一种训练数据生成方法、装置以及计算机可读存储介质与流程
本发明涉及人工智能领域,尤其涉及一种训练数据生成方法、装置以及计算机可读存储介质。
背景技术:
训练语音识别系统需要大量的语音和文本标注好的训练数据,现有获取训练数据的方案都是获取语音,由标注人员通过语音标注系统标注语音对应的文本;或者指定大量文本,由不同的说话人根据指定的文本来录制语音。通过大量的人工录制和标注,可以获取训练语音识别系统的训练数据。通过现有获取训练数据的方案需要消耗大量人力和时间成本,获取大量高质量的语音训练数据难度很高,导致训练语音识别系统的训练集匮乏。
技术实现要素:
本发明实施例提供了一种训练数据生成方法、装置以及计算机可读存储介质,具有高效率地获取大量并且高质量的语音训练数据并降低了耗费成本的技术效果。
本发明一方面提供一种训练数据生成方法,所述方法包括:接收音频信息和对应的标注文本信息;生成对应于所述音频信息的语音识别文本信息和第一时间戳信息;内容匹配所述标注文本信息和语音识别文本信息,根据所述第一时间戳信息生成对应于所述标注文本信息的第二时间戳信息;根据所述第二时间戳信息,获取所述标注文本信息中的子文本训练信息和所述音频信息中的子音频训练信息。
在一可实施方式中,所述内容匹配所述标注文本信息和语音识别文本信息,包括:利用编辑距离算法对所述标注文本信息和语音识别文本信息进行文本相似度匹配;以所述标注文本信息作为基准,对相匹配的语音文本信息中的字/词进行文本对齐处理。
在一可实施方式中,所述根据所述第一时间戳信息生成对应于所述标注文本信息的第二时间戳信息,包括:从所述第一时间戳信息中获取所述语音识别文本信息中每个字/词信息所对应的起始时间戳信息和结尾时间戳信息;针对所述标注文本信息中每个字/词信息,复制对应于所述语音识别文本信息中相匹配字/词信息的起始时间戳信息和结尾时间戳信息,生成对应于所述标注文本信息的第二时间戳信息。
在一可实施方式中,在内容匹配所述标注文本信息和语音识别文本信息之前,所述方法包括:通过语音识别系统获取所述语音识别文本信息中字/词信息所对应的置信度;根据每个所述字/词信息的置信度,检测并替换所述标注文本信息中所对应的字/词信息。
在一可实施方式中,所述根据所述第二时间戳信息,获取所述标注文本信息中的子文本训练信息和所述音频信息中的子音频训练信息,包括:对所述标注文本信息根据设定字符或者指定字符数量拆分为多个子文本训练信息,并从所述第二时间戳信息中分别获取多个所述子文本训练信息所对应的起始时间戳和结尾时间戳信息;根据多个所述子文本训练信息所对应的起始时间戳和结尾时间戳信息,将所述音频信息拆分为多个子音频训练信息。
在一可实施方式中,在生成对应于所述音频信息的语音识别文本信息和第一时间戳信息之前,所述方法还包括:将所述标注文本信息输入于语音识别系统中的语言模型进行训练,或者在语音识别系统进行解码时动态增加所述标注文本信息的概率值。
本发明另一方面提供一种训练数据生成装置,所述装置包括:信息接收模块,用于接收音频信息和对应的标注文本信息;第一信息生成模块,用于生成对应于所述音频信息的语音识别文本信息和第一时间戳信息;第二信息生成模块,用于内容匹配所述标注文本信息和语音识别文本信息,根据所述第一时间戳信息生成对应于所述标注文本信息的第二时间戳信息;训练数据生成模块,用于根据所述第二时间戳信息,获取所述标注文本信息中的子文本训练信息和所述音频信息中的子音频训练信息。
