用于对话可懂度评估的方法和装置与流程
1.本公开涉及评估音轨上对话的可懂度(intelligibility)。
背景技术:
2.在娱乐行业中,内容分发者将诸如电影和电视(tv)节目之类的视听内容流传输到消费者以供消费者消费该内容。关于音频,内容制作者面临的重大问题是消费者不断抱怨他们无法在家中正确听到和理解来自其流传输的内容的对话。解决该问题的常规方法试图通过传统的数字信号处理(dsp)技术来提高对话的语音可懂度,诸如提高人声频率范围。该常规方法一般假设dsp技术解决了“可理解性(understandability)”问题,但没有评估或解决消费者在附加处理之前或之后对对话的实际理解程度。这导致问题(即,消费者对对话可懂度差的抱怨)与其解决方案之间存在质量控制(qc)差距,从而使负责实现解决方案的内容制作者和/或音响工程师不知道他们是否真得充分解决了所报告的问题。
附图说明
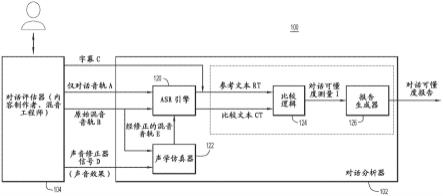
3.图1是示例声音工程环境的框图,该环境用于评估和提高听者对音轨的对话的可懂度。
4.图2是由声音工程环境的对话分析器执行的使用仅对话音轨作为对照其测量可懂度的参考来评估混音音轨的对话的可懂度的示例第一方法的图示。
5.图3是由对话分析器执行的使用对话的基于文本的字幕作为对照其测量可懂度的参考来评估混音音轨的对话的可懂度的示例第二方法的图示。
6.图4a是与通过对话分析器的asr引擎将音轨对话的相继时间切片转换成参考/比较文本的对应相继片段相关联的示例定时的图示。
7.图4b是字幕块与和固定持续时间的对话的时间切片对应的自动语音识别(asr)文本片段的示例文本匹配的图示。
8.图5是由对话分析器生成的对话的可懂度测量(以直方图形式显示)相对于时间的图形式的示例对话可懂度报告的图示,其是参考文本与比较文本之间的比较的结果。
9.图6是参考字幕的原始混音音轨的对话的可懂度的测量的图形式并指示字幕的质量的示例对话可懂度报告的图示。
10.图7是参考字幕的经修正的混音音轨的对话的可懂度的测量的图形式的示例对话可懂度报告的图示。
11.图8是表格形式的示例可懂度报告的图示,该表格具有用于来自图6和7的对话的相继时间切片的行,以及用于与每个时间切片对应的各种数据的列。
12.图9是示例对话可懂度报告的图示,该报告包括从比较结果生成的元数据。
13.图10是由对话分析器生成的文本距离相对于时间的极坐标图形式的示例对话可懂度报告的图示,其是使用editex文本距离算法在参考文本与比较文本之间进行比较的结果。
14.图11是由对话分析器生成的文本距离相对于时间的极坐标图形式的示例对话可懂度报告的图示,其是使用余弦文本距离算法在参考文本与比较文本之间进行比较的结果。
15.图12是评估音轨中对话的可懂度的示例高级方法的流程图。
16.图13是可以在其中实现音频分析器的示例计算机系统/设备的框图。
具体实施方式
17.示例实施例
18.内容分发者向消费者流传输视听内容,包括用于电影、tv节目等的混音音轨。例如,混音音轨可以包括对话和非对话声音,包括用于电影/tv的音乐和声音效果。消费者通过诸如电视或计算机之类的回放设备的声音再现系统来回放混音音轨。消费者常常无法将来自混音音轨的对话理解为通过消费者的回放室(诸如客厅)中的声音再现系统播放的。由于会降级对话的可懂度或“可理解性”的许多因素,消费者可能无法理解对话。如本文所使用的,术语“可懂度”和“可理解性”是同义词并且可互换。可能降级对话可懂度的因素包括:
19.a.对话的低信噪比(snr)。例如,声音混音级别会使得非对话声音相对于对话来说太大声,从而淹没对话。而且,回放室中的背景噪声会淹没对话。
20.b.回放室的声学特性(诸如混响)会干扰或降级对话的可懂度。
21.c.声音再现系统的限制会降级对话的可懂度。
22.d.对话中的单词咬字和发音清晰度(例如,口音)可能会让消费者感到困惑,从而降级对话的可懂度,即使在以高snr回放对话时也是如此。
23.e.消费者的个人听力缺陷和损伤会降级对话的可懂度。
24.为了对与对话的降级的可懂度相关联的问题实现有效的解决方案,能够在实现解决方案之前和之后评估对话对消费者(在随后的描述中称为“听者”)的可懂度是有帮助的。例如,能够预测对话的降低或降级的可懂度的可能性是有帮助的。评估上面提到的因素对对话的可懂度的影响也是有帮助的,以便解决方案可以适当地补偿这些因素。常规解决方案的缺点是它们不尝试估计听者可以理解对话(即,对话对于听者来说是可懂的)的可能性。
25.因而,本文提出的实施例评估自动语音识别(asr)的准确性,例如,以估计来自音轨的对话将被听者理解的可能性。更具体而言,实施例采用asr,例如,以估计或预测在回放室或“收听环境”中音轨的对话对听者的可懂度。例如,实施例使用asr分析和量化用于在典型家庭环境中回放的典型tv和电影内容的对话可懂度的可能性。实施例还仿真消费者收听场景,诸如回放设备的声音再现系统的限制、房间声学、收听水平、人类听力损失等,以进一步预测对话在回放室中保持可懂的可能性。实施例提供对话可懂度报告(也称为质量控制(qc)报告),其包括关于由上面提到的对话分析产生的对话的可懂度的定性和定量信息。此类信息使得有效的解决方案能够校正降级的可懂度。解决方案可以包括记录新的对话音轨或重新混音对话和非对话声音以增加对话对听者的可懂度。
