一种基于云端改善的本地语音识别方法与流程
本发明属于语音识别技术领域,具体涉及一种基于云端改善的本地语音识别方法。
背景技术:
语音识别(automaticspeechrecognition,asr)分为本地语音识别和云端语音识别。本地语音识别是通过预先设定好命令词的语音识别模块进行语音识别,其优点是不需要网络,响应速度快,缺点是命令词固定,无法实现自由顺畅的交流。云端语音识别是将采集到的语音内容通过网路传到云端服务器进行语义推断,再通过网络回传到设备上做出相应控制,其优点是借助大数据库可实现海量命令词识别,满足用户自由交流,但缺点是需要网络,且响应速度较慢。
技术实现要素:
为克服现有技术存在的技术缺陷,本发明公开了一种基于云端改善的本地语音识别方法。
本发明所述基于云端改善的本地语音识别方法,包括如下步骤:
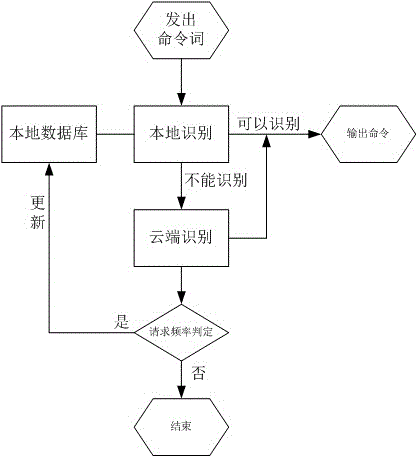
s1本地设备接收到命令词后,在本地数据库进行识别,如果本地数据库未存储,则发送命令词到云端识别;
s2云端接收到该命令词后,在云端进行识别并将识别结果返回本地设备,同时进行请求频率判定,判断该命令词是否符合更新标准,是则将该命令词在本地数据库中进行添加。
优选的,所述s2步骤中添加的具体步骤为:
s21请求频率判定成立时,将该命令词添加生成新的语言模型;
s22.生成新的语言模型后,在云端生成新的固件版本;
s23.生成新固件版本后,云端向本地设备发起更新请求,并向本地发送新生成固件版本的版本号;
s34.本地设备将版本号与本地存储的固件版本号比较,发现不一致后查询检索新生成固件的分区表版本;
s35.检索到分区表版本后,解析并下载分区表中信息,更新到本地数据库。
进一步的,所述分区表中信息包括应用程序,语言模型和命令词对应表。
优选的,所述请求频率判定具体为:从判定时间起上溯一定时间段,在该时间段内,该命令词的被请求次数超过阈值。
采用本发明所述基于云端改善的本地语音识别方法,通过云端收集用户的语音数据并统计出高频词,通过ota随时更新本地语言模型,使本地命令词库更适应客户实际需求,提高了设备响应速度,用户体验感更好。
附图说明
图1为本发明所述基于云端改善的本地语音识别方法的一种具体实施方式流程示意图
图2为本发明中添加更新命令词的一个具体实施方式过程示意图。
具体实施方式
下面结合附图,对本发明的具体实施方式作进一步的详细说明。
本发明所述基于云端改善的本地语音识别方法,包括如下步骤:
s1.本地设备接收到命令词后,在本地数据库进行识别,如果本地数据库未存储,则发送命令词到云端识别;
s2.云端接收到该命令词后,在云端进行识别并将识别结果返回本地设备,同时进行请求频率判定,判断该命令词是否符合更新标准,是则将该命令词在本地数据库中进行添加。
本发明基于可以进行本地语音识别的本地设备,设备指采用语音控制方式的各种电器,进行本地语音识别的芯片可以采用申请人所开发的ci1006,ci110x等,这些芯片通过存储在自身的语音识别软件及数据库对语音进行识别,并根据识别出的命令直接控制本地设备进行相应操作;电器通常为各种家用或办公电器如电视机,空调等,设备也可以是一个专门的语音识别终端。
例如用户发出"打开暖风机"这一命令词,安装有本地语音识别芯片的本地设备接收识别到命令词后,首先在本地数据库中寻找是否有与其匹配的命令词,如果发现有匹配命令词则直接执行命令,如果没有,则可以将识别出的命令词语音信息通过无线传输网络发送到云端,由云端服务器在云端数据库进行识别,并将识别出的识别结果通过无线传输网络返回到本地设备。
云端在进行识别的同时,进行请求频率判定,即对该命令词在过往一端时间的请求频率进行判定,根据其出现的频繁程度决定是否将该命令词添加到本地设备的数据库中。