在一可实施方式中,所述第二信息生成模块具体用于:利用编辑距离算法对所述标注文本信息和语音识别文本信息进行文本相似度匹配;以所述标注文本信息作为基准,对相匹配的语音文本信息中的字/词进行文本对齐处理。
在一可实施方式中,所述训练数据生成模块具体用于:对所述标注文本信息根据设定字符或者指定字符数量拆分为多个子文本训练信息,并从所述第二时间戳信息中分别获取多个所述子文本训练信息所对应的起始时间戳和结尾时间戳信息;根据多个所述子文本训练信息所对应的起始时间戳和结尾时间戳信息,将所述音频信息拆分为多个子音频训练信息。
本发明另一方面提供一种计算机可读存储介质,所述存储介质包括一组计算机可执行指令,当所述指令被执行时用于执行上述任一项所述的训练数据生成方法。
在本发明实施例中,通过获取原始的音频信息以及标注文本信息,利用音频信息的时间戳信息从原始的音频信息以及标注文本信息中获取多个子音频训练信息和对应的子文本训练信息,从而得到大量并且高质量的语音训练数据,此过程效率高并且降低了耗费成本。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
在附图中,相同或对应的标号表示相同或对应的部分。
图1为本发明实施例一种训练数据生成方法的实现流程示意图;
图2为本发明实施例一种训练数据生成装置的结构组成示意图。
具体实施方式
为使本发明的目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而非全部实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
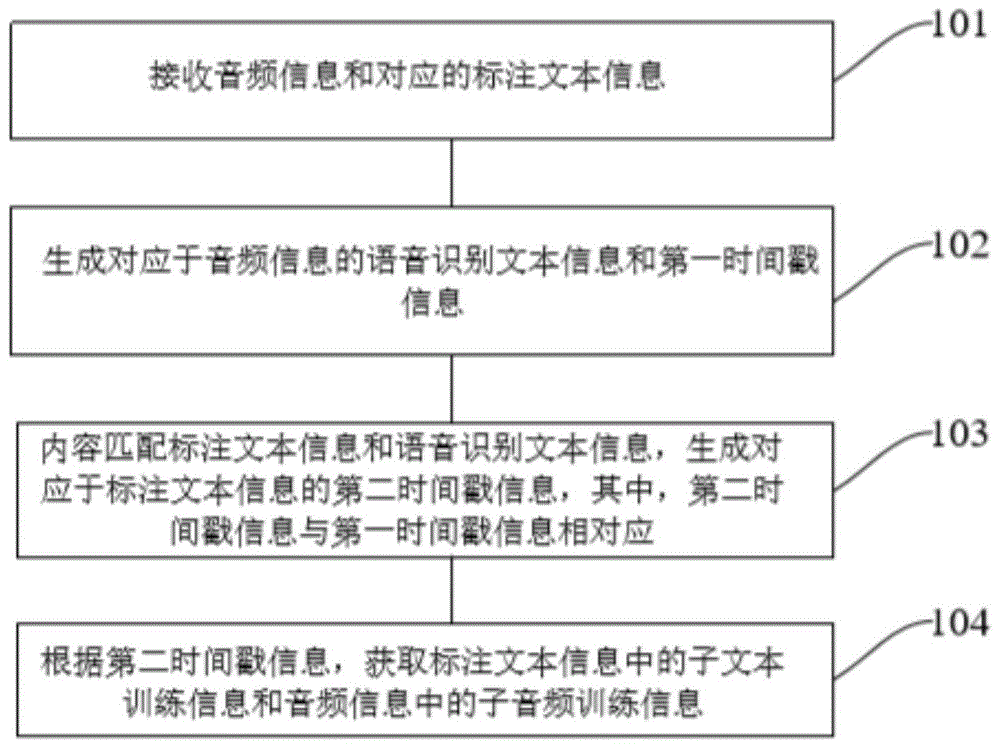
图1为本发明实施例一种训练数据生成方法的实现流程示意图。
如图1所示,本发明一方面提供一种训练数据生成方法,方法包括:
步骤101,接收音频信息和对应的标注文本信息;
步骤102,生成对应于音频信息的语音识别文本信息和第一时间戳信息;
步骤103,内容匹配标注文本信息和语音识别文本信息,生成对应于标注文本信息的第二时间戳信息,其中,第二时间戳信息与第一时间戳信息相对应;
步骤104,根据第二时间戳信息,获取标注文本信息中的子文本训练信息和音频信息中的子音频训练信息。
本实施例中,在步骤101中,音频信息和对应的标注文本信息优选为长音频和长标注文本信息,可以是有声书、演讲音频、访谈记录等等,其获取方式可以通过爬虫技术从网络上抓取或者从本地数据库中获取。
在步骤102中,语音识别文本信息和第一时间戳信息可以通过将所接收到的音频信息输入于现有的语音识别系统或者通过人工测量识别得到;第一时间戳信息包括对应于语音识别文本信息中每个字或词的起始和结尾时间戳信息,例如标注文本信息为:“天很热,地球南极的冰川都陷落了”,假设语音识别文本信息为“天很热地球南极冰川都显露”的时间戳信息可能为:
天很热:[天,19.83,20.49],[很,20.49,20.79],[热,20.79,21.00];
地球南极:[地球,21.90,22.05],[南极,22.05,22.62];
冰川显露:[冰川,23.67,24.00],[显露,24.00,24.24]。
在步骤103中,将标注文本信息和语音识别文本信息进行内容匹配,使生成对应于标注文本信息的第二时间戳信息。
