声学事件识别装置、方法和程序与流程
本技术涉及声学事件识别装置、方法和程序,尤其涉及能够在事后添加识别目标的声学事件识别装置、方法和程序。
背景技术:
传统上,基于声学信号识别声学事件的声学事件识别系统是已知的。
例如,作为与声学事件的识别相关的技术,已经提出了与其中预先准备识别目标的声学事件识别系统(例如,参见专利文献1)和用于在语音识别中从对话获得未知单词的系统(例如,参见专利文献2)相关的技术。
引用列表
专利文献
专利文献1:日本专利申请特开no.2015-49398
专利文献2:日本专利申请特开no.2003-271180
技术实现要素:
本发明要解决的问题
然而,在上述技术中,在声学事件识别系统中预先固定识别目标,并且不考虑声学事件识别系统在事后添加识别目标。即,只将预定声学事件设置为识别目标。
因此,在这种声学事件识别系统中,由用户呈现的声学事件不能在事后添加为识别目标。此外,由声学事件识别系统本身根据环境获得的声学事件也不能在事后添加为识别目标。
例如,根据专利文献1中公开的技术,预先准备待作为识别目标的声学事件,由此不能在事后添加识别目标。此外,虽然专利文献1公开了作为获得待用于生成模型数据的一般声音数据的方法而预先从语料库获得一般声音数据的示例,但是其几乎未提及与识别目标的设计相关的一般声音数据获取单元。
此外,根据专利文献2中公开的技术,可以通过在与用户的交互中获得未知单词并将其存储在存储器中来注册未知声学类别。然而,其基于以下假设,即,未知单词(即,具有语言信息的单词)的注册与语音识别相关联,未提及没有语言信息的声学事件,并且不能在事后添加识别目标。
鉴于这种情况构思了本技术,并且本技术旨在能够在事后添加识别目标。
问题的解决方案
根据本技术的一个方面的声学事件识别装置包括:获取单元,其获取由用户呈现的声学信号的特征量或环境声音的声学信号的特征量作为新声学事件的候选的特征量;和识别单元,其保留用于识别预定声学事件的参数,基于所述参数和所获取的特征量执行声学事件识别,并且在所述预定声学事件未被识别的情况下,保留所获取的特征量作为所述新声学事件的特征量。
根据本技术的一个方面的用于识别声学事件的方法或程序获取由用户呈现的声学信号的特征量或环境声音的声学信号的特征量作为新声学事件的候选的特征量;基于用于识别预定声学事件的参数和所获取的特征量来执行声学事件识别;和在所述预定声学事件未被识别的情况下,保留所获取的特征量作为所述新声学事件的特征量。
根据本技术的一个方面,获取由用户呈现的声学信号的特征量或环境声音的声学信号的特征量作为新声学事件的候选的特征量;基于用于识别预定声学事件的参数和所获取的特征量来执行声学事件识别;和在所述预定声学事件未被识别的情况下,保留所获取的特征量作为所述新声学事件的特征量。
附图说明
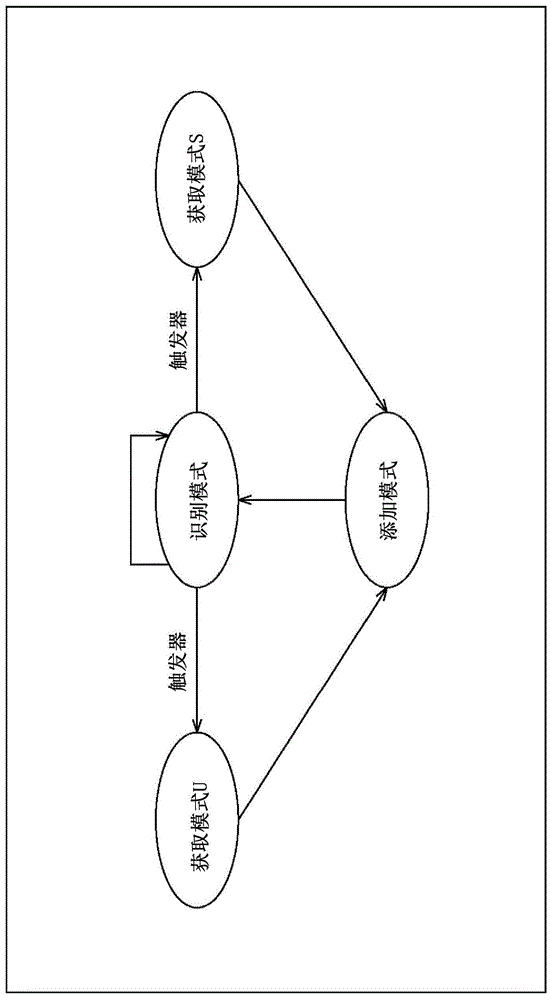
图1是示出操作模式转换的示意图。
图2是示出声学事件识别装置的示例性配置的示意图。
图3是示出系统支持的范围的示意图。
图4是示出用于基于来自用户的呈现获得特征量的处理的流程图。
图5是示出用于基于系统的获取来获得特征量的处理的流程图。
图6是示出映射、聚类和聚类选择的示意图。
图7是示出识别目标添加处理的流程图。
图8是示出对应于特征量的声学事件及其添加处理的示意图。
图9是示出识别处理的流程图。
图10是示出声学事件识别装置的示例性配置的示意图。
图11是示出声学事件识别装置的示例性配置的示意图。
图12是示出声学事件识别装置的示例性配置的示意图。
图13是示出机器人系统的示例性配置的示意图。
图14是示出计算机的示例性配置的示意图。
具体实施方式
在下文中,将参考附图描述应用本技术的实施例。
<第一实施例>
<声学事件识别装置的示例性配置>
本技术涉及能够在事后添加识别目标的声学事件识别系统。
在这里,声学事件表示具有诸如环境声音和音乐声音的共同声学特征的事件,包括例如拍掌声、铃声、哨声、脚步声、汽车引擎声、鸟鸣声等。此外,声学事件识别指示从记录的声学信号中识别目标声学事件。
在本技术中,例如,如图1所示,有识别模式、获取模式和添加模式作为操作模式。
例如,当系统启动时,操作模式进入识别模式,并且在识别模式中从输入声学信号识别声学事件。
在识别模式中,连续重复识别声学事件的处理,除非存在预定的触发,例如通过例如用户按压按钮等做出的转换到获取模式的指令。然后,当操作模式为识别模式期间发生触发时,操作模式从识别模式转换到获取模式。
在获取模式中,从输入声学信号获得特定部分的特征量(声学特征量)。特别地,在本示例中,获取模式包括从用户呈现的声学信号获得特征量的获取模式u,以及从系统获得的声学信号获得特征量的获取模式s。
因此,例如,当在操作模式为识别模式期间发生转换到获取模式u的触发时,操作模式从识别模式转换到获取模式u。
然后,在获取模式u中,从用户呈现的声学信号获得特征量。当以这种方式获得特征量时,此后操作模式从获取模式转换到添加模式,而不特别需要触发。
同时,当在操作模式为识别模式期间发生转换到获取模式s的触发时,操作模式从识别模式转换到获取模式s。
