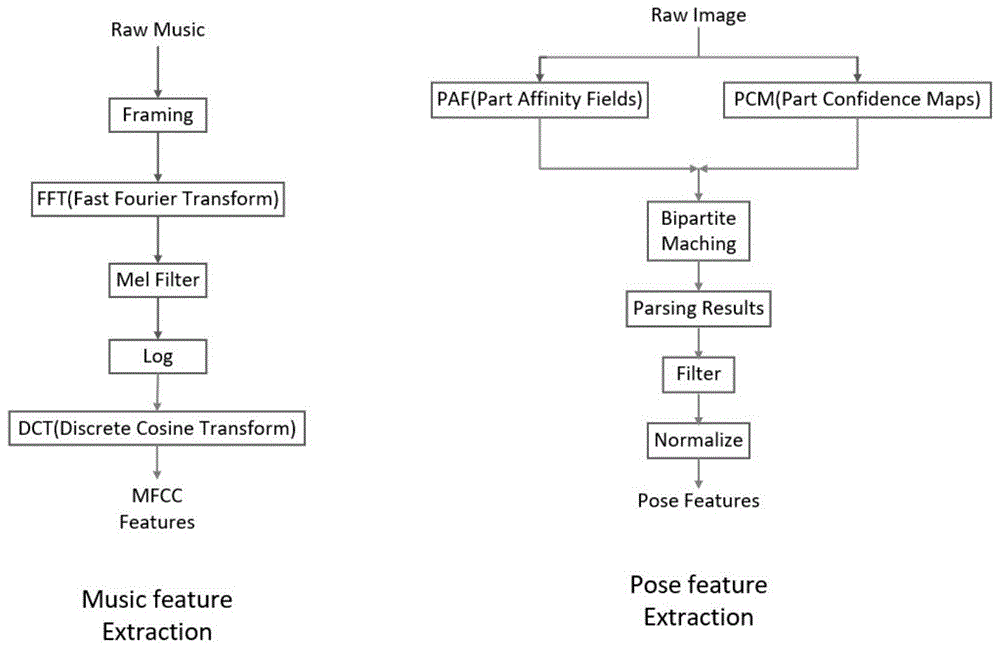
首先,我们设计网络的前置部分,前置部分即神经网络的前面几层,负责提取输入音乐序列和舞蹈序列的特征,我们将其封装为featuremodule,如图1所示。featuremodule由musicfeatureextraction和posefeatureextraction组成。音乐具有许多特征,如低级特征、谱特征和旋律特征等。本发明选取mel频率倒谱系数(mfcc)作为音乐特征。在语音处理中,mfcc是在mel尺度频域提取的倒谱参数,是语音自动识别和说话人识别中广泛应用的一个特征。经过framing、fft、melfilter、log、dct这一系列的处理可以得到n*28的音乐特征数据,其中n表示音乐的帧数,28表示最终的数据维度。在对舞蹈动作进行特征处理时,本发明选择了使用openpose系统进行人体位姿估计,进而获取舞蹈动作的特征。具体的处理流程如下:首先,前馈网络预测了一组体部位置的二维置信度图s和一组体部相似性的二维向量场l;然后,通过贪婪推理对置信图s和亲和域l进行解析,得到图像中所有人的二维关键点输出,每一帧的图像都做相同的处理,在得到所有的关键点坐标之后对其做统一的归一化处理,得到n*18*18的动作数据,其中n表示舞蹈序列的帧数,18*18表示18个关键点的二维坐标。
我们设计并使用seq2seqmodule作为神经网络的主体部分。首先,考虑到音乐驱动的舞蹈生成是一个长序列分析问题,我们的方法lstm-sa基于lstm网络的,这是一个具有代表性的、流行的跨域序列分析模型。lstm网络具有通过层连接的内存块。在训练过程中,网络不仅要维护记忆信息,更要关注最重要的特征。因此,我们选择基于编码解码器的lstm网络作为基本模型。
但是lstm网络有两个问题。一个是lstm网络将整个输入序列压缩成一个固定的向量,因此每个输出对应的语义代码是相同的。这将有两个缺点。一是语义向量不能完全表示整个序列的信息。另一种是,首先输入的内容中包含的信息将被稍后输入的信息稀释。另一个问题是忽略音乐序列中元素之间的相互关系,这可能导致舞蹈序列不那么和谐。
为了解决上述问题,我们的发明引入了注意机制和自我注意的概念。如图2所示,注意机制是指专注于导入信息,同时过滤掉不必要的数据的过程。在增加注意机制之后,网络将保留编码器的所有状态,并为解码器序列中每个元素的编码器状态分配加权平均。因此,每个输出对应的语义码是不同的,这样就可以解决将整个输入序列压缩成一个固定向量的问题。
网络架构如图2所示。它包含三个主要模块。设计了lstm和全连接层模块来处理输入和输出序列,并采用注意机制来改变解码过程。在解码过程中,解码器网络的状态与编码器的状态相结合,并传递给前馈网络。前馈网络返回每个编码器状态的权值。然后将编码器的输入乘以这些权重,然后计算编码器状态的加权平均值。然后将得到的上下文传递到解码器网络
神经网络的完整的结构主要由featuremodule和seq2seqmodule构成,如图3所示。在神经网络的开始部分使用一个featuremodule,紧接着使用一个seq2seqmodule。
深度神经网络的训练过程是通过梯度下降法训练模型中的参数,自动学习音乐与舞蹈之间的相关性,如图4所示。包括以下具体步骤:
预处理训练集过程41。在这里说明,本发明使用的训练集是私有数据集,共计120,000帧舞蹈动作和对应的伴舞音乐。这些数据记录了每帧18个骨骼关节点的二维位置坐标和28维的音乐特征
迭代次数epochs=500,一次输入的batch=32。初始化权重参数可以使神经网络在开始训练的时候不会出现发散和梯度消失的情况。初始化方法我们使用xavier。定义参数所在层的输入维度m,输出维度n,那么参数将以均匀分布的方式在
前向传播过程43。前向传播即计算输入音乐序列在神经网络每一层的输出。深层神经网络包含一个输入层,多个中间层,一个输出层,每一层可以表示为非线性映射过程。样本x在第m层的输入计算公式如下:
其中,
计算损失函数过程44。本发明使用的损失函数是mse函数。
反向传播过程更新网络权重参数结束后,跳转前向传播过程43。
本发明的测试网络模型过程是指输入测试音乐(待测试的音乐序列),通过神经网络模型的计算,给出预测的舞蹈序列结果。包含以下具体步骤:
初始化预测参数51。序列lookback=15,即使用多少帧的音乐特征用于合成一帧的舞蹈动作,batch=32。
输入音乐序列并进行特征提取52。因为训练过程使用的音乐序列统一是n*28,所以在测试过程中,所有输入的音乐需要调整为n*28作为神经网络的输入,如图5所示。
使用训练好的网络模型检测过程53。根据已经训练好的网络模型和输入的音乐序列预测,在输入层输出舞蹈序列。最后输出预测结果54,将其与输入的音乐序列进行结合,输出保存为.mp4文件55。
这里需要着重指出,相比于传统的舞蹈动作合成方法,本发明利用音乐来合成舞蹈动作而不是通过噪声合成。而且不能发明找到了音乐与舞蹈动作之间的强相关性,使得合成的舞蹈动作更丰富更协调。图6给出了本发明的部分预测的舞蹈动作的可视化视图。
- 还没有人留言评论。精彩留言会获得点赞!