语音处理装置、语音处理方法和记录介质与流程
[0001]
本公开涉及语音处理装置、语音处理方法和记录介质。具体地,本公开涉及用于从用户接收的话语的语音识别处理。
背景技术:
[0002]
随着智能电话和智能扬声器的广泛使用,用于响应从用户接收的话语的语音识别技术已被广泛使用。在这样的语音识别技术中,预先设置作为用于启动语音识别的触发的唤醒词,并且在确定用户说出唤醒词的情况下,启动语音识别。
[0003]
作为与语音识别相关的技术,已知一种用于根据用户的运动来动态地设置要说出的唤醒词,以防止由于唤醒词的说出而削弱用户体验的技术。
[0004]
现有技术文献
[0005]
专利文献
[0006]
专利文献1:日本专利申请公开第2016-218852号
技术实现要素:
[0007]
技术问题
[0008]
然而,在上述传统技术中存在改进的空间。例如,在使用唤醒词执行语音识别处理的情况下,用户向基于用户首先说出唤醒词的假设来控制语音识别的设备讲话。因此,例如,在用户输入特定话语而忘记说出唤醒词的情况下,不启动语音识别,并且用户应当再次说出唤醒词和话语的内容。这使得用户浪费时间和精力,并且可用性可能恶化。
[0009]
因此,本公开提供了一种可以提高与语音识别相关的可用性的语音处理装置、语音处理方法和记录介质。
[0010]
问题解决方案
[0011]
为了解决上述问题,一种语音处理装置,包括:接收单元,被配置为接收与预定时间长度对应的语音以及与用于启动与所述语音对应的预定功能的触发相关的信息;以及确定单元,被配置为根据由接收单元接收的与触发相关的信息,在与预定时间长度对应的语音中确定用于执行预定功能的语音。
[0012]
本发明的有益效果
[0013]
通过根据本公开的语音处理装置、语音处理方法和记录介质,可以提高与语音识别相关的可用性。本文所述的效果不是限制性的,并且可以使用本文所述的任何效果。
附图说明
[0014]
图1是示出根据本公开的第一实施方式的信息处理的概要的示图。
[0015]
图2是用于解释根据本公开的第一实施方式的话语提取处理的示图。
[0016]
图3是示出根据本公开的第一实施方式的智能扬声器的配置示例的示图。
[0017]
图4是示出根据本公开的第一实施方式的话语数据的示例的示图。
[0018]
图5是示出根据本公开的第一实施方式的组合数据的示例的示图。
[0019]
图6是示出根据本发明的第一实施方式的唤醒词数据的示例的示图。
[0020]
图7是示出根据本公开的第一实施方式的交互处理的示例的示图(1)。
[0021]
图8是示出根据本公开的第一实施方式的交互处理的示例的示图(2)。
[0022]
图9是示出根据本公开的第一实施方式的交互处理的示例的示图(3)。
[0023]
图10是示出根据本公开的第一实施方式的交互处理的示例的示图(4)。
[0024]
图11是示出根据本公开的第一实施方式的交互处理的示例的示图(5)。
[0025]
图12是示出根据本公开的第一实施方式的处理过程的流程图(1)。
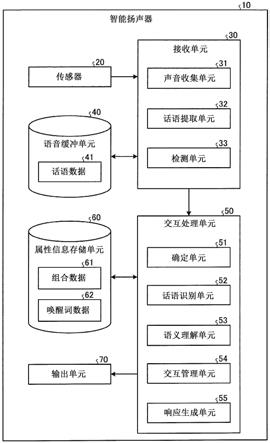
[0026]
图13是示出根据本公开的第一实施方式的处理过程的流程图(2)。
[0027]
图14是示出根据本公开的第二实施方式的语音处理系统的配置示例的示图。
[0028]
图15是示出根据本公开的第三实施方式的语音处理系统的配置示例的示图。
[0029]
图16是示出实现智能扬声器功能的计算机的示例的硬件配置图。
具体实施方式
[0030]
下面基于附图详细描述本公开的实施方式。在下面的实施方式中,相同的部分用相同的附图标记表示,并且将不再重复多余的描述。
[0031]
1.第一实施方式
[0032]
1-1.第一实施方式的信息处理概要
[0033]
图1是示出根据本公开的第一实施方式的信息处理的概要的示图。根据本公开的第一实施方式的信息处理由图1所示的语音处理系统1执行。如图1所示,语音处理系统1包括智能扬声器10。
[0034]
智能扬声器10是根据本公开的语音处理装置的示例。智能扬声器10是与用户进行交互,执行语音识别和响应等各种信息处理的设备。可替换地,智能扬声器10可以与经由网络与之连接的服务器装置协作来执行根据本公开的语音处理。在这种情况下,智能扬声器10用作主要执行与用户的交互处理的接口,诸如收集用户的话语的处理、向服务器装置发送所收集的话语的处理,以及输出从服务器装置发送的应答的处理。将在第二实施方式和以下详细描述中描述根据本公开的具有这种配置的执行语音处理的示例。在第一实施方式中,描述了根据本公开的语音处理装置是智能扬声器10的示例,但是语音处理装置也可以是智能电话、平板终端等。在这种情况下,智能电话和平板终端通过执行具有与智能扬声器10的功能相同的功能的计算机程序(应用)来显示根据本公开的语音处理功能。除了智能电话和平板终端之外,语音处理装置(即,根据本公开的语音处理功能)可以通过诸如手表型终端或眼镜型终端的可穿戴装置来实现。语音处理装置也可以由具有信息处理功能的各种智能设备来实现。例如,语音处理装置可以是诸如电视、空调和冰箱的智能家用设备,诸如汽车、无人驾驶飞机、家庭机器人等的智能车辆。
[0035]
在图1的示例中,智能扬声器10安装在用户u01(作为使用智能扬声器10的用户的示例)居住的房屋中。在以下的说明中,在不需要区分用户u01和其他用户的情况下,用户被共同地和简单地称为“用户”。在第一实施方式中,智能扬声器10对所收集的语音执行响应处理。例如,智能扬声器10识别用户u01提出的问题,并通过语音输出该问题的应答。具体地,智能扬声器10生成对用户u01提出的问题的响应,并且检索用户u01所请求的曲调,并且
执行用于使智能扬声器10输出检索到的语音的控制处理。
[0036]
各种已知技术可用于由智能扬声器10执行的语音识别处理、语音响应处理等。例如,智能扬声器10可以包括不仅用于收集语音而且用于获取各种其他信息的各种传感器。例如,除了麦克风之外,智能扬声器10可以包括用于获取空间中的信息的相机、检测照度的照度传感器、检测倾斜度的陀螺仪传感器、检测物体的红外传感器等。
[0037]
在使智能扬声器10执行如上所述的语音识别和响应处理的情况下,要求用户u01给出用于执行功能的特定触发。例如,在说出请求或问题之前,要求用户u01给出特定触发,诸如说出用于使智能扬声器10的交互功能(下文中称为“交互系统”)启动的特定词(下文中称为“唤醒词”)或注视包括在智能扬声器10中的相机。当在用户说出唤醒词后从用户接收到问题时,智能扬声器10通过语音输出对该问题的应答。这样,由于智能扬声器10在识别出唤醒词之前不需要启动交互系统,所以可以减少处理负荷。此外,用户u01可以防止当用户u01不需要响应时从智能扬声器10输出不必要的应答的情况。
[0038]
然而,在一些情况下,上述传统处理可能使可用性恶化。例如,在对智能扬声器10做出特定请求的情况下,用户u01应当执行以下步骤:中断与周围人继续的会话,说出唤醒词,然后提出问题。在用户u01忘记说出了唤醒词的情况下,用户u01应当重新说出唤醒词和整个请求语句。这样,在传统的处理中,不能灵活地使用语音应答功能,并且可用性可能恶化。
[0039]
因此,根据本公开的智能扬声器10通过下面描述的信息处理解决了相关技术的问题。具体地,智能扬声器10基于与唤醒词相关的信息(例如,为唤醒词预先设置的属性)在与一定时间长度对应的语音中确定要用于执行该功能的语音。作为示例,在用户u01在说出请求或问题之后说出唤醒词的情况下,智能扬声器10确定唤醒词是否具有“使用在唤醒词之前说出的语音执行响应处理”的属性。在确定唤醒词具有“使用在唤醒词之前说出的语音执行响应处理”的属性的情况下,智能扬声器10确定用户在唤醒词之前说出的语音是用于响应处理的语音。因此,智能扬声器10可以通过返回到用户在唤醒词之前说出的语音来生成用于应对问题或请求的响应。即使在用户u01忘记说出唤醒词的情况下,也不要求用户u01再次说出唤醒词,因此用户u01可以无压力地使用由智能扬声器10执行的响应处理。下面结合参考图1的过程描述根据本公开的语音处理的概要。