然后,在获取模式s中,从系统获得的声学信号中获得特征量。由这里提到的系统获得的声学信号表示例如由收集周围环境声音的系统获得的声学信号。当以这种方式获得特征量时,操作模式此后从获取模式转换到添加模式,而不特别需要触发。
当操作模式从获取模式u或获取模式s转换到添加模式时,在添加模式中,在事后添加与在获取模式u或获取模式s中获得的特征量相对应的声学事件作为识别目标。
当作为新识别目标的声学事件以这种方式在事后添加时,此后操作模式从添加模式转换到识别模式,而不特别需要触发。
根据本技术,从用户在获取模式u中呈现的声学信号中获得特征量,由此使得系统能够记住由用户指定的声学事件作为添加模式中事后的识别目标。
此外,特征量是从系统在获取模式s下获得的声学信号中获得的,由此系统可以使系统本身根据环境记住声学事件作为添加模式中事后的识别目标。
获取模式s在以下情况下尤其有用,例如,当已知声学事件发生在相当长的时间段内(例如一天或一小时)时,难以知道声学事件何时发生,期望对在预定定时周期性发生的声学事件执行一些处理的情况等。
请注意,在不特别要求将获取模式u和获取模式s彼此区分的情况下,在以下描述中将简单地称其为获取模式。
接下来,将描述实现这种声学事件识别系统的声学事件识别装置。
图2是示出根据实施例的应用了本技术的声学事件识别装置的示例性配置的示意图。
图2所示的声学事件识别装置11包括特征量提取单元21、识别单元22、标志管理单元23、获取单元24和控制单元25。
特征量提取单元21从系统输入的声学信号中提取特征量,以将其提供给识别单元22和获取单元24。例如,当操作模式为获取模式时,将由特征量提取单元21提取的特征量提供给获取单元24,并且当操作模式为识别模式时,将其提供给识别单元22。
识别单元22基于所提供的声学事件模型和从特征量提取单元21提供的特征量来识别声学事件。换言之,识别单元22参考声学事件模型,并从特征量输出声学事件识别结果。
这里,声学事件模型是指示特征量和声学事件之间的对应关系的信息,并且包括通过先前学习等获得的各种参数,例如函数、系数和特征量。
识别单元22包括标签内识别单元31和相似性/差异性确定单元32,标签内识别单元31识别预先附接的标签的范围内的声学事件,相似性/差异性确定单元32确定与所获得的声学事件的相似性/差异性,而与标签无关。
标签内识别单元31保留通过预先学习获得并在可选定时提供的声学事件模型,即,声学事件模型中包括的参数。
标签内识别单元31基于所保留的声学事件模型和所提供的特征量来识别预先附接的标签范围内的声学事件。
这里,在预先附接的标签的范围内的声学事件指示待由声学事件模型识别的声学事件,该声学事件模型由在学习声学事件模型时添加了正确答案数据的标签的学习数据指示。
因此,在使用声学事件模型的声学事件识别中,获得所提供的特征量是否对应于预定的一个或多个声学事件中的任何一个或者不对应于它们中的任何一个作为声学事件识别结果。换言之,在使用声学事件模型的声学事件识别中,识别预定的声学事件。
例如,在声学事件模型,即标签内识别单元31包括卷积神经网络(cnn)等的情况下,标签内识别单元31通过将特征量代入声学事件模型(cnn)来执行操作,从而获得声学事件识别结果作为操作的输出。
相似性/差异性确定单元32包括例如通过度量学习生成的诸如暹罗网络的声学模型,并且保留在获取模式中获得的标签范围之外的声学事件的特征量作为在事后添加的声学事件的特征量。
在识别模式中,相似性/差异确定单元32确定从特征量提取单元21提供的可选声学信号的特征量和保留的特征量之间的相似性/差异性,从而确定对应于所提供的特征量的声学事件是否是事后添加的声学事件。
具体地,例如,在相似性/差异性确定单元32包括暹罗网络的情况下,相似性/差异性确定单元32使用所提供的特征量和所保留的特征量作为暹罗网络的输入,并且在特征空间中映射那些特征量。
然后,相似性/差异性确定单元32计算特征空间中那些特征量之间的距离,并对获得的距离执行阈值处理,从而执行相似性/差异性确定。例如,在所获得的距离等于或小于预定阈值的情况下,对应于所提供的特征量的声学事件被确定为对应于所保留的特征量的声学事件,即,在事后添加的声学事件。
注意,在下文中,由标签内识别单元31识别的标签范围内的声学事件也被称为标签内声学事件,并且在由相似性/差异性确定单元32识别的事后添加的声学事件也被称为附加声学事件。
识别单元22向标志管理单元23输出由标签内识别单元31执行的声学事件识别的结果或者由相似性/差异性确定单元32执行的相似性/差异性确定的结果,作为识别单元22中的声学事件识别结果。
标志管理单元23管理标志表。该标志表示出了由识别单元22输出的声学事件识别结果和由系统(声学事件识别装置11)输出的声学事件识别结果之间的对应关系。
具体地,该标志表包括为每个标签内声学事件和附加声学事件生成的标志。声学事件的标志指示当识别单元22识别声学事件时,是否输出指示系统(声学事件识别装置11)已经识别声学事件的声学事件识别结果。换言之,声学事件的标志是指示是否输出由识别单元22输出的声学事件识别结果作为系统的最终声学事件识别结果的信息,即,指示是启用还是禁用识别单元22的输出的信息。