26.声音工程环境
27.参考图1,有一个示例声音工程环境100的高级框图,用于评估和提高音轨的对话对听者的可懂度。声音工程环境100包括被配置为如下所述分析音轨的对话的基于计算机
的对话分析器102,以及评估器104(诸如内容制作者和/或混音工程师)以与对话分析器交互。如已知的,评估器104可以表示人员和音响设备的组合。对话分析器102可以从评估器104接收与用于多媒体/视听内容(例如,包括电影和/或tv节目)的对话相关的各种输入。对话分析器102使用声音处理技术分析输入中传达的对话以产生对话可懂度报告形式的对话分析结果/评估,并将报告提供给评估器104。
28.在示例中,评估器104可以向对话分析器102提供电影和tv节目的音轨形式的内容。音轨可以包括例如(i)仅用于对话的未混音音轨a(也称为“仅对话音轨”或“对话音轨”),以及(ii)原始混音音轨b,包括与非对话声音(诸如音乐和电影/tv声音效果)混音的对话。此外,评估器104可以向对话分析器102提供基于文本的字幕c,其表示仅对话和混音音轨上的对话。对话分析器102还可以从评估器104接收声音修正器信号d,对话分析器102可以使用该信号d仿真各种损害的声音效果,包括回放室声学、背景噪声、回放设备的声音再现系统的限制、听者的听力障碍等中的一种或多种。仿真的声音效果不同于上面提到的原始混音音轨b的非对话声音(例如,电影/tv声音效果)。
29.对话分析器102实现过程以对照可懂度的理想参考/标准测量仅对话音轨a、原始混音音轨b和经修正的混音音轨e(其包括与仿真的声音效果相结合的原始混音音轨)中的每一个上的对话的可懂度。对话分析器102生成包括可懂度的测量的对话可懂度报告,并且可以将报告提供给评估器104。为此,对话分析器102包括彼此耦合并被配置为彼此交互的asr引擎120、声学仿真器122、比较逻辑124和报告生成器126。
30.asr引擎120可以包括一个或多个神经网络,诸如深度神经网络(dnn),以执行基于机器学习(ml)的asr以将由仅对话音轨a、原始混音音轨b和经修正的混音音轨e中的每一个传达的对话转换成对应的asr(对话)文本,并将文本提供给比较逻辑124。asr引擎120可以包括任何已知的或以后开发的用于将对话的音轨转换成文本的asr技术。关于在混音/经修正的混音音轨b/e上执行asr,asr引擎120可以包括(i)信号处理算法,包括基于ml的算法(例如,ml对话提取器),用以从混音/经修正的混音音轨提取对话以产生占主导地位的对话音轨,以及(ii)asr算法,将占主导地位的对话音轨转换成文本。
31.声学仿真器122接收声音修正器信号d并基于声音修正器信号仿真上述声音效果,以产生仿真的声音效果。声学仿真器122将仿真的声音效果组合到原始混音音轨b中,以产生经修正的混音音轨e。可以使用任何已知的或以后开发的声学仿真器。声学仿真器122向asr引擎120提供经修正的混音音轨。
32.如下文进一步详细描述的,比较逻辑124从asr引擎120接收比较文本ct和参考文本rt,参考文本rt可以包括来自asr引擎的文本,或者可替代地,基于文本的字幕c。比较逻辑124基于比较文本与参考文本的比较确定比较文本ct表示的对话相对于参考文本rt的可懂度i。比较逻辑124向报告生成器126提供对话可懂度i的测量和其它比较结果。报告生成器126生成对话可懂度报告,包括对话的可懂度i的测量和其它比较结果,并将报告提供给对话评估器104。
33.本文呈现的实施例仅以示例的方式使用asr作为可懂度的预测器。其它实施例可以不依赖asr。例如,此类其它实施例可以采用替代技术来(i)将音轨的对话翻译成对话的非文本表示,诸如具有接近对话的声音的散列值或签名,以及(ii)将非文本表示与理想参考进行比较,以产生对话的可懂度的测量。例如,可以使用基于ml的技术来执行比较操作,
以产生指示对话的可懂度的测量的比较结果。
34.使用仅对话音轨作为理想参考的混音音轨的对话可懂度
35.参考图2,其图示了使用仅对话音轨a作为对照其测量可懂度的理想参考/标准来评估原始混音音轨b和经修正的混音音轨e的对话的可懂度的示例第一方法200。方法200可以由对话分析器102执行。
36.原始混音音轨的对话可懂度
37.方法200包括操作202、204和206的第一集合,它们共同评估原始混音音轨b的对话的可懂度,而没有仿真的声音效果。