[0040]
如图1所示,智能扬声器10收集用户u01的日常会话。此时,智能扬声器10暂时存储所收集的与预定时间长度(例如,1分钟)对应的语音。即,智能扬声器10通过缓冲所收集的语音来反复累积和删除所收集的语音。
[0041]
此时,智能扬声器10可以执行从所收集的语音中检测话语的处理。下面参考图2描述关于这一点。图2是用于说明根据本公开的第一实施方式的话语提取处理的示图。如图2所示,通过仅记录假定对执行诸如响应处理的功能有效的语音(例如,用户的话语),智能扬声器10可以有效地使用用于缓冲语音的存储区域(称为缓冲存储器)。
[0042]
例如,关于语音信号的振幅超过特定水平,智能扬声器10在过零率超过特定数量时确定话语部分的开始,并且在值变得等于或小于特定值时确定结束,以提取话语部分。然后,智能扬声器10仅提取话语部分,并缓冲去除了静音部分的语音。
[0043]
在图2所示的示例中,智能扬声器10检测开始时间ts1,并检测此后的结束时间te1,以提取说出的语音1。类似地,智能扬声器10检测开始时间ts2,并且检测此后的结束时
间te2,以提取说出的语音2。智能扬声器10检测开始时间ts3,并检测此后的结束时间te3,以提取说出的语音3。然后,智能扬声器10删除说出的语音1之前的静音部分,说出的语音1和说出的语音2之间的静音部分,以及说出的语音2和说出的语音3之间的静音部分,并缓冲说出的语音1、说出的语音2和说出的语音3。因此,智能扬声器10可以有效地使用缓冲存储器。
[0044]
此时,智能扬声器10可以通过使用已知技术存储用于识别与话语相关联地讲话的用户的识别信息等。在缓冲存储器的空闲空间量变得小于预定阈值的情况下,智能扬声器10删除旧话语以确保空闲空间,并保存新语音。智能扬声器10可以直接缓冲所收集的语音而不执行提取话语的处理。
[0045]
在图1的示例中,假定智能扬声器10在用户u01的话语中缓冲“看起来要下雨”的语音a01和“告诉我天气”的语音a02。
[0046]
另外,智能扬声器10执行检测用于启动与语音对应的预定功能的触发的处理,同时继续语音的缓冲。具体地,智能扬声器10检测唤醒词是否包含在所收集的语音中。在图1的示例中,假定为智能扬声器10设置的唤醒词是“计算机”。
[0047]
在收集诸如“请,计算机”的语音a03的语音的情况下,智能扬声器10将包括在语音a03中的“计算机”检测为唤醒词。通过由检测到唤醒词被触发,智能扬声器10启动预定功能(在图1的示例中,所谓的交互处理功能是输出对用户u01的交互的响应)。另外,在检测到唤醒词的情况下,智能扬声器10根据唤醒词确定要用于响应的话语,并生成对该话语的响应。即,智能扬声器10根据接收到的语音和与触发相关的信息来执行交互处理。
[0048]
具体地,智能扬声器10根据用户u01说出的唤醒词或者唤醒词与在唤醒词之前或之后说出的语音的组合来确定要设置的属性。根据本公开的唤醒词的属性是指用于将用于处理的话语的定时情况分开的设置信息,诸如“在检测到唤醒词的情况下通过使用在唤醒词之前说出的语音来执行处理”或者“在检测到唤醒词的情况下通过使用在唤醒词之后说出的语音来执行处理”。例如,在用户u01说出的唤醒词具有“在检测到唤醒词的情况下通过使用在唤醒词之前说出的语音来执行处理”的属性的情况下,智能扬声器10确定将在唤醒词之前说出的语音用于响应处理。
[0049]
在图1的示例中,假设“通过使用在检测到唤醒词的情况下在唤醒词之前说出的语音来执行处理”的属性(在下文中,该属性被称为“先前语音”)被设置为“请”的语音和“计算机”的唤醒词的组合。即,在识别“请,计算机”的语音a03的情况下,智能扬声器10确定在语音a03之前使用话语用于响应处理。具体地,智能扬声器10确定使用在语音a03之前缓冲的语音a01或语音a02进行交互处理。即,智能扬声器10生成对语音a01或语音a02的响应,并对用户做出响应。
[0050]
在图1的示例中,作为对语音a01或语音a02的语义理解处理的结果,智能扬声器10估计用户u01要求知道天气的情况。然后,智能扬声器10参考当前位置的位置信息等,并执行在web上检索天气信息的处理以生成响应。具体地,智能扬声器10产生并输出“在东京,早上多云,下午下雨”的响应语音r01。在用于生成响应的信息不足的情况下,智能扬声器10可以适当地做出用于补偿信息不足的响应(例如,“请告诉我您想要知道的天气的位置、日期和时间”)。
[0051]
这样,根据第一实施方式的智能扬声器10接收与预定时间长度对应的缓存的语
音,以及与用于启动与该语音对应的预定功能的触发(唤醒词等)相关的信息。然后,智能扬声器10根据接收到的与触发相关的信息,在与预定时间长度对应的语音中确定用于执行预定功能的语音。例如,根据触发的属性,智能扬声器10确定在触发之前收集的语音被识别为用于执行预定功能的语音。智能扬声器10基于所确定的语音来控制预定功能的执行。例如,智能扬声器10控制与在检测到触发之前收集的语音对应的预定功能的执行(在图1的示例中,检索天气的检索功能,以及输出检索到的信息的输出功能)。
[0052]
如上所述,智能扬声器10不仅对唤醒词之后的语音作出响应,而且可以作出与各种情况对应的灵活响应,诸如在通过唤醒词启动交互系统时立即作出与唤醒词之前的语音对应的响应。换言之,在检测到唤醒词之后,无需来自用户u01等的语音输入,智能扬声器10可以追溯所缓冲的语音来执行响应处理。虽然将在后面描述细节,但是智能扬声器10还可以通过组合检测到唤醒词之前的语音和检测到唤醒词之后的语音来生成响应。因此,智能扬声器10可以对用户u01等在对话期间说出的临时问题等做出适当的响应,而不会使用户u01在说出唤醒词之后再次说出该问题,从而可以提高与交互处理相关的可用性。
[0053]
1-2.根据第一实施方式的语音处理装置的配置
[0054]
接下来,下面描述作为根据第一实施方式的执行语音处理的语音处理装置的示例的智能扬声器10的配置。图3是示出根据本公开的第一实施方式的智能扬声器10的配置示例的示图。
[0055]
如图3所示,智能扬声器10包括诸如接收单元30和交互处理单元50的处理单元。接收单元30包括声音收集单元31、话语提取单元32和检测单元33。交互处理单元50包括确定单元51、话语识别单元52、语义理解单元53、交互管理单元54和响应生成单元55。每个处理单元例如在存储在智能扬声器10中的计算机程序(例如,记录在根据本公开的记录介质中的语音处理程序)由cpu(中央处理单元)、mpu(微处理单元)等通过使用ram(随机存取存储器)等作为工作区域来执行时实现。每个处理单元还可以由诸如asic(专用集成电路)或fpga(现场可编程门阵列)的集成电路来实现。
[0056]
接收单元30接收与预定时间长度对应的语音,以及用于启动与该语音对应的预定功能的触发。与预定时间长度对应的语音例如是存储在语音缓冲单元40中的语音,在检测到唤醒词之后收集的用户的话语等。预定功能是由智能扬声器10执行的各种信息处理。具体地,预定功能是由智能扬声器10执行的与用户的交互处理(交互系统)的启动、执行、停止等。预定功能包括用于实现与生成对用户的响应的处理相伴随的各种信息处理的各种功能(例如,用于检索应答的内容的web检索处理、检索用户所请求的曲调并下载所检索的曲调的处理等)。接收单元30的处理由各个处理单元执行,即声音收集单元31、话语提取单元32和检测单元33。
[0057]
声音收集单元31通过控制智能扬声器10中包括的传感器20来收集语音。传感器20例如是麦克风。传感器20还可以具有检测与用户的运动相关的各种信息的功能,诸如用户身体的方向、倾斜度、运动、运动速度等。即,传感器20还可以包括对用户或周围环境成像的相机、感测用户存在的红外传感器等。