标志管理单元23管理标志表,并作为系统(声学事件识别装置11)从识别单元22输出的声学事件识别结果中输出声学事件识别结果。
因此,例如,利用由标志管理单元23改变的声学事件的标志的值,可以将预定的标签内声学事件视为好像它是在事后添加的声学事件。即,系统(声学事件识别装置11)能够像在事实发生之后学习预定的标签内声学事件一样工作。
在获取模式中,获取单元24从输入的声学信号中获取特定部分的特征量,并将其提供给识别单元22。即,获取单元24获取在获取模式下从特征量提取单元21提供的特征量,作为待作为识别目标新添加(在事后)的声学事件的候选特征量并将其提供给识别单元22。
注意,这里将描述获取单元24从特征量提取单元21获得特征量的示例。然而,不限于此,获取单元24可以经由有线或无线网络与云服务器等通信,以从服务器等接收特征量,从而获得特征量。
控制单元25控制识别单元22、标志管理单元23和获取单元24。
在声学事件识别装置11中,获取单元24、识别单元22和标志管理单元23在控制单元25的控制下以互锁的方式操作,由此将与在获取模式中获得的特征量相对应的声学事件添加为识别目标,使得此后可以识别声学事件。也就是说,有可能使系统记住该声学事件。
具体地,通过获取单元24从特征量提取单元21获得特征量,可以获得在事后作为识别目标添加的声学事件的特征量。此外,相似性/差异性确定单元32保留附加声学事件的特征量,并且使用该特征量来执行相似性/差异性确定,由此即使在声学事件在标签范围之外的情况下也可以识别声学事件。
利用以这种方式提供的获取单元24和相似性/差异性确定单元32,标签范围之外的声学事件也可以作为事后的识别目标。
通过进一步提供标志管理单元23,可以通过识别单元22调整声学事件识别结果的输出和作为系统调整声学事件识别结果的输出。
因此,例如,即使在识别单元22识别声学事件的情况下,系统也可以输出声学事件识别结果,就好像声学事件没有被识别一样。
图3示出了由本申请人提出的系统(声学事件识别装置11)支持的范围。
本系统(声学事件识别装置11)除了识别模式之外还具有获取模式和添加模式,并且能够在事后添加识别目标。
除了标签内识别单元31和标志管理单元23之外,本系统(即,声学事件识别装置11)还包括相似性/差异性确定单元32,并且支持标签范围之外的声学事件的添加和识别。
<特征量获取处理的描述>
接下来,将描述声学事件识别装置11的操作。
首先,将参照图4和图5描述获取模式下的操作。
图4示出了用于解释特征量获取处理的流程图,该特征量获取处理用于获得从用户在获取模式u下呈现的声学信号中提取的特征量。在下文中,将参考图4的流程图来描述由声学事件识别装置11执行的用户呈现声学信号的情况下的特征量获取处理。
在步骤s11中,控制单元25为获取单元24指定特征量获取部分。
在步骤s12中,获取单元24从特征量提取单元21提供的特征量中获取由控制单元25在步骤s11的处理中指定的获取部分(指定部分)的特征量,并将其提供给识别单元22。
当以这种方式获得特征量时,特征量获取处理终止。注意,除了特征量之外,还可以获得声学信号作为辅助信息。
如上所述,声学事件识别装置11从用户在获取模式u中呈现的声学信号中获得特征量。利用这种布置,在获取模式u中,可以使系统记住由用户指定(呈现)为识别目标的声学事件。
接下来,将参照图5的流程图描述在声学事件识别装置11(系统)自身根据获取模式s中的环境获取特征量的情况下的特征量获取处理。
在步骤s41,控制单元25为获取单元24指定特征量参考部分。这里,参考部分表示具有特定长度的部分,例如,一天、一小时等。
在指定的参考部分中,由于向特征量提取单元21顺序地提供声学事件识别装置11周围的声音,即,通过收集周围环境声音获得的声学信号,所以特征量提取单元21从所提供的声学信号中顺序地提取特征量,并将其提供给获取单元24。
在步骤s42中,获取单元24在特征空间中顺序地映射从特征量提取单元21提供的特征量中由控制单元25在步骤s41的处理中指定的参考部分的特征量。例如,整个参考部分被分成几个连续的部分,并且将在这些部分的每一个中获得的特征量映射到特征空间中。
在步骤s43中,获取单元24对映射的特征量组进行聚类。
在步骤s44中,获取单元24选择通过聚类获得的预定聚类。
在步骤s45中,获取单元24获得与在步骤s44中选择的聚类相关的特征量,并将其提供给识别单元22。具体地,例如,获取单元24获得代表值,例如属于在步骤s44中选择的聚类的多个特征量的平均值和中值,并将以这种方式获得的代表值作为与该聚类相关的特征量提供给识别单元22。注意,除了特征量之外,可以获得声学信号作为辅助信息。
这里,图6示出了映射、聚类和聚类选择的概念。也就是说,图6示出了映射、聚类和聚类选择的概念图。
特别地,在图6中,由箭头q11指示的部分示出了特征空间中的特征量的映射,由箭头q12指示的部分示出了示例性聚类,由箭头q13指示的部分示出了示例性聚类选择。