38.在202处,asr引擎120接收仅对话音轨a(在图2中标记为“原始仅对话混音音频”)。例如,仅对话音轨a可以作为波形音频文件(.wav)格式的文件提供,但是其它格式也是可能的。asr引擎120对仅对话音轨a执行asr,以将仅对话音轨转换成参考文本。例如,asr引擎120将仅对话音轨a的相继时间切片转换成参考文本的对应相继片段。相继的时间切片各自占据相继对话分析时隙的对应时隙。时隙(以及因此是时间切片)可以具有例如5-10秒范围内的固定持续时间,但是其它持续时间也是可能的。asr引擎120用相应的开始时间和相应的停止时间给每个时隙/时间切片加时间戳,并且还向相继的时隙/时间切片指派递增的时间切片标识符。asr引擎120将时间切片信息(例如,时间戳和标识符)与参考文本的相继片段中的对应片段相关联。asr引擎120将参考文本和时间切片信息提供给比较逻辑124。asr引擎120还生成相应的置信度级别,asr引擎利用这些置信度级别将仅对话音轨a的时间切片转换成参考文本的对应片段。
39.在204处,asr引擎120接收原始混音音轨b(在图2中标记为“原始全混音音频”)。例如,原始混音音轨b可以作为.wav文件中的文件提供。asr引擎120对原始混音音轨b执行asr,以将原始混音音轨的对话转换成比较文本。例如,asr引擎120将原始混音音轨b的时间切片转换成比较文本的对应片段,类似于asr引擎将仅对话音轨a转换成参考文本的相继片段的方式。表示相同的时间切片/时隙并且因此表示对话的相同部分(即,共同的对话片段)的比较文本的片段和参考文本的片段在本文中被称为用于比较的参考文本和比较文本的对应片段。asr引擎120将比较文本提供给比较逻辑124。
40.在206处,使用参考文本作为表示对话对听者的理想或最大可懂度的参考或标准,比较逻辑124基于比较文本与参考文本之间的比较来确定原始混音音轨b的对话对听者的可懂度的总体测量。即,比较逻辑124将比较文本与参考文本进行比较以产生表示两个文本之间的总体差异的比较结果,并基于总体差异确定对话对听者的可懂度的总体测量。
41.更具体而言,比较逻辑124(i)基于上面提到的时间切片时间戳和标识符建立比较文本的相继片段与表示相同/共同对话的参考文本的相继片段之间的对应关系,(ii)使用下面描述的一种或多种比较算法,确定比较文本的相继片段与表示共同对话的参考文本的相继片段中的对应片段之间的相继个体差异,以及(iii)基于个体差异计算原始混音音轨b的对话的可懂度的总体测量。对于比较文本的相继片段中的对应片段,个体差异可以被认为是对话的可懂度的个体测量。如本文所使用的,术语“对话的可懂度的测量”和“对话可懂度测量(或度量)”是同义的且可互换的,并且术语“测量(measure)”和“度量(metric)”也是同义的且可互换的。
42.以这种方式,本文呈现的实施例使用asr引擎120将语音转换成文本的准确度,如
比较文本与参考文本之间的总体差异所表示的,作为原始混音音轨b的对话对听者(被认为是“普通人类听者”)的可懂度的代理。随着总体差异(以及类似地个体差异)从零(指示确切匹配)逐渐增加到最大值(指示最大不匹配),对话的可懂度的测量对应地从理想逐渐减小/降级到最大降级,反之亦然。确切匹配指示asr引擎120完美地理解并转换原始混音音轨b上的对话,从而听者完全理解了对话。相反,不匹配指示asr引擎120没有正确理解原始混音音轨b的对话,因此听者没有完全理解对话,即,对话的可懂度降级。
43.对话的可懂度的测量可以以许多不同的方式来表示。例如,对话分析器102可以将对话的可懂度的测量(也称为“可懂度分数”)归一化为从1到0,使得(i)1表示由于比较文本与参考文本之间的最大不匹配(即,0%匹配)而引起的最小可懂度,即,比较文本与参考文本完全不同,并且(ii)0表示由于比较文本与参考文本之间完全匹配(即,100%匹配,没有不匹配)而引起的最大可懂度。
44.在示例中,比较逻辑124可以使用一种或多种已知的或以后开发的比较算法将比较文本与参考文本进行比较,以确定上面提到的比较文本与参考文本之间的总体差异。例如,比较算法可以包括基于编辑、基于标记、基于序列、基于压缩、基于语音或声音等的文本距离算法,这些算法确定比较文本与参考文本之间的文本距离。示例文本距离算法包括余弦距离算法,它计算比较文本的字母和/或单词之间的文本距离,以及由zobel和dart开发的editex距离算法,它计算比较文本的声音之间的文本距离,即,文本在被说出时如何发声之间的文本距离。在另一个示例中,比较算法可以包括确定参考文本与比较文本之间的差异的任何已知或以后开发的图像、图案和/或声音匹配算法。
45.在实施例中,比较逻辑124可以使用相同的比较算法来确定比较文本和参考文本的对应片段之间的个体差异,并且可以将个体差异组合成代表对话的可懂度的总体测量的总体差异。例如,比较逻辑124可以计算个体差异的平均值,并将该平均值用作总体差异,从而作为对话的可懂度的总体测量。
46.在另一个实施例中,比较逻辑124可以在将个体差异组合成总体差异之前使用不同比较算法的组合来确定个体差异中的每一个。例如,比较逻辑124可以根据以下函数将每个个体差异计算为使用不同比较算法计算的个体差异的加权和,但是其它函数是可能的:
47.个体差异d=c1d1+c2d2+..+c
ndn
,
48.其中n是≥0的整数,每个ci是系数,并且每个di是不同的比较算法。
49.在示例中,d
l
和d2可以分别表示余弦距离算法和editex距离算法。
50.同样在206处,报告生成器126生成包括在操作202-206中产生的结果的对话可懂度报告。下面结合图5-11描述各种对话可懂度报告。对话可懂度报告可以包括整个原始混音音轨b的对话的可懂度的总体测量、比较文本的片段的对话的可懂度的个体测量、与可懂度的个体测量对应的比较文本的片段、参考文本的对应片段、时间切片的时间戳和标识符、来自比较结果的附加信息,以及元数据,如下所述。对话可懂度报告可以以多种格式提供,包括但不限于超文本标记语言(html)、联合图像专家组(jpeg)、乐器数字接口(midi)等。
51.报告生成器126可以生成上面提到的元数据以用于结合到对话可懂度报告中。一般而言,元数据包括从对话分析的直接结果中抽象出的数据,并且被配置为与数字再现设备一起使用。数字再现设备的示例包括但不限于数字音频工作站(daw)、演播室音频软件和其它视听(av)设备(诸如电视机)。元数据可以被混音工程师用于音轨的播放、混音、编辑和
其它处理,以提高音轨上的对话的可懂度。元数据可以被用于标记音轨上的音频的降级区段并提升该对话相对于对话的其它区段的水平、列出音轨上对话的“好”和“坏”时间切片块,等等。
52.在上面的描述中,比较逻辑124被说成产生比较结果,该比较结果表示指示对话的可懂度的文本之间的差异。因为“差异”可以被解释为文本之间的“相似性”的倒数(即,差异越大,相似性越小,反之亦然),比较逻辑124也可以被说成产生表示文本之间的相似性的比较结果,使得相似性的增加指示可懂度的增加,反之亦然。在任一解释下,比较结果都指示对话的可懂度。而且,上面提到的比较算法可以被说成产生指示可懂度的文本之间的差异,或者相反,相似性。
53.经修正的混音音轨的对话可懂度
54.方法200包括操作202、206和208的第二集合,它们共同评估经修正的混音音轨e对听者的可懂度,即,原始混音音轨b与仿真的声音效果相结合的可懂度。以上对操作202和206的详细描述将足以满足随后的描述。
55.简而言之,在202处,asr引擎120将仅对话音轨a转换成参考文本,如上所述。
56.在208处,声音效果仿真器122接收原始混音音轨b和声音修正器信号d。声音修正器信号d包括要被仿真的声音效果,诸如回放室声学、背景噪声、回放设备的声音再现系统的限制以及听力障碍中的一种或多种。声音效果仿真器122基于声音效果修正信号d对一种或多种声音效果进行建模或仿真,并用声音效果修正原始混音音轨b,以产生经修正的混音音轨e。经修正的混音音轨e表示结合了(仿真的)声音效果的原始混音音轨。例如,经修正的音轨e可以包括仅仿真的回放室声学、仅仿真的背景噪声、仅仿真的声音再现系统的限制、仅仿真的听力障碍,或前述仿真的声音效果中的两种或更多种的组合。
57.在示例中,声音修正器信号d包括与要仿真的一个或多个声音效果对应的一个或多个.wav文件。如已阅读本描述的相关领域的普通技术人员将认识到的,.wav文件可以包括与要仿真的任何声音效果(诸如房间混响、声音高通和/或低通滤波器响应、增益响应等)的频率响应对应的脉冲响应。声音效果仿真器122可以将用于声音效果的(一个或多个).wav文件与原始混音音频的.wav文件进行卷积,以产生经修正的混音音轨e。
58.声音效果仿真器122将经修正的混音音轨e提供给asr引擎120。
59.以上面针对原始混音音轨描述的方式,asr引擎120对经修正的混音音轨e执行asr,以将经修正的混音音轨转换成比较文本。asr引擎120将比较文本,包括比较文本的相继片段,提供给比较逻辑124。
60.简而言之,在206处,比较逻辑124基于比较文本与参考文本的比较来确定经修正的混音音轨e的对话的可懂度的总体测量,并且向报告生成器126提供对话的可懂度的总体测量,以及用于比较文本的对应片段的对话的可懂度的个体测量,如上所述。报告生成器126基于来自操作206的结果生成对话可懂度报告。
61.使用对话可懂度报告作为指导,当对话可懂度报告指示带有或不带有仿真声音效果的对话的可懂度降级时,对话评估器104可以重新录制或重新混音原始混音音频音轨b,以产生重新混音的音轨。如上所述,对话评估器104可以使用对话分析器102来评估重新混音音轨的对话的可懂度,并根据需要重复重新录制或重新混音。
62.使用基于文本的字幕作为理想参考的音轨的对话可懂度
63.参考图3,其图示了由对话分析器102执行使用用于对话的基于文本的字幕c作为对照其测量对话对听者的可懂度的参考来评估混音音轨(例如,混音音轨b和e)的对话的可懂度的示例第二方法300。
64.原始混音音轨的对话可懂度(无声音效果)