[0058]
声音收集单元31收集语音,并将收集到的语音存储在存储单元中。具体地,声音收集单元31将所收集的语音临时存储在作为存储单元的示例的语音缓冲单元40中。
[0059]
声音收集单元31可以预先接收关于要存储在语音缓冲单元40中的语音的信息量
的设置。例如,声音收集单元31从用户接收将与某个时间对应的语音存储为缓冲的设置。然后,声音收集单元31接收要存储在语音缓冲单元40中的语音的信息量的设置,并且将在接收到的设置的范围中收集的语音存储在语音缓冲单元40中。因此,声音收集单元31可以在用户期望的存储容量范围内缓冲语音。
[0060]
在接收到删除存储在语音缓冲单元40中的语音的请求的情况下,声音收集单元31可以删除存储在语音缓冲单元40中的语音。例如,在一些情况下,考虑到私密性,用户可能期望防止过去的语音被存储在智能扬声器10中。在这种情况下,在从用户接收到与删除所缓冲的语音相关的操作之后,智能扬声器10删除所缓冲的语音。
[0061]
话语提取单元32从与预定时间长度对应的语音中提取用户说出的话语部分。如上所述,话语提取单元32通过使用与语音部分检测等相关的已知技术来提取话语部分。话语提取单元32将所提取的话语数据存储在话语数据41中。即,接收单元30从与预定时间长度对应的语音中提取由用户说出的话语部分作为用于执行预定功能的语音,并且接收所提取的话语部分。
[0062]
话语提取单元32还可以将话语和用于识别已经说出话语的用户的识别信息彼此关联地存储在语音缓冲单元40中。因此,确定单元51(稍后描述)能够使用用户识别信息来执行确定处理,诸如仅使用与说出唤醒词的用户相同的用户的话语来进行处理,而不使用与说出唤醒词的用户不同的用户的话语来进行处理。
[0063]
下面描述根据第一实施方式的语音缓冲单元40和话语数据41。例如,语音缓冲单元40由诸如ram和闪存之类的半导体存储器元件、诸如硬盘和光盘之类的存储装置等来实现。语音缓冲单元40包括话语数据41作为数据表。
[0064]
话语数据41是通过从在语音缓冲单元40中缓冲的语音中仅提取被估计为与用户的话语相关的语音的语音而获得的数据表。即,接收单元30收集语音,从收集的语音检测话语,并将检测到的话语存储在语音缓冲单元40中的话语数据41中。
[0065]
图4示出了根据第一实施方式的话语数据41的示例。图4是示出根据本公开的第一实施方式的话语数据41的示例的示图。在图4所示的示例中,话语数据41包括诸如“缓冲设置时间”、“话语信息”、“语音id”、“获取的日期和时间”、“用户id”和“话语”等项。
[0066]“缓冲设置时间”指示要缓冲的语音的时间长度。“话语信息”指示从缓冲的语音中提取的话语的信息。“语音id”指示用于识别语音(话语)的识别信息。“获取的日期和时间”指示获取语音的日期和时间。“用户id”指示用于识别讲话的用户的识别信息。在无法指定讲话的用户的情况下,智能扬声器10a不必登记用户id的信息。“话语”指示话语的具体内容。为了说明起见,图4示出了这样的示例,其中特定字符串被存储为话语的项,但是信息可以以与话语相关的语音数据或用于指定话语的时间数据(指示话语的开始时刻和结束时刻的信息)的模式被存储为话语的项。
[0067]
以此方式,接收单元30可仅在缓冲的语音中提取并存储话语。即,接收单元30可以接收通过仅提取话语部分作为要用于交互处理的功能的语音而获得的语音。因此,接收单元30仅处理被估计为对响应处理有效的话语就足够了,从而可以降低处理负荷。接收单元30可以有效地使用有限的缓冲存储器。
[0068]
返回到图3继续描述。检测单元33检测用于启动语音对应的预定功能的触发。具体地,检测单元33对作为触发的与预定时间长度对应的语音执行语音识别,并检测唤醒词,唤
醒词为用于启动预定功能的触发的语音。接收单元30接收由检测单元33识别出的唤醒词,并将接收到唤醒词的事实发送到交互处理单元50。
[0069]
在提取用户的话语部分的情况下,接收单元30可以接收提取的话语部分和唤醒词,其中唤醒词为用于启动预定功能的触发的语音。在这种情况下,确定单元51(稍后描述)可以将话语部分中与说出唤醒词的用户相同的用户的话语部分确定为用于执行预定功能的语音。
[0070]
例如,当在使用缓冲的语音做出响应的情况下使用除了说出唤醒词的用户的话语之外的话语时,可能做出实际上说出唤醒词的用户不想要的响应。因此,确定单元51可以通过仅使用与在缓冲的语音中说出唤醒词的用户相同的用户的话语执行交互处理来产生用户期望的适当响应。
[0071]
确定单元51不必确定只使用与说出唤醒词的用户相同的用户说出的话语来进行处理。即,确定单元51可以将话语部分中与说出唤醒词的用户相同的用户的话语部分和预先登记的预定用户的话语部分确定为用于执行预定功能的语音。例如,执行诸如智能扬声器10的交互处理的设备可以具有为诸如生活在安装该设备的他们自己的房屋中的家庭的多个人登记用户的功能。在具有这种功能的情况下,智能扬声器10可以在检测到唤醒词时使用唤醒词之前或之后的话语来执行交互处理,即使该话语是与说出唤醒词的用户不同的用户的话语,只要该话语是由预先登记的用户说出的。
[0072]
如上所述,接收单元30基于由包括声音收集单元31、话语提取单元32和检测单元33的处理单元执行的功能,接收与预定时间长度对应的语音和与用于启动与语音对应的预定功能的触发相关的信息。然后,接收单元30将接收到的语音和与触发相关的信息发送到交互处理单元50。
[0073]
交互处理单元50控制作为与用户进行交互处理的功能的交互系统,并与用户执行交互处理。由交互处理单元50控制的交互系统在接收单元30检测到诸如唤醒词的触发时启动,例如,控制跟随确定单元51的处理单元,并执行与用户的交互处理。具体地,交互处理单元50基于确定单元51确定要用于执行预定功能的语音来生成对用户的响应,并控制输出所生成的响应的处理。
[0074]
确定单元51根据接收单元30接收到的与触发相关的信息(例如,预先为触发设置的属性),在与预定时间长度对应的语音中确定用于执行预定功能的语音。
[0075]
例如,确定单元51根据触发的属性将与预定时间长度对应的语音中的在触发之前说出的语音确定为用于执行预定功能的语音。可替换地,确定单元51可以根据触发的属性将与预定时间长度对应的语音中的在触发之后说出的语音确定为用于执行预定功能的语音。
[0076]
确定单元51还可以根据触发的属性,将通过将与预定时间长度对应的语音中的在触发之前说出的语音和在触发之后说出的语音组合而获得的语音确定为用于执行预定功能的语音。
[0077]
在接收到作为触发的唤醒词的情况下,确定单元51根据预先对各唤醒词设置的属性,在与预定时间长度对应的语音中确定要用于执行预定功能的语音。可替换地,确定单元51可以根据与唤醒词和在唤醒词之前或之后检测到的语音的每个组合相关联的属性,在与预定时间长度对应的语音中确定要用于执行预定功能的语音。以这种方式,例如,智能扬声
的情况下,估计用户在唤醒词之后做出请求或要求。即,在用户说出“你好”的情况下,智能扬声器10可以通过不使用在话语之前的语音而对其后的语音执行处理来降低处理负荷。
[0088]
返回到图3继续描述。如上所述,确定单元51根据唤醒词等的属性来确定要用于处理的语音。在这种情况下,在根据唤醒词的属性将与预定时间长度对应的语音中在唤醒词之前说出的语音确定为要用于执行预定功能的语音的情况下,确定单元51可以在执行预定功能的情况下使得与唤醒词对应的会话结束。即,确定单元51可以通过在说出先前语音的属性所赋予的唤醒词之后使与交互相关的会话立即结束(更准确地,使交互系统比通常更早地结束)来减少处理负荷。与所述唤醒词对应的所述会话意味着由所述交互系统执行的由所述唤醒词触发而启动的一系列处理。例如,在智能扬声器10检测到唤醒词,并且之后交互被中断预定时间(例如,一分钟、五分钟等)的情况下,与唤醒词对应的会话结束。
