一种语音识别方法及装置与流程
本发明涉及信号处理技术领域,尤其涉及一种语音识别方法及装置。
背景技术:
目前,语音识别技术越来越广泛的应用在人们的生活中,比如用户发出一句语音即可将该语音转化为对应的文字,这样避免了用户去手动打字输入的繁琐操作,现有的语音识别技术是利用语音模块结合在线引擎对语音信号进行识别并且转换为文字,但是这种方法存在着以下缺点:在线引擎的优化识别率较低使得语音模板填充的语音发生错误从而导致识别的结果出现大的偏差,严重影响了用户的体验感。
技术实现要素:
针对上述所显示出来的问题,本方法基于利用在线引擎和离线引擎同时对语音模板中的语音信号进行识别,从两种识别结果中确定最终的识别结果来对语音进行识别输出。
一种语音识别方法,包括以下步骤:
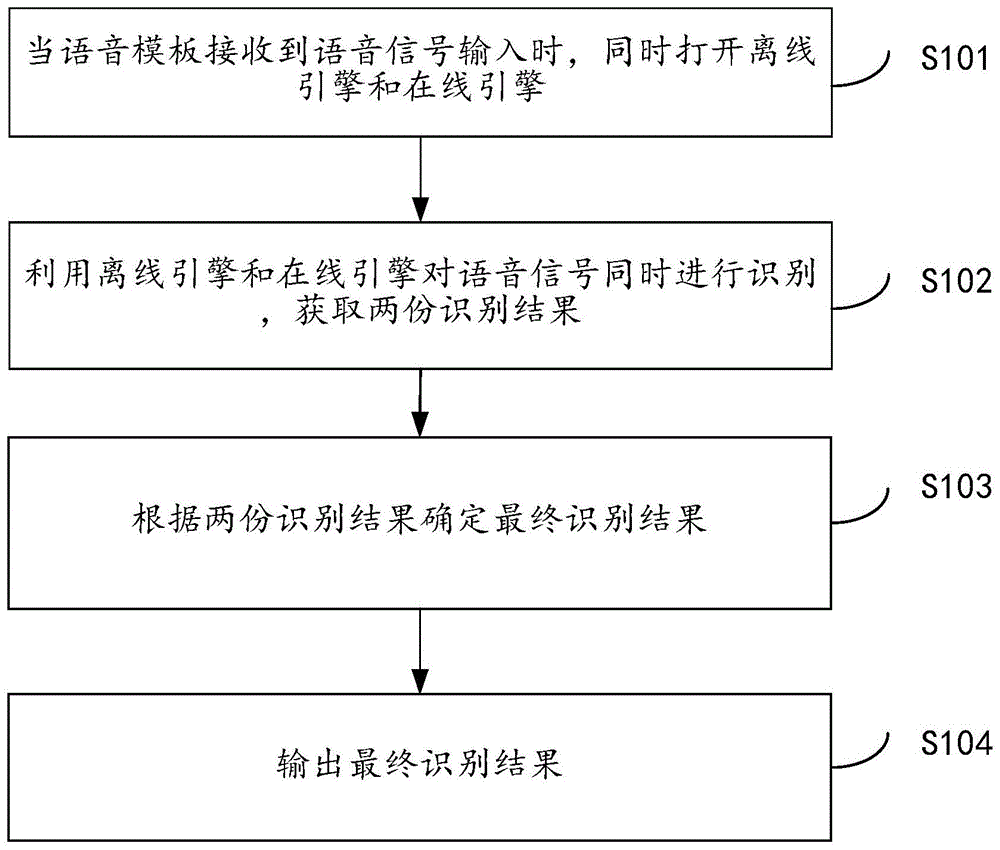
当语音模板接收到语音信号输入时,同时打开离线引擎和在线引擎;
利用所述离线引擎和所述在线引擎对所述语音信号同时进行识别,获取两份识别结果;
根据所述两份识别结果确定最终识别结果;
输出所述最终识别结果。
优选的,所述利用所述离线引擎和所述在线引擎对所述语音信号同时进行识别,获取两份识别结果,包括:
将所述语音信号复制为两份,获得两份相同的所述语音信号;
将所述两份相同的语音信号分别输入到所述离线引擎和所述在线引擎中;
获取所述在线引擎的第一识别结果和所述离线引擎识别的第二识别结果。
优选的,所述根据所述两份识别结果确定最终识别结果,包括:
判断所述第一识别结果的输出结果类型是否为第一预设类型;
若是,将所述第一识别结果确定为所述最终识别结果;
否则,判断所述第一识别结果的输出结果类型是否为第二预设类型;
若所述第一识别结果的输出结果类型为所述第二预设类型,判断所述第二识别结果的置信度是否大于等于预设阈值;
若所述置信度大于等于所述预设阈值,获取所述第二识别结果中的第二元素值,以及获取所述第一识别结果的第一元素填充位置信息;
根据所述第一元素填充位置信息确定所述第一识别结果中的第一元素值;
将所述第一识别结果中的所述第一元素值替换为所述第二元素值;
将所述替换后的第一识别结果确定为所述最终识别结果;
若所述置信度小于所述预设阈值,确定所述第二识别结果为错误识别结果,将所述第一识别结果确定为所述最终识别结果。
优选的,所述输出所述最终识别结果,包括:
获取预设设备的请求指令;
根据所述请求指令将所述最终识别结果输入到所述预设设备上;
将所述最终识别结果显示在所述预设设备上。
优选的,所述方法还包括:当所述语音模板接收到所述语音信号输入时,对所述语音信号进行降噪和提帧预处理。
一种语音识别装置,该装置包括:
开启模块,用于当语音模板接收到语音信号输入时,同时打开离线引擎和在线引擎;
识别模块,用于利用所述离线引擎和所述在线引擎对所述语音信号同时进行识别,获取两份识别结果;
确定模块,用于根据所述两份识别结果确定最终识别结果;
输出模块,用于输出所述最终识别结果。
优选的,所述识别模块,包括:
复制子模块,用于将所述语音信号复制为两份,获得两份相同的所述语音信号;
输入子模块,用于将所述两份相同的语音信号分别输入到所述离线引擎和所述在线引擎中;
第一获取子模块,用于获取所述在线引擎的第一识别结果和所述离线引擎识别的第二识别结果。
优选的,所述确定模块,包括:
第一判断子模块,用于判断所述第一识别结果的输出结果类型是否为第一预设类型;