虽然在箭头q11指示的部分中示出了二维特征空间,并且特征空间中的每个点表示由获取单元24获得并在特征空间中映射的一个特征量,但是特征空间的维数可以是任意数。例如,可以认为梅尔频率倒谱系数(mfcc)是一个特征空间。
此外,由虚线包围的部分表示由箭头q12指示的部分中的一个聚类,并且在这种情况下,将在特征空间中映射的特征量组聚类成两个聚类。比如可以将k-means聚类认为是聚类。
此外,由箭头q13指示的部分指示图中左侧的聚类是从由箭头q12指示的部分中的两个聚类中选择的。这里,作为选择聚类的方法,可以想到选择聚类中包括的元素的数量等于或大于第一阈值并且等于或小于第二阈值的聚类。当以这种方式选择聚类时,获得属于所选聚类的特征量的代表值,并且将该代表值作为与该聚类相关的特征量提供给识别单元22。
回到图5的流程图的解释,当获取单元24获取特征量时,特征量获取处理终止。
如上所述,声学事件识别装置11本身在获取模式s中根据环境获得特征量。利用这种布置,在获取模式s中,系统可以使系统本身根据环境记住声学事件作为识别目标。
<识别目标添加处理的描述>
接下来,将描述添加模式下的操作。
也就是说,在下文中,将参考图7的流程图描述由声学事件识别装置11执行的识别目标添加处理。
在获取模式u或获取模式s中获得特征量之后,当操作模式转换到添加模式时,识别目标添加处理开始。在识别目标添加处理中,添加与通过参考图4和5描述的特征量获取过程获得的特征量相对应的声学事件作为识别目标。
在步骤s71中,标签内识别单元31确定其是否是标签内的声学事件。即,标签内识别单元31基于在获取模式下从获取单元24提供的特征量和预先保留的声学事件模型来识别声学事件,并输出作为其结果获得的声学事件识别结果。
在标签内识别单元31不输出声学事件识别结果的情况下,即,在指示标签内声学事件未被识别的声学事件识别结果的情况下,在步骤s71中确定不是标签内的声学事件,并且处理进行到步骤s72。
在步骤s72中,相似性/差异性确定单元32设置相似性/差异性确定单元32来确定与声学事件的相似性/差异性,然后处理进行到步骤s74。
也就是说,在步骤s72中,相似性/差异性确定单元32保留在获取模式下从获取单元24提供的特征量作为附加声学事件的特征量。
具体地,例如,相似性/差异性确定单元32将指示新的附加声学事件的标签信息“未知1”和附加声学事件的特征量彼此关联地保留。
在步骤s74中,标志管理单元23在识别声学事件时启用标志,并且识别目标添加处理终止。
例如,在步骤s72中将指示新的附加声学事件的标签信息“未知1”和特征量彼此关联地保留的情况下,标志管理单元23生成由标签信息“未知1”指示的附加声学事件的标志,并启用该标志。也就是说,将附加声学事件的启用标志添加到标志表。
另一方面,在步骤s71中确定声学事件在标签内的情况下,即,在输出声学事件识别结果的情况下,标签内识别单元31将声学事件识别结果提供给标志管理单元23,然后处理进行到步骤s73。
在步骤s73中,标志管理单元23基于从识别单元22提供的声学事件识别结果,确定由声学事件识别结果指示的声学事件的标志是否在保留的标志表中启用。
在步骤s73中确定声学事件的标志启用的情况下,不执行特定处理,并且识别目标添加处理终止。
另一方面,在步骤s73中确定声学事件的标志未启用的情况下,即,在对应于声学事件识别结果的声学事件的标志禁用的情况下,处理进行到步骤s74。
在步骤s74中,标志管理单元23在标志表中启用在步骤s73中确定为未启用的声学事件的标志,并且识别目标添加处理终止。
如上所述,声学事件识别装置11适当地将声学事件添加为识别目标。
这里,图8示出了其中对应于所获得的特征量的声学事件及其在添加模式下的附加处理的表格。
在该示例中,在标签内有作为声学事件识别结果的输出并且相应声学事件的标志被启用的情况下,不执行特定处理。
此外,在标签内存在作为声学事件识别结果的输出并且标志被禁用的情况下,启用在识别相应声学事件时的标志,并且此后,以类似于预先准备的识别目标的方式处理该标志。
在标签内没有声学事件识别结果的输出的情况下,将相似性/差异性确定单元32设置为确定与要添加的声学事件的相似性/差异性,启用在确定为与要添加的声学事件相同时的动作标志,并且此后,以类似于预先准备的识别目标的方式处理该标志。
<识别处理的描述>
此外,将参照图9描述识别模式下的操作。也就是说,在下文中,将参考图9的流程图描述由声学事件识别装置11执行的识别处理。
在步骤s101中,特征量提取单元21从已经输入的声学信号(输入声学信号)中提取特征量,并将提取的结果提供给识别单元22。
在步骤s102中,识别单元22的标签内识别单元31基于从特征量提取单元21提供的特征量和保留的声学事件模型来执行标签内声学事件的声学事件识别,并输出声学事件识别的结果,从而确定对应于所提供的特征量的声学事件是否是标签内的声学事件。
在步骤s102中确定不是标签内的声学事件的情况下,在步骤s103中,相似性/差异性确定单元32基于特征量输出声学事件识别结果,从而确定其是否是标签外部添加的声学事件。