[0089]
话语识别单元52将确定单元51确定要用于处理的语音(话语)转换为字符串。话语识别单元52可以并行地处理在识别唤醒词之前缓冲的语音和在识别唤醒词之后获取的语音。
[0090]
语义理解单元53基于由话语识别单元52识别的字符串来分析来自用户的请求或问题的内容。例如,语义理解单元53参照包括在智能扬声器10或外部数据库中的词典数据来分析由字符串表示的请求或问题的内容。具体地,语义理解单元53基于字符串指定来自用户的请求的内容,诸如“请告诉我某个目标是什么”,“请在日历应用中登记日程”以及“请播放特定艺术家的歌曲”。然后,语义理解单元53将指定内容传递给交互管理单元54。
[0091]
在不能基于字符串分析用户意图的情况下,语义理解单元53可以将该事实传递给响应生成单元55。例如,在作为分析的结果包括不能从用户的话语估计的信息的情况下,语义理解单元53将内容传递到响应生成单元55。在这种情况下,响应生成单元55可以生成用于请求用户再次准确地说出不清楚信息的响应。
[0092]
交互管理单元54基于语义理解单元53所理解的语义表示来更新交互系统,并确定交互系统的动作。即,交互管理单元54执行与所理解的语义表示对应的各种动作(例如,检索应当向用户应答的事件的内容的动作,或者检索用户所请求的内容后跟随的应答的动作)。
[0093]
响应生成单元55基于交互管理单元54执行的动作等生成对用户的响应。例如,在交互管理单元54获取与请求的内容对应的信息的情况下,响应生成单元55生成与作为响应的措辞等对应的语音数据。根据问题或请求的内容,响应生成单元55可以为用户的话语生成“什么也不做”的响应。响应生成单元55执行控制以从输出单元70输出所生成的响应。
[0094]
输出单元70是用于输出各种信息的机构。例如,输出单元70是扬声器或显示器。例如,输出单元70通过语音输出由响应生成单元55生成的语音数据。在输出单元70是显示器的情况下,响应生成单元55可以执行使接收到的响应作为文本数据显示在显示器上的控制。
[0095]
以下参照图7至图12具体示出由确定单元51确定要用于处理的语音并基于所确定的语音生成响应的各种模式。图7至图12概念性地示出了在用户和智能扬声器10之间执行的交互处理的流程。图7是示出根据本公开的第一实施方式的交互处理的示例的示图(1)。图7示出了其中唤醒词和组合语音的属性是“先前语音”的示例。
[0096]
如图7所示,即使当用户u01说出“看起来要下雨”时,该话语中也不包括唤醒词,从
而智能扬声器10保持交互系统的停止状态。另一方面,智能扬声器10继续对话语进行缓冲。此后,在检测到用户u01说出“你觉得如何?”和“计算机”,智能扬声器10启动交互系统以开始处理。然后,智能扬声器10在启动之前分析多个话语以确定动作,并生成响应。即,在图7的示例中,智能扬声器10生成对用户u01的话语的响应,即,“看起来要下雨”和“你觉得如何?”。更具体地,智能扬声器10执行web检索,并获取天气预报信息或指定降雨的概率。然后,智能扬声器10将所获取的信息转换成语音输出给用户u01。
[0097]
在作出响应之后,智能扬声器10在保持交互系统被启动的情况下等待预定时间。即,在输出响应之后,智能扬声器10使交互系统的会话持续预定时间,并且在经过预定时间的情况下结束交互系统的会话。在会话结束的情况下,智能扬声器10不启动交互系统并且不执行交互处理,直到再次检测到唤醒词。
[0098]
在基于先前语音的属性执行响应处理的情况下,智能扬声器10可以将持续会话的预定时间设置为短于其他属性的情况下的预定时间。这是因为,在基于先前语音的属性的响应处理中,用户进行下一话语的可能性低于基于另一属性的响应处理中的可能性。因此,智能扬声器10可以立即停止交互系统,从而可以减少处理负荷。
[0099]
接下来,将参考图8进行描述。图8是示出根据本公开的第一实施方式的交互处理的示例的示图(2)。图8示出了唤醒词的属性为“未指定”的示例。在这种情况下,智能扬声器10基本上对在唤醒词之后接收的话语作出响应,但是在存在缓冲话语的情况下,也通过使用该话语来生成响应。
[0100]
如图8所示,用户u01说出“看起来要下雨”。类似于图7的示例,智能扬声器10缓冲用户u01的话语。此后,在用户u01说出“计算机”的唤醒词的情况下,智能扬声器10启动交互系统以启动处理,并等待用户u01的下一次话语。
[0101]
然后,智能扬声器10收到来自用户u01的“你觉得如何?”的话语。在这种情况下,智能扬声器10确定仅“你觉得如何?”的话语是不足以产生响应的信息。此时,智能扬声器10搜索在语音缓冲单元40中缓冲的话语,并参考紧接在前的用户u01的话语。然后,智能扬声器10确定使用所缓冲的话语中的“看起来要下雨”的话语来进行处理。
[0102]
也就是说,智能扬声器10在语义上理解了“看起来要下雨”和“你觉得如何”这两种话语,并生成与来自用户的请求对应的响应。具体地,智能扬声器10生成“在东京,早上多云,下午下雨”的响应,作为对用户u01的“看起来要下雨”和“你觉得如何?”的话语的响应,并且输出响应语音。
[0103]
这样,在唤醒词的属性为“未指定”的情况下,智能扬声器10可以使用唤醒词之后的语音进行处理,或者可以根据情况通过组合唤醒词之前和之后的语音来生成响应。例如,在难以根据在唤醒词之后接收的话语生成响应的情况下,智能扬声器10参考缓冲的语音,并尝试生成响应。这样,通过结合缓冲语音的处理和参照唤醒词属性的处理,智能扬声器10可以执行与各种情况对应的灵活响应处理。
[0104]
随后,将参考图9进行描述。图9是示出根据本公开的第一实施方式的交互处理的示例的示图(3)。在图9的示例中,示出了即使在属性未被预先设置的情况下,例如通过组合唤醒词和预定短语来将属性确定为“先前语音”的情况。
[0105]
在图9的示例中,用户u02向用户u01说出“它是由xx演唱的名称为yy的歌曲”。在图9的示例中,“yy”是特定的歌曲名称,“xx”是演唱“yy”的艺术家的名字。智能扬声器10缓冲
用户u02的话语。此后,用户u01向智能扬声器10说出“播放该歌曲”和“计算机”。
[0106]
智能扬声器10启动由唤醒词“计算机”触发的交互系统。随后,智能扬声器10对与唤醒词结合的短语即“播放该歌曲”执行识别处理,并确定该短语包括指示代词或指示词。通常,在话语包括对话中的类似“该歌曲”的指示代词或指示词的情况下,估计目标已经出现在先前的话语中。因此,在通过组合包括诸如“该歌曲”的示例代词或指示词和唤醒词进行话语的情况下,智能扬声器10确定唤醒词的属性为“先前语音”。即,智能扬声器10将用于交互处理的语音确定为“唤醒词之前的话语”。
[0107]
在图9的示例中,智能扬声器10在交互系统启动之前分析多个用户的话语(即,识别出“计算机”之前的用户u01和用户u02的话语),并确定与响应相关的动作。具体地,智能扬声器10基于“它是由xx演唱的名称为yy的歌曲”和“播放该歌曲”的话语,检索并下载“名称为yy且由xx演唱”的歌曲。当歌曲的再现准备完成时,智能扬声器10进行输出,使得歌曲与“播放xx的yy”的响应一起再现。此后,智能扬声器10使交互系统的会话持续预定时间,并等待话语。例如,如果在此期间从用户u01获得诸如“否,另一歌曲”的反馈,则智能扬声器10执行停止当前再现的歌曲的再现处理。如果在预定时间期间没有接收到新话语,则智能扬声器10结束会话并停止交互系统。
[0108]
以这种方式,智能扬声器10不必仅基于预先设置的属性来执行处理,而是可以在某种规则下确定要用于交互处理的话语,诸如在组合了指示词和唤醒词的情况下根据“先前语音”的属性来执行处理。因此,智能扬声器10可以像人之间的真实对话那样对用户的响应做出自然响应。
[0109]
