基于深度学习的声音质量处理系统及其方法与流程
本发明涉及声音处理方法技术领域,尤其涉及一种基于深度学习的声音质量处理系统及其方法。
技术背景
随着人们对声音品质的追求越来越高,以及日益进步的音频采样技术,目前有损音频的质量已经远远不能满足需求。如何在有限的存储和传输空间条件限制下实现最好的声音还原效果成为声音质量处理技术的核心。目前有损压缩方法中,如mp3、高级音频编码(aac)等通过人工数字信号处理算法方法,虽能初步降低了码率,能将基本的声音信号还原,从而得到广泛的应用。
然而目前基于人工填充或插值数据的方法进行重构的方案,效果均不太理想,根本原因是这种方式基于人的过于粗糙的主观感知实现,不能对声音有本质理解。
技术实现要素:
本发明的发明目的在于提供一种基于深度学习的声音质量处理系统及其方法,采用本发明提供的技术方案解决了目前基于人工填充或插值数据的方法进行声音重构的方案,存在无法理解声音特征本质的技术问题。
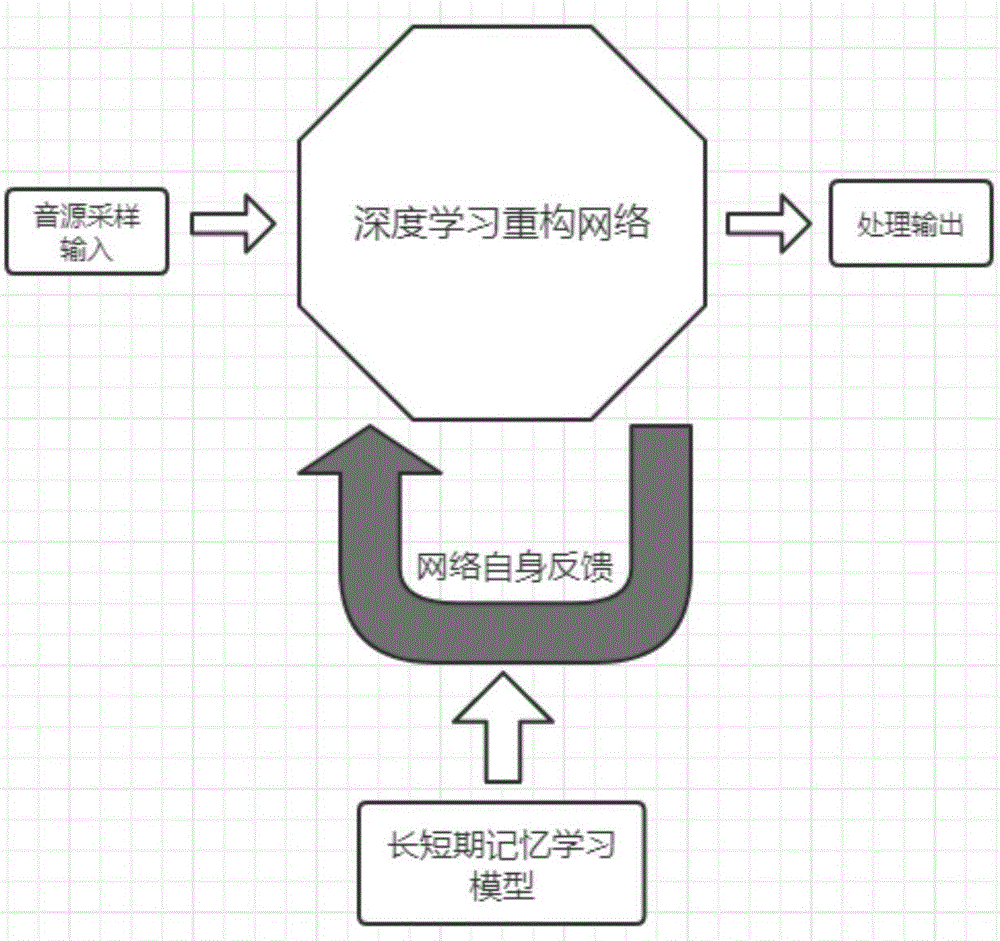
为了解决上述技术问题,本发明一方面提供一种基于深度学习的声音质量处理系统,包括音源采样输入模块、深度学习重构网络和音源处理输出模块;
所述音源采样输入模块,用于对无损音频样本和有损音频样本进行采样,获得原始裸数据;
所述深度学习重构网络,提取所述原始裸数据的特征后进行分类,分别对每一类特征进行频谱重构,再进行时域还原,得到时域波形数据;
所述音源处理输出模块,输出将所述深度学习重构网络得到的时域波形数据。
优选的,在所述音源采样输入模块中,所述有损音频样本由所述无损音频样本通过短时傅立叶变换得到。
优选的,所述深度学习重构网络包括输入层和输出层,所述原始裸数据为所述输入层的输入,所述原始裸数据的特征为所述输出层的目标。
优选的,所述深度学习重构网络由至少三个lstm网络、若干个dropout层、至少两个dence层和一softmax分类器依次连接组成,在相邻的两个lstm网络以及相邻的两个dence层之间均连接有一dropout层。
基于上述声音质量处理系统,本发明另一方面还提供一种声音质量处理方法,包括以下步骤:
s100、对无损音频样本和有损音频样本进行采样,获得原始裸数据;
s200、提取所述原始裸数据的特征后进行分类;
s300、分别对每一类特征进行频谱重构;
s400、对频谱重构的特征进行时域还原,得到时域波形数据并输出。
优选的,在步骤s200中,在对特征进行分类之前,对特征进行记忆处理,包括:
lstm网络提取原始裸数据的特征后;
提取的特征在dropout层每个隐藏层各单元之间的重置门和更新门之间传递;
传递过程控制之前声音特征和当前声音特征的记忆和遗忘程度。
优选的,所述重置门和更新门为遗忘门、输入门、候选门和输出门的变种可控门。
优选的,在步骤s200中,完成记忆处理的特征在dence层跟进声音特征的组合进行分类。
优选的,在步骤s300中,由softmax分类器分别对每一类特征进行频谱重构计算。
优选的,在lstm网络中,部分自身输出灌入音频输入帧中。