接着在步骤104中,根据第二时间戳信息,获取标注文本信息中的子文本训练信息和音频信息中的子音频训练信息。
由此,通过获取原始的音频信息以及标注文本信息,利用音频信息的时间戳信息从原始的音频信息以及标注文本信息中获取多个子音频训练信息和对应的子文本训练信息,从而得到大量并且高质量的语音训练数据,此过程效率高并且降低了耗费成本。
在一可实施方式中,内容匹配标注文本信息和语音识别文本信息,包括:
利用编辑距离算法对标注文本信息和语音识别文本信息进行文本相似度匹配;
以标注文本信息作为基准,对相匹配的语音文本信息中的字/词进行文本对齐处理。
本实施例中,编辑距离算法是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们相似度越低。
在相似度匹配时,具体可以将标注文本信息和语音识别文本信息分别根据标点符号或者分词工具拆分为多个长语句信息或者词级别语句信息,将标注文本信息和语音识别文本信息中的长语句信息或者词级别语句信息进行两两相似度匹配,选取相似度最高的两个语句信息认定为相匹配。
接着进行文本对齐处理,在处理过程中,可以首先利用现有的分词工具对相匹配的语音文本信息进行分词处理,得到多个字/词信息,接着以标注文本信息为基准,将语音文本信息中的字/词分别与标注文本信息中的字/词相对应,未对齐的部分可以通过增设特定符号进行填充,以此完成内容匹配。针对上述所举的例子,对齐后表示为:
标注文本:天很热,地球南极的冰川都陷落了;
识别文本:天很热__地球南极__冰川都显露__(下划线符号表示空白)。
在一可实施方式中,根据第一时间戳信息生成对应于标注文本信息的第二时间戳信息,包括:
从第一时间戳信息中获取语音识别文本信息中每个字/词信息所对应的起始时间戳信息和结尾时间戳信息;
针对标注文本信息中每个字/词信息,复制对应于语音识别文本信息中相匹配字/词信息的起始时间戳信息和结尾时间戳信息,生成对应于标注文本信息的第二时间戳信息。
本实施例中,第二时间戳信息的生成过程具体为:
在内容匹配完成之后,获取语音识别文本信息中每个字/词信息所对应的起始时间戳信息和结尾时间戳信息,将所获取的起始时间戳信息和结尾时间戳信息按照字符索引复制给标注文本信息中对应索引位置的字/词,从生成了对应于标注文本信息的第二时间戳信息。
在一可实施方式中,在内容匹配标注文本信息和语音识别文本信息之前,方法包括:
通过语音识别系统获取语音识别文本信息中字/词信息所对应的置信度;
根据每个字/词信息的置信度,检测并替换标注文本信息中所对应的字/词信息。
本实施例中,在步骤101所获取的标注文本信息可能存在错误,如“天很热地球南极冰川都显露”的“显露”为识别错误。因此在执行103步骤之前,在利用语音识别系统生成语音识别文本信息的同时获取到语音识别系统中每个字/词的置信度;
若每个字/词的置信度超过预设阈值,则认定该字/词的准确率较高,此时检测并判断标注文本信息中对应的字/词是否内容一致,若判定标注文本信息中对应的字/词内容不一致,则将替换标注文本信息中所对应的字/词信息,如将“天很热地球南极冰川都显露”替换为“天很热地球南极冰川都陷落”。通过此步骤,可以减少上述进行编辑距离算法时的计算量,进而提高运行效率。
在一可实施方式中,根据第二时间戳信息,获取标注文本信息中的子文本训练信息和音频信息中的子音频训练信息,包括:
对标注文本信息根据设定字符或者指定字符数量拆分为多个子文本训练信息,并从第二时间戳信息中分别获取多个子文本训练信息所对应的起始时间戳和结尾时间戳信息;
根据多个子文本训练信息所对应的起始时间戳和结尾时间戳信息,将音频信息拆分为多个子音频训练信息。
本实施例中,步骤104的具体过程为:
在生成第二时间戳信息之后,检测标注文本信息中的标点符号索引位置或者根据指定字符数量定位到所需切割的索引位置,按照索引位置将标注文本信息拆分为多个子文本训练信息,如将“天很热,地球南极的冰川都陷落了”分为“天很热”和“地球南极的冰川都陷落了”。
接着从第二时间戳信息中获取每个子文本训练信息中的起始时间戳信息和结尾时间戳信息,如“天很热”的[19.83,21.00]。
将音频信息按照子文本训练信息的起始时间戳信息和结尾时间戳信息进行拆分,获取到多个对应于子文本训练信息的字音频信息,将子文本训练信息和对应的字音频信息作为训练数据。
在一可实施方式中,在生成对应于音频信息的语音识别文本信息和第一时间戳信息之前,方法还包括:
将标注文本信息输入于语音识别系统中的语言模型进行训练,或者在语音识别系统进行解码时动态增加标注文本信息的概率值。
本实施例中,考虑到通过语音识别系统所得到的语音识别文本信息可能准确度不高,因此在执行步骤102之前,将所获取的标注文本信息输入于语音识别系统中的语言模型中进行训练,或者在语音识别系统针对该音频信息进行解码过程中动态增加对生成标注文本信息的概率值,以提高语音识别系统识别该音频信息的准确率。
图2为本发明实施例一种训练数据生成装置的结构组成示意图。
如图2所示,本发明另一方面提供一种训练数据生成装置,装置包括:
信息接收模块201,用于接收音频信息和对应的标注文本信息;
第一信息生成模块202,用于生成对应于音频信息的语音识别文本信息和第一时间戳信息;
第二信息生成模块203,用于内容匹配标注文本信息和语音识别文本信息,根据第一时间戳信息生成对应于标注文本信息的第二时间戳信息;
训练数据生成模块204,用于根据第二时间戳信息,获取标注文本信息中的子文本训练信息和音频信息中的子音频训练信息。
本实施例中,在信息接收模块201中,音频信息和对应的标注文本信息优选为长音频和长标注文本信息,可以是有声书、演讲音频、访谈记录等等,其获取方式可以通过爬虫技术从网络上抓取或者从本地数据库中获取。
在第一信息生成模块202中,语音识别文本信息和第一时间戳信息可以通过将所接收到的音频信息输入于现有的语音识别系统或者通过人工测量识别得到;第一时间戳信息包括对应于语音识别文本信息中每个字或词的起始和结尾时间戳信息,例如标注文本信息为:“天很热,地球南极的冰川都陷落了”,假设语音识别文本信息为“天很热地球南极冰川都显露”的时间戳信息可能为:
天很热:[天,19.83,20.49],[很,20.49,20.79],[热,20.79,21.00];
地球南极:[地球,21.90,22.05],[南极,22.05,22.62];
冰川显露:[冰川,23.67,24.00],[显露,24.00,24.24]。
在第二信息生成模块203中,将标注文本信息和语音识别文本信息进行内容匹配,使生成对应于标注文本信息的第二时间戳信息。
接着在训练数据生成模块204中,根据第二时间戳信息,获取标注文本信息中的子文本训练信息和音频信息中的子音频训练信息。