图9中所说明的示例可应用于各种实例。例如,在亲子之间的对话中,假定孩子说出“我们小学在x月y日有运动会”。响应于该话语,假定父母说出“计算机,将它登记在日历中”。此时,在通过检测包括在父母的话语中的“计算机”来启动交互系统之后,智能扬声器10基于字符串“它(i t)”来参考缓冲的语音。然后,智能扬声器10组合“我们小学在x月y日有运动会”和“将它登记在日历中”的两个话语,以执行将“x月y日”登记为“小学运动会”的处理(例如,在日历应用中登记日程)。这样,智能扬声器10可以通过组合唤醒词之前和之后的话语来做出适当的响应。
[0110]
随后,将参考图10进行描述。图10是示出根据本公开的第一实施方式的交互处理的示例的示图(4)。在图10的示例中,示出了在唤醒词和组合语音的属性为“先前语音”的情况下在只有用于处理的话语不足以作为用于生成响应的信息时生成的处理的示例。
[0111]
如图10所示,用户u01说出“明天唤醒我”,之后说出“请,计算机”。在缓冲了“明天唤醒我”的话语之后,智能扬声器10启动由“计算机”的唤醒词触发的交互系统,并启动交互处理。
[0112]
智能扬声器10基于“请”和“计算机”的组合确定唤醒词的属性为“先前语音”。即,智能扬声器10将用于处理的语音确定为唤醒词之前的语音(在图10的示例中,“明天唤醒我”)。智能扬声器10在启动之前分析“明天唤醒我”的话语,并确定动作。
[0113]
此时,智能扬声器10确定只有“明天唤醒我”的话语在唤醒用户u01的动作中缺少关于“用户希望什么时间唤醒”的信息(例如,将定时器设置为闹钟)。在这种情况下,为了实现“唤醒用户u01”的动作,智能扬声器10生成用于向用户u01询问作为该动作的目标的时间的响应。具体地,智能扬声器10向用户u01生成“我什么时间唤醒你?”的问题。此后,在从用
户u01新获得“在7点钟”的话语的情况下,智能扬声器10分析该话语,并设置定时器。在这种情况下,智能扬声器10可以确定动作已完成(确定对话将以低概率继续),并且可以立即停止交互系统。
[0114]
随后,将参考图11进行描述。图11是示出根据本公开的第一实施方式的交互处理的示例的示图(5)。在图11的示例中,示出了仅在唤醒词之前的话语足以作为用于在图10中所说明的示例中产生响应的信息时发生的处理的示例。
[0115]
如图11所示,用户u01说出“明天7点钟唤醒我”,之后说出“请,计算机”。智能扬声器10缓冲“明天7点钟唤醒我”的话语,启动“计算机”唤醒词触发的交互系统,启动处理。
[0116]
智能扬声器10基于“请”和“计算机”的组合确定唤醒词的属性为“先前语音”。即,智能扬声器10将用于处理的语音确定为唤醒词之前的语音(在图10的示例中,“明天7点钟唤醒我”)。智能扬声器10在启动之前分析“明天唤醒我”的话语,并确定动作。具体地,智能扬声器10将定时器设置为7点钟。然后智能扬声器10生成指示定时器已被设置的事实的响应,并且响应用户u01。在这种情况下,智能扬声器10可以确定动作已完成(确定对话将以低概率继续),并且可以立即停止交互系统。即,在确定属性是“先前语音”并且基于唤醒词之前的话语估计完成了交互处理的情况下,智能扬声器10可以立即停止交互系统。由此,用户u01能够仅告知智能扬声器10必要的内容,之后立即使智能扬声器10进入停止状态,从而能够节省进行超额响应的时间和精力,并且能够节省智能扬声器10的电力。
[0117]
以上已经参考图7至图11描述了根据本公开的交互处理的示例,但是这些示例仅仅是示例。智能扬声器10可以通过在除了上述情形之外的情形中参考缓冲的语音或唤醒词的属性来生成对应于各种情形的响应。
[0118]
1-3.根据第一实施方式的信息处理过程
[0119]
接下来,下面参照图12描述根据第一实施方式的信息处理过程。图12是示出根据本公开的第一实施方式的处理过程的流程图(1)。具体地,参考图12,下面描述根据第一实施方式的智能扬声器10生成对用户的话语的响应并输出所生成的响应的处理过程。
[0120]
如图12所示,智能扬声器10收集周围的语音(步骤s101)。智能扬声器10确定是否从所收集的语音中提取了话语(步骤s102)。如果没有从所收集的语音中提取话语(在步骤s102为否),则智能扬声器10不将语音存储在语音缓冲单元40中,并且继续收集语音的处理。
[0121]
另一方面,如果提取了话语,则智能扬声器10将所提取的话语存储在存储单元(语音缓冲单元40)中(步骤s103)。如果提取了话语,则智能扬声器10还确定交互系统是否正在启动(步骤s104)。
[0122]
如果没有启动交互系统(在步骤s104为否),则智能扬声器10确定话语是否包括唤醒词(步骤s105)。如果话语包括唤醒词(在步骤s105为是),则智能扬声器10启动交互系统(步骤s106)。另一方面,如果话语不包括唤醒词(在步骤s105为否),则智能扬声器10不启动交互系统,并且继续收集语音。
[0123]
在接收到话语并且启动了交互系统的情况下,智能扬声器10根据唤醒词的属性来确定要用于响应的话语(步骤s107)。然后,智能扬声器10对被确定为用于响应的话语执行语义理解处理(步骤s108)。
[0124]
此时,智能扬声器10确定是否获得了足以生成响应的话语(步骤s109)。如果没有
获得足以生成响应的话语(步骤s109为否),则智能扬声器10参考语音缓冲单元40,并确定是否存在缓冲的未处理话语(步骤s110)。
[0125]
如果存在缓冲的未处理话语(在步骤s110为是),则智能扬声器10参考语音缓冲单元40,并确定话语是否是预定时间内的话语(步骤s111)。如果话语是预定时间内的话语(在步骤s111为是),则智能扬声器10确定缓冲的话语是要用于响应处理的话语(步骤s112)。这是因为,即使存在被缓冲的语音,也假定比预定时间(例如,60秒)早的时间缓冲的语音对于响应处理是无效的。如上所述,智能扬声器10通过仅提取话语来对语音进行缓冲,使得可以与缓冲设置时间无关地缓冲在预定时间之前很久收集的话语。在这种情况下,假定与使用很久以前收集的话语进行处理的情况相比,通过从用户重新接收信息,提高了响应处理的效率。因此,智能扬声器10使用预定时间内的话语而不使用比预定时间早接收到的话语进行处理。
[0126]
如果获得了足以生成响应的话语(在步骤s109为是),如果没有缓冲的未处理话语(在步骤s110为否),并且如果缓冲的话语不是预定时间内的话语(在步骤s111为否),则智能扬声器10基于该话语生成响应(步骤s113)。在步骤s113,在没有缓冲的未处理的话语的情况下或者缓冲的话语不是预定时间内的话语的情况下产生的响应可以变成用于促使用户输入新信息的响应或者用于通知用户不能产生对来自用户的请求的应答的事实的响应。
[0127]
智能扬声器10输出所生成的响应(步骤s114)。例如,智能扬声器10将与所生成的响应相对应的字符串转换为语音,并经由扬声器再现响应内容。
[0128]
接下来,下面参照图13描述在输出响应之后的处理过程。图13是示出根据本公开的第一实施方式的处理过程的流程图(2)。
[0129]
如图13所示,智能扬声器10确定唤醒词的属性是否为“先前语音”(步骤s201)。如果唤醒词的属性是“先前语音”(在步骤s201为是),则智能扬声器10将等待时间设置为n作为等待用户的下一话语的时间(步骤s202)。另一方面,如果唤醒词的属性不是“先前语音”(在步骤s201为否),则智能扬声器10将等待时间设置为m作为等待用户的下一话语的时间(步骤s203)。n和m是可选的时间长度(例如,秒数),并且假定满足关系n<m。
[0130]
随后,智能扬声器10确定是否已经经过了等待时间(步骤s204)。在经过等待时间之前(在步骤s204为否),智能扬声器10确定是否检测到了新的话语(步骤s205)。如果检测到了新的话语(在步骤s205为是),智能扬声器10保持交互系统(步骤s206)。另一方面,如果没有检测到新的话语(在步骤s205为否),智能扬声器10等待直到检测到新的话语。如果已经经过了等待时间(在步骤s204为是),则智能扬声器10结束交互系统(步骤s207)。
