基于SDK的无人车语音交互系统及其建立方法与流程
本发明涉及语音交互技术领域,具体为基于sdk的无人车语音交互系统及其建立方法。
背景技术:
随着时代的变迁,智能机器人相比于传统机器人的通过按键和摇杆等人机交流困难的方式而言,智能机器人的语音控制拥有操作简便,快捷等优点,人们能够直接通过语音系统对机器人进行控制,同时能够与人们进一步的进行语音交流,因此,通过语音技术解决人机交流困难势在必行。
语音是最被看好的人机交互方式,它的优势在于使用便捷、反应迅速、效率高等。相比于传统机器人的通过按键和摇杆等人机交流困难的方式而言,智能机器人的语音控制拥有操作简便,快捷等优点。
机器人只采用了在线语音识别和基于网络的语音合成,在互联网信号的低质量或没有信号的情况下,语音识别和合成会有影响,甚至无法使用。同时还需要克服在实际环境中运行所能遇到的噪声,回声等问题,这些问题的解决将会大大地增强语音识别的功能,使得语音识别系统更加完善。因此,设计无需在线语音识别和解决噪声、回声问题的基于sdk的无人车语音交互系统及其建立方法是很有必要的。
技术实现要素:
本发明的目的在于提供基于sdk的无人车语音交互系统及其建立方法,以解决上述背景技术中提出的问题。
为了解决上述技术问题,本发明提供如下技术方案:基于sdk的无人车语音交互系统,包括语音识别的功能库、人工智能标记语言aiml、计算机预处理模块、科大讯飞语音识别sdk、语音合成模块和人工智能语音对话模块;
所述语音识别的功能库包括语音识别的pocketsphinx功能包,用于识别英文语音和使用中文语音引擎和模型识别中文;
所述人工智能标记语言aiml用于使用户与智能机器人交谈,机器人也能通过自然语言的软件代理给出一个明确的回答;
所述计算机预处理模块用于将语音中的词汇转换为计算机可以读取的代码输入;
所述科大讯飞语音识别sdk用于识别出的最终效果会通过网络在科大讯飞sdk在线识别后通过话题发布,在终端中就可以看到联网所识别生成的字符串;
所述语音合成模块用于完成语音文本和语音输出之间的转换,将计算机所接收到的语音指令转换成文字输出;
所述人工智能语音对话模块用于通过对话系统与用户进行对话,在理解用户语言的情况下回答问题。
基于sdk的无人车语音交互系统的建立方法,其特征在于:包括
步骤一,根据语音系统选择可以满足用户需求的识别方法,对语音特征参数进行分析,判断,并以标准模式将它进行存储,用过参数之后,再将模块与所存模块进行比对,最后判断最佳的匹配模块为识别结果;
步骤二,通过编写语音问答的代码创建的智能语音回答所需要的语音库,通过语音功能包pocketsphinx可以赋予机器人语音识别的能力,poceketsphinx功能包提供了大量的将文本转换为语音的功能包,这些功能包还可以提供机器人实现播报英语的能力;
步骤三,机器人可以通过aiml从本地的语音库中匹配合适的语句,以此完成智能交流操作,最后在ros集成中使用科大讯飞的sdk,让机器人听懂中文;
步骤四,根据输入的语音指令识别生成对应的字符串,实现一个语音控制机器人小车的小应用,从而可以通过语音控制小车运动;
步骤五,通过科大讯飞sdk,使用ros系统构建机器人中文语音交互应用;
步骤六,通过编写节点让机器人具备说的能力,能够回答用户所提出的问题,科大讯飞的sdk中有该模块技术的tts_sample例程,在功能包中输入所需要的代码,为机器人添加ros语音接口;
步骤七,创建一个完整的智能语音系统。
根据上述技术方案,上述步骤七中,需要以下三个步骤来完成,
a)创建start_chat.launch文件以便可以启动智能语音系统的所有节点;
b)启动三个关键节点,分别是语音识别、语音合成、自然语音处理;
c)启动成功后,测试这款本文所设计的智能语音对话的机器人。
根据上述技术方案,上述步骤二中,需要以下三个步骤来完成,
d)创建每行一个单词或短语的asimple文本文件;这是可用于通过语音命令来驱动机器人的语料库,接着将其存储在一个名为commands.txt的文件中,在robot_voice软件包的config子目录中;
e)登录网站在线将该文件生成语音信息和识别模块,然后使用该网站的sphinxknowledgebasetool进行在线编译;