第一确定子模块,用于若所述第一判断子模块确定为所述第一预设类型时,将所述第一识别结果确定为所述最终识别结果;
第二判断子模块,用于当所述第一判断子模块确定不是所述第一预设类型时,判断所述第一识别结果的输出结果类型是否为第二预设类型;
第三判断子模块,用于若所述第二判断子模块确定所述第一识别结果的输出结果类型为所述第二预设类型时,判断所述第二识别结果的置信度是否大于等于预设阈值;
第二获取子模块,用于若所述第三判断子模块确定所述置信度大于等于所述预设阈值时,获取所述第二识别结果中的第二元素值,以及获取所述第一识别结果的第一元素填充位置信息;
第二确定子模块,用于根据所述第一元素填充位置信息确定所述第一识别结果中的第一元素值;
替换子模块,用于将所述第一识别结果中的所述第一元素值替换为所述第二元素值;
输出子模块,用于输出替换后的第一识别结果;
第三确定子模块,用于将所述替换后的第一识别结果确定为所述最终识别结果;
第四确定子模块,用于若所述第三判断子模块确定所述置信度小于所述第三预设阈值,确定所述第二识别结果为错误识别结果,将所述第一识别结果确定为所述最终识别结果。
优选的,所述输出模块,包括:
第三获取子模块,用于获取预设设备的请求指令;
输入子模块,用于根据所述请求指令将所述最终识别结果输入到所述预设设备上;
显示子模块,用于将所述最终识别结果显示在所述预设设备上。
优选的,所述装置还包括:
预处理模块,用于当所述语音模板接收到所述语音信号输入时,对所述语音信号进行降噪和提帧预处理。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制,在附图中:
图1为本发明所提供的一种语音识别方法的工作流程图;
图2为本发明所提供的一种语音识别方法的另一工作流程图;
图3为本发明所提供的一种语音识别方法的工作流程截图;
图4为本发明所提供的一种语音识别装置的结构图;
图5为本发明所提供的一种语音识别装置的另一结构图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
目前,语音识别技术越来越广泛的应用在人们的生活中,比如用户发出一句语音即可将该语音转化为对应的文字,这样避免了用户去手动打字输入的繁琐操作,现有的语音识别技术是利用语音模块结合在线引擎对语音信号进行识别并且转换为文字,但是这种方法存在着以下缺点:在线引擎的优化识别率较低使得语音模板填充的语音发生错误从而导致识别的结果出现大的偏差,严重影响了用户的体验感。为了解决上述问题,本实施例公开了一种基于利用在线引擎和离线引擎同时对语音模板中的语音信号进行识别,从两种识别结果中确定最终的识别结果来对语音进行识别输出的方法。
一种语音识别方法,如图1所示,包括以下步骤:
步骤s101、当语音模板接收到语音信号输入时,同时打开离线引擎和在线引擎;
步骤s102、利用离线引擎和在线引擎对语音信号同时进行识别,获取两份识别结果;
步骤s103、根据两份识别结果确定最终识别结果;
步骤s104、输出最终识别结果;
在本实施例中,上述离线引擎指的是在没有网络接入的引擎,在线引擎指的是有网络接入的引擎。
上述技术方案的工作原理为:当语音模板接收到语音信号输入时,同时打开离线引擎和在线引擎同时对语音信号进行识别,得到两份识别结果,根据两份识别结果确定最终识别结果,将最终识别结果输出给用户观看。