[0131]
例如,在上述步骤s202,通过将等待时间n设置为极低的数值,当完成对来自用户的请求的响应时,智能扬声器10可以立即结束交互系统。等待时间的设置可以从用户接收,或者可以由智能扬声器10的管理者等执行。
[0132]
1-4.根据第一实施方式的变型例
[0133]
在上述第一实施方式中,例示了智能扬声器10将用户说出的唤醒词检测为触发的情况。然而,该触发不限于唤醒词。
[0134]
例如,在智能扬声器10包括作为传感器20的相机的情况下,智能扬声器10可以对通过对用户成像而获得的图像执行图像识别,并且从所识别的信息检测触发。例如,智能扬声器10可以检测注视智能扬声器10的用户的视线。在这种情况下,智能扬声器10可以通过
使用与视线检测相关的各种已知技术来确定用户是否正在注视智能扬声器10。
[0135]
在确定用户正在注视智能扬声器10的情况下,智能扬声器10确定用户期望来自智能扬声器10的响应,并且启动交互系统。即,智能扬声器10执行以下处理:读取所缓冲的语音以生成响应,并且输出由注视智能扬声器10的用户的视线触发的所生成的响应。这样,通过根据用户的视线执行响应处理,智能扬声器10可以在用户说出唤醒词之前执行用户想要的处理,从而可以进一步提高可用性。
[0136]
在智能扬声器10包括作为传感器20的红外传感器等的情况下,智能扬声器10可以检测通过感测用户的预定运动或到用户的距离而获得的信息作为触发。例如,智能扬声器10可以感测到用户接近智能扬声器10的预定距离范围(例如,1米)的事实,并且检测其接近的运动作为语音响应处理的触发。可替换地,例如,智能扬声器10可以检测用户从预定距离的范围之外接近智能扬声器10并且面对智能扬声器10的事实。在这种情况下,智能扬声器10可以通过使用与检测用户的运动相关的各种已知技术来确定用户接近智能扬声器10或者用户面对智能扬声器10。
[0137]
然后,智能扬声器10感测用户的预定运动或到用户的距离,并且在感测到的信息满足预定条件的情况下,智能扬声器10确定用户期望来自智能扬声器10的响应,并且启动交互系统。即,智能扬声器10执行读取缓存的语音以生成响应,并输出由用户面对智能扬声器10的事实、用户接近智能扬声器10的事实等触发的生成的响应的处理。通过这样的处理,智能扬声器10可以基于在用户执行预定动作等之前用户说出的语音做出响应。这样,通过估计用户期望基于用户的运动的响应,并执行响应处理,智能扬声器10可以进一步提高可用性。
[0138]
2.第二实施方式
[0139]
2-1.根据第二实施方式的语音处理系统的配置
[0140]
接下来,描述第二实施方式。在第一实施方式中,例示了由智能扬声器10执行根据本公开的语音处理的情况。另一方面,在第二实施方式中,例示了由语音处理系统2执行根据本公开的语音处理的情况,该语音处理系统2包括收集语音的智能扬声器10a和作为经由网络接收语音的服务器装置的信息处理服务器100。
[0141]
图14示出了根据第二实施方式的语音处理系统2的配置示例。图14是示出根据本公开的第二实施方式的语音处理系统2的配置示例的示图。
[0142]
智能扬声器10a是所谓的iot(物联网)设备,与信息处理服务器100协作执行各种信息处理。具体地,智能扬声器10a是用作根据本公开的语音处理(诸如与用户的交互的处理)的前端的设备,例如,在一些情况下,其被称为代理设备。根据本公开的智能扬声器10a可以是智能电话、平板终端等。在这种情况下,智能电话和平板终端执行具有与智能扬声器10a的功能相同的功能的计算机程序(应用),以显示上述代理功能。除了智能手机和平板终端之外,还可以通过手表型终端和眼镜型终端等可穿戴装置来实现由智能扬声器10a实现的语音处理功能。由智能扬声器10a实现的语音处理功能也可以由具有信息处理功能的各种智能设备来实现,并且例如可以由诸如电视、空调和冰箱的智能家用设备,诸如汽车、无人驾驶飞机或家庭机器人的智能车辆来实现。
[0143]
如图14所示,与根据第一实施方式的智能扬声器10相比,智能扬声器10a包括语音发送单元35。语音发送单元35除了包括根据第一实施方式的接收单元30之外还包括发送单
元34。
[0144]
发送单元34通过有线或无线网络等发送各种信息。例如,在检测到唤醒词的情况下,发送单元34向信息处理服务器100发送在检测到唤醒词之前收集的语音,即,在语音缓冲单元40中缓冲的语音。发送单元34可以不仅向信息处理服务器100发送所缓冲的语音,还发送在检测到唤醒词之后收集的语音。即,智能扬声器10a不执行与交互处理相关的功能,例如自己生成响应,而是将话语发送到信息处理服务器100,并使信息处理服务器100执行交互处理。
[0145]
图14所示的信息处理服务器100是所谓的云服务器,云服务器是与智能扬声器10a协同进行信息处理的服务器装置。在第二实施方式中,信息处理服务器100对应于根据本公开的语音处理装置。信息处理服务器100获取由智能扬声器10a收集到的语音,对收集到的语音进行分析,生成与分析出的语音对应的响应。然后,信息处理服务器100将所生成的响应发送到智能扬声器10a。例如,信息处理服务器100生成对用户说出的问题的响应,或者执行用于检索用户请求的歌曲并使智能扬声器10输出检索到的语音的控制处理。
[0146]
如图14所示,信息处理服务器100包括接收单元131、确定单元132、话语识别单元133、语义理解单元134、响应生成单元135和发送单元136。每个处理单元例如在由cpu、mpu等使用ram等作为工作区域执行存储在信息处理服务器100中的计算机程序(例如,根据本公开的记录介质中记录的语音处理程序)时实现。例如,每个处理单元还可以由诸如asic、fpga等的集成电路来实现。
[0147]
接收单元131接收与预定时间长度对应的语音和用于启动与该语音对应的预定功能的触发。即,接收单元131接收各种信息,诸如对应于由智能扬声器10a收集的预定时间长度的语音,指示智能扬声器10a已检测到唤醒词的信息等。然后,接收单元131将接收到的语音和与触发相关的信息传递给确定单元132。
[0148]
确定单元132、话语识别单元133、语义理解单元134和响应生成单元135执行与根据第一实施方式的交互处理单元50所执行的相同的信息处理。响应生成单元135将所生成的响应传递给发送单元136。发送单元136将所生成的响应发送到智能扬声器10a。
[0149]
这样,根据本公开的语音处理可以由诸如智能扬声器10a的代理设备和诸如信息处理服务器100的云服务器来实现,信息处理服务器100处理由代理设备接收的信息。即,根据本公开的语音处理也可以以设备的配置被灵活改变的模式来实现。
[0150]
3.第三实施方式
[0151]
接下来,描述第三实施方式。在第二实施方式中,描述了信息处理服务器100包括确定单元132并确定用于处理的语音的配置示例。在第三实施方式中,将描述包括确定单元51的智能扬声器10b在将语音发送到信息处理服务器100的在前步骤中确定用于处理的语音的示例。
[0152]
图15是示出根据本公开的第三实施方式的语音处理系统3的配置示例的示图。如图15所示,根据第三实施方式的语音处理系统3包括智能扬声器10b和信息处理服务器100b。
[0153]
与智能扬声器10a相比,智能扬声器10b还包括接收单元30、确定单元51和属性信息存储单元60。通过此配置,智能扬声器10b收集语音,且将收集到的语音存储在语音缓冲单元40中。所述智能扬声器10b还检测用于启动所述语音对应的预定功能的触发。在检测到
触发的情况下,智能扬声器10b根据触发的属性确定语音中用于执行预定功能的语音,并将用于执行预定功能的语音发送到信息处理服务器100。