即,相似性/差异性确定单元32基于保留的附加声学事件的特征量和从特征量提取单元21提供的特征量来执行附加声学事件的声学事件识别(相似性/差异性确定),并输出声学事件识别结果。
例如,在相似性/差异性确定单元32不输出声学事件识别结果的情况下,即,在获得指示对应于所提供的特征量的声学事件不是附加声学事件的识别结果的情况下,确定不是标签外部添加的声学事件。
注意,在识别模式中,在由标签内识别单元31执行的声学事件识别中没有识别出标签内声学事件的情况下,相似性/差异性确定单元32可以执行相似性/差异性确定,或者由标签内识别单元31执行的声学事件识别和由相似性/差异性确定单元32执行的相似性/差异性确定可以同时(并行)执行。
在步骤s103中确定不是标签外部添加的声学事件的情况下,在步骤s104中,标志管理单元23不作为系统(声学事件识别装置11)执行输出,并且识别处理终止。
另一方面,在步骤s103中确定为标签外部添加的声学事件的情况下,相似性/差异性确定单元32将声学事件识别结果输出到标志管理单元23,然后处理进行到步骤s105。
此外,在步骤s102中确定声学事件在标签内的情况下,标签内识别单元31将声学事件识别结果输出到标志管理单元23,然后处理进行到步骤s105。
在步骤s102中确定声学事件在标签内或者在步骤s103中确定为在标签外添加的声学事件的情况下,执行步骤s105的处理。
在步骤s105中,标志管理单元23基于从识别单元22提供的声学事件识别结果来确定相应声学事件的标志是否被启用。
在步骤s105中确定声学事件的标志未被启用的情况下,标志管理单元23在步骤s104中不作为系统(声学事件识别装置11)执行输出,并且识别处理终止。
另一方面,在步骤s105中确定声学事件的标志被启用的情况下,此后处理进行到步骤s106。
在步骤s106中,标志管理单元23作为系统(声学事件识别装置11)输出相应的声学事件,即识别单元22的输出结果,并且识别处理终止。
如上所述,声学事件识别装置11不仅识别标签内的声学事件,还识别标签外添加的声学事件。利用这种布置,可以在事后添加作为识别目标的声学事件。
注意,虽然特征量提取单元21从系统输入的声学信号中提取特征量,但是,例如,特征量可以是mfcc或声谱图。
此外,声学事件模型指示特征量和声学事件之间的对应关系,并且,例如,对用于声学事件e1等的声学事件模型进行预先学习并由标签内识别单元31进行参考。此外,预先学习用于确定与可选声学事件的相似性/差异性的声学事件模型,并由相似性/差异性确定单元32参考该声学事件模型。
此外,识别单元22参考声学事件模型,并根据特征量输出声学事件识别结果。识别单元22包括标签内识别单元31和相似性/差异性确定单元32,标签内识别单元31识别预先附接的标签的范围内的声学事件,相似性/差异性确定单元32确定与所获得的声学事件的相似性/差异性,而不管标签如何。例如,可以将卷积神经网络(cnn)视为标签内识别单元31。此外,例如,可以将暹罗网络视为相似性/差异性确定单元32。
<第一实施例的变型>
<声学事件识别装置的示例性配置>
此外,声学事件识别装置11不限于图2所示的配置,并且可以具有例如图10、11或12所示的配置。注意,在图10至12中,对应于图2的情况的部分由相同的附图标志表示,并且将适当省略其描述。
图10所示的声学事件识别装置11包括特征量提取单元21、识别单元22、标志管理单元23、获取单元24和控制单元25。此外,识别单元22包括标签内识别单元31。
图10所示的声学事件识别装置11的配置与图2所示的声学事件识别装置11的不同之处在于,不包括相似性/差异性确定单元32,除此之外,其配置与图2所示的声学事件识别装置11的配置相同。
由于图10中的声学事件识别装置11不包括相似性/差异性确定单元32,所以其不支持标签范围之外的声学事件的添加和识别。
然而,由于在该示例中提供了标志管理单元23,所以可以在添加模式中添加具有禁用标志的标签内声学事件作为识别目标。在这种情况下,从系统外部看,似乎声学事件是在事后作为识别目标添加的。
此外,图11所示的声学事件识别装置11包括特征量提取单元21、识别单元22、标志管理单元23、获取单元24和控制单元25。此外,识别单元22包括相似性/差异性确定单元32。
图11所示的声学事件识别装置11的配置与图2所示的声学事件识别装置11的不同之处在于,不包括标签内识别单元31,除此之外,其配置与图2所示的声学事件识别装置11的配置相同。
虽然图11的声学事件识别装置11由于不包括标签内识别单元31而不能预先将声学事件固定为识别目标,但是其能够在事后添加可选的声学事件作为识别目标。
此外,图12所示的声学事件识别装置11包括特征量提取单元21、识别单元22、获取单元24和控制单元25。此外,识别单元22包括标签内识别单元31和相似性/差异性确定单元32。
图12所示的声学事件识别装置11的配置与图2所示的声学事件识别装置11的不同之处在于,不包括标志管理单元23,除此之外,其配置与图2所示的声学事件识别装置11的配置相同。