f)在系统编译好程序之后把该压缩文件解压到config文件夹下,在该文件夹内所有的文件都是根据本文所编写的语音识别模块所解析出来,通过在终端运行这些文件,这时用户就可以通过麦克风向计算机输入语音,最终的语音识别结果会在终端话题中打印出来。
根据上述技术方案,上述步骤三中,需要以下三个步骤来完成,
g)安装pythonaiml库,可以通过在python终端中输入importaiml来确定pyaiml有没有安装成功,若出现任何错误,则说明安装失败;
h)将文件为aiml命名,之后就需要对文件进行扫描识别。在发布指令的同时aiml文件也在加载,aiml需要生成数据书之后才能够被系统匹配,当所有匹配的语句全部记录进系统后,可以输入命令进行测试;
i)观察语音识别系统窗口,可以看到机器人已经匹配好了所输入的语音指令,并且输出了应答的语句。
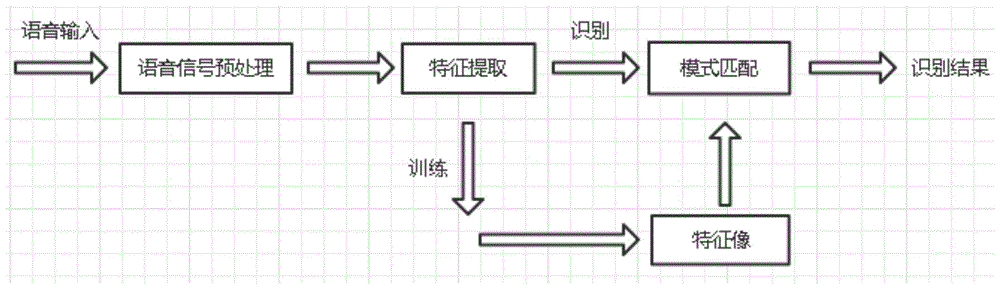
根据上述技术方案,上述步骤四中,语音输入到计算机后,系统会进行语音信号的预处理,紧接着提取语音信号的特征参数,语音特征的提取分为两步,
j)进行语音的识别,系统匹配到语音模式之后就直接通过话题发布识别的结果;
k)在进行语音训练之后直接提取出特征像,然后再通过话题发布最终结果。
根据上述技术方案,上述步骤二中,语音库生成之后,将做所有的文件全都重命名为chat,同时还要与commends文件放在同一路径下,创建launch文件,运行pocketsphinx的语言识别节点,并设置语音库路径,pocketsphinx功能包通过话题将识别的文本进行发布,创建话题转换节点,将语音识别结果发送到voicewords话题,使用string类型将文本发布,将命令输入系统,对着麦克风讲话,就可以在终端看到识别的语音字符串。
根据上述技术方案,上述步骤五中,下载科大讯飞的sdk的开发包并下载语音听写所需要的sdk,然后,开始测试所下载的sdk,以便对它的功能有个大致的了解,继续编译生成可执行的文件,通过终端运行编译成功的程序,依据编译成功后的文件进行操作,无需上传用户字典,将麦克风设置为语音输入源,然后就会出现15s的语音输入提示,出现说话提示后,再通过麦克风在规定时间内输入语音指令。
根据上述技术方案,上述步骤五中,在下载的sdk的功能包中可以找到iat_online_record_sample文件,打开文件接下来需要对代码进行修改,并添加需要的ros接口,修改完成后将文件重新命名为iat_publish.cpp,在改写的文件代码中,需要加入一些环境变量用来接收语音信号指令,在调用了语音识别功能后,系统识别出了系统变量的位置,识别之后再通过话题打印出最后识别出来的结果。
与现有技术相比,本发明所达到的有益效果是:本发明,相对于传统机器人使用更加方便,操作更加简单,相比于传统机器人的通过按键和摇杆等人机交流困难的方式而言,智能机器人的语音控制拥有操作简便,快捷等优点。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明的语音识别步骤示意图;
图2是本发明的科大讯飞iat_record解析示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-2,本发明提供技术方案:基于sdk的无人车语音交互系统,包括语音识别的功能库、人工智能标记语言aiml、计算机预处理模块、科大讯飞语音识别sdk、语音合成模块和人工智能语音对话模块;
语音识别的功能库包括语音识别的pocketsphinx功能包,用于识别英文语音和使用中文语音引擎和模型识别中文;
人工智能标记语言aiml用于使用户与智能机器人交谈,机器人也能通过自然语言的软件代理给出一个明确的回答;
计算机预处理模块用于将语音中的词汇转换为计算机可以读取的代码输入;
科大讯飞语音识别sdk用于识别出的最终效果会通过网络在科大讯飞sdk在线识别后通过话题发布,在终端中就可以看到联网所识别生成的字符串;
语音合成模块用于完成语音文本和语音输出之间的转换,将计算机所接收到的语音指令转换成文字输出;
人工智能语音对话模块用于通过对话系统与用户进行对话,在理解用户语言的情况下回答问题;
基于sdk的无人车语音交互系统的建立方法,其特征在于:包括
步骤一,根据语音系统选择可以满足用户需求的识别方法,对语音特征参数进行分析,判断,并以标准模式将它进行存储,用过参数之后,再将模块与所存模块进行比对,最后判断最佳的匹配模块为识别结果;