[0154]
即,在检测到唤醒词之后,智能扬声器10b不发送所有缓冲的话语,而是自己执行确定处理,并且选择要发送的语音来执行向信息处理服务器100的发送处理。例如,在唤醒词的属性是“先前语音”的情况下,智能扬声器10b仅向信息处理服务器100发送在检测到唤醒词之前接收到的话语。
[0155]
通常,在网络上的云服务器等执行与交互相关的处理的情况下,存在对由于语音发送而导致的通信业务量增加的担心。然而,当要发送的语音被减少时,存在没有执行适当的交互处理的可能性。即,存在在减少通信业务量的同时应当实现适当的交互处理的问题。另一方面,通过根据第三实施方式的配置,可以在减少与交互处理相关的通信业务量的同时生成适当的响应,从而可以解决上述问题。
[0156]
在第三实施方式中,确定单元51可以响应于来自信息处理服务器100b的请求来确定要用于处理的语音。例如,假设信息处理服务器100b确定从智能扬声器10b发送的语音作为信息不足,并且不能生成响应。在这种情况下,信息处理服务器100b请求智能扬声器10b进一步发送过去缓冲的话语。智能扬声器10b参照话语数据41,在存在记录之后还没有经过预定时间的话语的情况下,智能扬声器10b将话语发送到信息处理服务器100b。这样,智能扬声器10b可以根据是否可以生成响应等来确定要新发送到信息处理服务器100b的语音。因此,信息处理服务器100b可以使用与所需数量对应的语音执行交互处理,从而可以执行适当的交互处理,同时节省其与智能扬声器10b之间的通信业务量。
[0157]
4.其他实施方式
[0158]
根据上述各个实施方式的处理可以以不同于上述实施方式的各种不同形式来执行。
[0159]
例如,可以将根据本公开的语音处理装置实现为智能电话等的功能,而不是诸如智能扬声器10的独立设备。根据本公开的语音处理装置还可以以安装在信息处理终端中的ic芯片等的模式来实现。
[0160]
根据本公开的语音处理装置可以具有向用户做出预定通知的配置。下面将通过示例智能扬声器10来描述这一点。例如,在通过使用在检测到触发之前收集的语音执行预定功能的情况下,智能扬声器10向用户做出预定通知。
[0161]
如上所述,根据本公开的智能扬声器10基于缓冲的语音执行响应处理。基于在唤醒词之前说出的语音执行这样的处理,从而可以防止用户花费过多的时间和精力。然而,可能使用户担心多久以前说出了基于其执行处理的语音。即,使用缓冲的语音响应处理可能使用户担心由于总是收集生活声音是否侵犯了隐私。换言之,这样的技术具有应当减少用户的焦虑的问题。另一方面,通过由智能扬声器10执行的通知处理向用户进行预定的通知,智能扬声器10能够给予用户安全感。
[0162]
例如,在执行预定功能时,智能扬声器10在检测到使用在触发之前收集的语音的情况与检测到使用在触发之后收集的语音的情况之间以不同的模式进行通知。作为示例,在通过使用缓冲的语音执行响应处理的情况下,智能扬声器10执行控制,使得从智能扬声器10的外表面发射红光。在通过使用唤醒词之后的语音来执行响应处理的情况下,智能扬声器10执行控制,使得从智能扬声器10的外表面发射蓝光。因此,用户可基于缓冲的语音,
或基于在唤醒词之后他/她自己说出的语音来识别对他/她自己的响应。
[0163]
智能扬声器10可以以进一步不同的模式进行通知。具体地,在执行预定功能时使用在检测到触发之前收集的语音的情况下,智能扬声器10可以向用户通知与所使用的语音对应的日志。例如,智能扬声器10可以将实际用于响应的语音转换成要在包括在智能扬声器10中的外部显示器上显示的字符串。参考图1作为示例,智能扬声器10在外部显示器上显示“看起来要下雨”和“告诉我天气”的字符串,并连同该显示器一起输出响应语音r01。因此,用户能够准确地识别哪个话语被用于处理,使得用户能够从隐私保护的角度获得安全感。
[0164]
智能扬声器10可以经由预定装置显示用于响应的字符串,而不是在智能扬声器10上显示字符串。例如,在使用缓冲的语音进行处理的情况下,智能扬声器10可以将与用于处理的语音对应的字符串发送到预先登记的智能电话等终端。由此,用户能够准确地掌握使用哪种语音进行处理,不使用哪种字符串进行处理。
[0165]
智能扬声器10还可以做出指示所缓冲的语音是否被发送的通知。例如,在没有检测到触发并且没有发送语音的情况下,智能扬声器10执行控制以输出指示该事实的显示(例如,以输出蓝色光)。另一方面,在检测到触发的情况下,发送所缓冲的语音,并且随后的语音用于执行预定功能,智能扬声器10执行控制以输出指示该事实的显示(例如,输出红色光)。
[0166]
智能扬声器10还可以接收来自接收到该通知的用户的反馈。例如,在做出使用所缓冲的语音的通知之后,智能扬声器10从用户接收建议使用诸如“否,使用较早的话语”的另外的先前话语的语音。在这种情况下,例如,智能扬声器10可以执行预定的学习处理,例如延长缓冲时间,或者增加要发送到信息处理服务器100的话语的数量。即,智能扬声器10可以基于用户对预定功能的执行的反应来调整在检测到触发之前收集的并且用于执行预定功能的语音的信息量。因此,智能扬声器10可以执行更适合于用户的使用模式的响应处理。
[0167]
在各个实施方式中的上述处理的片段中,描述为自动执行的处理的片段的全部或部分也可以手动执行,或者描述为手动执行的处理的片段的全部或部分也可以使用公知的方法自动执行。另外,除非另外特别指出,否则在此描述和在附图中示出的包括处理过程、特定名称、各种数据和参数的信息可以可选地改变。例如,附图中所示的各种信息不限于其中所示的信息。
[0168]
附图中所示的设备的部件仅仅是概念性的,并且不要求这些部件按所需物理配置。即,装置的分配和集成的具体形式不限于附图中所示的那些。其全部或部分可以在功能上或物理上分布/集成在任意单元中,这取决于各种负荷或使用状态。话语提取单元32和检测单元33可以彼此集成。
[0169]
上述实施方式和修改可以在不与处理内容矛盾的情况下适当组合。
[0170]
这里描述的效果仅仅是示例,并且效果不限于此。可以显示出其他效果。
[0171]
5.硬件配置
[0172]
根据上述实施方式的诸如智能扬声器10或信息处理服务器100的信息装置由具有例如图16所示的配置的计算机1000来实现。下面举例说明根据第一实施方式的智能扬声器10。图16是示出了实现智能扬声器10的功能的计算机1000的示例的硬件配置图。计算机
1000包括cpu 1100、ram 1200、rom(只读存储器)1300、hdd(硬盘驱动器)1400、通信接口1500和输入/输出接口1600。计算机1000的各个部分经由总线1050彼此连接。
[0173]
cpu 1100基于存储在rom 1300或hdd 1400中的计算机程序进行操作,并控制各个部分。例如,cpu 1100将存储在rom 1300或hdd 1400中的计算机程序加载到ram 1200中,并执行与各种计算机程序对应的处理。
[0174]
rom 1300存储在计算机1000启动时由cpu 1100执行的bios(基本输入输出系统)等引导程序,以及取决于计算机1000的硬件的计算机程序等。
[0175]
hdd 1400是非临时地记录由cpu 1100执行的计算机程序、由计算机程序使用的数据等的计算机可读记录介质。具体而言,hdd 1400是记录作为程序数据1450的示例的根据本公开的语音处理程序的记录介质。
[0176]
通信接口1500是用于将计算机1000连接到外部网络1550(例如,因特网)的接口。例如,cpu 1100经由通信接口1500从另一设备接收数据,或者将由cpu 1100生成的数据发送到另一设备。
[0177]