虽然图12的声学事件识别装置11不包括标志管理单元23,因此不能管理作为识别目标的每个声学事件的标志,但是其能够在事后添加可选的声学事件作为识别目标。
<当前技术的应用示例>
此外,在下文中,将描述应用本技术的声学事件识别系统安装在自主机器人中的示例性情况。
例如,如图13所示配置将应用本技术的机器人系统。
图13的机器人系统71例如安装在自主机器人等中,并且包括声音收集单元81、声学事件识别单元82、传感器83、记录单元84、扬声器85、显示器86、通信单元87、输入单元88、驱动单元89和控制单元90。
声音收集单元81包括麦克风,其收集机器人系统71周围的声音,并将作为其结果获得的声学信号提供给声学事件识别单元82。
声学事件识别单元82对从声音收集单元81提供的声学信号执行声学事件识别等,并且适当地将声学事件识别结果和声音信号提供给控制单元90。
请注意,声学事件识别单元82具有与图2所示的声学事件识别装置11相同的配置。即,声学事件识别单元82包括到标志管理单元23的特征量提取单元21,并且声学事件识别单元82的识别单元22包括标签内识别单元31和相似性/差异性确定单元32。
传感器83包括例如照相机、距离测量传感器等,并且捕获机器人系统71周围的图像以将其提供给控制单元90,或者测量到机器人系统71周围的物体的距离以将测量结果提供给控制单元90。
记录各种数据和程序的记录单元84记录从控制单元90提供的数据,并将记录的数据提供给控制单元90。
扬声器85基于从控制单元90提供的声音信号输出声音。显示器86包括例如液晶显示面板等,并且在控制单元90的控制下显示各种图像。
通过有线或无线与诸如服务器(未示出)的装置通信的通信单元87将从控制单元90提供的数据发送到服务器等,并将从服务器等接收的数据提供到控制单元90。
输入单元88包括例如由用户操作的按钮、开关等,并且根据用户做出的操作向控制单元90提供信号。
驱动单元89包括例如致动器等,并且在控制单元90的控制下驱动,从而使得配备有机器人系统71的自主机器人等执行诸如行走的动作。控制单元90控制整个机器人系统71的操作。
接下来,将描述配备有这种机器人系统71的自主机器人的操作的具体示例。
首先,将描述声学事件模型、标志表等的预先准备。
假设预先学习诸如其标签范围是声学事件“拍手”和“铃声”的cnn的声学事件模型,并将其保留在标签内识别单元31中。此外,假设对诸如暹罗网络之类的声学事件模型进行预先学习并保留在相似性/差异性确定单元32中,该声学事件模型也适用于标签范围之外并确定与特定声学事件的相似性/差异性。
对于“拍手”,启用标志(使得在标志表中,识别单元22输出的结果将是识别系统输出的结果)。将整个机器人系统71设置为在识别系统输出“拍手”的情况下使机器人跑动。
对于“铃声”,禁用标志(使得在标志表中,忽略识别单元22输出的结果,并且识别系统不执行输出)。然而,将整个机器人系统71设置为在识别系统输出“铃声”的情况下使机器人跳舞。
在识别系统输出在标签范围之外并且将在事后进行添加的声学事件“未知1”的情况下,假设将整个机器人系统71设置为使机器人唱歌。
接下来,将描述激活包括识别系统的整个机器人系统71之后的操作。
“响应于拍手跑动”
当激活机器人系统71时,操作模式转向识别模式,并且在识别模式期间,不断重复参考图9描述的识别处理。
此外,在机器人系统71中,声音收集单元81不断地收集环境声音,并且声学信号经受到声学事件识别单元82的特征量提取单元21的流输入。此时,特征量提取单元21从声学信号中顺序地提取特征量。
当输入普通声学信号时,识别单元22不执行输出,使得识别系统,即声学事件识别单元82不执行输出。
当机器人的用户在机器人周围拍手时,接收特征量,并且识别单元22,特别是标签内识别单元31,输出“拍手”的声学事件识别结果。在接收到输出时,标志管理单元23参考标志表来确认启用了“拍手”的标志,并且将声学事件识别结果“拍手”直接输出作为识别系统。
然后,已经接收到所提供的声学事件识别结果“拍手”的控制单元90响应于声学事件识别结果驱动驱动单元89,并控制机器人跑动。
此时,即使听到铃声或标签范围之外的声音,识别单元22也不输出声学事件识别结果,使得识别系统不输出声学事件识别结果以使机器人不表现任何反应。
"呈现并使人们记住铃声,一听到铃声就跳舞"
此外,例如,当用户按下作为输入单元88的呈现添加按钮等时,操作模式从识别模式转换到获取模式u(用户呈现)。
在获取模式u中,用户在指定的部分响铃。获取单元24获取从该部分中的声学信号提取的声学事件“铃声”的特征量。请注意,在获取模式u中,通信单元87可以与外部装置通信以获得特征量。
当在获取模式u中获得特征量时,此后操作模式转换到添加模式。
在添加模式中,执行参考图7描述的识别目标添加处理。此时,标签内识别单元31输出“铃声”的声学事件识别结果。当标志管理单元23参考标志表时,由于声学事件“铃声”的标志被禁用,标志管理单元23启用声学事件“铃声”的标志。
当以这种方式执行识别目标添加处理时,此后操作模式转换到识别模式。
在识别模式中,重复执行参考图9描述的识别处理。