步骤二,通过编写语音问答的代码创建的智能语音回答所需要的语音库,通过语音功能包pocketsphinx可以赋予机器人语音识别的能力,poceketsphinx功能包提供了大量的将文本转换为语音的功能包,这些功能包还可以提供机器人实现播报英语的能力;
步骤三,机器人可以通过aiml从本地的语音库中匹配合适的语句,以此完成智能交流操作,最后在ros集成中使用科大讯飞的sdk,让机器人听懂中文;
步骤四,根据输入的语音指令识别生成对应的字符串,实现一个语音控制机器人小车的小应用,从而可以通过语音控制小车运动;
步骤五,通过科大讯飞sdk,使用ros系统构建机器人中文语音交互应用;
步骤六,通过编写节点让机器人具备说的能力,能够回答用户所提出的问题,科大讯飞的sdk中有该模块技术的tts_sample例程,在功能包中输入所需要的代码,为机器人添加ros语音接口;
步骤七,创建一个完整的智能语音系统;
上述步骤七中,需要以下三个步骤来完成,
a)创建start_chat.launch文件以便可以启动智能语音系统的所有节点;
b)启动三个关键节点,分别是语音识别、语音合成、自然语音处理;
c)启动成功后,测试这款本文所设计的智能语音对话的机器人;
上述步骤二中,需要以下三个步骤来完成,
d)创建每行一个单词或短语的asimple文本文件;这是可用于通过语音命令来驱动机器人的语料库,接着将其存储在一个名为commands.txt的文件中,在robot_voice软件包的config子目录中;
e)登录网站在线将该文件生成语音信息和识别模块,然后使用该网站的sphinxknowledgebasetool进行在线编译;
f)在系统编译好程序之后把该压缩文件解压到config文件夹下,在该文件夹内所有的文件都是根据本文所编写的语音识别模块所解析出来,通过在终端运行这些文件,这时用户就可以通过麦克风向计算机输入语音,最终的语音识别结果会在终端话题中打印出来;
上述步骤三中,需要以下三个步骤来完成,
g)安装pythonaiml库,可以通过在python终端中输入importaiml来确定pyaiml有没有安装成功,若出现任何错误,则说明安装失败;
h)将文件为aiml命名,之后就需要对文件进行扫描识别。在发布指令的同时aiml文件也在加载,aiml需要生成数据书之后才能够被系统匹配,当所有匹配的语句全部记录进系统后,可以输入命令进行测试;
i)观察语音识别系统窗口,可以看到机器人已经匹配好了所输入的语音指令,并且输出了应答的语句;
上述步骤四中,语音输入到计算机后,系统会进行语音信号的预处理,紧接着提取语音信号的特征参数,语音特征的提取分为两步,
j)进行语音的识别,系统匹配到语音模式之后就直接通过话题发布识别的结果;
k)在进行语音训练之后直接提取出特征像,然后再通过话题发布最终结果;
上述步骤二中,语音库生成之后,将做所有的文件全都重命名为chat,同时还要与commends文件放在同一路径下,创建launch文件,运行pocketsphinx的语言识别节点,并设置语音库路径,pocketsphinx功能包通过话题将识别的文本进行发布,创建话题转换节点,将语音识别结果发送到voicewords话题,使用string类型将文本发布,将命令输入系统,对着麦克风讲话,就可以在终端看到识别的语音字符串;
上述步骤五中,下载科大讯飞的sdk的开发包并下载语音听写所需要的sdk,然后,开始测试所下载的sdk,以便对它的功能有个大致的了解,继续编译生成可执行的文件,通过终端运行编译成功的程序,依据编译成功后的文件进行操作,无需上传用户字典,将麦克风设置为语音输入源,然后就会出现15s的语音输入提示,出现说话提示后,再通过麦克风在规定时间内输入语音指令;
上述步骤五中,在下载的sdk的功能包中可以找到iat_online_record_sample文件,打开文件接下来需要对代码进行修改,并添加需要的ros接口,修改完成后将文件重新命名为iat_publish.cpp,在改写的文件代码中,需要加入一些环境变量用来接收语音信号指令,在调用了语音识别功能后,系统识别出了系统变量的位置,识别之后再通过话题打印出最后识别出来的结果。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!