输入/输出接口1600是用于将输入/输出装置1650与计算机1000连接的接口。例如,cpu 1100经由输入/输出接口1600从诸如键盘和鼠标的输入装置接收数据。cpu 1100经由输入/输出接口1600将数据发送到输出装置,例如显示器、扬声器和打印机。输入/输出接口1600可以用作介质接口,该介质接口读取记录在预定记录介质(媒介)中的计算机程序等。媒介的示例包括诸如dvd(数字多功能盘)和pd(相变可重写盘)的光记录介质、诸如mo(磁光盘)的磁光记录介质、磁带介质、磁记录介质、半导体存储器等。
[0178]
例如,在计算机1000用作根据第一实施方式的智能扬声器10的情况下,计算机1000的cpu 1100执行加载到ram 1200中的语音处理程序以实现接收单元30的功能等。hdd 1400将根据本公开的语音处理程序和数据存储在语音缓冲单元40中。cpu 1100从要执行的hdd 1400读取程序数据1450。或者,作为另一示例,cpu 1100可经由外部网络1550从另一装置获取这些计算机程序。
[0179]
本技术可采用以下配置。
[0180]
(1)
[0181]
一种语音处理装置,包括:
[0182]
接收单元,被配置为接收与预定时间长度对应的语音和与用于启动与所述语音对应的预定功能的触发相关的信息;以及
[0183]
确定单元,被配置为根据由接收单元接收的与触发相关的信息,在与预定时间长度对应的语音中确定用于执行预定功能的语音。
[0184]
(2)
[0185]
根据(1)所述的语音处理装置,其中,所述确定单元根据与所述触发相关的信息,将与所述预定时间长度对应的所述语音中在所述触发之前说出的语音确定为用于执行所述预定功能的语音。
[0186]
(3)
[0187]
根据(1)所述的语音处理装置,其中,所述确定单元根据与所述触发相关的信息,将与所述预定时间长度对应的所述语音中在所述触发之后说出的语音确定为用于执行所述预定功能的语音。
[0188]
(4)
[0189]
根据(1)所述的语音处理装置,其中,所述确定单元根据与所述触发相关的信息,将与所述预定时间长度对应的所述语音中的在所述触发之前说出的语音和在所述触发之后说出的语音进行组合而获得的语音确定为用于执行所述预定功能的语音。
[0190]
(5)
[0191]
根据(1)至(4)中任一项所述的语音处理装置,其中所述接收单元接收与唤醒词相关的信息作为与所述触发相关的信息,所述唤醒词为用于启动所述预定功能的所述触发的语音。
[0192]
(6)
[0193]
根据(5)所述的语音处理装置,其中,所述确定单元根据先前为所述唤醒词设置的属性,在与所述预定时间长度对应的所述语音中确定用于执行所述预定功能的语音。
[0194]
(7)
[0195]
根据(5)所述的语音处理装置,其中,所述确定单元根据与所述唤醒词和在所述唤醒词之前或之后检测到的语音的每个组合相关联的属性,在与所述预定时间长度对应的所述语音中确定用于执行所述预定功能的语音。
[0196]
(8)
[0197]
根据(6)或(7)所述的语音处理装置,其中,在根据所述属性将与所述预定时间长度对应的所述语音中在所述触发之前说出的语音确定为用于执行所述预定功能的语音的情况下,所述确定单元在执行所述预定功能的情况下结束与所述唤醒词对应的会话。
[0198]
(9)
[0199]
根据(1)至(8)中任一项所述的语音处理装置,其中,所述接收单元从与所述预定时间长度对应的所述语音中提取由用户说出的话语部分,并且接收所提取的话语部分。
[0200]
(10)
[0201]
根据(9)所述的语音处理装置,其中
[0202]
接收单元接收所提取话语部分以及唤醒词,所述唤醒词为用于启动预定功能的触发的语音,以及
[0203]
所述确定单元将所述话语部分中与说出所述唤醒词的用户相同的用户的话语部分确定为用于执行所述预定功能的语音。
[0204]
(11)
[0205]
根据(9)所述的语音处理装置,其中
[0206]
所述接收单元接收所提取的话语部分以及唤醒词,所述唤醒词为为用于启动预定功能的触发的语音,以及
[0207]
所述确定单元将话语部分中与说出所述唤醒词的用户相同的用户的话语部分以及预先登记的预定用户的话语部分,确定为用于执行预定功能的语音。
[0208]
(12)
[0209]
根据(1)至(11)中任一项所述的语音处理装置,其中,所述接收单元接收与通过对所述用户成像而获得的图像执行图像识别而检测到的用户的注视视线相关的信息作为与所述触发相关的信息。
[0210]
(13)
[0211]
根据(1)至(12)中任一项所述的语音处理装置,其中所述接收单元接收通过感测用户的预定运动或到所述用户的距离而获得的信息作为与所述触发相关的信息。
[0212]
(14)
[0213]
一种语音处理方法,由计算机执行,所述语音处理方法包括:
[0214]
接收与预定时间长度对应的语音和与用于启动与所述语音对应的预定功能的触发相关的信息;以及
[0215]
根据接收到的与所述触发相关的信息,在与所述预定时间长度对应的语音中确定用于执行所述预定功能的语音。
[0216]
(15)
[0217]
一种计算机可读非暂时性记录介质,记录有语音处理程序,所述语音处理程序用于使计算机用作:
[0218]
接收单元,被配置为接收与预定时间长度对应的语音和与用于启动与所述语音对应的预定功能的触发相关的信息;以及
[0219]
确定单元,被配置为根据由接收单元接收的与触发相关的信息,在与预定时间长度对应的语音中确定用于执行预定功能的语音。
[0220]
(16)
[0221]
一种语音处理装置,包含:
[0222]
声音收集单元,被配置为收集语音并将收集到的语音存储在存储单元中;
[0223]
检测单元,被配置为检测用于启动与所述语音对应的预定功能的触发;
[0224]
确定单元,被配置为在所述检测单元检测到所述触发的情况下,根据与所述触发相关的信息来确定所述语音中用于执行所述预定功能的语音;以及
[0225]
发送单元,被配置为向执行所述预定功能的服务器装置发送由所述确定单元确定为用于执行所述预定功能的语音。
[0226]
(17)
[0227]
一种语音处理方法,由计算机执行,所述语音处理方法包括:
[0228]
收集语音,并将收集到的语音存储在存储单元中;
[0229]
检测用于启动与所述语音对应的预定功能的触发;
[0230]
在检测到所述触发的情况下,根据与所述触发相关的信息在所述语音中确定用于执行所述预定功能的语音;以及
[0231]
向执行预定功能的服务器装置发送被确定为用于执行所述预定功能的语音。
[0232]
(18)
[0233]
一种计算机可读非暂时性记录介质,记录有语音处理程序,所述语音处理程序用于使计算机用作:
[0234]
声音收集单元,被配置为收集语音并将收集到的语音存储在存储单元中;
[0235]
检测单元,被配置为检测用于启动与所述语音对应的预定功能的触发;
[0236]
确定单元,被配置为在所述检测单元检测到所述触发的情况下,根据与所述触发相关的信息来确定所述语音中用于执行所述预定功能的语音;以及
[0237]
发送单元,被配置为向执行所述预定功能的服务器装置发送由所述确定单元确定为用于执行所述预定功能的语音。
[0238]
符号说明
[0239]
1、2、3 语音处理系统
[0240]
10、10a、10b智能扬声器
[0241]
100、100b 信息处理服务器
[0242]
31声音收集单元
ꢀꢀꢀ
32话语提取单元
ꢀꢀꢀ
33检测单元
[0243]
34发送单元
ꢀꢀꢀꢀꢀꢀꢀ
35语音发送单元
ꢀꢀꢀ
40语音缓冲单元
[0244]
41话语数据
ꢀꢀꢀꢀꢀꢀꢀ
50交互处理单元
ꢀꢀꢀ
51确定单元
[0245]
52话语识别单元
ꢀꢀꢀ
53语义理解单元
ꢀꢀꢀ
54交互管理单元
[0246]
55响应生成单元
ꢀꢀꢀ
60属性信息存储单元
[0247]
61组合数据
ꢀꢀꢀꢀꢀꢀꢀ
62唤醒词数据。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1