此时,当用户在机器人周围响铃时,识别单元22接收特征量,并且识别单元22,特别是标签内识别单元31,输出“铃声”的声学事件识别结果。在接收到输出时,标志管理单元23参考标志表来确认“铃声”的标志被启用,并且将声学事件识别结果“铃声”直接输出到作为识别系统的控制单元90。
然后,控制单元90响应于声学事件识别结果“铃声”驱动驱动单元89,以控制机器人跳舞。
此时,即使发出标签范围之外的声音,识别单元22也不输出声学事件识别结果,使得识别系统不执行输出以使机器人不表现任何反应。
“获得并记住哨声,听到哨声就歌唱”
此外,当操作模式为识别模式时,例如,当用户操作输入单元88以指示转换到获取模式s时,操作模式从识别模式转换到获取模式s(系统获取)。
在获取模式s中,获取单元24顺序地映射由控制单元25指定的参考部分的特征空间中的特征量,例如一天。这时,参考部分除了有规律的噪音外,还吹哨声。参考部分过去之后,使映射的特征量组聚集。这时候就形成了一个有规律的噪声和哨声聚类的聚类。根据标准,从中选择一组具有正确元素数量的哨声。获取单元24获取与聚类相关的特征量。请注意,在获取模式s中,通信单元87可以与外部装置通信以获得特征量。
在参考部分过去之后,操作模式从获取模式转换到添加模式。
在添加模式中,执行参考图7描述的识别目标添加处理。在该示例中,标签内识别单元31不输出声学事件识别结果。因此,将相似性/差异性确定单元32设置为使得相似性/差异性确定单元32确定与哨声声学事件“未知1”的相似性/差异性,并且启用识别“未知1”时的标志。也就是说,从哨声的声学信号提取的特征量和对应于该特征量的标签信息“未知1”彼此相关联,并保留在相似性/差异性确定单元32中。
当识别目标添加处理终止时,操作模式从获取模式s转换到识别模式,并且重复执行参考图9描述的识别处理。
在这种情况下,当机器人周围吹起哨声时,识别单元22接收其特征量。标签内识别单元31不输出声学事件识别结果。同时,相似性/差异性确定单元32输出作为哨声的“未知1”的声学事件识别结果。在接收到输出时,标志管理单元23参考标志表来确认声学事件“未知1”的标志被启用,并且声学事件“未知1”作为识别系统被直接输出。
然后,控制单元90根据从标志管理单元23提供的声学事件“未知1”的声学事件识别结果,从记录单元84读出预定音乐等的声学信号。此外,控制单元90将读取的声学信号提供给扬声器85以再现一段音乐等,从而控制机器人唱歌。
此时,即使除了哨声之外的标签范围之外的声音响起,识别单元22也不输出声学事件识别结果,使得识别系统不输出声学事件识别结果以使机器人不表现任何反应。
此外,上述现有技术可以如下所述。
也就是说,例如,操作模式的每个处理可以以多处理方式并行执行。具体地,例如,可以持续执行参考图9描述的识别处理,并且与识别处理并行,可以适当地执行参考图4描述的获取模式u中的特征量获取处理、参考图5描述的获取模式s中的特征量获取处理、或者参考图7描述的识别目标添加处理。
此外,可以设想从声学事件识别系统的外部反馈是否连续识别添加的识别目标。例如,在通过用户按压自主机器人等的按钮从外部接收到停止命令的情况下,例如,可以设想禁用识别目标的标志。
例如,控制单元90响应于用户做出的操作,基于从输入单元88提供的信号来控制标志管理单元23,并且禁用指定声学事件的标志。
此外,例如,可以设想将在外部添加识别目标时获得的特征量或声学信号发送到外部,以将其用作辅助信息。例如,可以设想,当获得狗的叫声时,将其特征量传输到外部并在输出时进行反映,等等。
此外,例如,标志管理单元23可以经由识别单元22和获取单元24从特征量提取单元21获得狗的叫声的声学信号,以将其提供给控制单元90。在这种情况下,控制单元90将从标志管理单元23提供的声学信号提供给扬声器85,使得狗的叫声再现。通过这种布置,用户可以理解添加了什么样的声学事件作为识别目标。
此外,例如,可以设想使用应用程序等来检查由系统自动获得的特征量和声学信号。此外,还可以设想允许用户操作标签和标志。例如,可以设想,用户在智能手机应用程序上检查上述“未知1”的特征量和声学信号,以将事件标志为“哨声”等。
此外,在将声学事件“哨声”新添加为识别目标的情况下,例如,控制单元90经由标志管理单元23从识别单元22获得声学事件“哨声”的标签信息“未知1”,并将其提供给显示器86以进行显示。
此时,如上所述,控制单元90可以向扬声器85提供声学事件“哨声”的声学信号,以使其再现实际的声学事件“哨声”,从而用户可以直接检查实际的声音。
此外,用户在看到显示器86上显示的标签信息“未知1”或听到实际声学事件“哨声”的声音后操作输入单元88,以发出将标签信息从“未知1”改变为“哨声”的指令。然后,控制单元90根据从输入单元88提供的信号控制标志管理单元23,并且使得标志管理单元23和相似性/差异性确定单元32中的声学事件“哨声”的标签信息被改变为“哨声”。这种标签信息的改变可以通过通信单元87与用户的智能手机和操作智能手机的用户通信来实现。
如上所述,根据本技术,例如通过在自主机器人中安装应用本技术的系统,使得自主机器人记住用户希望机器人记住的声学事件或事后的环境特定声学事件成为可能。