由上可知,应用本发明提供的可以得到以下有益效果:本发明基于深度学习,利用神经网络重构算法对较差的音频源通过动态的方法处理各个音源场景,能从声音各方面的特征本质进行处理,重构出接近无损还原的效果,让输出的音质接近无损水平的效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对本发明实施例或现有技术的描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一部分实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例基于深度学习的声音质量处理系统框图;
图2为本发明实施例基于深度学习的声音质量处理系统lstm网络门结构示意图;
图3为本发明实施例基于深度学习的声音质量处理系统神经网络架构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
目前有损压缩方法中,基于人工填充或插值数据的方法进行重构的方案,效果均不太理想,根本原因是这种方式基于人的过于粗糙的主观感知实现,不能对声音有本质理解。
请参见图1-3,为了解决上述技术问题,本实施例提供一种基于深度学习的声音质量处理系统,包括音源采样输入模块、深度学习重构网络和音源处理输出模块。
其中,音源采样输入模块,用于对无损音频样本和有损音频样本进行采样,获得原始裸数据;
深度学习重构网络,提取原始裸数据的特征后进行分类,分别对每一类特征进行频谱重构,再进行时域还原,得到时域波形数据;
音源处理输出模块,输出将深度学习重构网络得到的时域波形数据。
在本发明中,深度学习重构网络采用lstm网络实现深度学习,具体的,lstm即longshortmemorynetwork,长短时记忆网络,属于rnn的一种变种,lstm网络是为了克服rnn无法很好处理远距离依赖而提出,相比普通的rnn,lstm能够在更长的序列中有更好的表现。
rnn不能处理距离较远的序列是因为训练时很有可能会出现梯度消失,让rnn失去了对较远时刻的感知能力。lstm的重复网络模块,实现了三个门计算,即遗忘门、输入门和输出门。每个门负责是事情不一样,其中遗忘门负责决定保留多少上一时刻的单元状态到当前时刻的单元状态;输入门负责决定保留多少当前时刻的输入到当前时刻的单元状态;输出门负责决定当前时刻的单元状态有多少输出。
为此在lstm网络中,每个lstm包含了三个输入,即上时刻的单元状态、上时刻lstm的输出和当前时刻输入。
基于上述lstm网络,本发明实施例提供的基于深度学习的声音质量处理系统,其深度学习重构网络包括输入层和输出层,原始裸数据为输入层的输入,原始裸数据的特征为输出层的目标。
在连接结构中,深度学习重构网络由至少三个lstm网络、若干个dropout层、至少两个dence层和一softmax分类器依次连接组成,在相邻的两个lstm网络以及相邻的两个dence层之间均连接有一dropout层。
基于上述声音质量处理系统,本发明另一方面还提供一种声音质量处理方法,包括以下步骤:
s100、对无损音频样本和有损音频样本进行采样,获得原始裸数据。