65.操作302、304和306共同评估原始混音音轨b参考用于混音音轨的对话的基于文本的字幕c的可懂度。原始混音音轨b不包括仿真的声音效果。
66.在302处,比较逻辑124接收基于文本的字幕c。基于文本的字幕可以被格式化为跨越相继的、相应的时间间隔的字幕文本块的序列,这些时间间隔可以相对于彼此变化,如时间间隔的相应开始和停止时间所指示的。例如,可以以subrip(srt)格式或任何其它已知或以后开发的字幕格式来提供基于文本的字幕。
67.在304处,asr 120接收原始混音音轨b并在原始混音音轨上执行asr,以产生比较文本,如上所述。asr 120将比较文本提供给比较逻辑124。
68.因为字幕文本c的块(称为“字幕块”)的变化的时间间隔可以不同于用于比较文本的片段(称为“比较文本片段”)的固定时间切片持续时间,每个字幕块与每个比较文本片段之间可以不存在一一对应关系。因而,比较逻辑124将每个比较文本片段的文本与跨越对应字幕块的相同/共同文本进行匹配,以建立比较文本片段与传达相同/共同对话的字幕块的文本之间的对应关系。
69.为此,比较逻辑124可以使用文本匹配算法,该算法最大化每个比较文本片段的文本与跨越在时间上接近或邻近于该比较文本片段的对应/匹配字幕块的文本之间的文本相似性。文本匹配算法可以基于比较文本片段和字幕块的时间戳建立时间邻接。
70.为了为每个比较文本片段找到对应/匹配的字幕文本,文本匹配算法可以执行以下示例操作:
71.a.使用任何已知或以后开发的字符串匹配/差异技术确定(当前)比较文本片段与跨越一个或多个字幕块的(当前)字幕文本串之间的相似性的测量。基于比较文本片段和字幕块的时间戳,字幕文本串在时间上与比较文本片段大致重叠。将确定的相似性的测量存储为(当前)最大相似性测量。
72.b.从字幕文本字符串的末端添加/减去单词以延长/缩短字幕文本字符串,并重复操作(a)以确定新的相似度测量。仅当/当新的相似性测量超过来自操作(a)的最大相似性测量时,才将最大相似性测量设置为等于新的相似性测量。
73.c.重复操作(a)和(b),直到满足预定的终止条件,例如,达到预定的最大相似性测量,并声明字幕文本字符串和比较文本匹配以进行比较(这是由文本匹配算法输出的结果)。
74.d.移动到下一个比较文本片段和下一个字幕文本字符串,并重复操作(a)-(c)。
75.在306处,比较逻辑124基于比较文本与基于文本的字幕c中的匹配字幕之间的比较,确定原始混音音轨b的对话对听者的可懂度的总体测量。更具体而言,比较逻辑124确定比较文本的片段与表示相同/共同对话的字幕块的对应块的字幕文本之间的个体差异,如由文本匹配算法确定的。比较逻辑124将个体差异组合成对话的可懂度的总体测量。
76.比较逻辑124向报告生成器126提供原始混音音轨b的对话的可懂度的总体测量,以及对话的可懂度的个体测量(和字幕质量的指示),例如,如个体差异所表示的,报告生成
器126生成如本文描述的对话可懂度报告。
77.经修正的混音音轨的对话可懂度(带声音效果)
78.操作306、308和310共同评估经修正的混音音轨e参考基于文本的字幕c的的可懂度。
79.在308处,比较逻辑124接收字幕c以用作参考文本,如上所述。
80.操作310类似于上述操作208。在310处,声学仿真器122接收原始混音音轨b和声音修正器信号d。声音效果仿真器122基于声音修正器信号d仿真一个或多个声音效果,并用声音效果修正原始混音音轨b,以产生经修正的混音音轨e。声音效果仿真器122将经修正的混音音轨e提供给asr引擎120。asr引擎120以上述方式将经修正的混音音轨e转换成比较文本。asr引擎120将比较文本,包括相继的比较文本片段,提供给比较逻辑124。
81.在306处,比较逻辑124以上述方式基于比较文本与基于文本的字幕c之间的比较来确定经修正的混音音轨e的对话的可懂度的总体测量。比较逻辑124向报告生成器126提供经修正的混音音轨e的对话的可懂度的总体测量,以及对话的可懂度的个体测量,报告生成器126生成如本文所述的对话可懂度报告。
82.使用上面提到的对话可懂度报告作为指导,当对话可懂度报告指示带有或不带有仿真声音效果的对话的可懂度降级时,对话评估器104可以重新录制或重新混音原始混音音频音轨,以产生重新混音的音轨。对话分析器102可以被用于评估重新混音音轨的对话的可懂度,并且可以根据需要重复重新混音/评估过程。
83.用于asr片段和字幕的时序图
84.参考图4a,其图示了与由asr引擎120将音轨对话dialog1-dialog4的相继时间切片转换成参考/比较文本的对应相继片段相关联的示例定时400。参考/比较文本片段也称为“asr文本片段”或简称为“asr文本”。定时400示出了与音轨对话dialog1-dialog4的时间切片对应的参考文本的相继片段(“参考文本片段”)r1-r4,以及比较文本的对应相继片段(“比较文本片段”)c1-c4。相继的个体差异d1-d4表示参考文本片段r1-r4与比较文本片段c1-c4中的对应文本片段之间的个体差异,即,个体差异di是文本片段ri与ci之间的差异。一种或多种比较算法(在图4a中以