具体判定方式可以是从判定时间起上溯一定时间段,在该时间段内,该命令词的被请求次数超过阈值。例如设定时间段为7天,阈值为5次,在进行判定时,云端对上溯7天时间内该命令词被请求识别的次数进行统计,超过5次则判定成立,符合更新标准,并对本地数据库中的命令词进行更新。
所述s2步骤中添加的具体步骤为:
s21请求频率判定成立时,将该命令词添加生成新的语言模型;
语言模型用于判断一个语言序列是否由人发出,原始的语言模型中可能没有该命令词例如“我要听歌”,当用户说出“我要听歌”命令词时,系统将该命令词“我要听歌”加入进来,重新建模,生成新的语言模型。
s22.生成新的语言模型后,在云端生成新的固件版本;
s23.生成新固件版本后,云端向本地设备发起更新请求,并向本地发送新生成固件版本的版本号;
s34.本地设备将版本号与本地存储的固件版本号比较,发现不一致后查询检索新生成固件的分区表版本;
s35.检索到分区表版本后,解析并下载分区表中信息,更新到本地数据库。
所述分区表中信息包括应用程序,语音模型和命令词对应表。
其中,语音识别的过程需要通过运行应用程序来实现。更新命令词的途径就是更新应用程序和语言模型,命令词对应表为存储命令词的文档。
固件也可以采用ota升级方式,如果需要更新其中一个固件块,首先从存储固件块中读取相关信息;通过从服务器读取出配置区域信息和从本机中读取出配置区域信息,然后对比其中的数据,就可以发现哪些相同哪些不同,就升级对应的固件块。如有多个不一样,则升级所有不同的固件块。
随后终端设备开始擦除以起始地址为起点且大小相符的存储区域,随后将通过http方式下载得到的数据写入擦除后的falsh中,写入完成后,终端设备计算该区域的校验和并且从服务器中取出对应区域的校验和,判断一致后从服务器中取出对应区域的配置信息并写入到配置信息存储固件中对应的区域。升级完成后向服务器发送升级结束信号。
服务器对于各个固件按照紧迫性等级的升级排序方式可以具体为包括以下步骤:
s21服务器接收到的更新固件中包含该固件的紧迫性等级信息及该固件对应的全部可升级设备uid信息;
uid信息(useridentify,中文用户id),是与设备唯一对应的信息,例如某一固件对应十个设备,每个设备包含各自独立的uid信息。
服务器将紧迫性等级最高的固件按照其uid信息更新到服务器数据库中,并生成url(uniformresourcelocator,统一资源定位符,实际即网页地址)链接;
设备上传自身uid信息,服务器根据uid信息,从数据库中调取url链接并下发到设备;设备根据url链接开始进行数据下载和升级;
上传uid信息时,服务器可以先判断设备当前工作状态是否适合升级,允许则调取url链接;
s24设备升级完成后上报服务器,该紧迫性等级下的全部可升级设备uid信息对应的所有设备升级完成后,服务器中已升级完成的固件被清除,重复步骤s22-s23;对等级较低的固件开始继续升级,直至所有固件升级完毕。
数据写入flash后,需要进行验错,可以通过crc32程序求出该块的校验和(checksum值),使该值和服务器中对应该块存储的checksum值对比,如果相同判断为数据写入成功,如果失败重新升级该块数据。crc全称循环冗余校验,是一种检错程序,crc32是最新的程序版本。
每当设备完成写入固件块后,例如,已经从服务器取得大小为size的固件并且写入flash,校验成功;需要从服务器中读取配置区域块中,表示固件块3的信息包含ver、size、flashstart、checksum,更新到本机固件块,即配置信息存储区中对应的位置,从而防止后续重复升级。
采用本发明所述基于云端改善的本地语音识别方法,通过云端收集用户的语音数据并统计出高频词,通过随时更新本地语言模型,使本地命令词库更适应客户实际需求,提高了设备响应速度,用户体验感更好。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!