由此,通过获取原始的音频信息以及标注文本信息,利用音频信息的时间戳信息从原始的音频信息以及标注文本信息中获取多个子音频训练信息和对应的子文本训练信息,从而得到大量并且高质量的语音训练数据,此过程效率高并且降低了耗费成本。
在一可实施方式中,第二信息生成模块203具体用于:
利用编辑距离算法对标注文本信息和语音识别文本信息进行文本相似度匹配;
以标注文本信息作为基准,对相匹配的语音文本信息中的字/词进行文本对齐处理。
本实施例中,编辑距离算法是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们相似度越低。
在相似度匹配时,具体可以将标注文本信息和语音识别文本信息分别根据标点符号或者分词工具拆分为多个长语句信息或者词级别语句信息,将标注文本信息和语音识别文本信息中的长语句信息或者词级别语句信息进行两两相似度匹配,选取相似度最高的两个语句信息认定为相匹配。
接着进行文本对齐处理,在处理过程中,可以首先利用现有的分词工具对相匹配的语音文本信息进行分词处理,得到多个字/词信息,接着以标注文本信息为基准,将语音文本信息中的字/词分别与标注文本信息中的字/词相对应,未对齐的部分可以通过增设特定符号进行填充,以此完成内容匹配。针对上述所举的例子,对齐后表示为:
标注文本:天很热,地球南极的冰川都陷落了;
识别文本:天很热__地球南极__冰川都显露__(下划线符号表示空白)。
在一可实施方式中,训练数据生成模块204具体用于:
对标注文本信息根据设定字符或者指定字符数量拆分为多个子文本训练信息,并从第二时间戳信息中分别获取多个子文本训练信息所对应的起始时间戳和结尾时间戳信息;
根据多个子文本训练信息所对应的起始时间戳和结尾时间戳信息,将音频信息拆分为多个子音频训练信息。
本实施例中,训练数据生成模块204具体用于:
在生成第二时间戳信息之后,检测标注文本信息中的标点符号索引位置或者根据指定字符数量定位到所需切割的索引位置,按照索引位置将标注文本信息拆分为多个子文本训练信息,如将“天很热,地球南极的冰川都陷落了”分为“天很热”和“地球南极的冰川都陷落了”。
接着从第二时间戳信息中获取每个子文本训练信息中的起始时间戳信息和结尾时间戳信息,如“天很热”的[19.83,21.00]。
将音频信息按照子文本训练信息的起始时间戳信息和结尾时间戳信息进行拆分,获取到多个对应于子文本训练信息的字音频信息,将子文本训练信息和对应的字音频信息作为训练数据。
本发明另一方面提供一种计算机可读存储介质,存储介质包括一组计算机可执行指令,当指令被执行时用于执行上述任一项的训练数据生成方法。
在本发明实施例中计算机可读存储介质包括一组计算机可执行指令,当指令被执行时用于,接收音频信息和对应的标注文本信息;生成对应于音频信息的语音识别文本信息和第一时间戳信息;内容匹配标注文本信息和语音识别文本信息,生成对应于标注文本信息的第二时间戳信息,其中,第二时间戳信息与第一时间戳信息相对应;根据第二时间戳信息,获取标注文本信息中的子文本训练信息和音频信息中的子音频训练信息。由此,通过获取原始的音频信息以及标注文本信息,利用音频信息的时间戳信息从原始的音频信息以及标注文本信息中获取多个子音频训练信息和对应的子文本训练信息,从而得到大量并且高质量的语音训练数据,此过程效率高并且降低了耗费成本。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!