上述技术方案的有益效果为:通过同时利用在线引擎和离线引擎对语音信号进行识别,使得识别的结果更加准确,由于离线引擎具有比在线引擎更高的识别率,故而识别的结果也可以根据两个引擎各自的识别结果进行调整,保证了识别的准确性。解决了现有技术中由于在线引擎的优化识别率较低使得语音模板填充的语音发生错误从而导致识别的结果出现大的偏差,提高了用户的体验感。
在一个实施例中,如图2所示,利用离线引擎和在线引擎对语音信号同时进行识别,获取两份识别结果,包括:
步骤s201、将语音信号复制为两份,获得两份相同的语音信号;
步骤s202、将两份相同的语音信号分别输入到离线引擎和在线引擎中;
步骤s203、获取在线引擎的第一识别结果和离线引擎识别的第二识别结果。
上述技术方案的有益效果为:通过获取第一识别结果和第二识别结果可以将二者进行对比,由第二识别结果去检查第一识别结果是否准确,降低了识别错误的风险。
在一个实施例中,根据两份识别结果确定最终识别结果,包括:
判断第一识别结果的输出结果类型是否为第一预设类型;
若是,将第一识别结果确定为最终识别结果;
否则,判断第一识别结果的输出结果类型是否为第二预设类型;
若第一识别结果的输出结果类型为第二预设类型,判断第二识别结果的置信度是否大于等于预设阈值;
若置信度大于等于预设阈值,获取第二识别结果中的第二元素值,以及获取第一识别结果的第一元素填充位置信息;
根据第一元素填充位置信息确定第一识别结果中的第一元素值;
将第一识别结果中的第一元素值替换为第二元素值;
输出替换后的第一识别结果;
将替换后的第一识别结果确定为最终识别结果;
若置信度小于预设阈值,确定第二识别结果为错误识别结果,将第一识别结果确定为最终识别结果;
在本实施例中,上述第一预设模型和第二预设模型都是体现在识别的文字里,它们表示为一个预设数字,第一预设模型可以为0,第二预设模型可以为1,上述预设阈值可以为1。
上述技术方案的有益效果为:将离线引擎的第二识别结果中的第二元素值替换为第一识别结果中的第一元素值,保证了元素值的准确性,获取第一元素填充位置信息可以快速的将第二元素值替换为第一元素值,有效的减少了识别的时间,提高了识别效率。
在一个实施例中,输出最终识别结果,包括:
获取预设设备的请求指令;
根据请求指令将最终识别结果输入到预设设备上;
将最终识别结果显示在预设设备上;
在本实施例中,上述预设设备可以为手机、平板、电脑等智能设备。
上述技术方案的有益效果为:可以更直观的向用户显示识别结果,使用户有良好的视觉感受。
在一个实施例中,上述方法还包括:当语音模板接收到语音信号输入时,对语音信号进行降噪和提帧预处理。
上述技术方案的有益效果为:将语音信号中的噪音剔除并且进行提帧处理使得语音信号中的人声更加清晰,使得在线引擎和离线引擎的识别率更高,避免了误识别几率的同时提高了识别效率。
在一个实时例中,如图3所示,包括:
第一步:打开模板之后,离线引擎和在线引擎共同识别开启,将语音复制两份,分别送入离线引擎和在线引擎;
第二步:在线引擎经过后处理获取到识别结果,如图中红色1序号所示,resulttype为1表示是命令(resulttype为0表示是文本),得到的识别结果中包含了元素所在的位置索引(index)信息,但是识别结果中元素的值识别错误既elementvalue应该为10,但是识别结果为4,所以填充结果是错误的(红色1序号中红色字部分经常出错,同样错误的还存在识别结果出现毫无根据的大数问题);