“‑”
指示)生成个体差异d1-d4,其可以包括文本距离、模式匹配结果等。每个个体差异di可以代表示用于对应的比较文本片段ci的对话的可懂度的对应个体测量。
85.参考图4b,其图示了示例450,该示例450示出跨越对应变化时间间隔的srt字幕块1-7与和对话的相继时间切片slice1、slice2和slice3对应的相继asr文本片段的文本匹配,时间切片slice1、slice2和slice3中的每一个有10秒的固定持续时间。每个字幕块由前导字幕序列号(例如,1、2、...、7)和时间间隔(例如,“00:00:03,400
→
00:00:06,177”)定义,其中逗号将秒与毫秒分开。在图4b的示例中,上述文本匹配算法将(i)由跨越字幕块1-3的方框452涵盖的字幕文本串匹配到asr文本slice1的对话,(ii)由跨越字幕块3-5的方框454涵盖的字幕文本串匹配到asr文本slice2的对话,以及(iii)由跨越字幕块5-7的方框456所涵盖的字幕文本串匹配到asr文本slice3的对话。
86.对话可懂度报告
87.现在结合图5-12描述为显示而生成,然后由对话分析器102显示的对话可懂度报告。例如,对话可懂度报告可以显示在用户界面的面板中。
88.参考图5,其图示了以对话的可懂度的测量(垂直轴)相对于时间(水平轴)的图的形式的示例对话可懂度报告500,这是由参考文本与比较文本之间的比较产生的。可懂度的测量归一化为从0到1,其中0表示完全匹配(即,100%匹配),而1表示完全不匹配或完全不同的文本(即,0%匹配或完全不匹配)。时间轴以近似10秒的时间增量示出从0分钟到4分22秒的时间(即,使用近似3秒的时间切片持续时间)。
89.图上的垂直条表示用于文本片段/时间切片的可懂度的个体测量。给定可懂度映射匹配=0和不匹配=1,可懂度的个体测量可以解释为可懂度的降级的测量,因为测量的增加表示可懂度的降级的增加。而且,为了提高可读性,可以用不同的颜色、阴影或交叉影线图案来描绘落在不同范围内的可懂度的个体测量。例如,超过预定阈值(并因此表示更高水平的降级)的可懂度的个体测量可以用第一种颜色(例如,红色)描绘,而不超过预定阈值(因此表示较低水平的降级)可以用第二种颜色(例如,绿色)描绘。多个预定阈值和对应的颜色/阴影/交叉影线可以被用于描绘绿色和红色之间的一个或多个范围。
90.图3的示例包括三个不同的交叉影线图案,其可以用对应的颜色(或粗体、虚线等)代替,以指示对话的三个对应的可懂度级别,包括:(i)双交叉影线(即,“x”交叉影线)以指示最不易于理解的对话,即,在最大降级范围内的可懂度;(ii)具有负斜率(即,高度从左到右下降)的单个交叉影线以指示最易懂的对话,即,在最小降级范围内的可懂度;以及(iii)具有正斜率(即,高度从左到右上升)的单个交叉影线以指示最易懂和最难懂的对话之间的对话可懂度范围。
91.此外,对话可懂度报告500包括对话的可懂度的总体测量,称为“总体分数”,其基于可懂度的个体测量计算。在图5的示例中,总体分数为52.02%。
92.下面结合图6-9描述用于不同音轨上相同对话参考对话的基于文本的字幕的各种对话可懂度报告。例如,对话可懂度报告由方法300执行的分析产生。
93.参考图6,其图示了示例对话可懂度报告600,其形式为原始混音音轨(例如,原始混音音轨b)的对话参考对照字幕(例如,字幕c)的可懂度的测量的图。换句话说,该图显示了字幕形式的参考文本与源自原始混音音轨的比较文本之间的比较结果。因此,该图表示字幕质量。图中的垂直条表示由比较文本片段和相应字幕块之间的比较产生的可懂度(或可懂度降级)的各个测量,如上所述。该图还表明原始混音音轨的总分为94.17%。
94.参考图7,其图示了示例对话可懂度报告700,其形式为经修正的混音音轨(例如,经修正的混音音轨e)的对话参考对照字幕的可懂度的测量的图,即,图6的原始混音音轨结合仿真的声音效果。该图在1:52之后的时间示出了出色的对话可懂度降级伪影,这是由仿真的声音效果造成的。该图指示经修正的混音音轨的总体分数为90.88%,由于声音效果,该分数相对于图6的图的分数有所下降。
95.参考图8,其图示了表格形式的示例可懂度报告800,该表格具有(i)来自图6和7的对话的相继时间切片的枚举行,和(ii)与每个时间切片(即,行)对应的各种数据的列。在表格中从左到右移动,这些列包括:
96.a.时间切片标识符(id)列804,用于对话的每个时间切片的行/时间切片标识符。
97.b.参考文本栏806,用于每个时间切片的字幕文本(例如,srt文本)形式的参考文本。
98.c.时间戳列808和810,用于每个时间切片的开始和结束时间。
99.d.比较文本列812,其引用由原始混音音轨的每个时间切片的asr产生的比较文本片段。