<计算机的示例性配置>
同时,上述一系列处理可以通过硬件或软件来执行。在由软件执行该一系列处理的情况下,将包括在软件中的程序安装在计算机中。这里,计算机的示例包括结合在专用硬件中的计算机、能够通过安装各种程序来执行各种功能的通用个人计算机等。
图14是示出使用程序执行上述一系列处理的计算机的示例性硬件配置的框图。
在计算机中,中央处理单元(cpu)501、只读存储器(rom)502和随机存取存储器(ram)503通过总线504相互耦合。
输入/输出接口505进一步连接到总线504。输入单元506、输出单元507、记录单元508、通信单元509和驱动器510连接到输入/输出接口505。
输入单元506包括键盘、鼠标、麦克风、摄像设备等。输出单元507包括显示器、扬声器等。记录单元508包括硬盘、非易失性存储器等。通信单元509包括网络接口等。驱动器510驱动可移动记录介质511,例如磁盘、光盘、磁光盘和半导体存储器。
在如上所述配置的计算机中,例如,中央处理器501经由输入/输出接口505和总线504将存储在记录单元508中的程序加载到随机存取存储器503中,并执行该程序,从而执行上述一系列处理。
将由计算机(cpu501)执行的程序可以通过例如作为封装介质等记录在可移动记录介质511中来进行提供。此外,可以通过有线或无线传输介质,例如局域网、互联网和数字卫星广播来提供程序。
在计算机中,可以通过将可移动记录介质511附接到驱动器510,经由输入/输出接口505将程序安装在记录单元508中。此外,程序可以由通信单元509经由有线或无线传输介质接收,并安装在记录单元508中。另外,程序可以预先安装在只读存储器502或记录单元508中。
注意,要由计算机执行的程序可以是其中根据本说明书中描述的顺序以时序方式执行处理的程序,或者可以是其中并行执行处理或者在诸如进行呼叫时的必要时刻执行处理的程序。
此外,本技术的实施例不限于上述实施例,并且可以在不脱离本技术的主旨的情况下进行各种修改。
例如,本技术可以采用云计算的配置,其中一个功能由多个设备经由网络共享和联合处理。
此外,上述流程图中描述的每个步骤可以由一个设备执行或者由多个设备共享。
此外,在一个步骤中包括多个处理的情况下,一个步骤中包括的多个处理可以由一个设备执行或者由多个设备共享。
此外,本技术还可以采用以下配置。
(1)一种声学事件识别装置,包括:
获取单元,其获取由用户呈现的声学信号的特征量或环境声音的声学信号的特征量作为新声学事件的候选的特征量;和
识别单元,其保留用于识别预定声学事件的参数,基于所述参数和所获取的特征量执行声学事件识别,并且在所述预定声学事件未被识别的情况下,保留所获取的特征量作为所述新声学事件的特征量。
(2)根据(1)所述的声学事件识别装置,其中
所述识别单元包括:
标签内识别单元,其保留所述参数并执行所述声学事件识别;和
相似性/差异性确定单元,其保留所述新声学事件的特征量,并且基于可选声学信号的特征量和所述保留的特征量,执行关于所述可选声学信号是否是所述新声学事件的声学信号的相似性/差异性确定。
(3)根据(2)所述的声学事件识别装置,其中
所述识别单元输出所述标签内识别单元对所述可选声学信号执行的所述声学事件识别的结果或者所述相似性/差异性确定单元对所述可选声学信号执行的所述相似性/差异性确定的结果,作为所述可选声学信号的声学事件识别结果。
(4)根据(3)所述的声学事件识别装置,其中
在所述标签内识别单元对所述可选声学信号执行的所述声学事件识别中未识别出所述预定声学事件的情况下,所述相似性/差异性确定单元对所述可选声学信号执行所述相似性/差异性确定。
(5)根据(2)至(4)所述的声学事件识别装置,其中
所述相似性/差异性确定单元包括暹罗网络。
(6)根据(3)至(5)所述的声学事件识别装置,进一步包括:
标志管理单元,其管理指示是否输出从所述识别单元输出的所述声学事件识别结果作为最终声学事件识别结果的标志。
(7)根据(1)至(6)所述的声学事件识别装置,其中
所获取单元与另一装置通信,并从所述另一装置获取所述新声学事件候选的特征量。
(8)一种识别声学事件的方法,使得声学事件识别装置执行:
获取由用户呈现的声学信号的特征量或环境声音的声学信号的特征量作为新声学事件的候选的特征量;
基于用于识别预定声学事件的参数和所获取的特征量来执行声学事件识别;和
在所述预定声学事件未被识别的情况下,保留所获取的特征量作为所述新声学事件的特征量。
(9)一种程序,用于使计算机执行包括以下步骤的处理:
获取由用户呈现的声学信号的特征量或环境声音的声学信号的特征量作为新声学事件的候选的特征量;
基于用于识别预定声学事件的参数和所获取的特征量来执行声学事件识别;和
在所述预定声学事件未被识别的情况下,保留所获取的特征量作为所述新声学事件的特征量。
参考符号列表
11声学事件识别装置21特征量提取单元
22识别单元23标志管理单元
24获取单元25控制单元
31标签内识别单元32相似性/差异性确定单元
- 还没有人留言评论。精彩留言会获得点赞!