第三步:和第二步同步进行,离线引擎获取识别结果,如图中红色2序号所示;
第四步:1)当红色1标号中resulttype为0时,表示的识别结果为文本,将在线识别结果最为最终结果;
2)当红色1标号中resulttype为1时,表示的识别结果为命令,查看离线识别结果中的阈值(红色2序号中confidence),如果阈值大于指定值,则认为离线引擎识别了正确结果,那么将离线识别结果(红色2序号)中的value,替换到在线识别结果(红色1序号)elementvalue中作为最终结果;
如果阈值小于指定值,则认为离线引擎识别了错误结果,那么将在线引擎的识别结果作为最终结果;
第五步:拿到的最终提供给客户端使用,并更新界面显示。
上述技术方案的有益效果为:首先利用了在线引擎的后处理模块提供元素填充位置和在线引擎的文本识别功能,针对在线引擎的句式识别率低的问题,由识别率高的离线引擎替代。提高在固定位置准确填充识别结果。
本实施例还公开了一种语音识别装置,如图4所示,该装置包括:
开启模块401,用于当语音模板接收到语音信号输入时,同时打开离线引擎和在线引擎;
识别模块402,用于利用离线引擎和在线引擎对语音信号同时进行识别,获取两份识别结果;
确定模块403,用于根据两份识别结果确定最终识别结果;
输出模块404,用于输出最终识别结果。
在一个实施例中,识别模块,包括:
复制子模块4021,用于将语音信号复制为两份,获得两份相同的语音信号;
输入子模块4022,用于将两份相同的语音信号分别输入到所述离线引擎和在线引擎中;
第一获取子模块4023,用于获取在线引擎的第一识别结果和离线引擎识别的第二识别结果。
在一个实施例中,确定模块,包括:
第一判断子模块,用于判断第一识别结果的输出结果类型是否为第一预设类型;
第一确定子模块,用于若第一判断子模块确定为第一预设类型时,将第一识别结果确定为最终识别结果;
第二判断子模块,用于当第一判断子模块确定不是第一预设类型时,判断第一识别结果的输出结果类型是否为第二预设类型;
第三判断子模块,用于若第二判断子模块确定第一识别结果的输出结果类型为第二预设类型时,判断第二识别结果的置信度是否大于等于预设阈值;
第二获取子模块,用于若第三判断子模块确定置信度大于等于预设阈值时,获取第二识别结果中的第二元素值,以及获取第一识别结果的第一元素填充位置信息;
第二确定子模块,用于根据第一元素填充位置信息确定第一识别结果中的第一元素值;
替换子模块,用于将第一识别结果中的第一元素值替换为第二元素值;输出子模块,用于输出替换后的第一识别结果;
第三确定子模块,用于将替换后的第一识别结果确定为最终识别结果;
第四确定子模块,用于若第三判断子模块确定置信度小于第三预设阈值,确定第二识别结果为错误识别结果,将第一识别结果确定为最终识别结果。
在一个实施例中,输出模块,包括:
第三获取子模块,用于获取预设设备的请求指令;
输入子模块,用于根据请求指令将最终识别结果输入到预设设备上;
显示子模块,用于将最终识别结果显示在预设设备上。
在一个实施例中,上述装置还包括:
预处理模块,用于当语音模板接收到语音信号输入时,对语音信号进行降噪和提帧预处理。
本领域技术人员应当理解的是,本发明中的第一、第二指的是不同应用阶段而已。
本领域技术用户员在考虑说明书及实践这里公开的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!