100.e.分数列814,用于每个比较文本片段参考列806中的对应字幕文本的可懂度的个体测量(即,个体分数)。因此,个体测量指示字幕质量。个体分数被表示为字幕文本与比较文本之间的百分比匹配(0-100%)。在个体分数表示如上所述由多种比较算法产生的总分的示例中,分数列814可以被细分为多个分数列,包括用于由每种比较算法计算的分数的相应列,以及一列用于累积分数。例如,在比较逻辑124将editex距离和余弦距离组合成累积文本距离的示例中,可懂度分数列可以细分为用于editex距离的第一列、用于余弦距离的第二列和用于组合editex距离和余弦距离的累积文本距离的第三列。
101.f.比较文本列816,其引用由经修正的混音音轨的每个时间切片的asr产生的比较文本片段,即,原始混音音轨与仿真声音效果相结合。
102.g.分数列818,用于经修正的混音音轨的每个比较文本片段参考对应字幕文本的可懂度的个体测量(即,个体分数)。
103.h.置信度级别列820,用于正确计算每个分数的置信度级别。asr引擎120可以计算置信度级别。
104.例如,表中与低于指示差可懂度(例如,75%)的预定阈值的可懂度分数相关联的时间切片/行可以用红色描绘,而其它行可以用绿色或黑色描绘。在图8的示例中,具有低可懂度分数的时间切片/行13和15可以用红色描绘。更一般而言,这种颜色编码突出显示特定于用户的降级或坏片段。
105.参考图9,其图示了示例对话可懂度报告900,其包括由对话分析器102生成的元数据。例如,报告900将来自图8的对话可懂度报告800的信息/结果结合到标准midi文件(smf)中。报告900描绘了midi文件的内容。midi文件可以在任何被配置为处理midi文件的daw中进行处理。midi文件的顶部区段901描绘垂直布置的轨道902、904和906,每个轨道被划分为由枚举为m1-mn的垂直标记指示的相继时间切片,在轨道上从左到右移动。轨道902是对话音轨的音频波形。轨道904和906是midi轨道,其将用于时间切片的可懂度分数表示为水平节距条,其中0-127的节距表示0-1的可懂度分数。轨道904仅示出超过预定阈值的“good(好)”可懂度分数(由缩写标签“go”指示)。轨道906仅示出不超过预定阈值的降级/差“deg”可懂度分数(由缩写标签“de”指示)。midi文件的底部区段910描绘与标记m1-mn对应的文本行、与文本对应的可懂度分数以及通用的可懂度指示符“good”和“bad(坏)”。
106.参考图10,其图示了以文本距离(即,半径)相对于时间(角旋转/位移)的极坐标图形式的示例对话可懂度报告1000,该图是为了供对话分析器102显示而作为跨越一定时间长度的参考文本与比较文本之间的比较的结果而生成的。在图上,文本距离(即,半径)可以归一化为从0到1,其中0表示完全匹配,而1表示完全不匹配。在图10的示例中,对话分析器102使用editex算法基于语音确定距离。如结合图10所描述的,不同的距离范围可以用不同的颜色或用其它类型的不同格式来描绘,诸如粗体或虚线。
107.参考图11,其图示了以文本距离(即,半径)相对于时间(角旋转)的极坐标图的形式的示例可懂度降级报告1100,该图是为了供对话分析器102显示而作为与图10中所示跨越相同时间长度的相同参考文本与相同比较文本之间的比较的结果而生成的。在图11的示例中,对话分析器102根据余弦距离算法基于单词和字符差异确定文本距离。
108.高级流程图
109.参考图12,其图示了总结上述操作的确定对话可懂度的示例方法1200的流程图。方法1200可以由对话分析器102执行。
110.在1202处,对话分析器102获得混音音轨,该混音音轨包括与非对话声音混音的对话。例如,对话分析器接收包括与非对话声音混音的对话的原始混音音轨,并将该音轨用作混音音轨。可替代地,对话分析器用仿真室内声学、声音再现系统回放声学和背景噪声中的一种或多种的仿真的声音效果对原始混音音轨进行声学修正,以产生混音音轨。
111.在1204处,对话分析器102使用asr将混音音轨的时间切片转换成比较文本的相继片段。
112.在1206处,对话分析器10获得对话的参考文本,作为对话对听者的可懂度的理想参考/标准。例如,对话分析器102使用asr将仅对话音轨的时间切片转换成参考文本的相继片段。可替代地,对话分析器接收对话的基于文本的字幕作为参考文本。
113.在1208处,对话分析器102基于比较文本与参考文本的比较来确定混音音轨的对话对听者的可懂度的测量(即,总体对话可懂度度量)。例如,对话分析器(i)基于比较(即,基于比较文本与参考文本的相应片段之间的比较)计算针对混音音轨的时间切片的对话的可懂度的个体测量(即,个体对话可懂度度量),和(ii)基于对话的可懂度的个体测量来计算对话的可懂度的测量。
114.在示例中,对话分析器102可以使用一种或多种比较算法将可懂度的测量(和可懂度的个体测量)计算为对应的参考文本与比较文本之间的差异。例如,对话分析器102可以执行以下操作:
115.a.使用第一比较算法(例如,第一文本距离算法)计算对应参考文本与比较文本之间的第一差异(例如,第一文本距离)。
116.b.使用第二比较算法(例如,第二文本距离算法)计算对应参考文本与比较文本之间的第二差异(例如,第二文本距离)。
117.c.计算对应的参考文本与比较文本之间的差异(例如,组合文本距离)作为第一差异(例如,第一文本距离)和第二差异(例如,第二文本距离)的加权组合。
118.在1210处,对话分析器102报告,例如,为了显示而生成,然后可以显示对话的可懂度的测量、对话的可懂度的测量、针对时间切片的对话的可懂度的个体测量,以及其它比较结果(例如,元数据)。可替代地和/或附加地,对话分析器102可以将报告存储到文件中以供用户随后访问。
119.计算机系统
120.图13是在其上可以实现本文呈现的实施例的示例计算机设备1300的框图。例如,计算机设备1300可以表示对话分析器102,并且可以在个人计算机(pc)、智能电话、平板pc等中实现。计算机设备1300包括处理与本文描述的过程相关的指令的处理器或控制器1310、存储各种数据和软件指令的存储器1320。处理器1310例如是微处理器或微控制器,其执行存储器1320中的计算机设备控制逻辑1355的指令,以实现本文针对对话分析器102描述的过程。计算机设备还包括网络接口单元(例如,卡)1330,以通过诸如互联网和/或局域网(lan)之类的通信网络与其它设备通信。网络接口单元1330可以包括具有端口(或多个这样的设备)以通过有线以太网链路进行通信的以太网卡和/或具有无线收发器以通过无线
链路进行通信的无线通信卡。计算机设备1300还包括其它接口单元,包括物理连接到其它设备的硬件插头和/或插座、光学接口、音频接口等。
121.计算机设备还可以包括用于接收来自用户的输入的用户接口单元1340、麦克风1350和扬声器1360。用户接口单元1340可以是键盘、鼠标和/或触摸屏用户界面的形式,以允许用户与计算机设备交互。麦克风1350和扬声器1360使音频能够被记录和输出。计算机设备还可以包括显示器1370,包括例如可以向用户显示数据的触摸屏显示器。
122.存储器1320可以包括只读存储器(rom)、随机存取存储器(ram)、磁盘存储介质设备、光学存储介质设备、闪存设备、电的、光的或其它物理/有形的(例如,非暂态)存储器存储设备。因此,一般而言,存储器1320可以包括一个或多个有形的(非暂态的)计算机可读存储介质/介质(例如,存储器设备),其编码有包括计算机可执行指令的软件(例如,控制逻辑/软件1355)并且当软件被(处理器1310)执行时,它可操作以执行本文针对对话分析器102描述的操作。逻辑1355可以包括用于asr引擎、声学仿真器、比较逻辑和报告生成器的逻辑,如上所述。逻辑1355包括生成和显示用户界面以在显示器1370上呈现信息并允许用户通过例如用户界面的用户可选择选项向计算机设备1300提供输入的指令。存储器1320还存储由计算机设备控制逻辑1355生成和使用的数据,诸如用于音轨的数据、比较结果、元数据等。
123.总之,以一种形式,提供了一种方法,包括:获得包括与非对话声音混音的对话的混音音轨;将混音音轨转换成比较文本;获得对话的参考文本,作为对话可懂度的参考;基于比较文本与参考文本的比较,确定混音音轨的对话对听者的可懂度的测量;以及报告对话的可懂度的测量。
124.以另一种形式,提供了一种装置,包括:处理器,被配置为:获得包括与非对话声音混音的对话的混音音轨;将混音音轨转换成比较文本;获得对话的参考文本,作为对话对听者的可懂度的参考;基于比较文本与参考文本的比较,计算混音音轨的对话的可懂度的个体测量;基于对话的可懂度的个体测量,计算混音音轨的对话的可懂度的总体测量;以及生成包括对话的可懂度的总体测量的报告。
125.以又一种形式,提供了一种非暂态计算机可读介质。计算机可读介质编码有指令,指令在由处理器执行时使处理器:获得包括与非对话声音混音的对话的混音音轨;使用自动语音识别(asr)将混音音轨的时间切片转换成比较文本;获得对话的参考文本,作为对话的可懂度的参考;基于比较文本与参考文本之间的差异,计算时间切片的混音音轨的对话的可懂度的个体测量;基于对话的可懂度的个体测量,计算混音音轨的对话的可懂度的总体测量;以及生成包括对话的可懂度的总体测量和对话的可懂度的个体测量的报告。
126.虽然技术在本文中被图示和描述为实施在一个或多个具体示例中,但是它并不旨在限于所示的细节,因为可以在权利要求的等同物的范围内进行各种修改和结构改变。
127.下面呈现的每个权利要求表示单独的实施例,并且组合不同权利要求和/或不同实施例的实施例在本公开的范围内并且在阅读本公开之后对于本领域普通技术人员将是显而易见的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1