在该步骤中,通过音源采样输入模块对音源样本进行采样,其中有损音频样本由无损音频样本通过短时傅立叶变换得到。
s200、提取原始裸数据的特征后进行分类。
在对特征进行分类之前,对特征进行记忆处理,包括:
lstm网络提取原始裸数据的特征后;提取的特征在dropout层每个隐藏层各单元之间的重置门和更新门之间传递;传递过程控制之前声音特征和当前声音特征的记忆和遗忘程度。
具体通过深度学习重构网络实现,此模块是具有一种重复神经网络模块的链式形式,对输入源直接处理。
对音源采样输入的有损音频样本和无损音频样本分别进行特征提取,分别得到所述有损音频样本的特征和所述无损音频样本的特征。将采样的原始裸数据作为所述音频重构神经网络的输入层的输入,并将得到的所述原始裸数据的特征作为所述原始裸数据重构神经网络的输出层的目标,递归调节训练参数,以训练所述音频重构神经网络模型。
深度神经网络是使用lstm网络(longshorttermmemory),由普通的rnn循环神经网络在各自的隐藏层各神经单元中增加记忆单元,从而从声音信号的时间序列上的记忆的特征信息可控,特征在每个隐藏层各单元中传递时通过几个可控门(遗忘门、输入门、候选门、输出门)的变种重置门、更新门,可以控制之前声音特征和当前声音特征的记忆和遗忘程度。在这个结构中,把神经元状态和隐藏状态进行了合并,输出的模型比标准的lstm结构要简单,从而使此rnn网络具备了对声音特征有长期记忆功能。
本发明实施例采用的lstm变体网络如图2所示,其中,r代表重置门,z代表更新门。r门代表的特征将决定是否将之前的状态遗忘,作用等同于遗忘门和传入门。当rt→0的时候,t的前一个状态h会被遗忘掉,隐藏状态h(~)t的参数会被清空并设置为当前输入的信号。tanh输出的每个结果都是一个在0和1之间的实数,表示让对应信号通过的权重(或者占比)。
神经网络架构如图3所示,网络将输入层经数据过反复的两次512个神经元进行运算,每次得到的结果采取30%丢弃的方式避免网络产生过拟合的现象。使用全连接dence层根据声音特征的组合进行分类,尽量减少特征重复位置对分特征类带来的影响。
s300、分别对每一类特征进行频谱重构。
频谱重构通过一个softmax多类特征分类器完成,softmax多类特征分类器分别对每一类特征进行频谱重构计算。
s400、对频谱重构的特征进行时域还原,得到时域波形数据并输出。
步骤s300中得到的结果再进行时域还原,即可得到重构后的音频流。
在上述处理系统及其方法中,存在处理误差的技术问题,为此在本发明实施例中,还增加了网络自身反馈,将lstm变体网络部分有用的自身输出灌入音频输入帧中,使其形成自身反馈,克服了误差消失的问题。
综上,本发明实施例基于深度学习,利用神经网络重构算法对较差的音频源通过动态的方法处理各个音源场景,能从声音各方面的特征本质进行处理,重构出接近无损还原的效果,让输出的音质接近无损水平的效果。
以上所述的实施方式,并不构成对该技术方案保护范围的限定。任何在上述实施方式的精神和原则之内所作的修改、等同替换和改进等,均应包含在该技术方案的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!